
最近在看Apache DolphineScheduler,發現DolphinScheduler在處理任務時,通過先將任務快速的存儲在資料庫中,然後基於對應的Task,將Task放入隊列中,然後將Task進行快速消費的思路。 這種模型在很多框架中,都有體現。 我們知道在Master模塊時處理任務的核心 ...
一. 高併發場景下常見的3種問題
1.1 緩存穿透
當用戶訪問的數據既不存在緩存中也不在資料庫中時,就會導致每個用戶查詢都會“穿透”緩存“直抵”資料庫。這種情況就成為緩存穿透。當高併發的請求到達時,緩存穿透不僅增加了響應時間,而且還會引發對DBMS的高併發查詢,這種高併發查詢很可能會導致DBMS的奔潰。
緩存穿透產生的主要原因有兩個:一是在資料庫中沒有相應的查詢結果,二是查詢結果為空時,不對查詢結果進行緩存。所以,針對以上兩點,解決方案也有兩個:
* 對非法請求進行限制;
* 對結果為空的查詢給出預設值。
1.2 緩存擊穿
對於某一個緩存,在高併發情況下若其訪問量特別巨大,當該緩存的有效時間達到時,可能會出現大量的訪問都要重建該緩存,即這些訪問請求發現緩存中沒有該數據,則立即到DBMS中進行查詢,那麼這就有可能會引發對DBMS的高併發查詢,從而導致DBMS的崩潰。這種情況稱為緩存擊穿,而該緩存數據稱為熱點數據。
對於緩存擊穿的解決方案,較典型的是使用“雙重檢測鎖”機制。
1.3 緩存雪崩
對於緩存中的數據,很多都是有過期時間的。若大量緩存的過期時間在同一很短的時間段內幾乎同時達到,那麼在高併發訪問場景下就可能會引發對DBMS的高併發查詢,而這將可能直接導致DBMS的奔潰。這種情況稱為緩存雪崩。
對於緩存雪崩沒有很直接的解決方案,最好的解決方案就是預防,即提前規劃好緩存的過期時間。要麼就是讓緩存永久有效,當DB中數據發生變化時清除相應的緩存。如果DBMS採用的是分散式部署,則將熱點數據均勻分佈在不同資料庫節點中,則可能到來的訪問負載均衡開來。
二. 資料庫緩存雙寫不一致
以上三種情況都是針對高併發 讀 場景中可能會出現的問題,而資料庫緩存雙寫不一致問題,則是在高併發 寫 場景下出現的問題。
對於資料庫緩存雙寫不一致問題,以下兩種場景均有可能會發生:
2.1 “修改DB更新緩存”場景
對於具有緩存warmup功能的系統,DBMS中常用數據的變更,都會引發緩存中相關數據的更新。
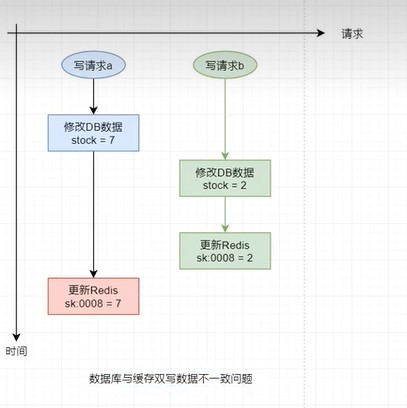
在高併發 寫 操作場景下,若多個請求要對DBMS中同一個數據進行修改,修改後還需要更新緩存中相關數據,那麼就有可能出現緩存與資料庫中數據不一致的情況。
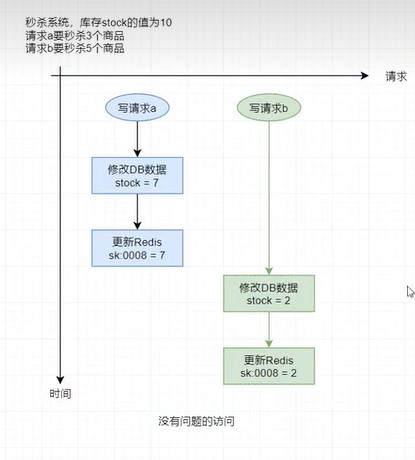
概況舉例如下,
理想情況下的訪問:
異常情況
2.2 修改DB刪除緩存”場景
在很多系統中是沒有緩存warmup功能的,為了保持緩存與資料庫數據的一致性,一般都是在對資料庫執行了寫操作後,就會刪除相應緩存。
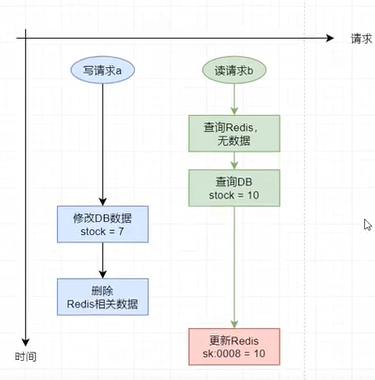
在高併發 讀寫 請求場景下,若這些請求對DBMS中同一個數據的操作既包含寫也包含讀,且修改後還要刪除緩存中相關數據,那麼就有可能會出現緩存與資料庫中數據不一致的情況。
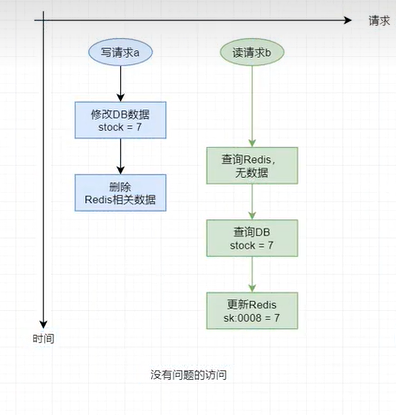
概況舉例如下:
仍然為秒殺系統,庫存stock的值為10,請求a要秒殺3個商品,請求b僅查看商品剩餘數量,暫時不參與搶購。
理想情況下的訪問:
異常情況(即 資料庫與緩存雙寫數據不一致問題)
三. 解決方案
3.1 延遲雙刪
延遲雙刪方案是專門針對於“修改DB刪除緩存”場景的解決方案。但該方案並不能徹底解決數據不一致的狀況,其只可能降低發生數據不一致的概率。
延遲雙刪方案是指,在寫操作完畢後會立即執行一次緩存的刪除操作,然後再停止一段時間(一般為幾秒)後再進行一次刪除。而兩次刪除中間的間隔時長,要大於一次緩存寫操作的時長。
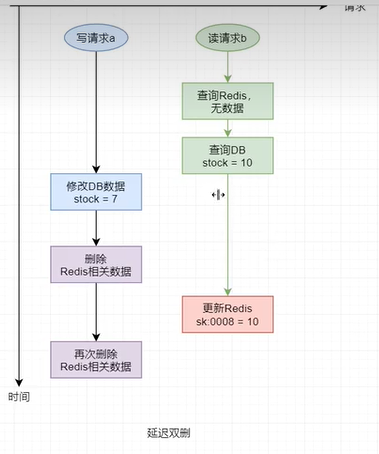
難點在於雙刪之間的停頓時間大小的設置。
3.2 隊列
以上兩種場景中,之所以會出現資料庫與緩存中數據不一致,主要是因為對請求的處理出現了並行。只要將請求寫入到一個統一的隊列,只有處理完一個請求後才可以處理下一個請求,即 系統對用戶的請求處理串列化,這樣就可以解決數據不一致的問題。
主要問題:併發性差。
3.3 分散式鎖
使用隊列的串列化雖然可以解決資料庫與緩存中數據不一致,但系統失去了併發性,降低了性能。使用分散式鎖可以在不影響併發的前提下,協調各處理線程間的關係,使資料庫與緩存中的數據達成一致性。
只需要對資料庫中的這個共用數據的訪問,通過分散式鎖來協調對其的操作即可。
學習筆記--參閱特別聲明
【Redis視頻從入門到高級】
【https://www.bilibili.com/video/BV1U24y1y7jF?p=11&vd_source=0e347fbc6c2b049143afaa5a15abfc1c】


