
Spectre.Console.NET程式員可能都不陌生,寫控制台程式美化還是不錯的,支持著色,表格,圖標等相當Nice,如果對這個庫不熟悉我強烈推薦你瞭解一下,Spectre.Console.Cli作為Spectre.Console的子集,對於寫一些CLI小工具還是相當方便 本文主要講講 Spec ...
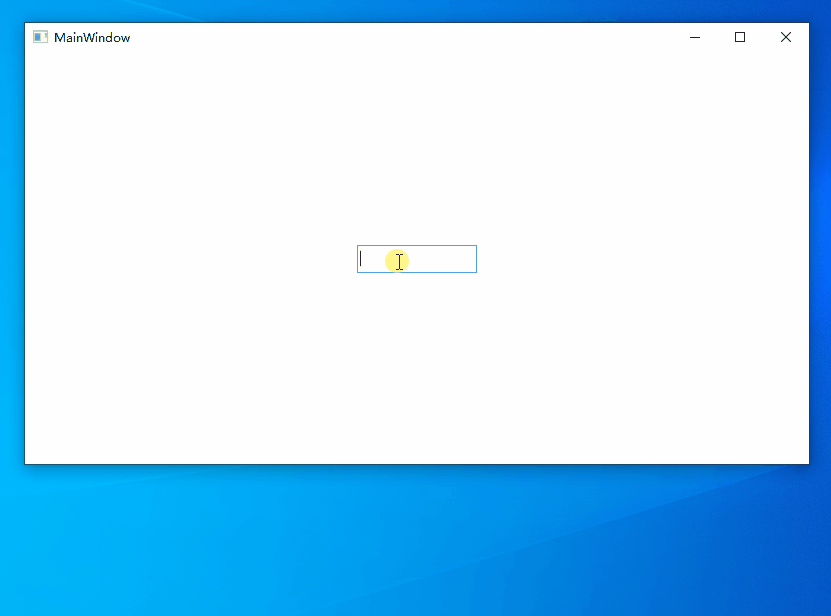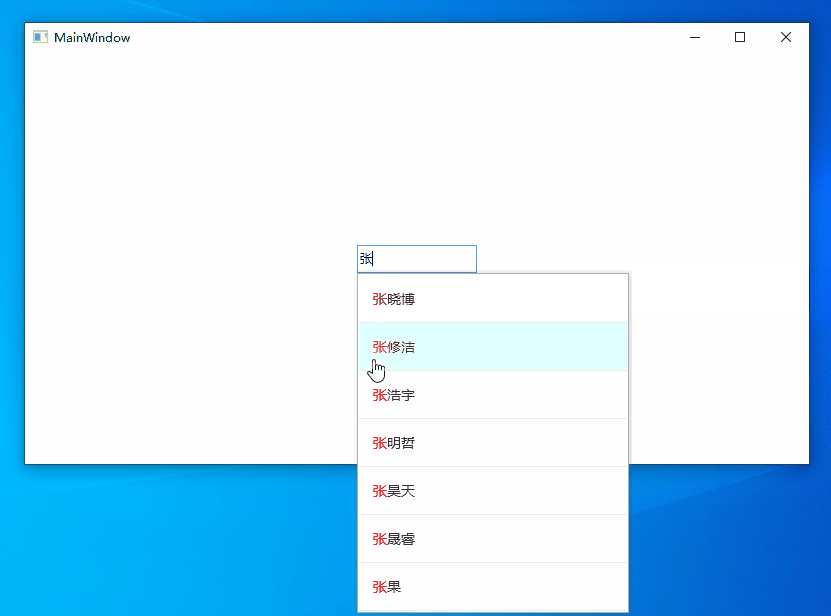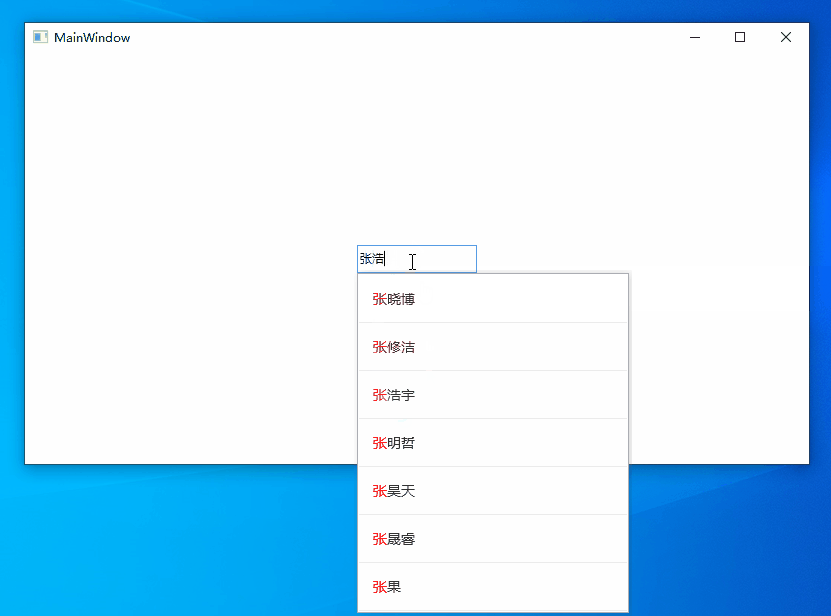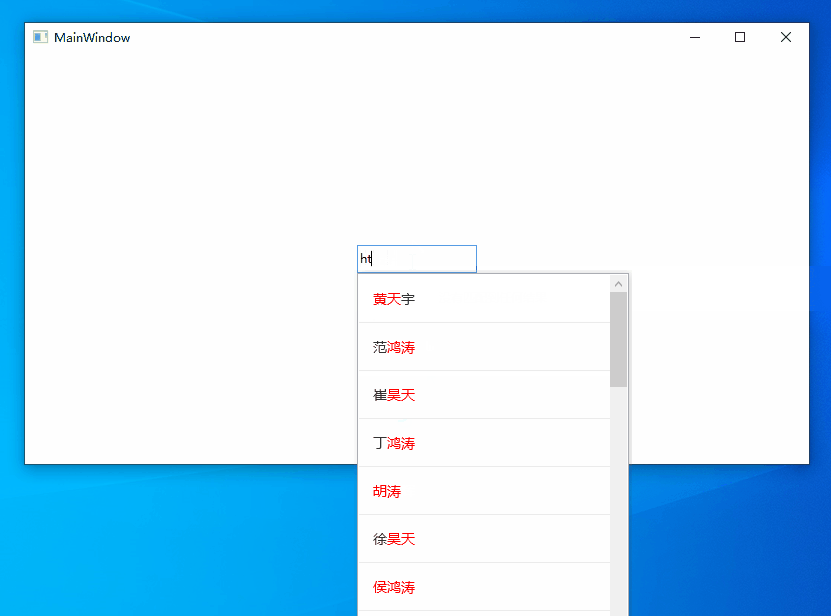
AutoCompleteBox是一個常見的提高輸入效率的組件,很多WPF的第三方控制項庫都提供了這個組件,但基本都是字元串的子串匹配,不支持拼音模糊匹配,例如無法通過輸入ldh或liudehua匹配到劉德華。要實現拼音模糊搜索功能,通常會採用分詞、資料庫等技術對待匹配數據集進行預處理。某些場景受制於條件限制,無法對數據進行預處理,本文將介紹在這種情況下如何實現支持拼音模糊搜索的AutoCompleteBox,先來看下實現效果。
主要思路
WPF中並沒有AutoCompleteBox控制項,我們可以使用TextBox輸入搜索內容,用Popup+ListBox顯示匹配到的提示內容。拼音模糊匹配漢字則採用字元串匹配的方式來解決,也就是搜索字元串和待匹配數據集的內容全部轉換為拼音字元串,然後進行子串匹配。這裡有三個問題需要解決。
- 漢字轉換為拼音。
- 拼音如何匹配。 例如
ldh、lidh、ldhua、liudehua、dhua、hua等都能匹配到劉德華 - 匹配後的內容高亮顯示。 當輸入
dhua匹配到劉德華時需要把德華兩個字高亮。
漢字轉換拼音
微軟為了開發者實現國際化語言的互轉,提供了Microsoft Visual Studio International Pack,這個擴展包裡面有中文、日文、韓文、英語等各國語言包,並提供方法實現互轉、獲取拼音、獲取字數、甚至獲取筆畫數等等。下載Microsoft Visual Studio International Pack 1.0 SR1安裝後,在安裝目錄中找到ChnCharInfo.dll,然後在項目中添加引用。
ChnCharInfo.dll獲取漢字的拼音時只能傳入單個字元,因此只能把漢字字元串拆分成一個個字元處理,由於漢字存在多音字情況以及缺少語義信息,獲取的拼音組合可能是多個,例如輸入長江,返回的是changjiang和zhangjiang。漢字轉拼音的方法如下:
/// <summary>
/// 獲取漢字拼音
/// </summary>
/// <param name="str">待處理包含漢字的字元串</param>
/// <param name="split">拼音分隔符</param>
/// <returns></returns>
public static List<string> GetChinesePhoneticize(string str, string split = "")
{
List<string> result = new List<string>();
char[] chs = str.ToCharArray();
Dictionary<int, List<string>> totalPhoneticizes = new Dictionary<int, List<string>>();
for (int i = 0; i < chs.Length; i++)
{
var phoneticizes = new List<string>();
if (ChineseChar.IsValidChar(chs[i]))
{
ChineseChar cc = new ChineseChar(chs[i]);
phoneticizes.AddRange(cc.Pinyins.Where(r => !string.IsNullOrWhiteSpace(r)).ToList<string>().ConvertAll(p => Regex.Replace(p, @"\d", "").ToLower()).Distinct());
}
else
{
phoneticizes.Add(chs[i].ToString());
}
if (phoneticizes.Any())
totalPhoneticizes[i] = phoneticizes;
}
foreach (var phoneticizes in totalPhoneticizes)
{
var items = phoneticizes.Value;
if (result.Count <= 0)
{
result = items;
}
else
{
var newtotalPhoneticizes = new List<string>();
foreach (var totalPingYin in result)
{
newtotalPhoneticizes.AddRange(items.Select(item => totalPingYin + split + item));
}
newtotalPhoneticizes = newtotalPhoneticizes.Distinct().ToList();
result = newtotalPhoneticizes;
}
}
return result;
}
拼音匹配演算法
漢字轉換後的拼音字元串有多組,只要搜索字元串轉換的拼音組合有一組與待匹配字元串轉換的拼音組合中匹配,則認為匹配成功,為了後續高亮顯示,需要記錄下匹配的起始位置以及匹配的子串長度。代碼如下:
public static bool fuzzyMatchChar(string character, string input, out int matchStart, out int matchCount)
{
List<string> regexs = GetChinesePhoneticize(input);
List<string> targetStr = GetChinesePhoneticize(character, " ");
matchStart = -1;
matchCount = 0;
foreach (string regex in regexs)
{
foreach (string target in targetStr)
{
if (PhoneticizeMatch(regex, target.Split(' '), out matchStart, out matchCount))
return true;
}
}
return false;
}
這裡的PhoneticizeMatch方法是拼音匹配演算法的核心,是在【演算法】拼音匹配演算法這篇博文中演算法的基礎上稍作修改,詳細的思路及圖解可閱讀這篇博文。
高亮匹配的子串
WPF中可以通過TextEffect的PositionStart、PositionCount以及Foreground屬性設置字元串中需要高亮內容的起始位置、長度以及高亮顏色。前面拼音匹配演算法中獲取了匹配成功子串的起始位置和長度,也正是為此做準備。之前在WPF使用TextBlock實現查找結果高亮顯示一文中有詳細介紹思路和代碼,此處不再贅述。
小結
本文介紹了在不依賴資料庫及分詞的情況下如何實現拼音模糊搜索併在目標字元串中高亮顯示,方法中也存在諸多不足需要完善的地方。
- 匹配策略存在誤匹配。例如輸入
石,可以匹配出拼音為shi的所有漢字。 - 匹配演算法效率不夠高。測試過程中,待匹配數據集中模擬了500條數據,匹配耗時大概在400~500ms左右。

