
《數據資產管理核心技術與應用》是清華大學出版社出版的一本圖書,全書共分10章,第1章主要讓讀者認識數據資產,瞭解數據資產相關的基礎概念,以及數據資產的發展情況。第2~8章主要介紹大數據時代數據資產管理所涉及的核心技術,內容包括元數據的採集與存儲、數據血緣、數據質量、數據監控與告警、數據服務、數據許可權 ...
《數據資產管理核心技術與應用》是清華大學出版社出版的一本圖書,全書共分10章,第1章主要讓讀者認識數據資產,瞭解數據資產相關的基礎概念,以及數據資產的發展情況。第2~8章主要介紹大數據時代數據資產管理所涉及的核心技術,內容包括元數據的採集與存儲、數據血緣、數據質量、數據監控與告警、數據服務、數據許可權與安全、數據資產管理架構等。第9~10章主要從實戰的角度介紹數據資產管理技術的應用實踐,包括如何對元數據進行管理以發揮出數據資產的更大潛力,以及如何對數據進行建模以挖掘出數據中更大的價值。
圖書介紹:數據資產管理核心技術與應用
今天主要是給大家分享一下第二章的內容:
第二章的標題為元數據的採集與存儲
主要是介紹瞭如何從Apache Hive、Delta lake、Apache Hudi、Apache Iceberg、Mysql 等常見的數據倉庫、數據胡以及關係型資料庫中採集獲取元數據。、
1、Hive的元數據採集方式:
1.1、基於Hive Meta DB的元數據採集
由於Hive在部署時,是將數據單獨存儲在指定的資料庫中的,所以從技術實現上來說肯定是可以直接通過從Hive元數據存儲的的資料庫中獲取到需要的元數據信息。Hive通常是將元數據存儲在單獨的資料庫中,可以在部署時由用戶自己來指定存儲在哪種資料庫上,通常可以支持存儲在MySQL、SQLServer、Derby 、Postgres、Oracle等資料庫中。Hive元數據資料庫中常見的關鍵表之間的關聯關係如下圖,根據下圖的關聯關係,我們就可以用SQL語句查詢到需要的元數據的數據信息。
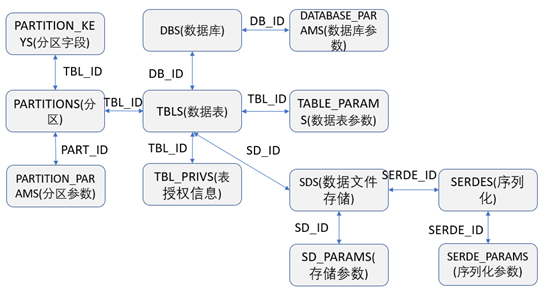
相關表的介紹如下:
DBS:存儲著Hive中資料庫的相關基礎信息
DATABASE_PARAMS:存儲著Hive中資料庫參數的相關信息
TBLS:存儲著Hive中資料庫的數據表的相關基礎信息
COLUMNS_V2:存儲著數據表的欄位信息
TABLE_PARAMS:存儲著Hive中資料庫的數據表參數或者屬性的相關基礎信息
TBL_PRIVS:存儲著表或者視圖的授權信息
SERDES:存儲著數據序列化的相關配置信息
SERDE_PARAMS:存儲著數據序列化的屬性或者參數信息
SDS:存儲著數據表的數據文件存儲的相關信息
SD_PARAMS:存儲著數據表的存儲相關屬性或者參數信息
PARTITIONS:存儲著數據表的分區相關信息
PARTITION_KEYS:存儲著數據表的分區欄位信息
PARTITION_PARAMS:存儲分區的屬性或者參數信息
1.2、基於Hive Catalog的元數據採集
Hive Catalog 是Hive提供的一個重要的組件,專門用於元數據的管理,管理著所有Hive庫表的結構、存儲位置、分區等相關信息,同時Hive Catalog提供了RESTful API或者Client 包供用戶來查詢或者修改元數據信息,其底層核心的Jar包為hive-standalone-metastore.jar。在該Jar包中的org.apache.hadoop.hive.metastore.IMetaStoreClient.java 介面中定義了對Hive元數據的管理的抽象,詳細代碼實現可以參考紙質書。
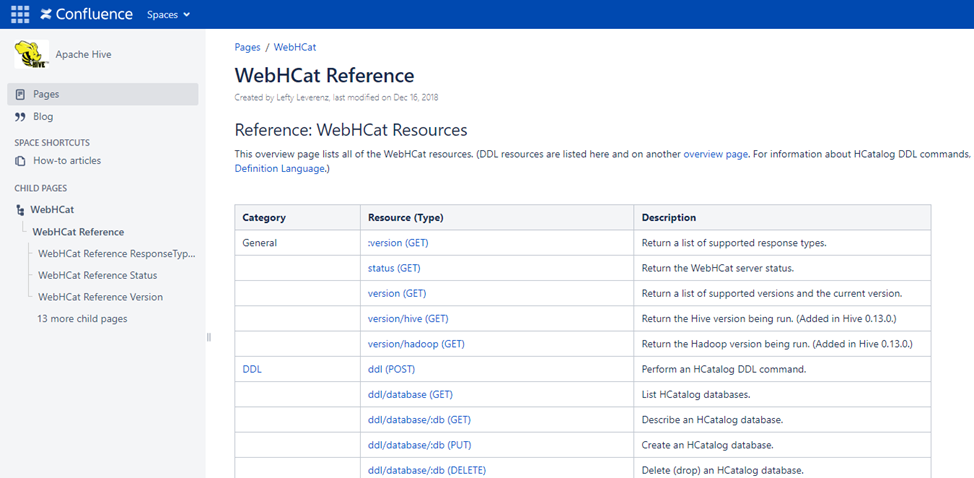
在Hive2.2.0版本之前Hive還提供了以Hcatalog REST API的形式對外可以訪問Hive Catalog(Hive2.2.0版本後,已經移除了Hcatalog REST API這個功能),REST API 訪問地址的格式為:http://yourserver/templeton/v1/resource,在Hive的Wiki網站:WebHCat Reference - Apache Hive - Apache Software Foundation中有詳細列出REST API 支持哪些介面訪問,如下圖
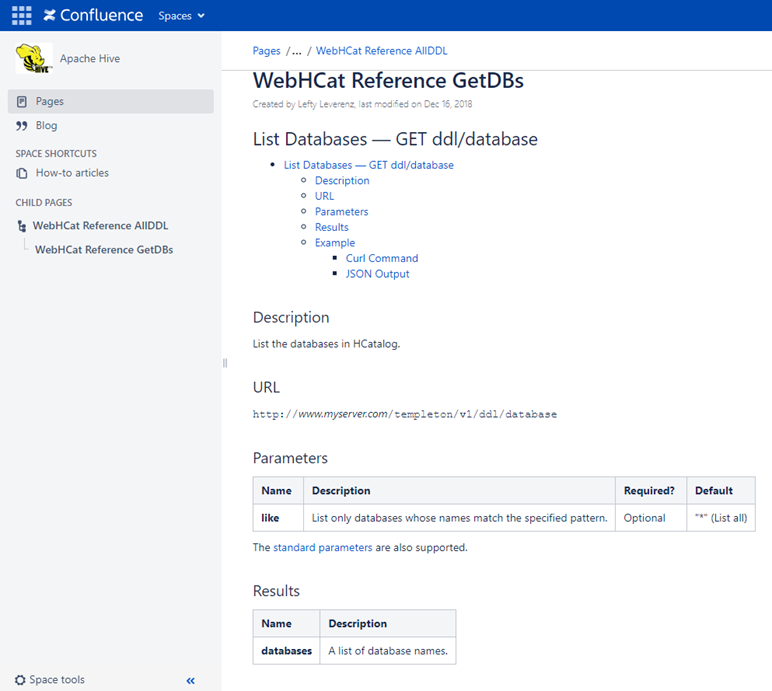
比如通過調用REST API 介面:http://yourserver/templeton/v1/ddl/database 便可以獲取到Catalog中所有的資料庫的信息,如下圖
1.2、基於Spark Catalog的元數據採集
Spark 是一個基於分散式的大數據計算框架。Spark 和Hadoop的最大的不同是,Spark的數據主要是基於記憶體計算,所以Spark的計算性能遠遠高於Hadoop,深受大數據開發者的喜歡,Spark提供了 Java、Scala、Python 和 R 等多種開發語言的 API。
Spark Catalog是Spark提供的一個元數據管理組件,專門用於Spark對元數據的讀取和存儲管理,管理著Spark 支持的所有數據源的元數據,Spark Catalog支持的數據源包括HDFS、Hive、JDBC等,Spark Catalog將外部數據源中的數據表映射為Spark中的表,所以通過Spark Catalog 也可以採集到我們需要的元數據信息。
自Spark3.0版本起,引入了Catalog Plugin,雖然org.apache.spark.sql.catalog.Catalog 提供了一些常見的元數據的查詢和操作,但是並不夠全面、強大以及靈活,比如無法支持多個Catalog等,所以 Catalog Plugin是Spark為瞭解決這些問題而應運而生的。
詳細代碼實現可以參考紙質書。
2、Delta Lake 中的元數據採集
提到Delta Lake 就不得提數據湖這個概念了,Delta Lake 是數據湖的一種。數據湖是相對於數據倉庫提出來的一個集中式存儲概念,和數據倉庫中主要存儲結構化的數據不同的是,數據湖中可以存儲結構化數據(一般指以行和列來呈現的數據)、半結構化數據(如 日誌、XML、JSON等)、非結構化數據(如 Word文檔、PDF 等)和 二進位數據(如視頻、音頻、圖片等)。通常來說數據湖中以存儲原始數據為主,而數據倉庫中以存儲原始數據處理後的結構化數據為主。
Delta Lake是一個基於數據湖的開源項目,能夠在數據湖之上構建湖倉一體的數據架構,提供支持ACID數據事務、可擴展的元數據處理以及底層支持Spark上的流批數據計算處理。
Delta Lake的主要特征如下:
基於Spark之上的ACID數據事務,可序列化的事務隔離級別確保了數據讀寫的一致性。
利用Spark的分散式可擴展的處理能力,可以做到PB級以上的數據處理和存儲。
數據支持版本管控,包括支持數據回滾以及完整的歷史版本審計跟蹤。
支持高性能的數據行級的Merge、Insert、Update、Delete 操作,這點是Hive 所不能具備的。
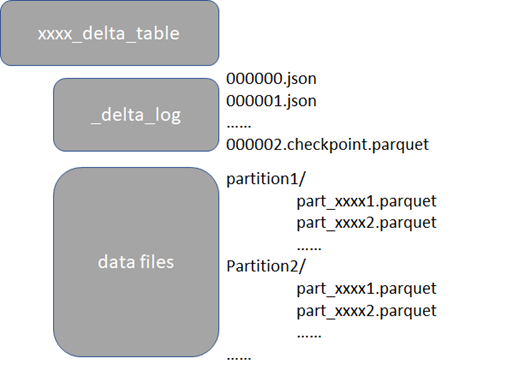
以Parquet文件作為數據存儲格式,同時會有 Transaction Log文件記錄了數據的變更過程,日誌格式為JSON,如下圖
2.1 基於Delta Lake自身設計來採集元數據
Delta Lake 的元數據由自己管理,通常不依賴於類似Hive Metastore 這樣的第三方外部元數據組件。在Delta Lake中元數據是和數據一起存放在自己的文件系統的目錄下,並且所有的元數據操作都被抽象成了相應的 Action 操作,表的元數據是由 Action 子類實現的。如下是Delta Lake中源碼的結構(源碼Github地址:https://github.com/delta-io/delta),如下圖
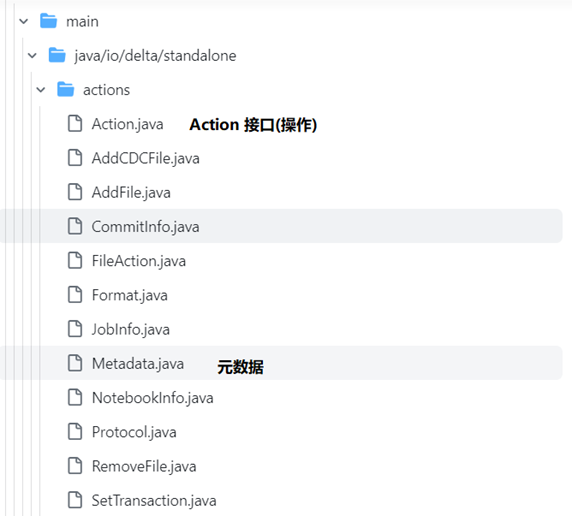
在Metadata.java這個實現類中提供了元數據的方法調用,詳細代碼實現可以參考紙質書。
2.2 基於Spark Catalog來採集元數據
由於Delta Lake 是支持使用spark 來讀取和寫入數據,所以在Delta Lake的源碼中,也實現了Spark提供的CatalogPlugin介面,由於Delta Lake 也實現了Spark提供的CatalogPlugin介面,所以基於Spark Catalog的方式,也可以直接獲取到delta lake的元數據信息,詳細代碼實現可以參考紙質書。
3、MySQL 中的元數據採集
MySQL是被廣泛使用的一款關係型資料庫,在MySQL資料庫系統中自帶了information_schema 這個庫來提供MySQL元數據的訪問,INFORMATION_SCHEMA是每個MySQL實例中的一個自有資料庫,存儲著MySQL伺服器維護的所有其他資料庫的相關信息,INFORMATION_SCHEMA中的表其實都是只讀的視圖,而不是真正的基表,不能執行INSERT、UPDATE、DELETE操作,因此沒有與INFORMATION_SCHEMA相關聯的數據文件,也沒有具有該名稱的資料庫目錄,並且不能設置觸發器。
information_schema 中與元數據相關的重點表如下:
Tables表:提供了資料庫中表、視圖等信息
Columns表:提供了資料庫中表欄位的相關信息
Views表:提供了資料庫中視圖的相關信息
Partitions表:提供了資料庫中數據表的分區信息
Files表:提供了有關存儲MySQL表空間數據的文件的信息
4、Apache Hudi中的元數據採集
Hudi 和Delta Lake 一樣,也是一款基於數據湖的開源項目,同樣也能夠在數據湖之上構建湖倉一體的數據架構,通過訪問網址:Apache Hudi | An Open Source Data Lake Platform即可計入到Hudi的官方首頁。
Hudi的主要特征如下:
支持表、事務、快速的Insert、Update、Delete 等操作
支持索引、數據存儲壓縮比高,並且支持常見的開源文件存儲格式
支持基於Spark、Flink的分散式流式數據處理
支持Apache Spark、Flink、Presto、Trino、Hive等SQL查詢引擎
4.1 基於Spark Catalog來採集元數據
由於Hudi是支持使用Spark 來讀取和寫入數據,所以在Hudi的源碼中,也實現了Spark提供的CatalogPlugin介面,由於Hudi 和Delta Lake一樣, 也實現了spark提供的CatalogPlugin介面,所以採用基於Spark Catalog的方式,也可以直接獲取到Hudi的元數據信息,詳細代碼實現可以參考紙質書。
4.2 Hudi Timeline Meta Server
通常情況下數據湖是通過追蹤數據湖中數據文件的方式來管理元數據的,不管是Delta Lake還是Hudi ,底層都是通過跟蹤文件操作的方式來提取元數據的。在Hudi中,對元數據的操作和Delta Lake的實現很類似,底層也都是抽象成了相應的Action 操作,只是Action操作的類型略微有些不同。
數據湖之所以不能直接用Hive Meta Store 來管理元數據,是因為Hive Meta Store 的元數據管理是沒有辦法實現數據湖特有的數據跟蹤能力的。因為數據湖管理文件的粒度非常細,需要記錄和跟蹤哪些文件是新增操作,哪些文件是失效操作,哪些數據的新增的,哪些數據是更新的,而且還需要具備原子的事務性,支持回滾等操作。Hudi為了管理好元數據,記錄數據的變更過程,設計了Timeline Meta Server,Timeline 記錄了在不同時刻對錶執行的所有操作的日誌,有助於提供表的即時視圖。
在Hudi中抽象出了一個Marker的概念,翻譯過來就是標記的意思,數據的寫入操作可能在完成之前出現寫入失敗的情況,從而在存儲中留下部分或損壞的數據文件,而標記則用於跟蹤和清除失敗的寫入操作,寫入操作開始時,會創建一個標記,表示正在進行文件寫入。寫入提交成功後,標記將被刪除。如果寫入操作中途失敗,則會留下一個標記,表示這個寫入的文件不完整。使用標記主要有如下兩個目的。
正在刪除重覆/部分數據文件:標記有助於有效地識別寫入的部分數據文件,與稍後成功寫入的數據文件對比,這些文件包含重覆的數據,並且在提交完成時會清除這些重覆的數據文件。
回滾失敗的提交:如果寫入操作失敗,則下一個寫入請求將會在繼續進行新的寫入之前會先回滾該失敗的提交。回滾是在標記的幫助下完成的,標記用於識別整體失敗但已經提交的一部分寫入的數據文件。
加入沒用標記來跟蹤每次提交的數據文件,那麼Hudi將不得不列出文件系統中的所有文件,將其與Timeline中看到的文件關聯起來做對比,然後刪除屬於部分寫入失敗的文件,這在一個像Hudi 這樣龐大的分散式系統中,性能的開銷將會是非常昂貴的。
4.3 基於Hive Meta DB來採集元數據
雖然Hudi 元數據存儲是通過Timeline來管理的,但是Hudi 在設計時,就考慮了支持將自身元數據同步到Hive Meta Store中,其實就是將Hudi的Timeline中的元數據非同步更新到Hive Meta Store中存儲。

在Hudi的源碼中,定義了org.apache.hudi.sync.common.HoodieMetaSyncOperations.java這個介面抽象來作為元數據同步給類似Hive Meta DB這樣的第三方的外部元數據存儲庫,詳細代碼實現可以參考紙質書。
5、Apache Iceberg中的元數據採集
Apache Iceberg同樣也是一款開源的數據湖項目,Iceberg的出現進一步推動了數據湖和湖倉一體架構的發展,並且讓數據湖技術變得更加豐富,通過訪問網址:Apache Iceberg - Apache Iceberg 即可進入其官方首頁。
Iceberg的主要特點如下:
同樣也支持Apache Spark、Flink、Presto、Trino、Hive、Impala等眾多的SQL查詢引擎。
支持更加靈活的SQL語句來Merge、Update、Delete數據湖中的數據。
可以很好的支持對數據Schema的變更,比如添加新的列、重命名列等。
支持快速的數據查詢,數據查詢時可以快速跳過不必要的分區和文件以快速查找到符合指定條件的數據,在Iceberg中,單個表可以支持PB級別數據的快速查詢。
數據存儲支持按照時間序列的版本控制以及回滾,可以按照時間序列或者版本來查詢數據的快照。
數據在存儲時,壓縮支持開箱即用,可以有效的節省數據存儲的成本。
5.1 Iceberg的元數據設計
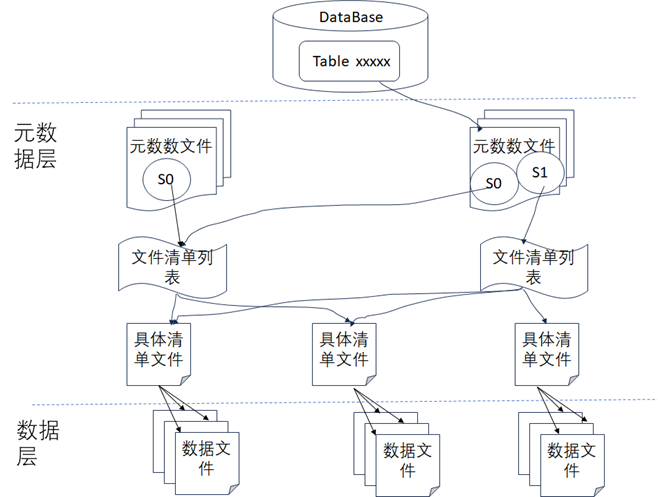
由於Hive數據倉庫的表的狀態是直接通過列出底層的數據文件來查看的,所以表的數據修改無法做到原子性,所以無法支持事務以及回滾,一旦寫入出錯可能就會產生不准確的結果。所以Iceberg在底層通過架構設計時增加了元數據層這一設計來規避Hive數據倉庫的不足,如下圖所示,從圖中可以看到Iceberg使用了兩層設計來持久化數據,一層是元數據層,一層是數據層,在數據層中存儲是Apache Parquet、Avro或ORC等格式的實際數據,在元數據層中可以有效地跟蹤數據操作時刪除了哪些文件和文件夾,然後掃描數據文件統計數據時,就可以確定特定查詢時是否需要讀取該文件以便提高查詢的速度。元數據層通常包容如下內容:
元數據文件:元數據文件通常存儲表的Schema、分區信息和表快照的詳細信息等數據信息。
清單列表文件:將所有清單文件信息存儲為快照中的清單文件的索引,並且通常會包含一些其他詳細信息,如添加、刪除了多少數據文件以及分區的邊界情況等。
清單文件:存儲數據文件列表(比如以Parquet/ORC/AVRO格式存儲的數據),以及用於文件被修改後的列級度量和統計數據。
5.2 通過Spark Catalog來採集元數據
同Hudi 和Delta Lake一樣,由於Iceberg也是支持使用Spark 來讀取和寫入數據,所以在Iceberg的底層設計時,也實現了Spark提供的CatalogPlugin介面,所以通過Spark Catalog的方式,也是可以直接獲取到Iceberg的元數據信息,詳細代碼實現可以參考紙質書。
5.3 通過Iceberg Java API來獲取元數據
在Iceberg中提供了Java API 來獲取表的元數據,通過訪問官方網址:Java API - Apache Iceberg 即可獲取到Java API的詳細介紹,如下圖
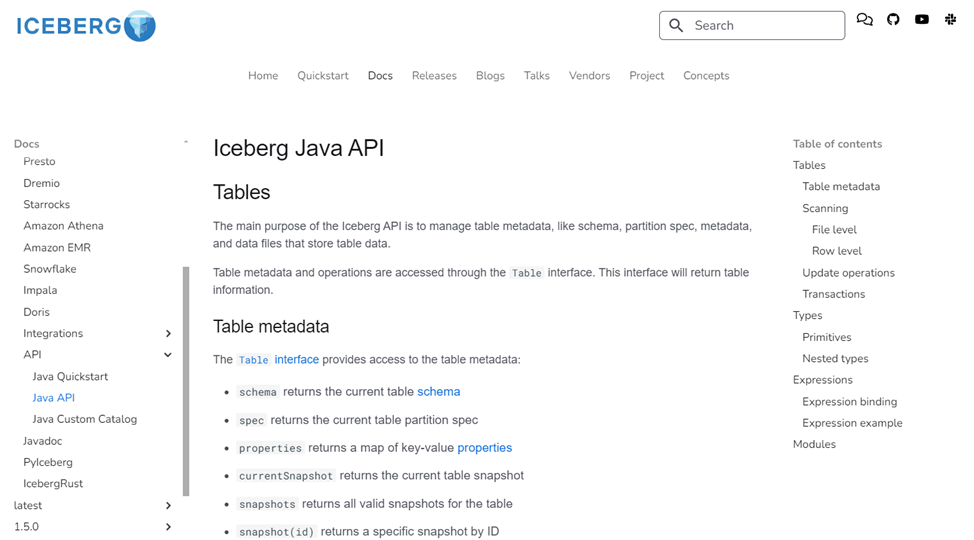
從圖中可以看到,通過Java API 可以獲取到Iceberg數據表的Schema、屬性、存儲路徑、快照等眾多元數據信息。


