
歡迎查閱袋鼠雲第10期產品功能更新報告。本期,我們精心推出了72項新增和優化功能,致力於在數字化浪潮中為您提供更高效、更智能的服務。我們相信,這些新特性將為您的業務註入新活力,確保您在數字化轉型的每一步都堅實而有力。 以下為袋鼠雲產品功能更新報告第10期內容,更多探索,請繼續閱讀。 離線開發平臺 新 ...
歡迎查閱袋鼠雲第10期產品功能更新報告。本期,我們精心推出了72項新增和優化功能,致力於在數字化浪潮中為您提供更高效、更智能的服務。我們相信,這些新特性將為您的業務註入新活力,確保您在數字化轉型的每一步都堅實而有力。
以下為袋鼠雲產品功能更新報告第10期內容,更多探索,請繼續閱讀。
離線開發平臺
新增功能更新
1.調度周期為自定義調度日期時,支持在任務中靈活設置天、時、分鐘三種調度模式
背景:目前任務選擇自定義調度周期時,僅可設置天調度實例的執行時間,無法根據自定義調度日曆再去設置小時、分鐘調度,沒辦法靈活地滿足客戶的使用場景。
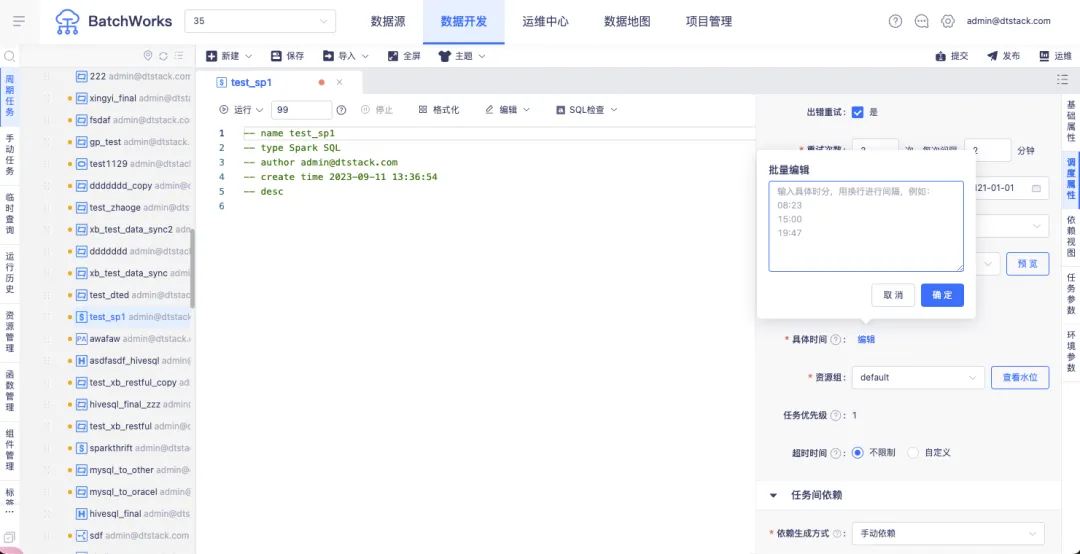
新增功能說明:當選擇的自定義調度周期為天日曆時,可以進行實例批次的選擇。選擇“單批次”代表計劃日期內僅可指定一個計劃時間運行實例,選擇“多批次”代表計劃日期內可以指定多個計劃時間運行實例。
例如,上傳自定義調度日曆,2023-12-21,2023-12-22,2023-12-24等日期為自定義調度日期。選擇單批次並指定具體時間為00時00分,則代表2023-12-21 00:00 , 2023-12-22 00:00,2023-12-24 00:00為調度計劃時間。

選擇多批次並填寫時間,08:23,15:00,19:47,則代表2023-12-21 08:23 , 2023-12-21 15:00,2023-12-21 19:47,2023-12-22 08:23,2023-12-22 15:00,2023-12-22 19:47,2023-12-23 08:23, 2023-12-23 15:00,2023-12-23 19:47,為調度計劃時間。
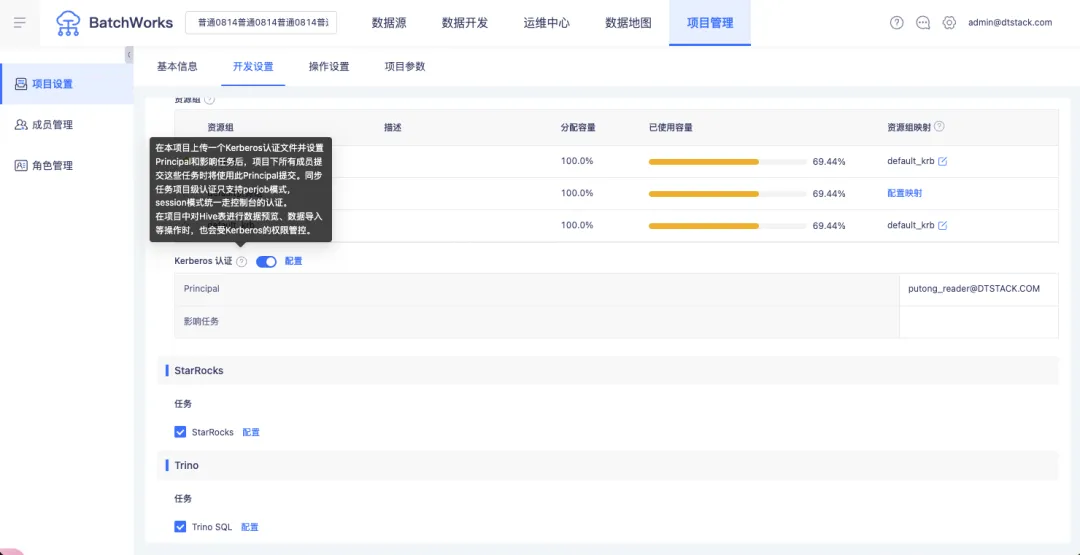
2.項目級 Kerberos 生效範圍變更
背景:當前的許可權管控方法主要是將每個項目作為一個單元進行許可權控制,通過項目級 Kerberos 認證去和底層的 Linux 賬號做關聯。這樣項目層面在表查詢數據預覽是有缺陷的,項目級 Kerberos 認證無法管控到表查詢數據預覽的內容。
新增功能說明:數據同步、數據預覽、SQL 任務運行提交、本地數據上傳,以上場景涉及到的 Hadoop meta 數據源,若在項目中和集群中都上傳了 Kerberos 票據信息,將會使用項目級 Kerberos 票據信息進行校驗。
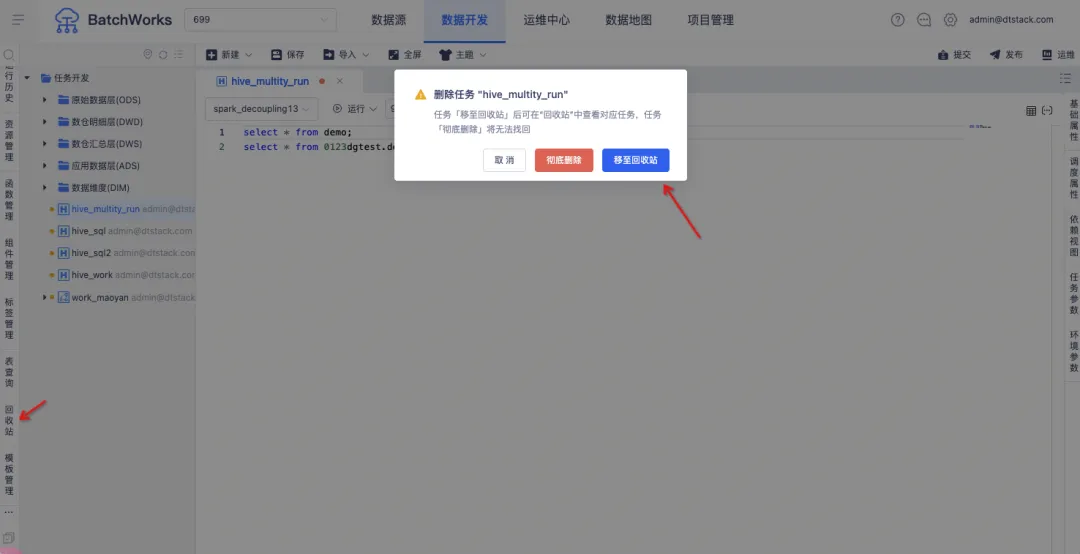
3.支持任務回收站
背景:當前任務被刪除後,用戶無法恢復,為提升容錯機制,產品新增了回收站功能。用戶可在回收站中查看已刪除的周期任務、手動任務和臨時查詢,並選擇恢復。
新增功能說明:新增【回收站】模塊,在刪除任務時可以選擇「徹底刪除」或「移至回收站」。「徹底刪除」的任務將直接刪除且不在回收站展示,「移至回收站」的任務可以在【回收站】中進行查看。
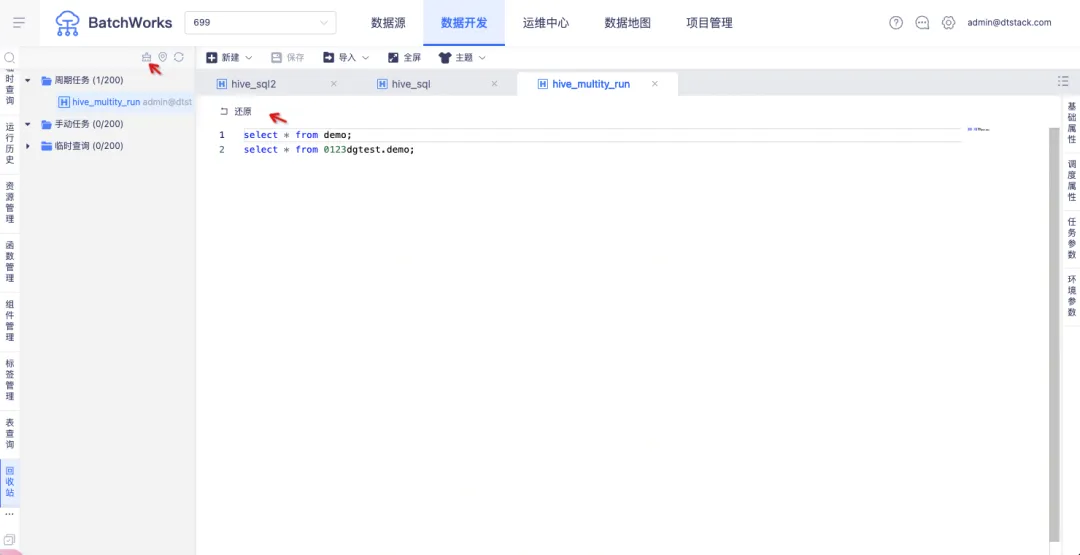
支持對回收站中的任務進行「還原」和「清空」操作。
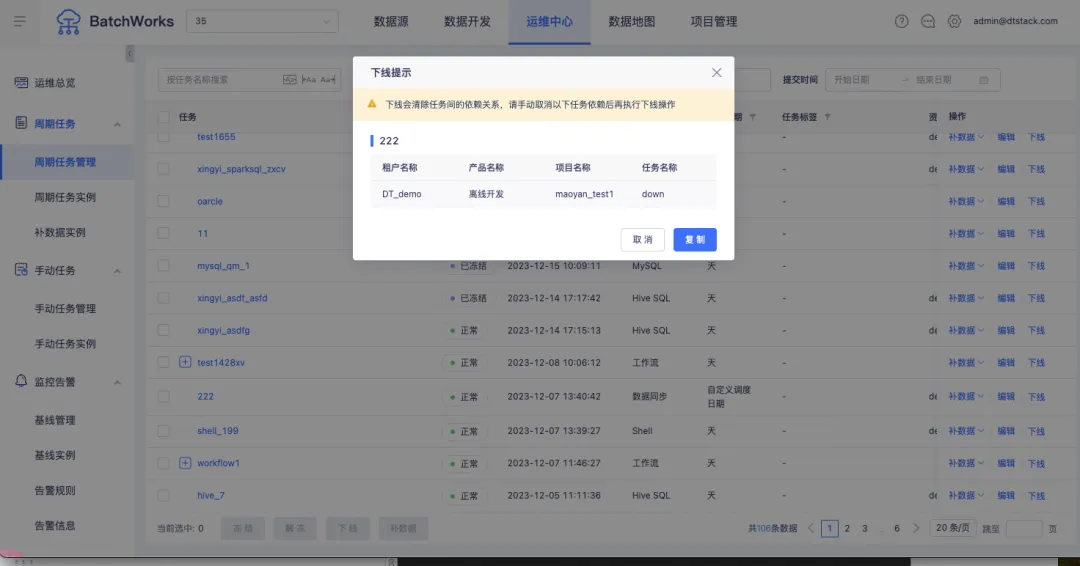
4.上游任務存在下游依賴時禁止下線
背景:上游任務存在依賴時,不應該被允許下線,會影響下游任務運行。此前需要讓用戶自己手動取消依賴關係後,再進行下線操作。
新增功能說明:在下線時進行提示,隱藏下線入口。新增「複製」按鈕,便於用戶粘貼到文本框後依次取消依賴。
5.元資料庫 DMDB 8 適配 MySQL,WEB 中間件東風通 tongweb 替換 tomcat
信創全流程適配,適應國產替代化浪潮。
6.SQL 基礎功能補全
臨時運行、系統函數、自定義函數、執行計劃等功能各計算引擎補全(除了極少數不常用引擎)。
7.支持物化視圖
背景:物化視圖是將表連接或者聚合等耗時較多的結果進行預計算並將計算結果保存下來,在對複雜 SQL 進行查詢的時候,直接基於上一步預計算的結果進行計算,從而避免耗時的操作,更快的得到結果。
新增功能說明:在 Spark3.2.2 版本創建的 Spark SQL 任務支持物化視圖相關語法。
8.數據同步
• 支持 Iceberg0.13 數據同步
• StarRocks 3.x 版本適配,支持作為計算引擎,支持數據同步讀寫
功能優化
1.創建項目時,項目支持不對接並且不創建 Schema
背景:此前離線創建項目必須對接或者創建一個 schema。但在很多應用場景中,用戶的 SQL 開發任務都是在同一個 Schema 下,他們不想在自己的庫里去創建很多無意義的 Schema。
體驗優化說明:在創建項目時,支持選擇「不創建或對接 Schema」。
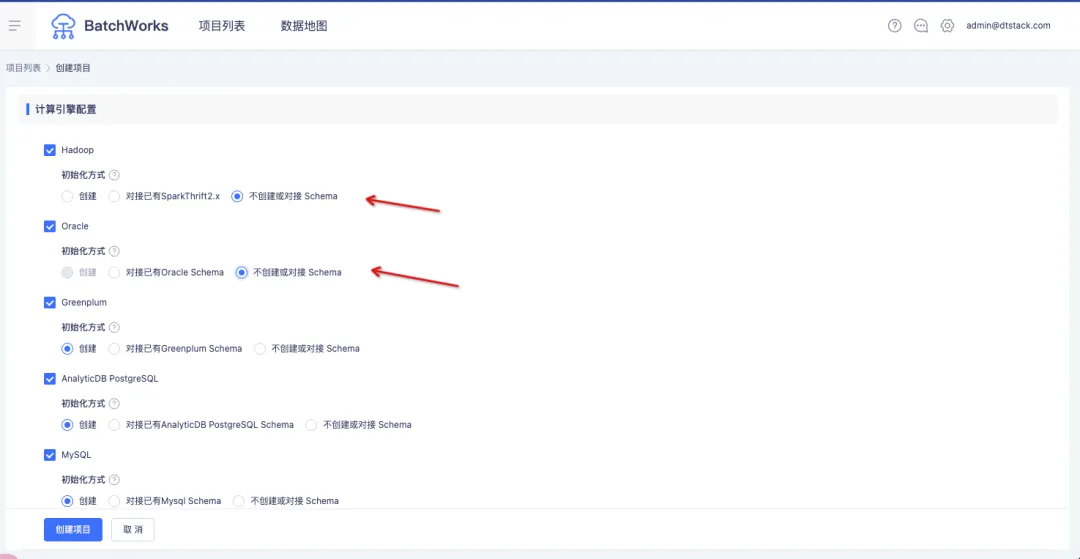
創建項目成功後,在編輯任務時,需要指定 Schema。
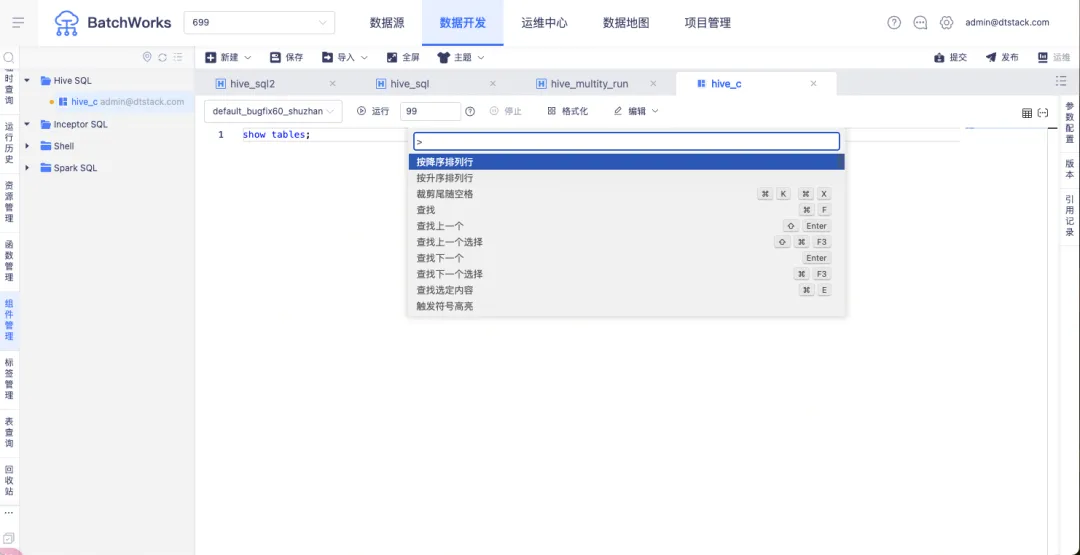
2.快捷鍵優化
快捷鍵選擇欄支持中文。
3.Hive 脫敏改造,複雜查詢生效
原脫敏功能存在問題,複雜查詢不生效。現優化調整後,複雜查詢的結果也會生效脫敏規則。
4.Flink 任務類型改名為 Flink Batch 任務類型
Flink 任務通常是指實時 Flink 任務,實際上該任務是進行離線批處理,更名後信息更加準確。
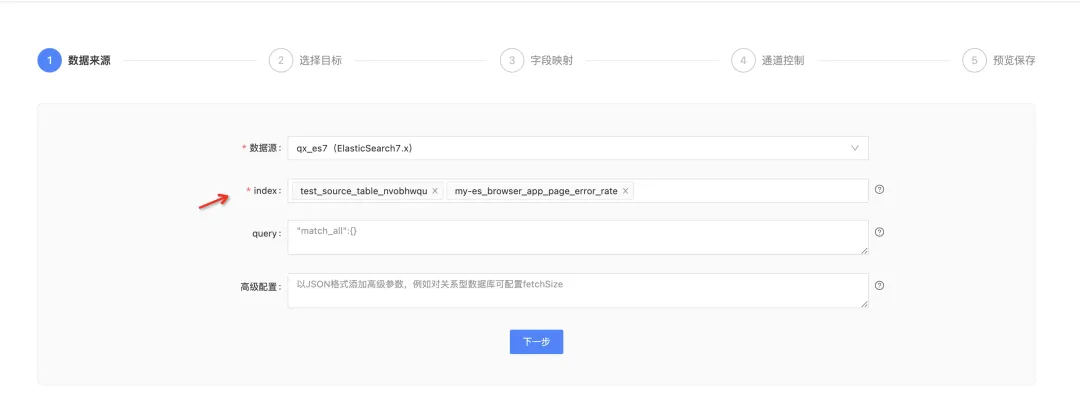
5.ES 數據同步優化
背景:存在多個 Index 同時向目標表進行寫入的場景。
體驗優化說明:讀取 ES 數據源時,支持批量多選 Index,降低了用戶的操作成本。支持地理位置欄位類型,地理標識欄位是 ES 常用的一個欄位,在欄位映射時支持數據轉換。
實時開發平臺
新增功能更新
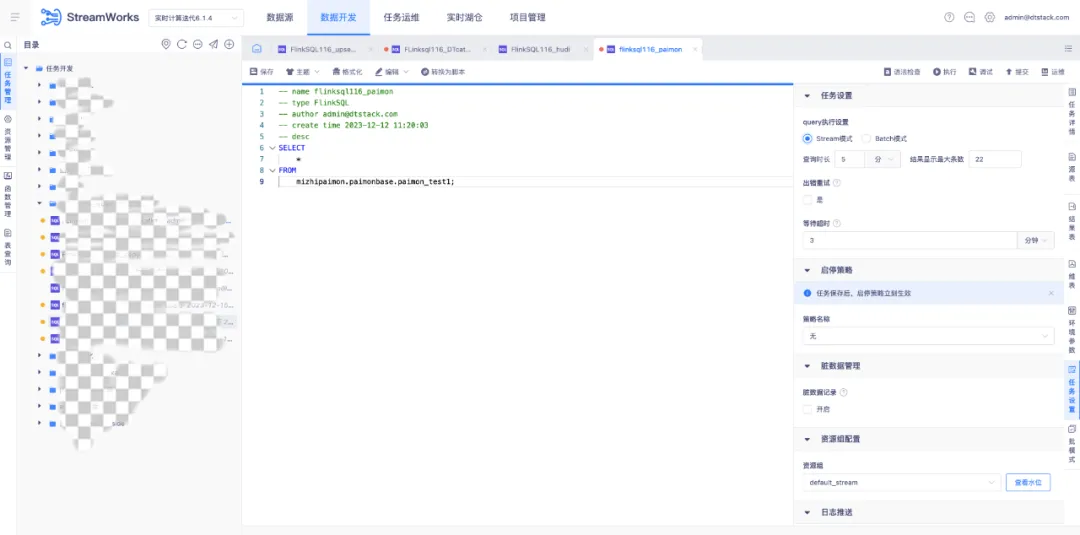
1.數據開發 SQL Query 支持 streaming、batch 模式選擇
背景:此前只支持 streaming 模式。
新增功能說明:針對 FlinkSQL 任務(1.16),任務設置中支持 Query 執行設置,可選擇執行方式為流模式或者批模式。
• 定義:任務以流模式查數據
• 查詢時長:將任務開始在 Flink 引擎上執行,作為計算起點,當查詢時間達到此處設置上限時自動停止查詢
• 結果最大顯示條數:當查詢到的數據條數滿足設置值時,數據總量不再增加,新的數據覆蓋最早的數據
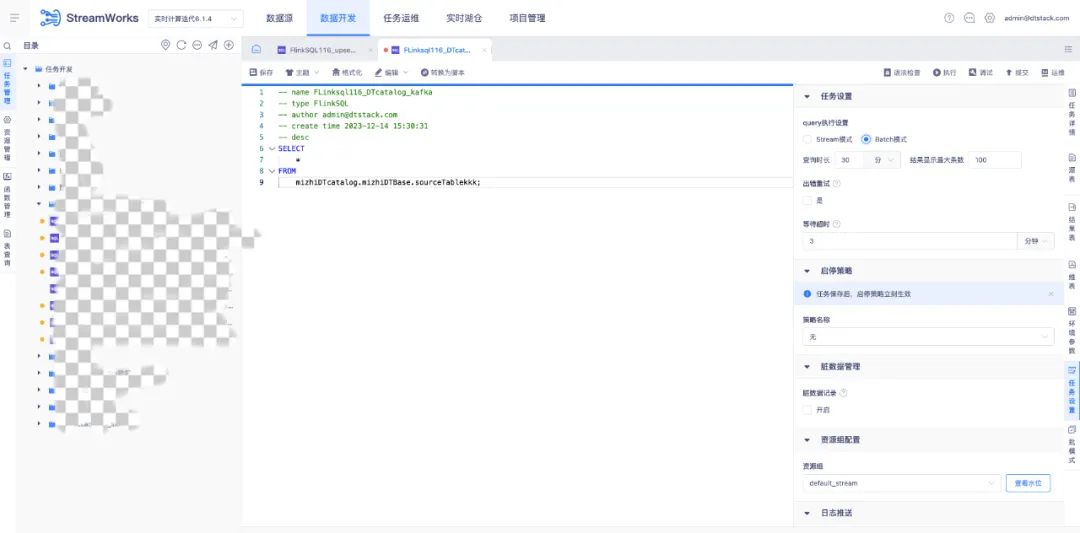
「Batch 模式」
• 定義:任務以批模式查數據,數據查完後暫存,一次性返回至平臺展示,支持結果下載,下載功能同 stream 模式
• 查詢時長:查詢時間達到此處設置上限時自動停止查詢,若在此時間內數據返回結束則列印結果,否則結果為空
• 結果最大顯示條數:查詢/下載結果上限為此處設置的條數
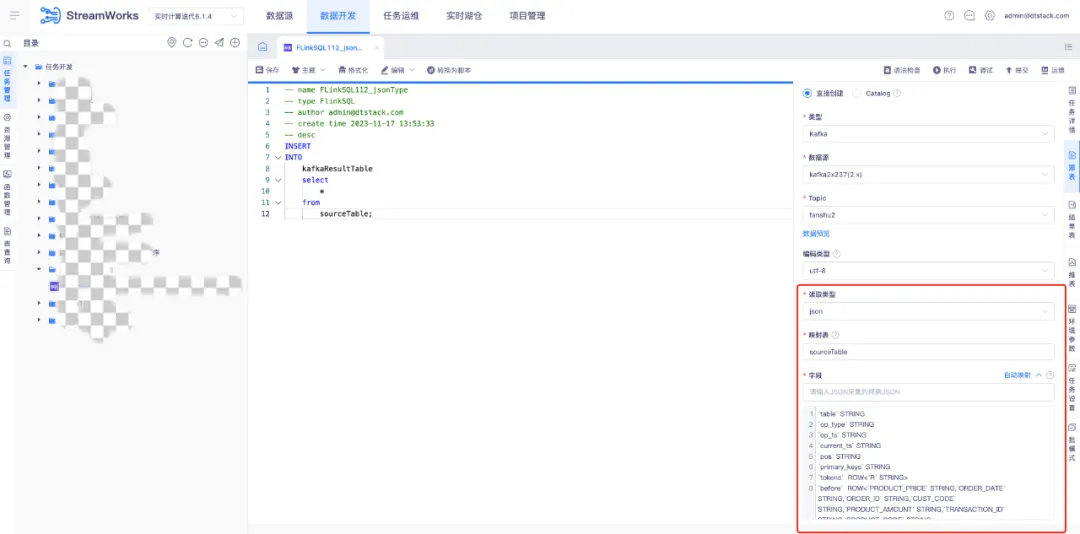
2.數據開發 kafka 格式新增 attunity json
支持基於 Attunity json 的讀取類型採集/輸入樣例數據,自動映射 Flink 表。使用 json 平鋪解析的方式可以通過添加自動映射功能來實現,從而滿足需求。
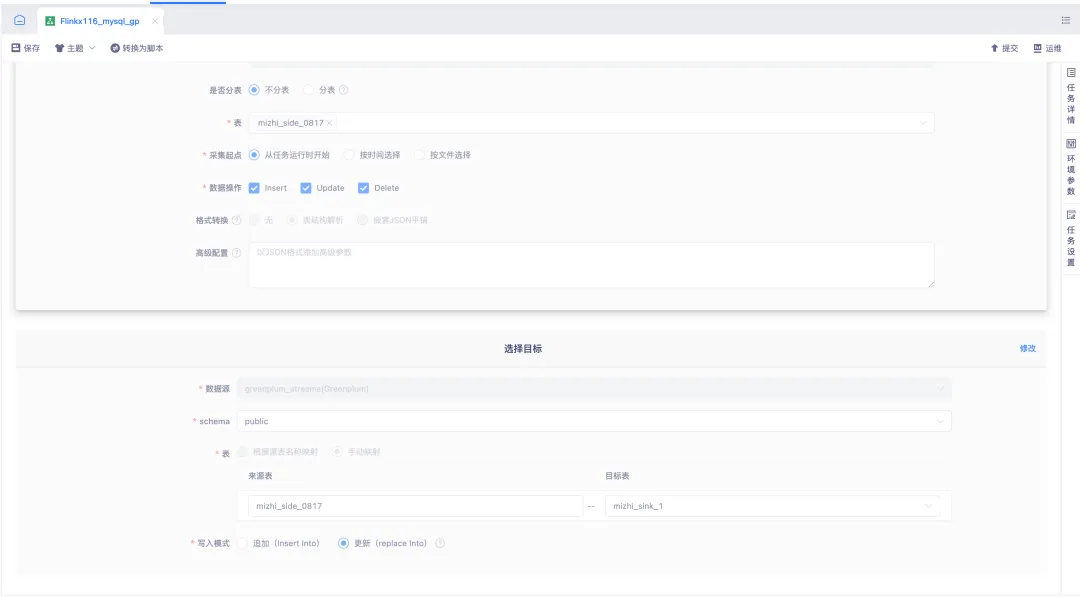
3.實時採集嚮導模式結果端支持 gp
實時採集1.12&1.16版本支持 Greenplum 目標表寫入能力,為用戶提供了更加靈活和高效的數據處理能力。
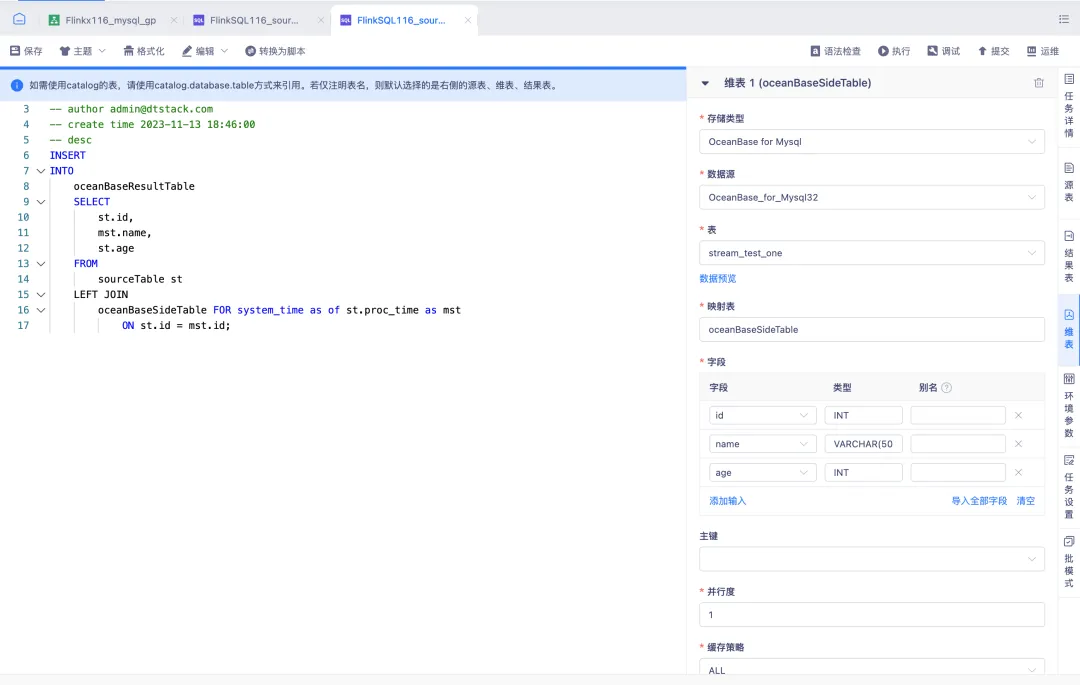
4.FlinkSQL 維表支持 OceanBase
FlinkSQL1.16 版本支持 OceanBase 維表讀取能力,為用戶提供了更加靈活和高效的數據處理能力。
5.實時湖倉通過後端文件配置控制湖表的展示和其他操作
背景:用戶對實時湖倉表管理中表的範圍提出需求,此前實時湖倉不支持展示在其他平臺或底層創建的表,並需要對錶的增刪改查操作設置許可權限制。
新增功能說明:
• 優化實時湖倉獲取 HMScatalog 元數據的方式
• 通過配置項參數,控制 IED 編輯 SQL 和湖倉管理-表展示的範圍、控製表操作的範圍,當前配置項僅針對 HSMCatalog
• 優化表管理 Catalog 展示性能問題
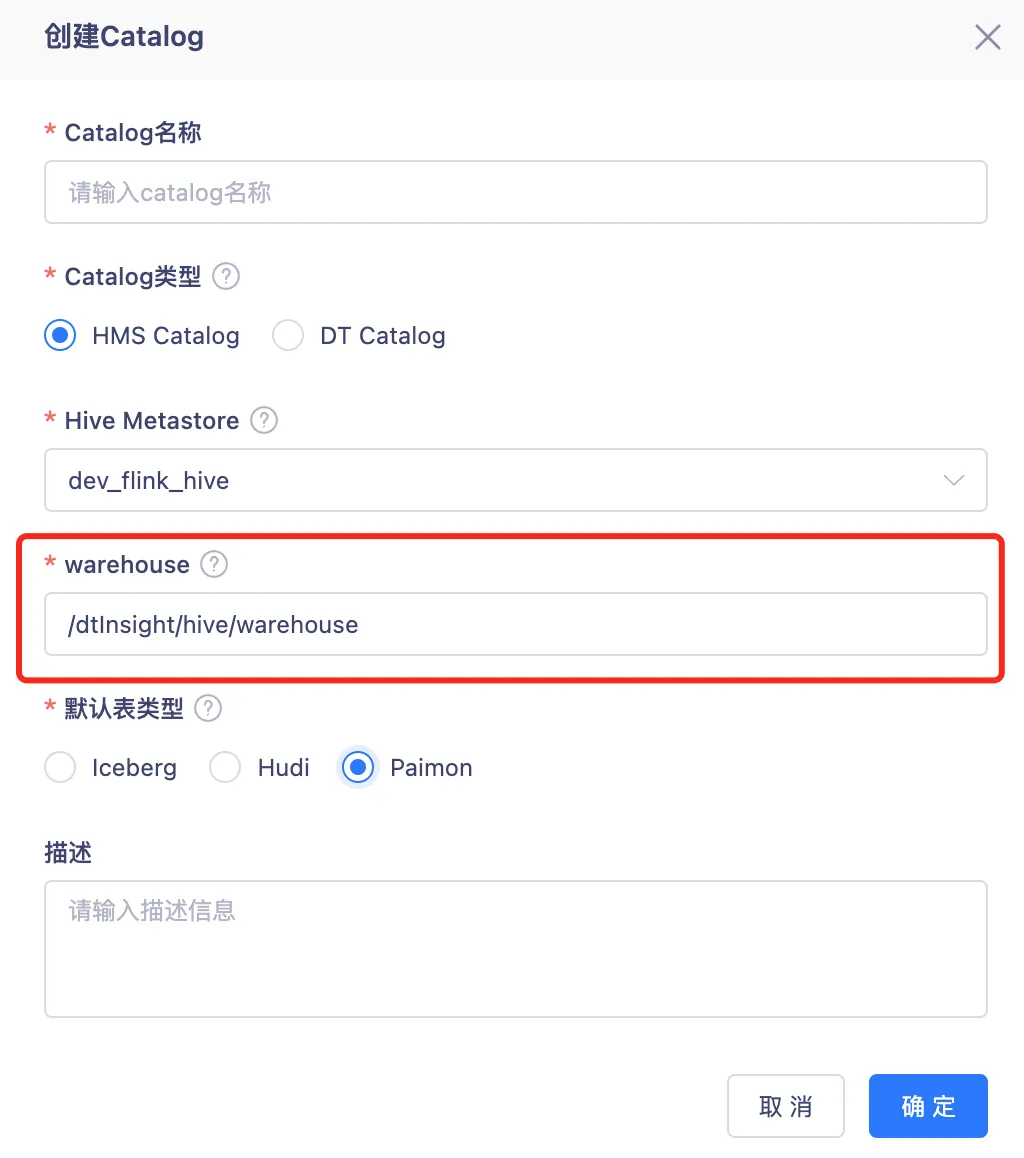
6.實時湖倉 HMSCatalog 創建增加 Warehouse 參數
背景:當前不支持在創建 HMSCatalog 時配置 Warehouse 地址,只能使用預設的地址,且不做展示。
新增功能說明:增加必填 Warehouse 項,回填 hive-site 文件內 Warehouse 地址,湖倉創建 catalog 時可以指定存儲路徑而不是按預設的路徑進行存儲。
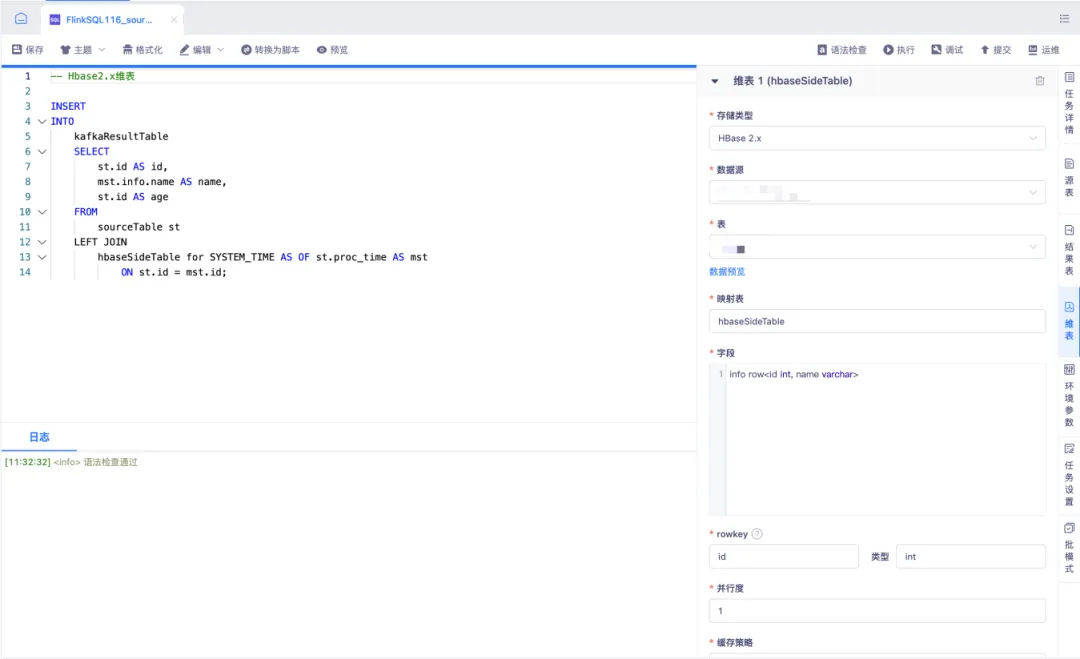
7.版本適配和支持
• 實時湖倉 Hive 適配 CDH6.2.1 對應的 Hive 2.1 版本
•實時湖倉 FLinkSQL1.12 支持運行 DTCatalog 和 IcebergCatalog
• 實時計算平臺支持 Hbase2.x 數據源作為 FLinkSQL 維表且版本支持1.16
8.數據開發頁面支持高級檢索方式
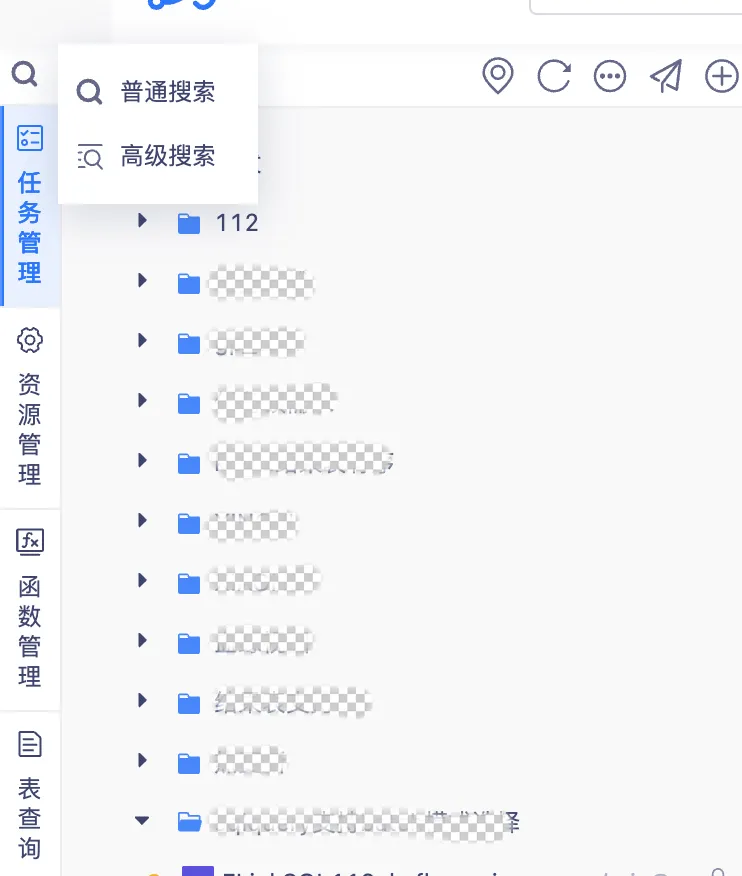
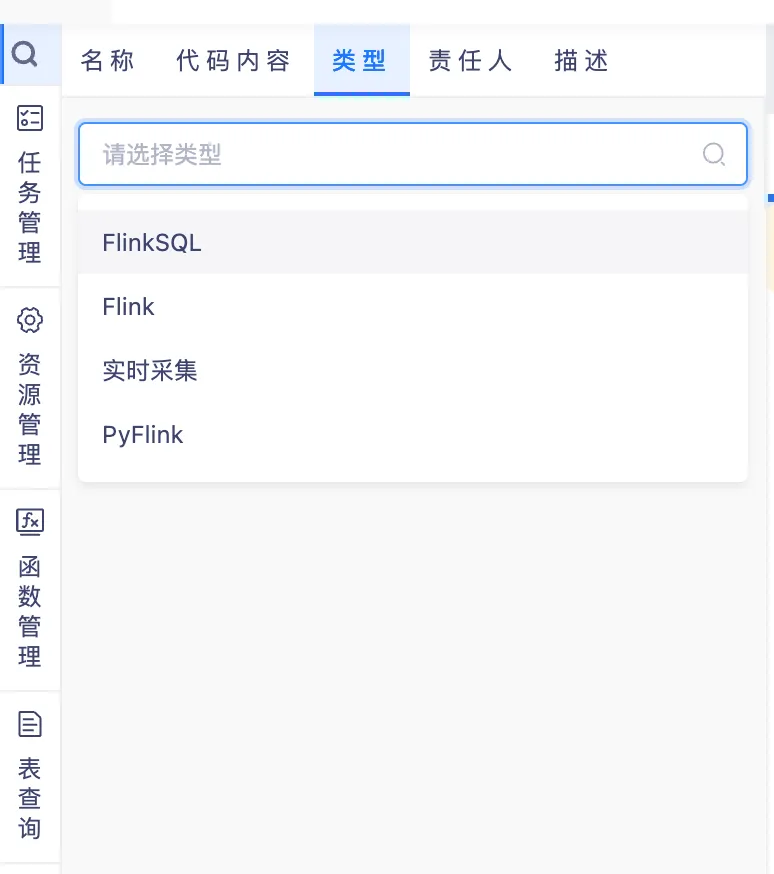
背景:此前的搜索不區分具體的查詢類型,導致查詢效率低下。
新增功能說明:數據開發頁面新增支持高級檢索方式,如支持代碼檢索等功能,同時增加支持根據代碼內容搜索相對應的任務,提高搜索的實用性。
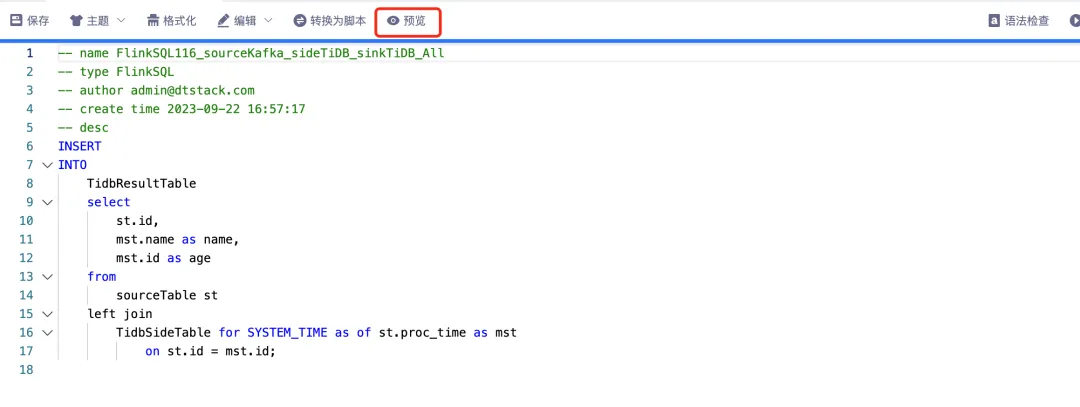
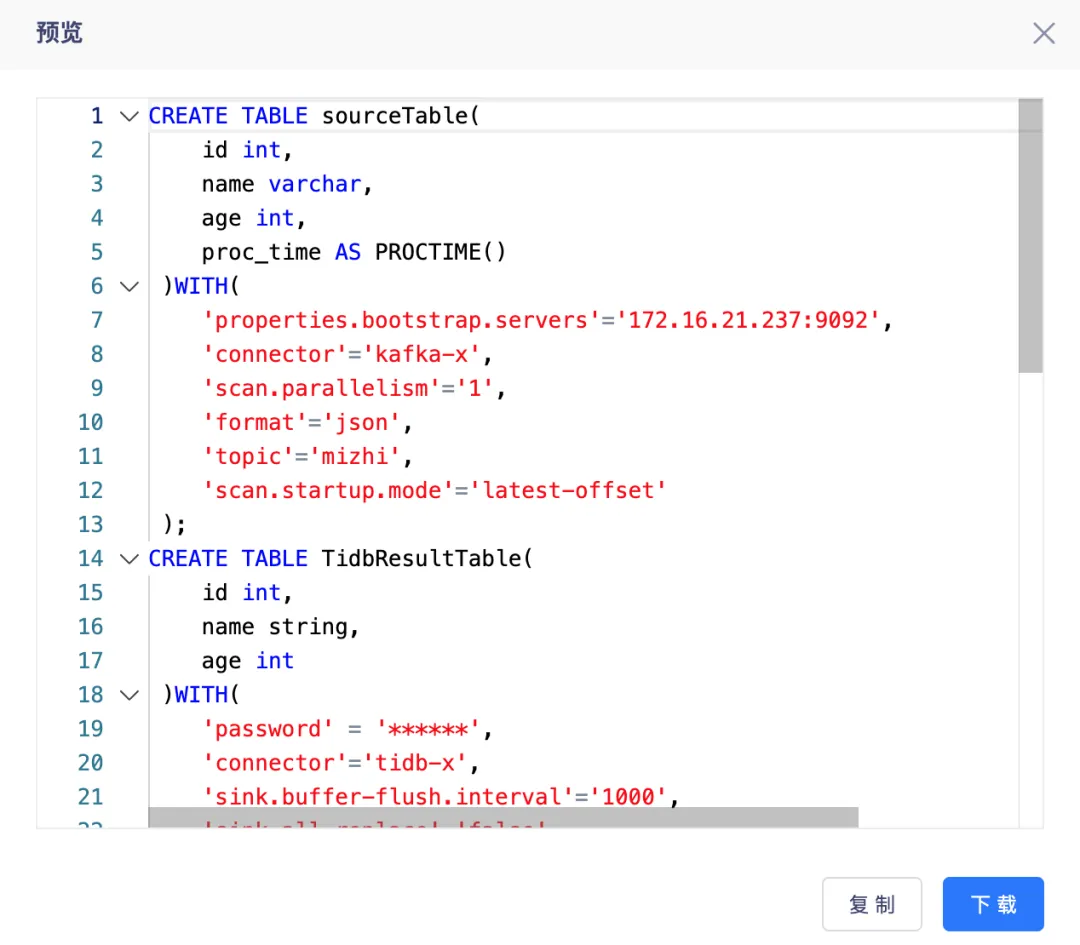
9.FlinkSQL&實時採集嚮導模式增加腳本預覽功能
FlinkSQL&實時採集嚮導模式增加腳本預覽功能,前端支持功能包含:搜索、複製、read-only、下載。
10.欄位自動補全功能
背景:數據開發在編寫 FlinkSQL 時,從當前的拓撲圖編寫中無法得到具體的一些欄位信息。
新增功能說明:
• 實時計算數據開發眾的 FlinkSQL,支持源表、維表、結果表欄位在 SQL 編輯器 IED 編輯時的欄位自動補全功能,提高開發 SQL 的效率
• 支持嚮導模式和腳本模式
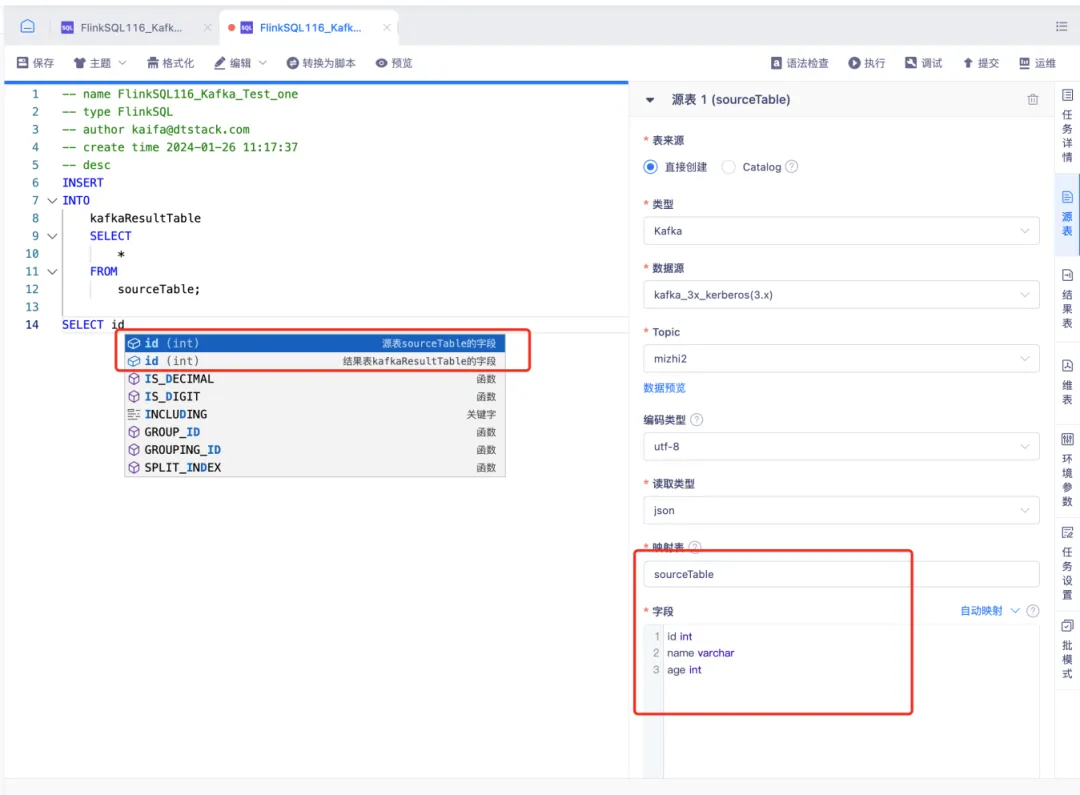
11.適配 kafka3 且支持 kerberos 認證
• 支持 FlinkSQL1.16 版本作為源表、結果表
• 支持實時採集1.16版本作為來源表、目標表
• 支持開啟 kerberos 認證方式
• 支持實時湖倉 DTCatalog 作為源表、結果表
• 支持調試運行
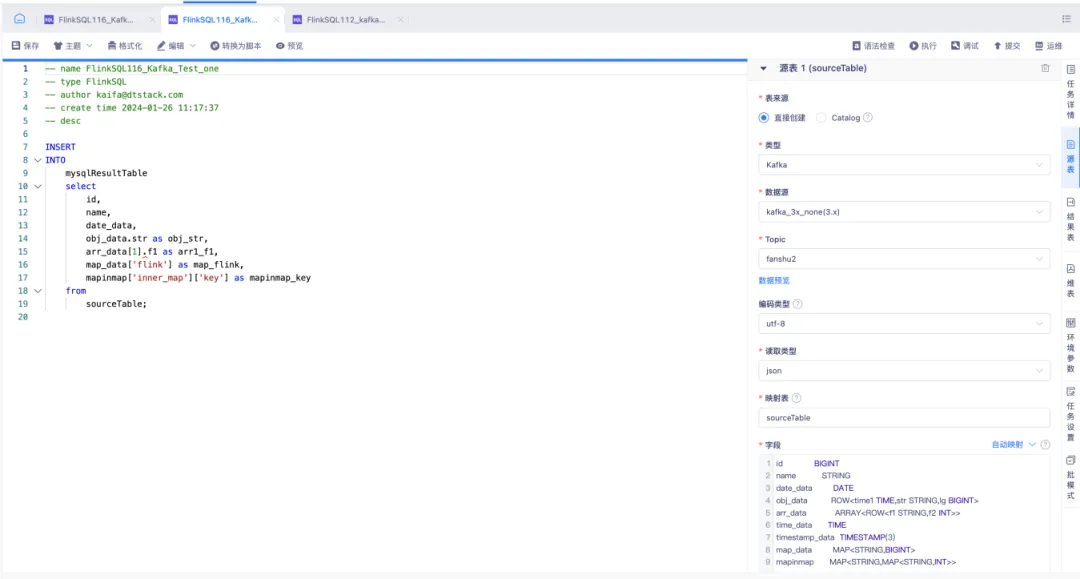
功能優化
1.任務運維實時任務並行度修改的熱更新
背景:在修改環境參數中的任務並行度參數後,為保證儘快生效,平臺會自動停止任務後重啟,這讓實時任務有了一個停止時間,重啟耗時會比較久。
體驗優化說明:在修改任務並行度參數後,不需要停止任務,提交後可直接生效,需要引擎出方案修改。支持熱更新的參數如下:
• FlinkSQL 插件參數:維表 all 改為 lru、查詢超時時間
• Flink參數:並行度、checkPoint 參數
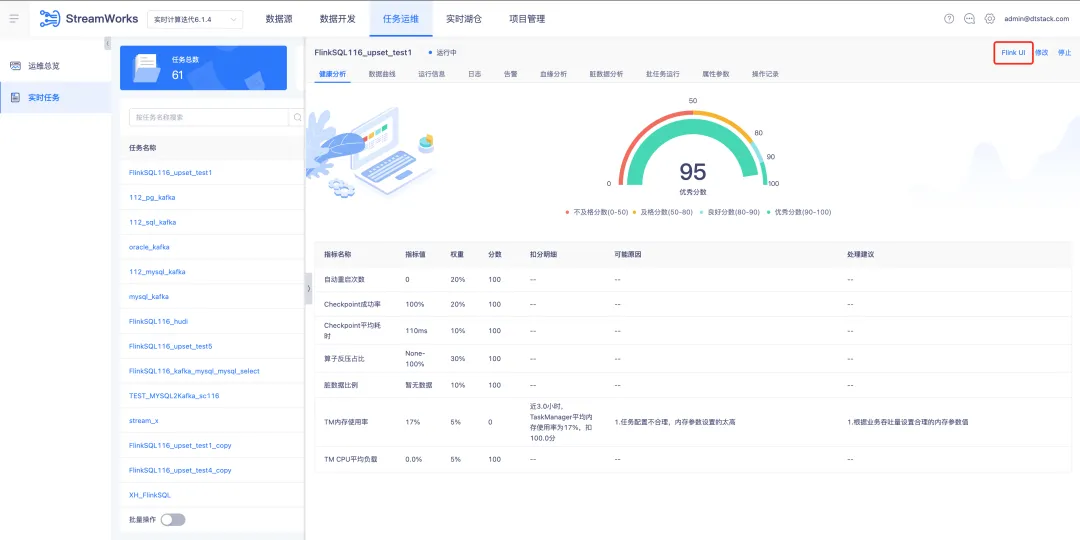
2.任務運維任務支持跳轉 FlinkUI
背景:Flink Dashboard 展示了一些平臺沒有展示的運行及日誌等信息,對有經驗的數據開發來說更方便排查問題。
體驗優化說明:實時計算所有“運行中”狀態(實際非 application 運行中,需要 job 運行中才能跳轉成功)的任務的運維頁面在下圖位置顯示 FlinkUI 跳轉入口。
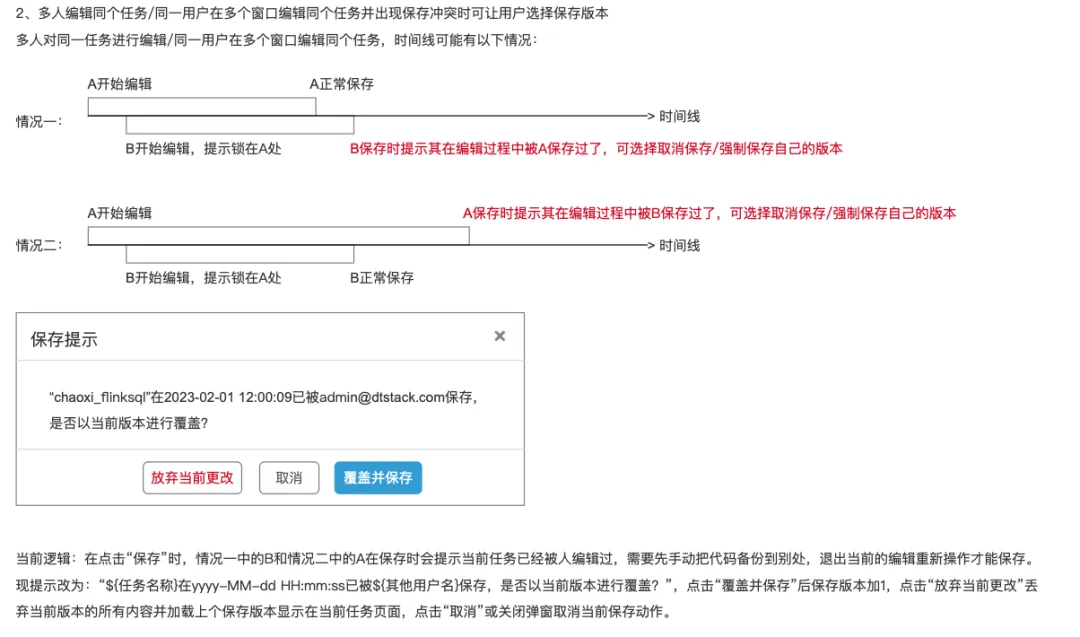
3.數據開發任務鎖覆蓋邏輯優化
背景:目前同一用戶在兩個視窗同時編輯任務時,A視窗先保存,B視窗再次保存時,覆蓋邏輯預設A覆蓋B,會導致後保存版本內容丟失。
體驗優化說明:任務鎖覆蓋邏輯優化
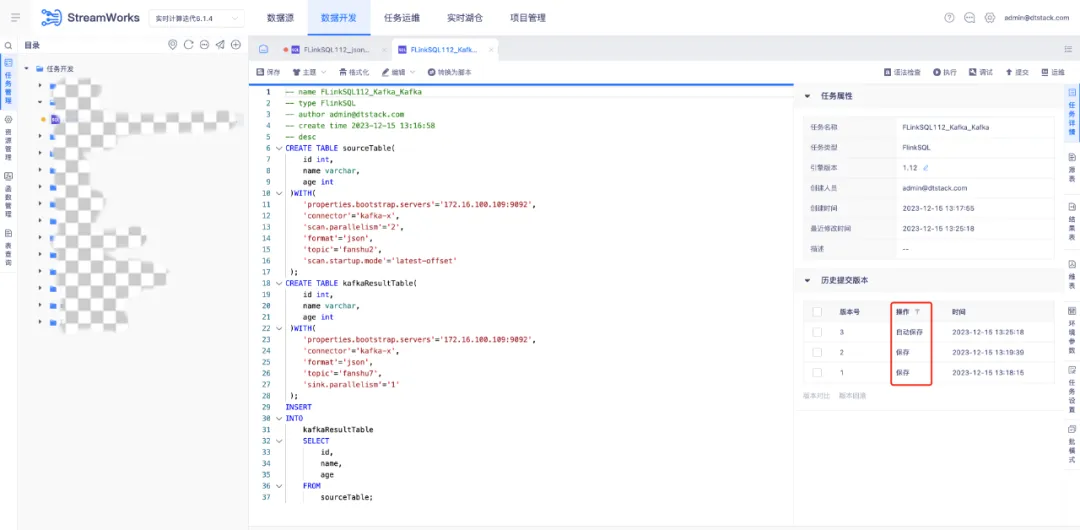
• 版本記錄增加保存版本,平臺異常登出時自動保存任務
• 多人編輯同個任務/同一用戶在多個視窗編輯同個任務並出現保存衝突時,可讓用戶選擇保存版本
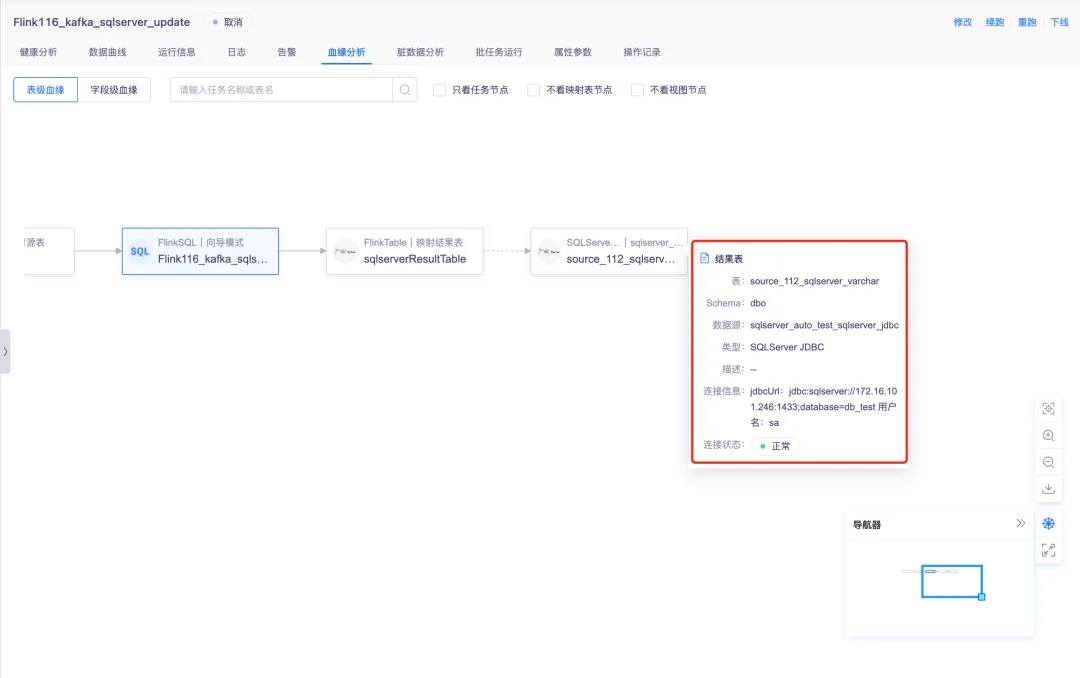
4.任務運維血緣節點信息優化
針對 FlinkSQL 和實時採集任務,表級血緣圖中的源表、維表與結果表的節點,點擊時顯示數據源信息,對交互與任務的詳細浮窗不一致問題進行優化。
5.實時開發選擇資源時,直接根據任務類型限制能選擇的資源類型範圍
背景:需要通過資源創建的任務類型,在創建時應有校驗資源類型是否選擇正確的功能,而不是在選擇資源時直接根據當前任務類型進行可選資源範圍過濾,導致錯誤提示滯後,增加用戶誤操作成本。
體驗優化說明:選擇資源時直接根據任務類型限制可選範圍,其餘不可選的資源類型在下拉時置灰無法選中
• Flink 可選範圍為 jar
• PyFlink 可選範圍為 py 文件
6.任務信息清理
背景:
• 某個任務由於業務變更需要修改邏輯或在較長的一段時間內不需要執行時,在任務運維列表中還持續存在會造成信息干擾,需要進行下線操作,和提交形成逆向的操作閉環
• 任務下線後可能隔斷時間會重新提交,也可能很長一段時間內不會再次提交,目前所有任務的 cp sp 信息都保留會導致無用文件的堆積,任務刪除時任務相關的信息更需要完整刪除
• on k8s 的任務在 jobgraph 創建之前被取消或異常失敗不會被清理,只有在正常結束或者 jobgraph 調度之後再被取消才會正常清理;on yarn 的任務,如果任務 cancel 會刪除數據,但是如果直接 kill application 則不會刪除 zk 數據,同樣會導致無用文件的堆積
體驗優化說明:
• 實時開發任務下線後可選擇清理 check point、save point 信息,任務異常狀態時清理 zk 信息
• 任務下線時可選擇清理運維記錄及日誌數據,任務刪除時自動刪除運維記錄及日誌數據
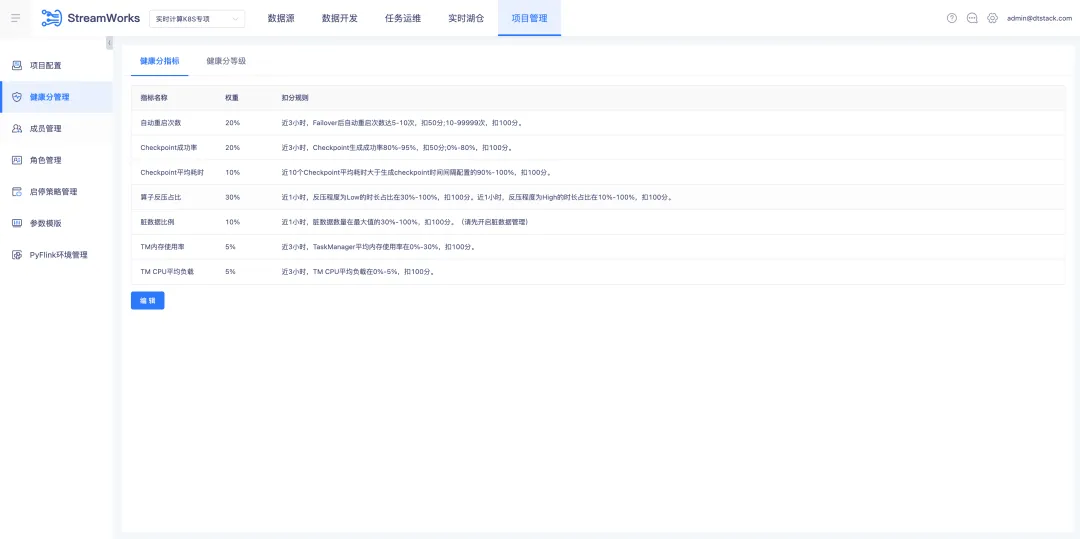
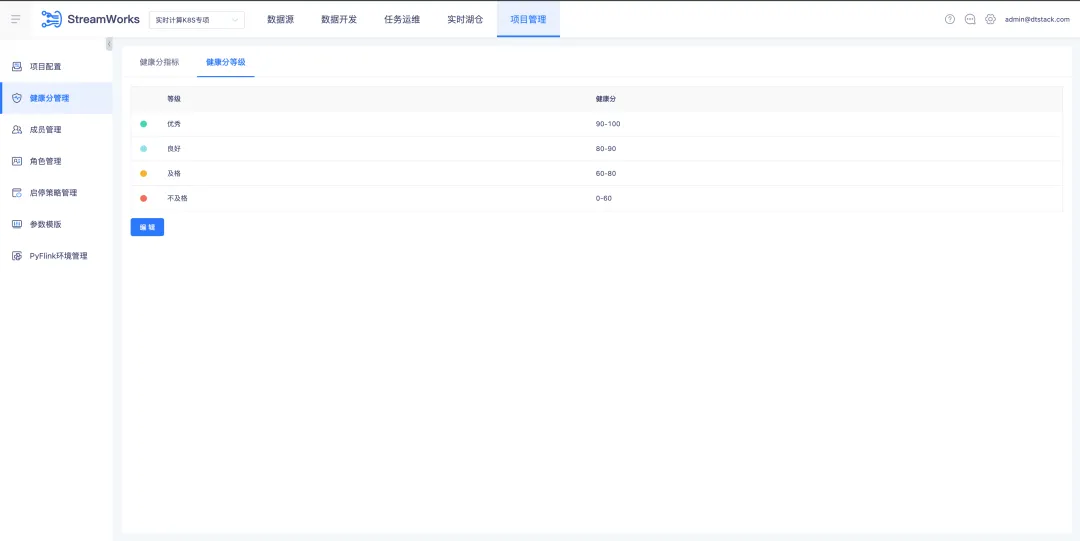
7.健康分優化
項目管理導航欄下新增【健康分管理】子頁面,裡面分為【健康分指標】(預設展示)和【健康分等級】兩個 tab。
8.前端改造
• 將 React Router 從 v3.x 升級到 v6.x
• 對前端易用性性能進行改造,改進首屏性能,通過易測做量化,改進 FPS 場景任務
9.嚮導模式下 AS 別名隱藏
歷史版本的1.10支持維表 AS 別名,後續在1.12及以上使用 Flink 語法則不支持。為防止使用上出現問題,將嚮導模式下別名隱藏,修改後欄位和類型的顯示跟結果表保持一致。
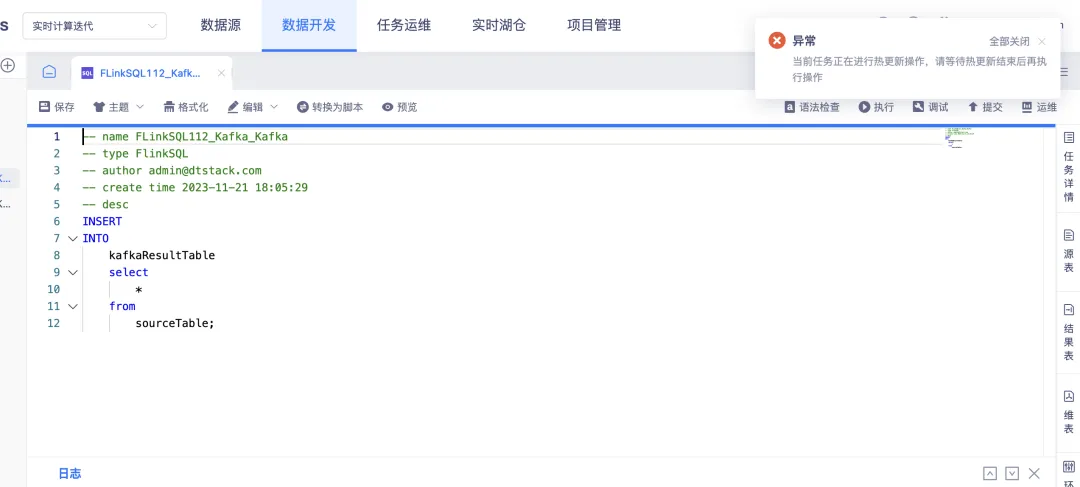
10.實時開發任務熱更新優化
背景:此前版本對熱更新未做狀態限制,存在正在熱更新的任務重覆提交熱更新的操作。
體驗優化說明:
• 通過後端對任務熱更新狀態的判斷,正在熱更新的任務無法重覆的提交熱更新操作,將給出提示:當前任務正在進行熱更新操作,請等待熱更新結束後再執行操作
• 調度增加任務運行狀態,可以通過狀態進行判斷
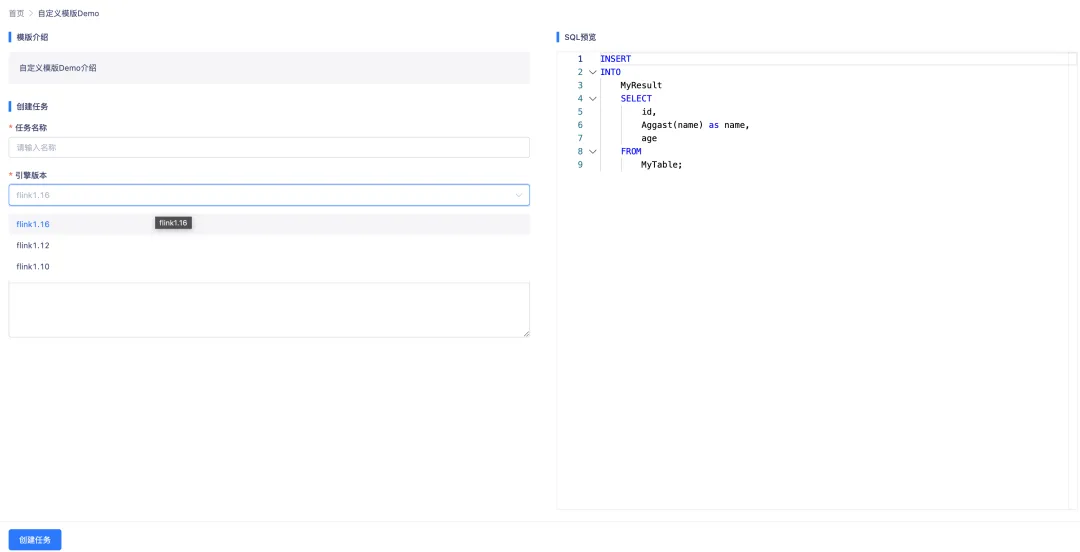
11.自定義模版創建任務時取消引擎版本限制
背景:此前的自定義模版,只支持 Flink1.16 版本使用,限制了模版的使用版本,6.0的用戶存在低版本未升級到1.16的情況,就無法使用此功能。
體驗優化說明:自定義模版創建任務取消引擎版本的限制,同步支持了低版本也能使用此功能。
12.任務開發頁面優化
背景:任務開發時,點擊保存,頁面會自動跳回至頂部,打亂開發節奏,無法定位上一次編輯的位置。
體驗優化說明:數據開發在使用任務開發頁面編輯 SQL 腳本不需要從頂部開始往下滑動,可以直接停留在保存的位置。
數據資產平臺
新增功能更新
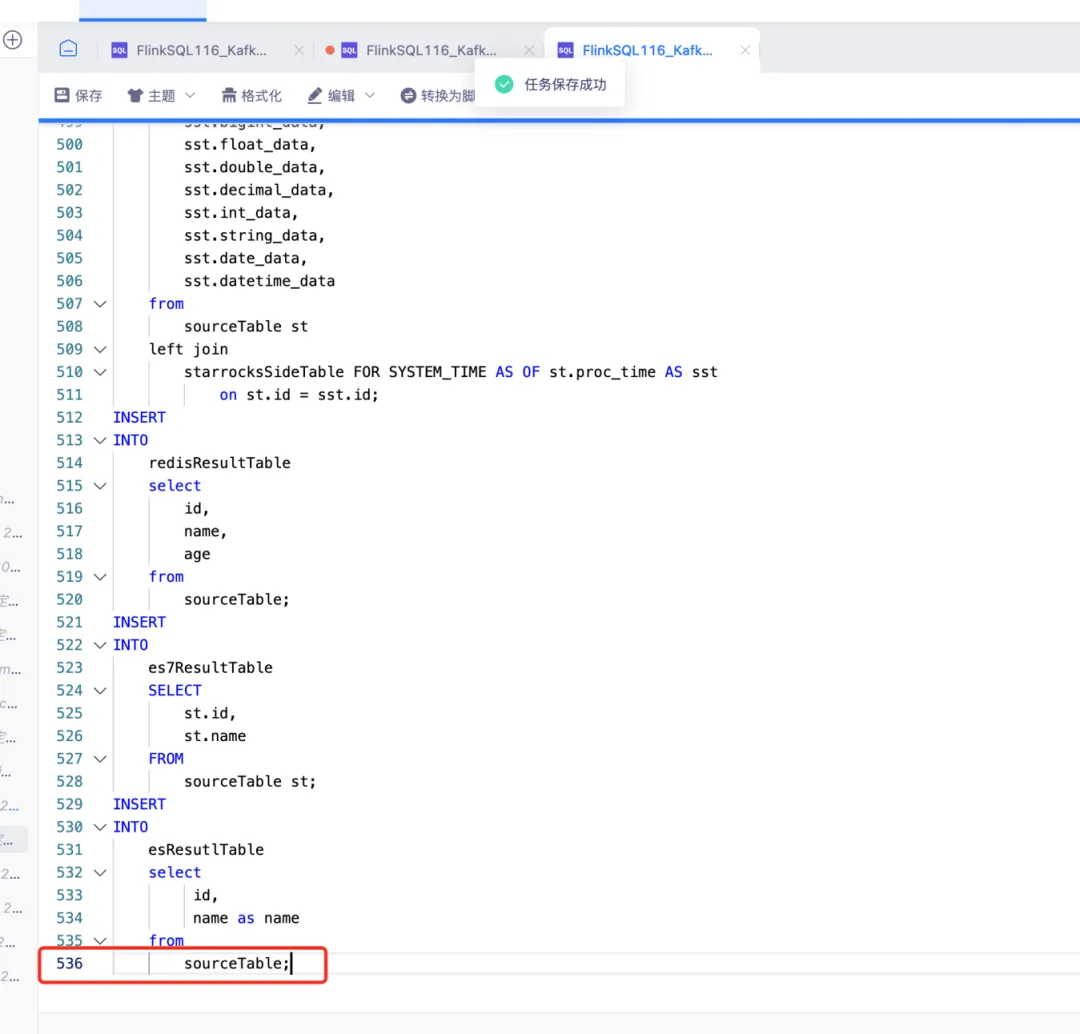
1.平臺層數據許可權管理,包含表級、行級、列級許可權的授予與申請
• 支持進行數據許可權的配置,可配置數據許可權範圍、生效用戶
• 支持按照庫、表、行、列維度進行數據許可權的配置
• 支持表級許可權的申請(擴充行、列許可權的申請),申請通過後,在許可權配置的頁面,自動為此用戶所在的用戶組,添加這條許可權信息
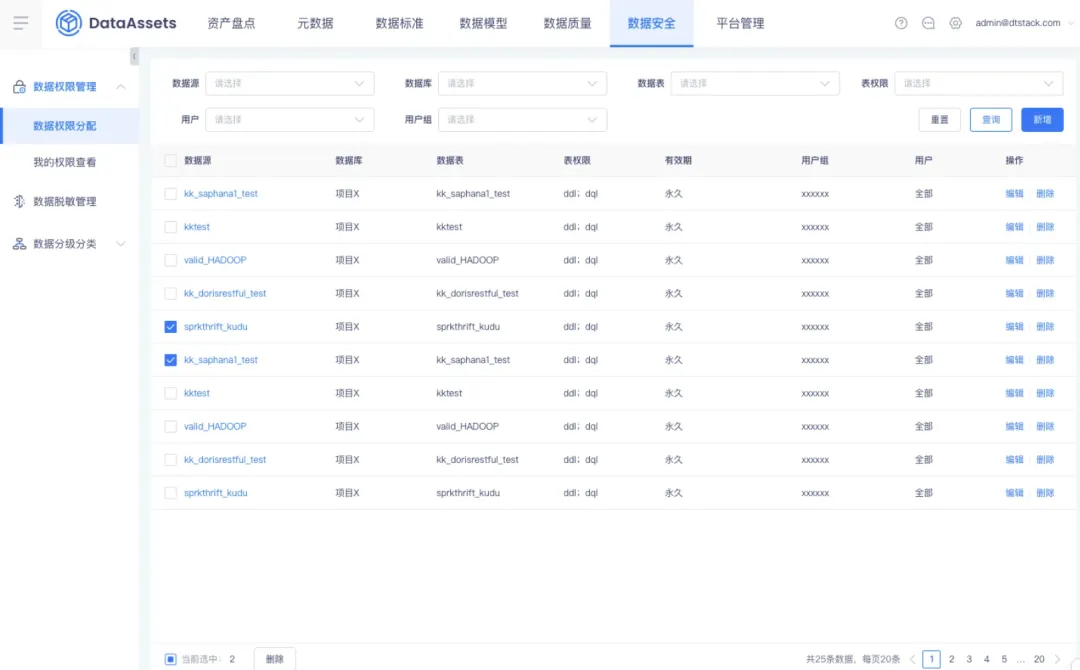
2.移除用戶時需進行用戶許可權轉讓
背景:當人員離職時,需支持自動交接;在移除產品操作時需要進行用戶信息校驗;若已經負責了數據治理模塊的具體項目,有關聯的待處理問題、通知信息配置,需要進行提示,並要在進行許可權轉讓後再移除產品。
新增功能說明:在用戶被移除的時候,增加許可權交接功能,包括告警配置、許可權信息等信息的交接。
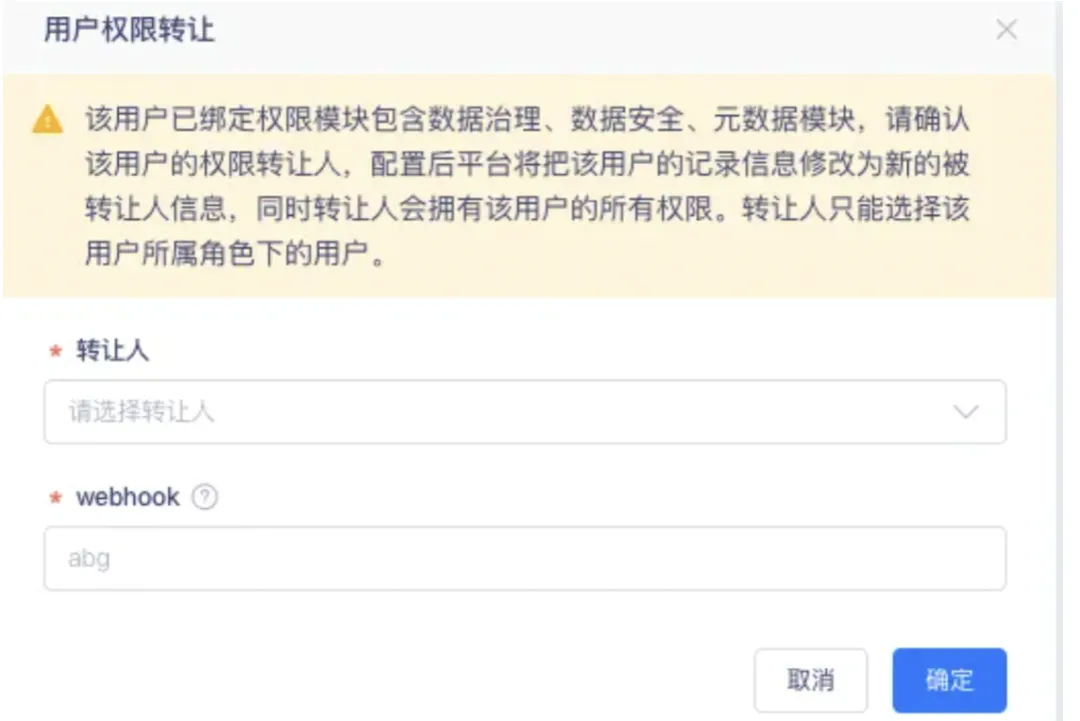
3.oushudb/oracle 類型數據源支持視圖同步
4.數據表質量校驗支持質量評分
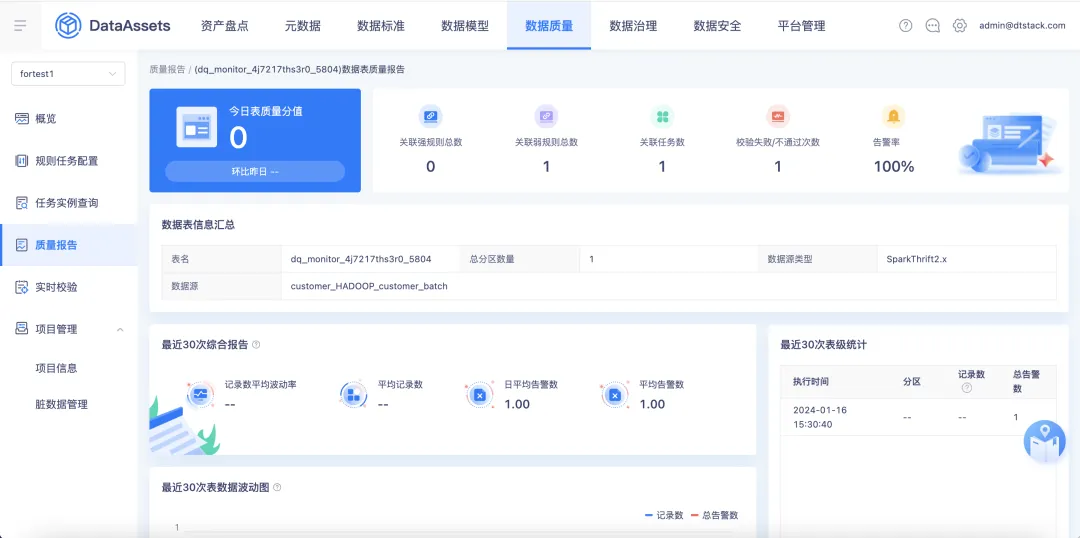
支持針對單表校驗的表級質量報告分析,包含表質量評分、質量分值變化趨勢、質量評估概覽、近期規則校驗異常明細、近期校驗結果;質量概覽頁面新增針對單表校驗下各個數據表的表級質量分排名。
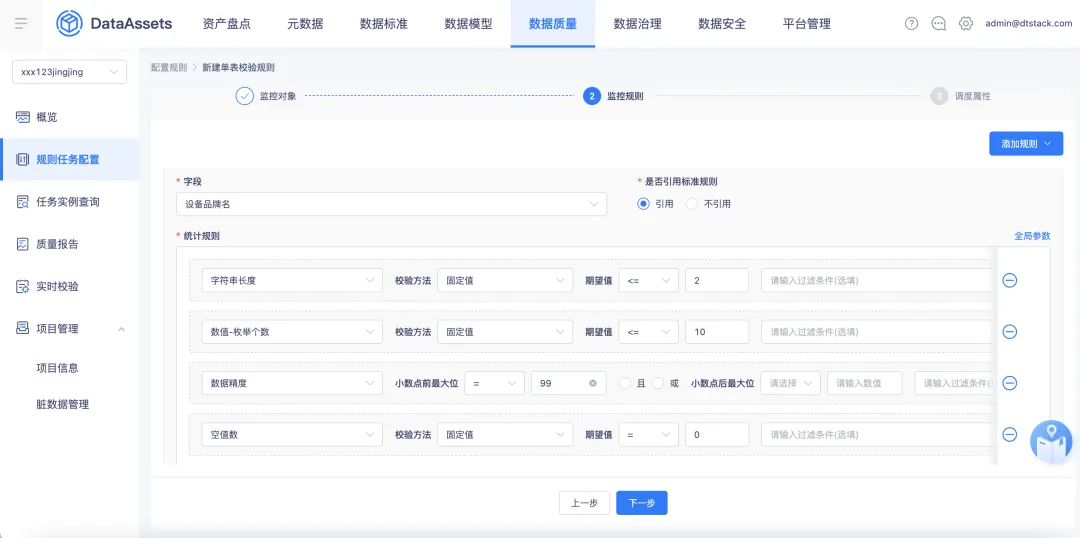
5.對接數據標準自動創建質量規則
背景:當出現數據質量的規範性校驗和數據標準設定規則基本一致時,優化數據質量的規範性校驗規則設計邏輯,支持與數據標準對接。
新增功能說明:在創建數據質量的規範性校驗規則時,支持自動對接數據標準來生成質量規則。當【數據質量規則】的【規範性規則】創建時,若識別到選擇的欄位為綁定了標準的欄位,支持選擇是否引用標準規則。若選擇引用標準規則,則會根據標準中定義的長度、精度、枚舉個數、是否空值、是否重覆,自動生成質量校驗規則。
6.元數據周期同步增加資料庫過濾條件
• 元數據周期同步增加資料庫過濾條件
• 新增、編輯周期任務按鈕優化,調整為支持「新增」以及「新增並立即執行」兩個操作按鈕
• 元數據周期同步列表增加資料庫、數據表的展示
7.支持 tbds_hive 類型數據源
新增支持 tbds_hive 類型數據源,支持範圍包括元數據同步、血緣分析、數據地圖、元模型、元數據管理、元數據質量、資產盤點、數據安全(數據許可權)。
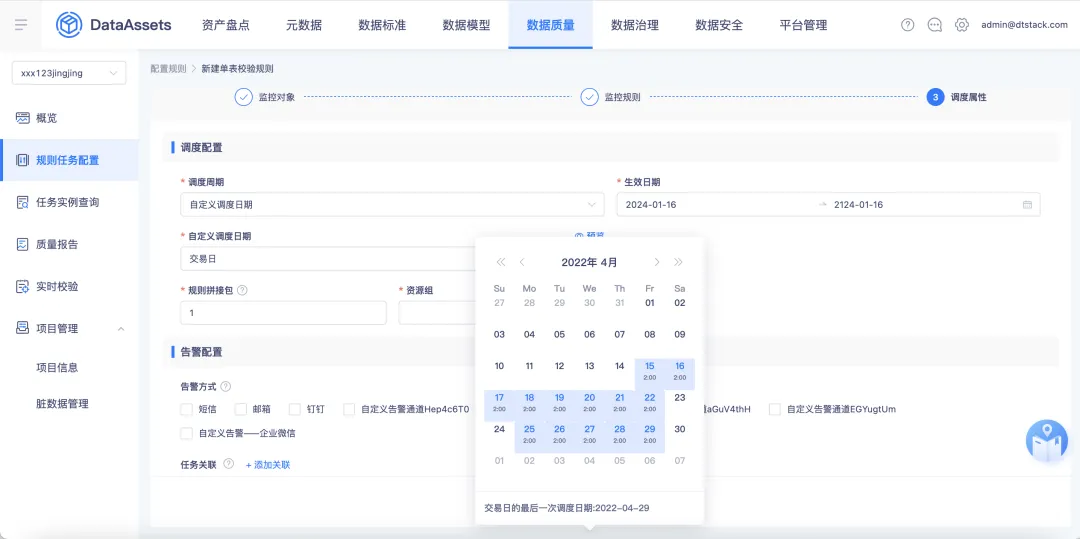
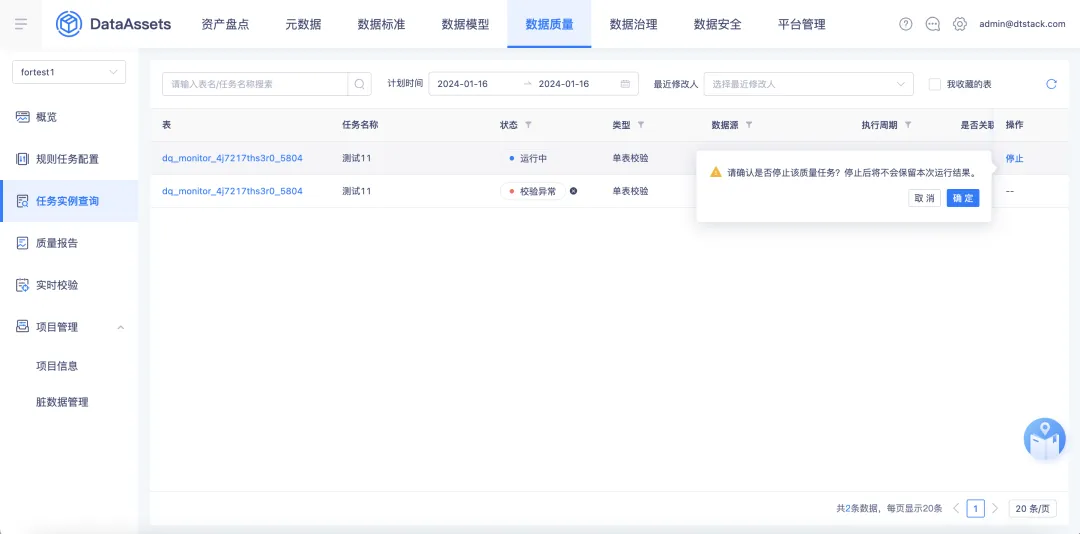
8.質量任務定時執行可以關聯自定義調度周期
背景:在配置質量規則時,無法關聯自定義調度周期進行質量任務的運行,導致需要個性化配置運行周期時無法滿足;在質量任務運行過程中,存在一個質量任務運行時間過長的情況,中途無法停止導致無法釋放資源。
新增功能說明:
• 質量規則創建時,在配置調度信息時支持關聯自定義調度周期,修改模塊包含新建/編輯單表校驗規則、多表校驗規則、規則集、查看規則詳情
• 質量規則創建後,在質量任務運行過程中支持中途停止操作
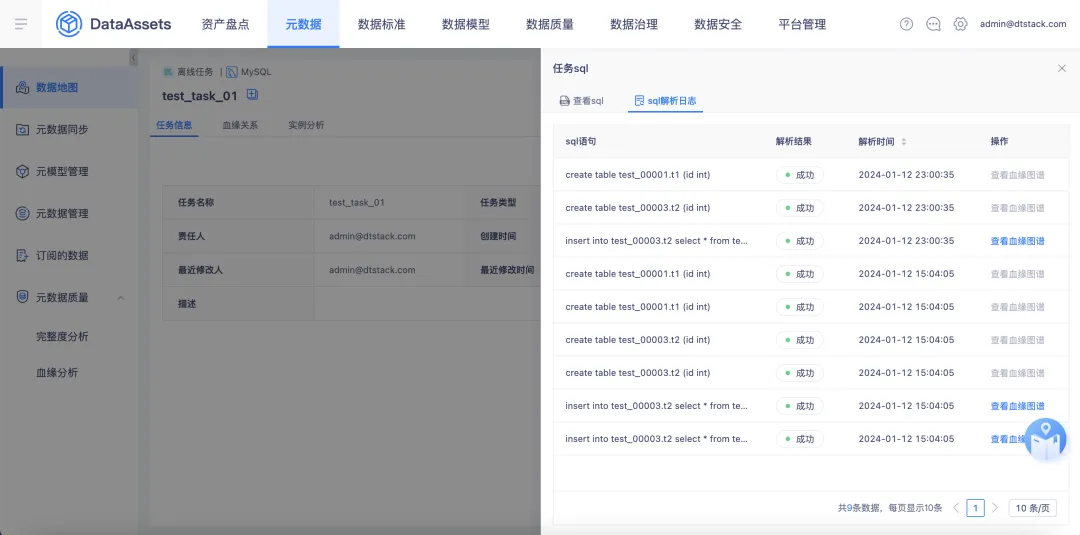
9.支持記錄每條 SQL 解析出的血緣關係
在【數據地圖】的【離線任務詳情】頁面,支持對解析 SQL 結果進行記錄,包含 SQL 語句、解析結果(成功/失敗)、解析時間。針對解析成功的可查看此條 SQL 對應的血緣關係圖譜(只展示表級圖譜),針對解析失敗的可查看日誌。
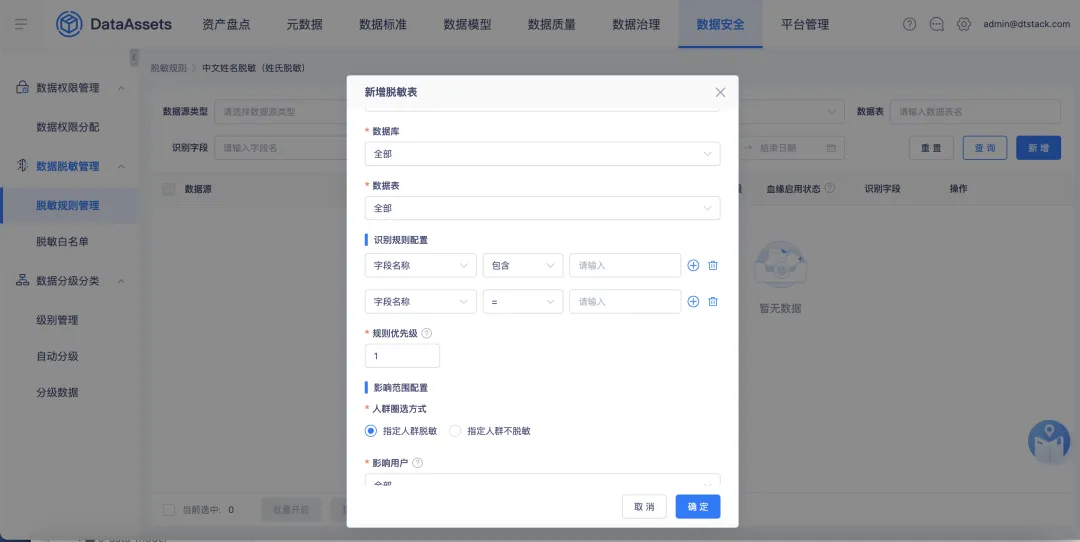
10.數據脫敏支持對識別規則的優先順序配置
• 在配置【脫敏規則】的【識別規則】時,支持擴充匹配符的選擇,新增「正則」、「包含」選項
• 在配置脫敏規則時,支持定義識別規則的優先順序,優先順序高的進行優先匹配,若優先順序衝突,預設按照最新配置的識別規則進行脫敏應用
• 支持進行脫敏白名單的配置,存在於脫敏白名單內的數據表預設不進行脫敏操作
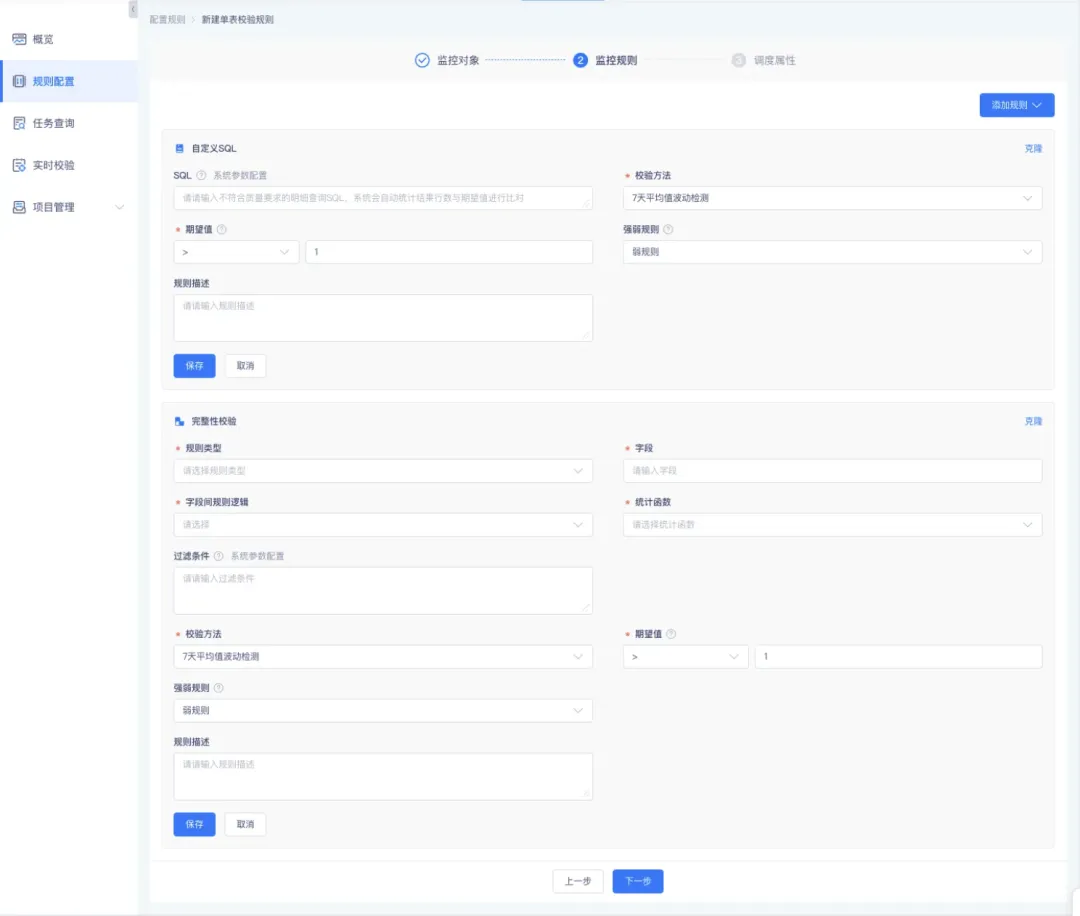
11.針對單表每個欄位可以批量生成校驗規則
數據質量管理模塊,可以批量配置規則。增加 or 或 and 篩選框,支持用戶配置檢驗規則,新增效果檢驗規則。
12.新增元數據的展示信息
• 在【數據地圖】的【表詳情】頁面,新增支持在數據表名下方展示表質量評分(若該表無質量評分則不展示),支持點擊數據質量評分後跳轉至【該數據表的質量報告】
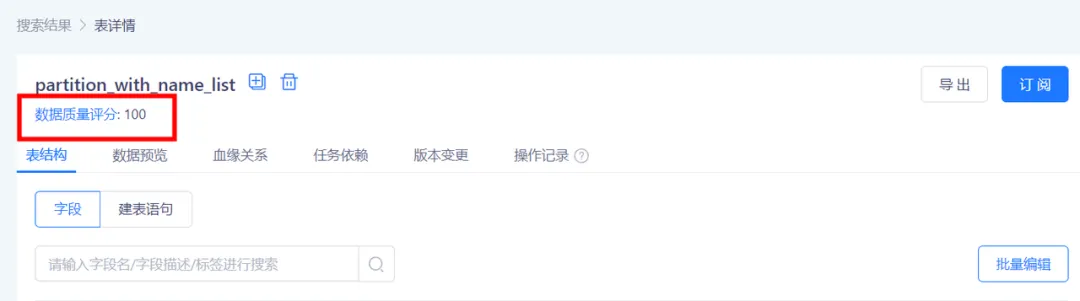
• 表信息新增熱度統計按鈕,並新增訂閱數、使用次數、查看次數、影響表數
• 針對操作記錄板塊新增 DML 操作記錄
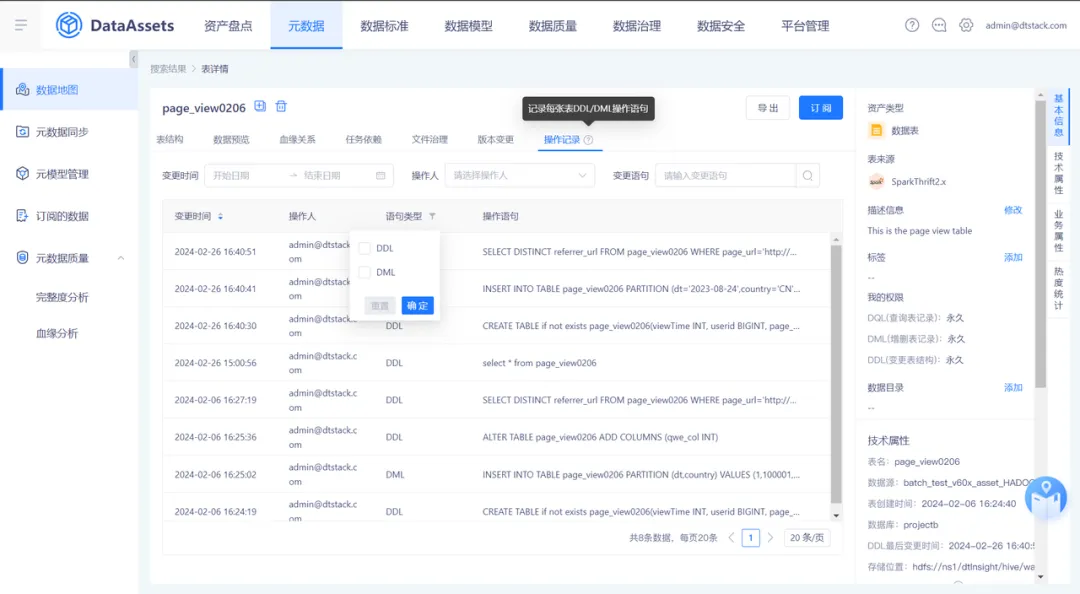
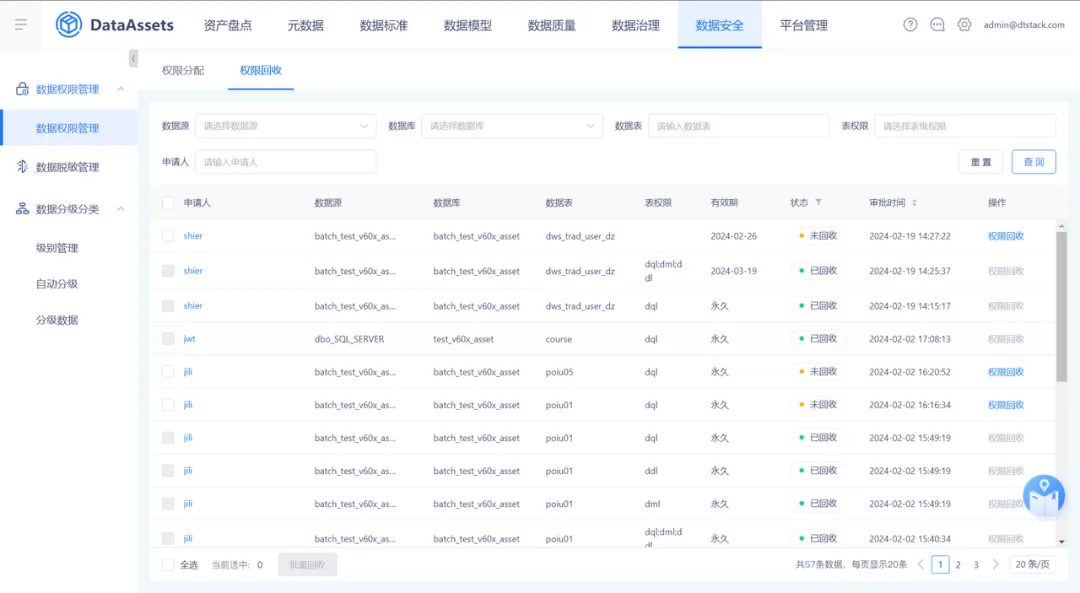
13.數據許可權管理新增許可權回收功能
在數據許可權管理頁面新增一個名為【許可權回收】的標簽頁,列表展示每個用戶自己申請且已經通過的許可權列表。管理員可以通過此功能刪除用戶的許可權信息,預設情況下,只有管理員具備許可權回收的許可權。
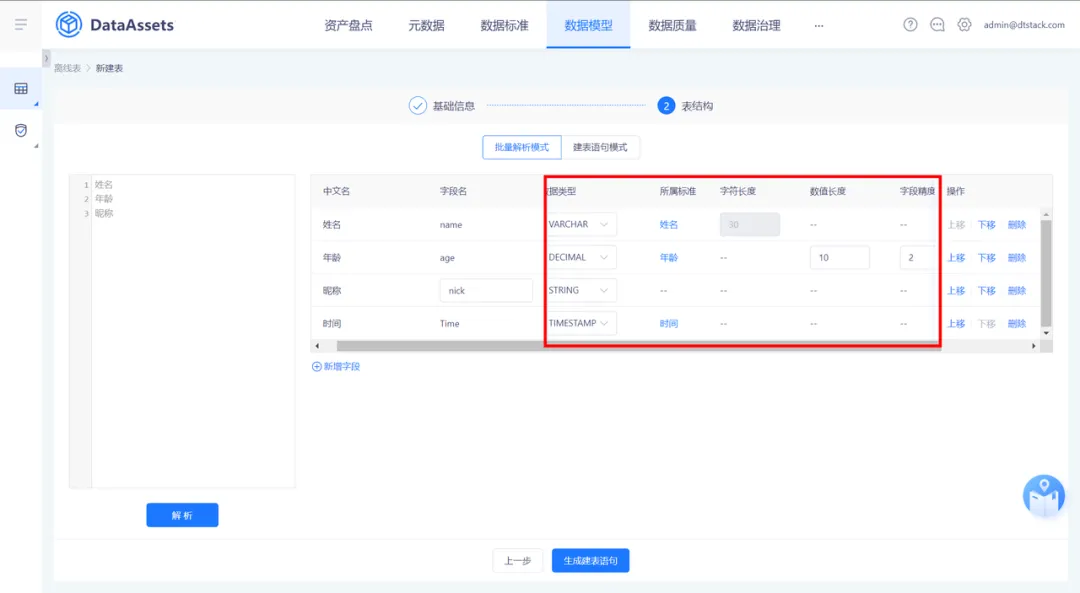
14.規範建表的嚮導模式配置內容擴充
• 嚮導模式配置內容擴充:
(1)針對 adb 類型建表支持配置欄位是否為主鍵、是否為空、精度值
(2)針對 inceptor、hive、spark 類型建表支持配置精度值
(3)inceptor 支持配置事務表/非事務表,支持指定 hdfs 存儲路徑
• 當數據標準中配置了長度、精度信息時,引用標準可自動同步
• 支持 hive3.x(Apache) 類型數據源的建表,建表邏輯和 hive2.x 保持一致
功能優化
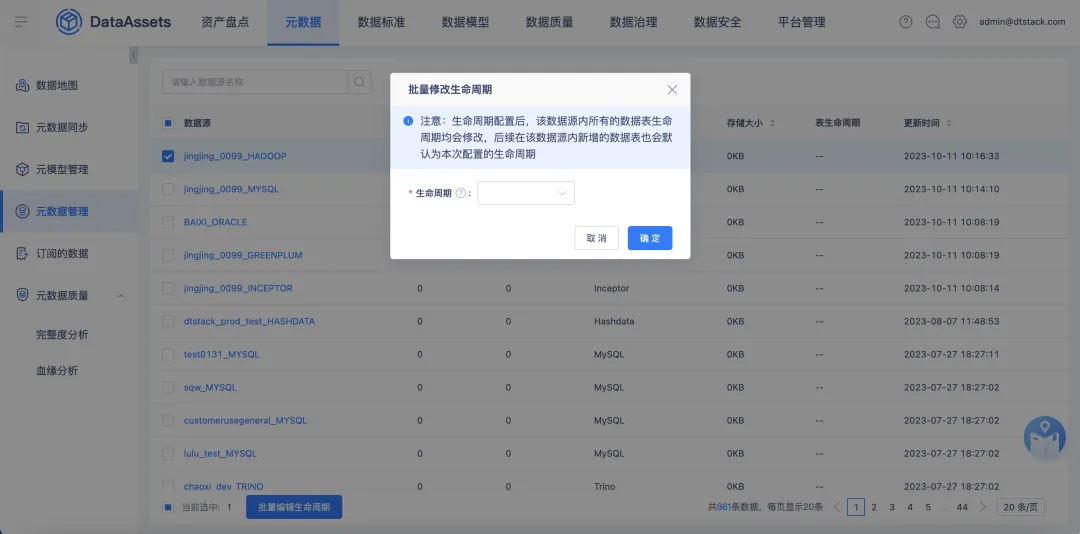
1.支持配置表生命周期
背景:此前沒有基於數據源、資料庫維度批量配置數據表生命周期的入口。
體驗優化說明:【元數據管理】頁面展示維度修改為「數據源」「資料庫」「數據表維度」,支持基於數據源、資料庫、數據表維度進行生命周期的批量配置。
2.表行數、存儲大小支持顯示更新時間
背景:若表行數、存儲大小為0,無法區分此表是空表還是沒有同步表行數/存儲大小,且有可能存在第一次同步了表行數/存儲大小,第二次沒有同步的情況,故需要記錄下最近的更新時間。
體驗優化說明:【數據地圖】的【數據表詳情】中針對錶行數、存儲大小支持顯示更新時間。
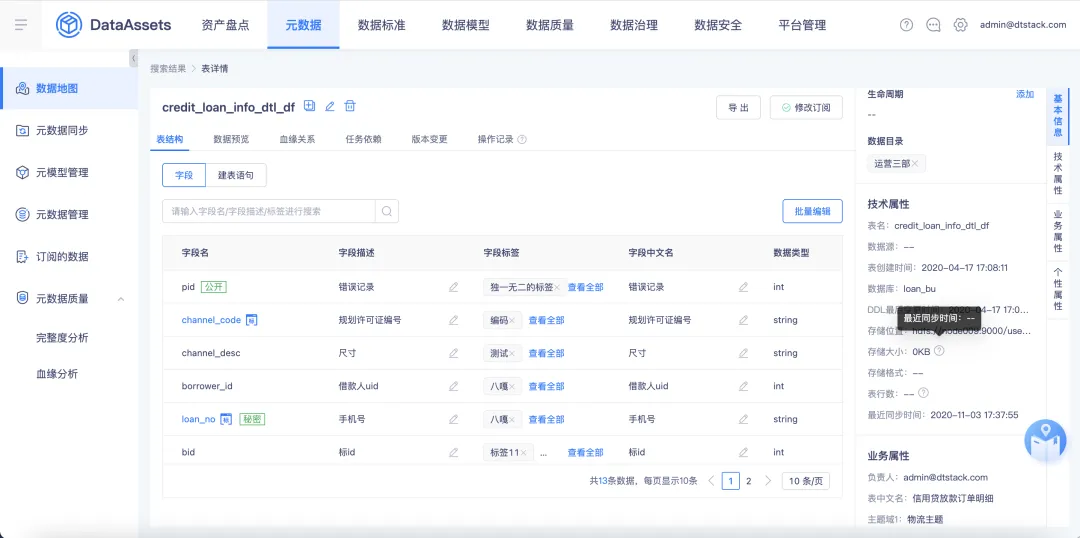
3.欄位中文名支持修改
背景:目前數據地圖中欄位中文名、欄位描述的取值邏輯是拿的建表語句中的 comment 欄位,欄位描述可修改,欄位中文名也需要對應得調整為可修改。
體驗優化說明:【數據地圖】中的【表詳情】頁面針對欄位中文名支持修改操作,支持單個修改/批量操作。
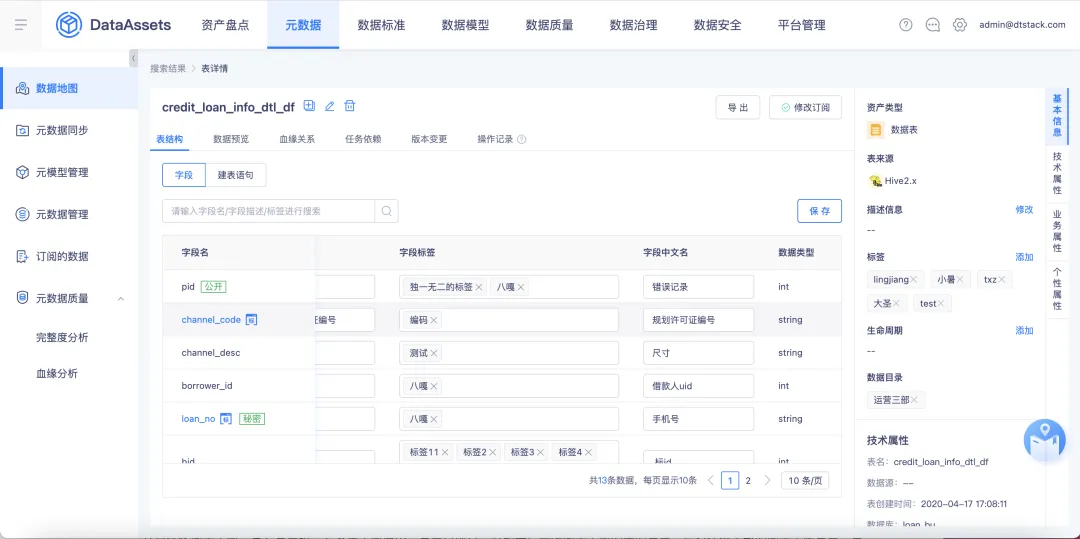
4.在編輯表的業務屬性時需提示最大字元長度限制
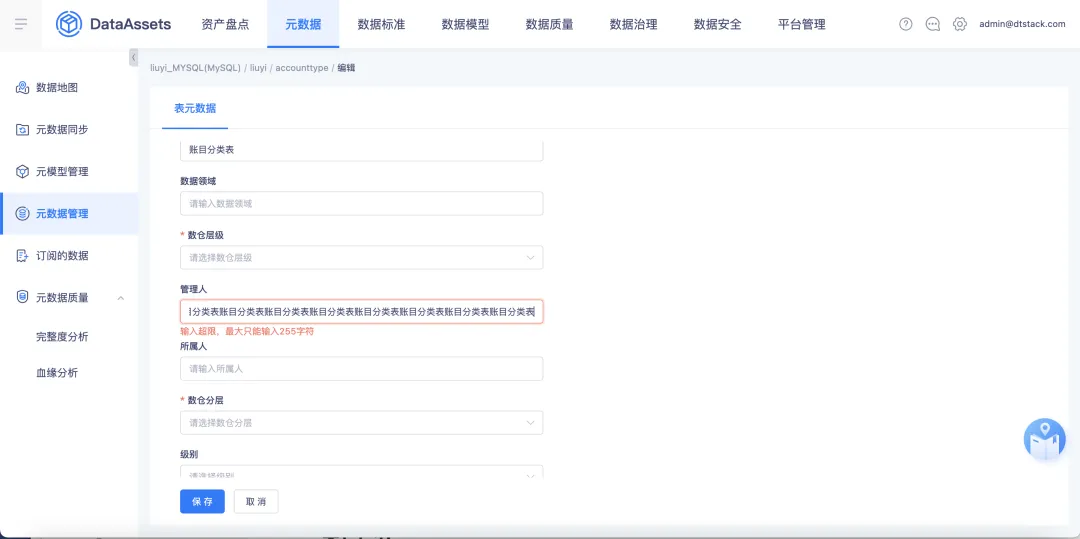
背景:針對錶的業務屬性為 string 類型的預設長度為100,目前在編輯表的業務屬性的時候沒有長度提示,且預設長度較小,會存在某些業務場景長度超限的情況。
體驗優化說明:針對業務屬性為 string 類型的,預設值的最大長度為255字元,並且在編輯業務屬性頁面進行最大長度提示。
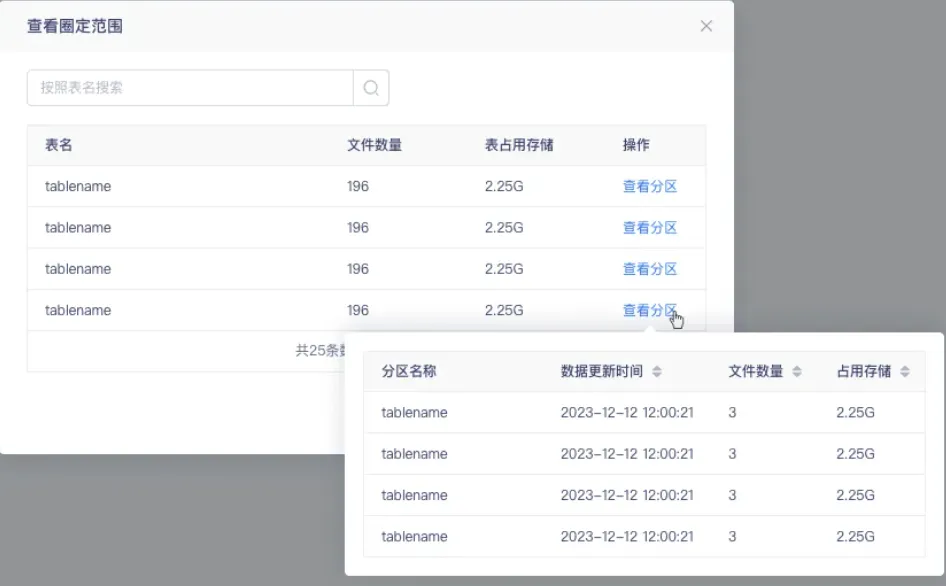
5.「小文件治理」 周期治理規則配置優化
對周期治理規則的規則配置頁面進行優化,針對分區表,設置【查看分區】操作,點擊展示每個分區表對應的文件數量。
6.元數據同步(日誌)優化
· 同步失敗的表,不僅展示表名,還展示這個表所屬資料庫
· 元數據同步時,針對每個同步實例,同步表數量、全部表數量的計算優化
• 日誌在同步表記錄列表中可以查看每個同步失敗的表的日誌
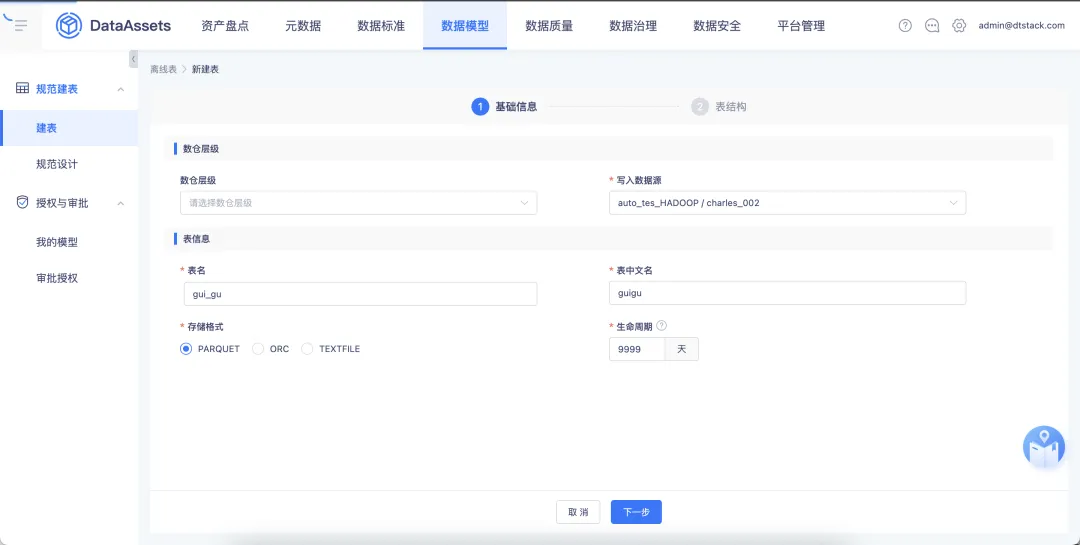
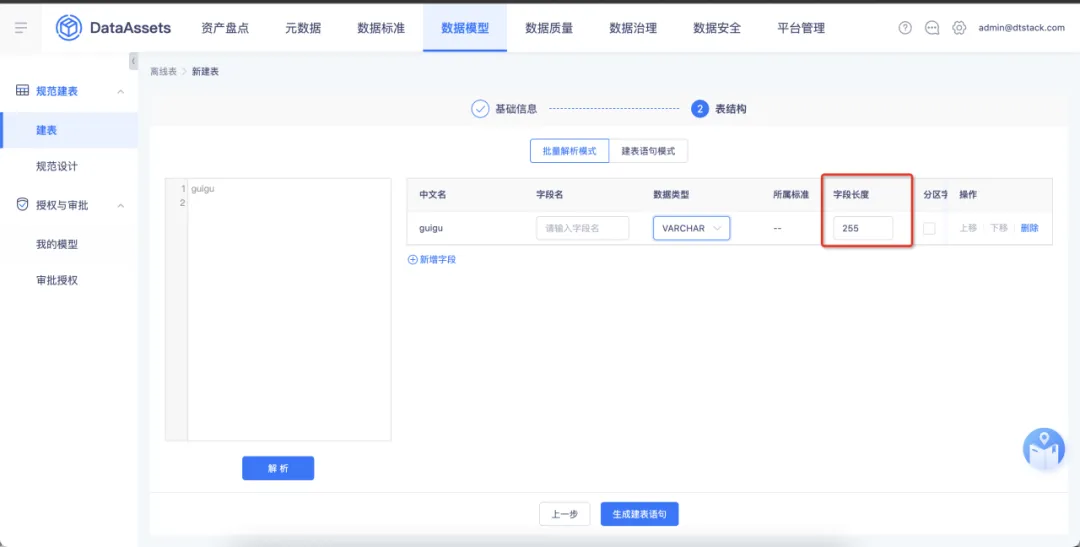
7.欄位類型設置 varchar 支持自定義字元長度
欄位類型 varchar 支持自定義字元長度。在數倉層級設置中,數倉層級為非必選欄位。如果用戶未選擇數倉層級,表名的首碼無信息。
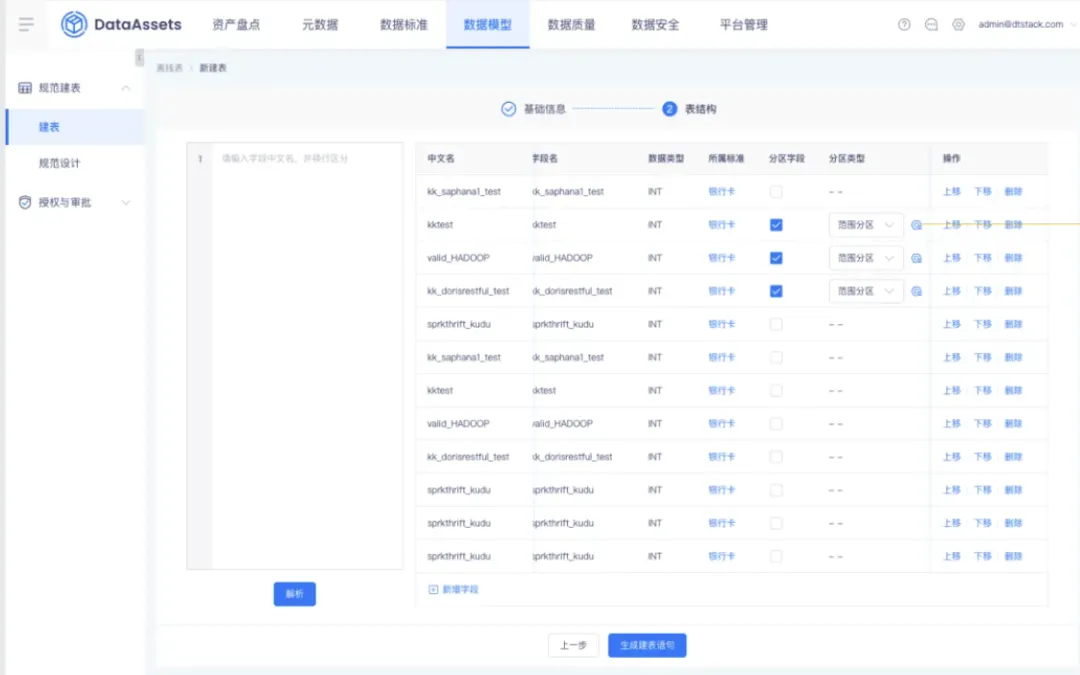
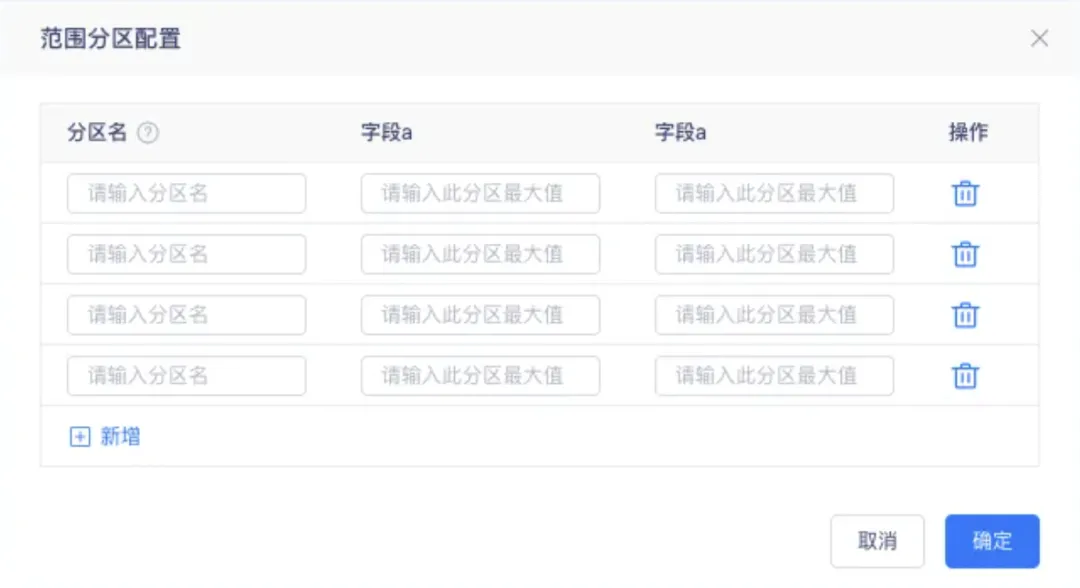
8.數據模型建表時支持配置分區範圍
性能優化,方便用戶在創建時能自定義分區範圍,減少操作流程,完善用戶體驗。
9.支持 meta 數據源的自動引入
數據資產平臺針對所有的子產品(離線、指標、標簽)都支持 meta 數據源的自動引入。同時針對指標、標簽,支持指標標簽生成的 trino 類型 meta 數據源的自動引入。
10.可定義資產概覽中展示的預設數據源
可定義預設展示數據源(按照數據源、資料庫、數據表數量排序)最多的數據源類型。例如如果用戶 spark 數據源下麵的數據源數量最多,預設的就展示 spark 類型,涉及到的展示模塊包含資產盤點頁面以及元數據管理頁面。

11.【資產盤點】數據價值排行邏輯優化
背景:數據價值排行最大可統計最近一年的數據,由於後端存儲的是全量數據,隨著時間的推移,數據量將不斷增加,影響查詢性能。
體驗優化說明:對【資產盤點】頁面的數據價值排行進行邏輯優化,後端僅保留最近一年的數據,以優化性能。
12.數據目錄顯示和拖動優化
背景:【數據目錄】因左側欄固定寬度,導致目錄顯示不全。
體驗優化說明:【數據地圖】的【數據目錄】、【數據標準】的【碼表管理】、【數據標準】的標準管理(包括標准定義和標準映射)、【數據安全】的【自動分級】的【數據目錄】支持左右拉伸,支持選擇該層級的整個範圍進行拖動。
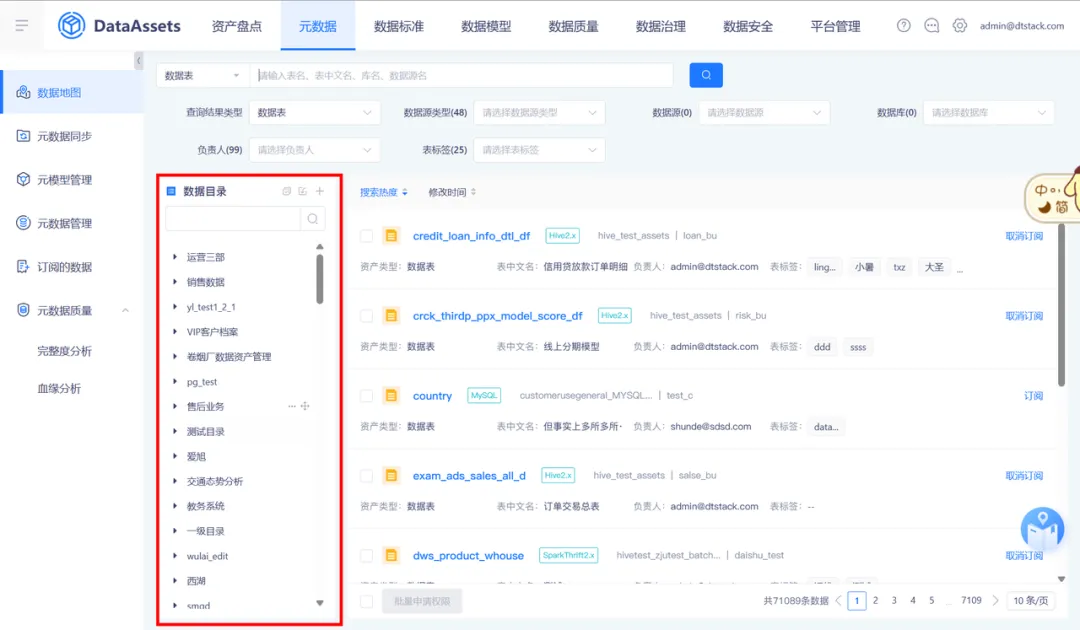
13.支持對錶負責人的許可權點管理
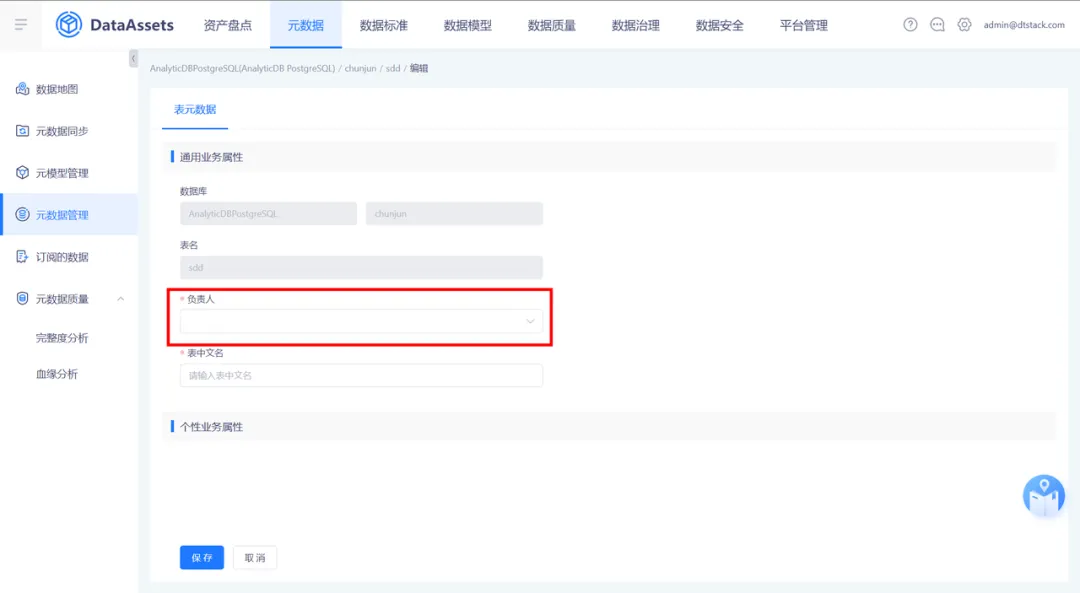
表負責人變更為非必填屬性,針對沒有表負責人修改許可權的用戶,點擊編輯業務屬性頁面時,無編輯“表負責人”選擇框
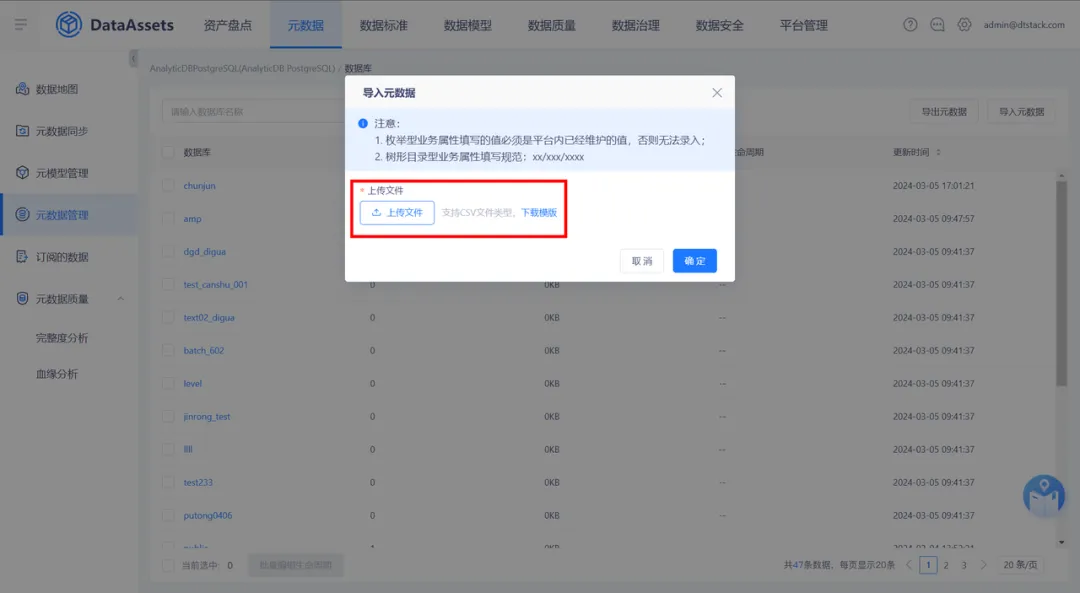
針對沒有表負責人修改許可權的用戶,上傳文件後需要校驗上傳用戶是否有表負責人的編輯許可權,若無編輯許可權,則導入的表負責人不生效(數據開發和訪客角色預設無表負責人修改許可權)
14.單表校驗波動檢測結果取值調整為取最新值
針對單表校驗中波動檢測結果取值,表行數的1天波動性檢、表行數的7天波動檢測、月度波動檢測取值修改為取最新值。
15.告警通道配置校驗優化
背景:當控制台未設置郵件預設告警通道,在進行質量配置告警/其他通知時不會提示,會導致發告警失敗。
體驗優化說明:在配置通知時,將校驗郵件、簡訊是否已配置告警通道,若未配置,會提示用戶“簡訊/郵件未配置告警通道,請先確認告警通道配置完成後再進行通知信息配置。”(涉及模塊包含:元數據周期同步告警;元數據實時同步告警;數據質量單表校驗、多表校驗、規則集告警;數據治理治理任務配置通知、指派人通知;表訂閱通知)

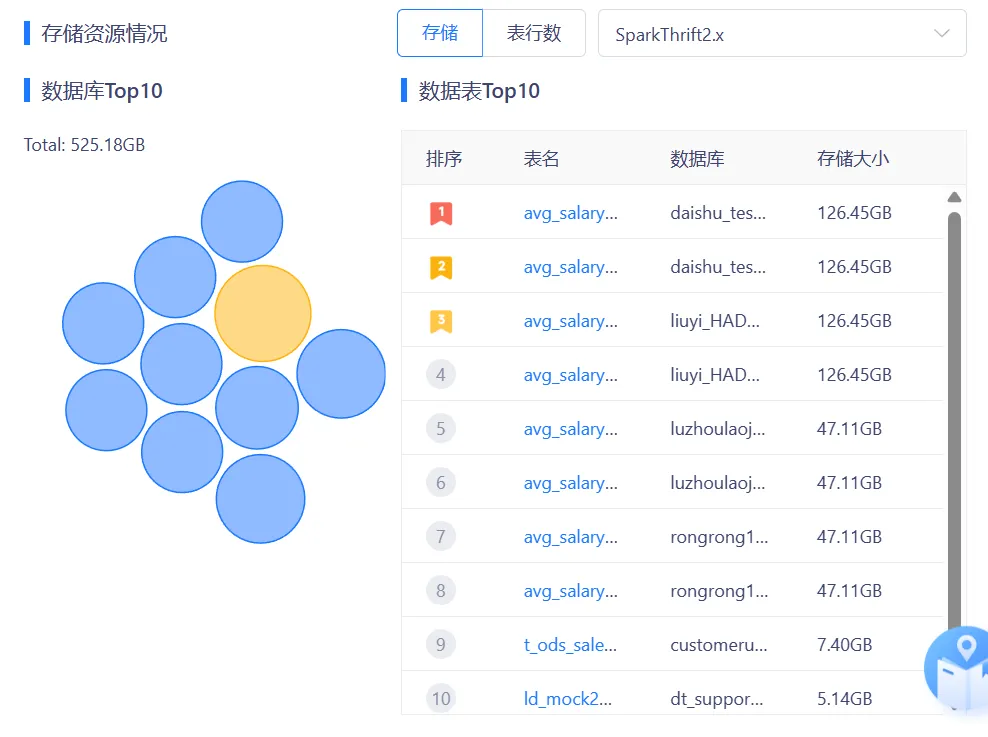
16.存儲資源情況篩選框保留數據源選擇狀態
若選擇框中已經選擇數據源,不論是存儲切換為表行數,還是表行數切換為存儲,數據源的選擇狀態都保持不變。
數據服務平臺
新增功能更新
1.數據源中心增加邏輯
背景:為確保數據源中心與數據服務的同步開發,每次開發新數據源時,都需要與數據服務並行進行。為了避免數據源中心提前開發完成而數據服務尚未對接,導致新數據源無法上線的問題,API 需要增加新的邏輯來預防這種情況的發生。
新增功能說明:對數據源管理增加過濾邏輯,對於數據服務未支持的數據源做過濾,在數據服務對接該數據源後,再添加進數據源管理。
功能優化
1.da_invoke_log 表相關優化
• 對同一用戶,在一段時間內因登陸失敗寫入資料庫的數據做最大條數的限制,最大程度上保障數據的安全
• 對 da_apply_invoke 表 SQL 查詢進行優化
2.發佈內容優化
背景:當前發佈內容,僅可發佈API,這樣會造成當從測試環境發佈至生產環境後,關聯的行級許可權、告警配置等無法生效,致使數據安全出現問題。
體驗優化說明:對發佈內容進行了改進,現在可以單獨發佈行級許可權、API、告警策略和熔斷策略等,也可以將它們組合打包發佈。這樣做可以確保生產環境中的 API 保持穩定,用戶可以更安全、高效地使用。
指標管理平臺
新增功能更新
1.指標發佈/下線對接審批中心
背景:指標發佈/下線都是重要操作,需要增加審批流程以提高操作的安全性。由於數棧中已經有審批功能模塊,所以直接對接現有審批流程。
新增功能說明:
超級管理員可在【公共管理】-【審批中心】-【流程管理】中設置審批流程。指標發佈和下線都有對應的內置流程,分別是「指標發佈審批」和「指標下線審批」,預設應用於所有租戶,只有一個審批節點,審批人為申請發生的租戶下的項目管理員、項目所有者、租戶管理員和租戶所有者。
確認當前租戶開啟了對應的審批流程之後,加入了【指標管理】的項目的用戶可在【指標中心】界面對指標進行發佈/下線的申請操作。
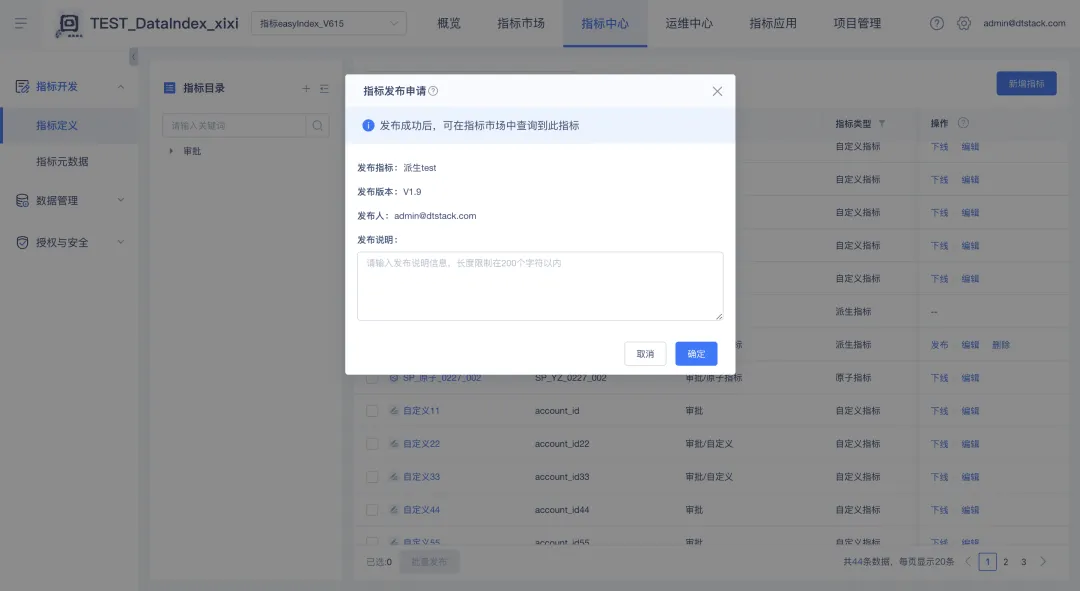
用戶可在【審批中心】-【我的申請】-【審批中】中查看自己已經提交的申請的審批進度,也可以取消審批流程未完成的申請,取消申請後將終止審批流程。
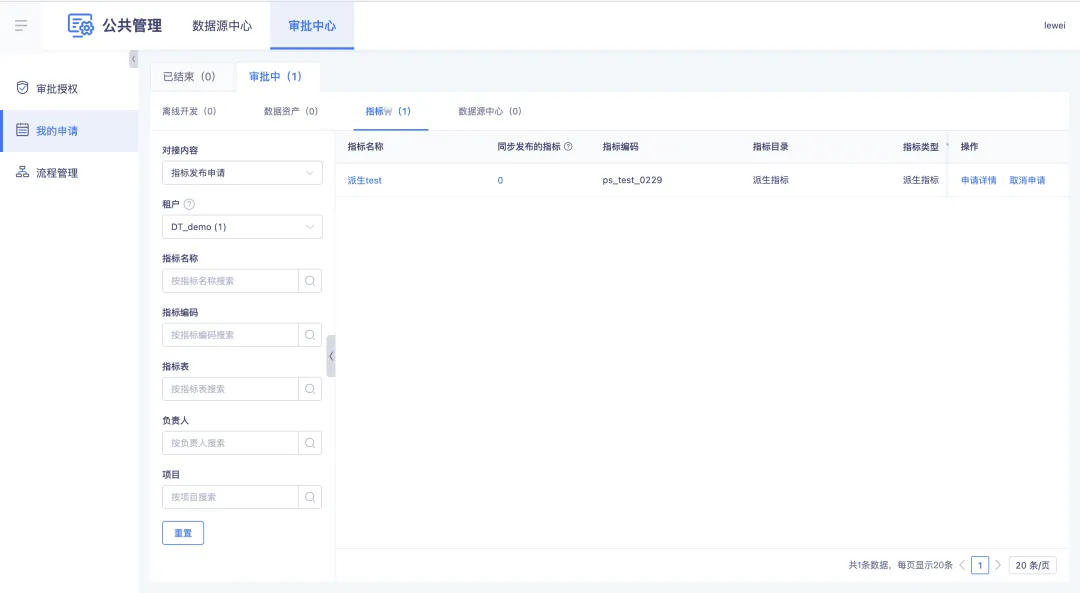
審批人可在【審批中心】-【審批授權】界面中審批已經提交的申請。審批節點上的任一審批人通過之後,則該申請通過該審批節點。申請通過所有審批節點後,則該申請變為「已通過」狀態,該指標發佈/下線申請生效,指標的發佈狀態隨之更改為「已發佈」或「已下線」狀態。
2.指標屬性自定義
背景:目前指標基本信息中的屬性都是平臺內置屬性,實際使用中客戶會存在需要使用自定義屬性的場景,比如指標等級、指標負責部門等,所以需要支持指標屬性自定義的功能,方便客戶自定義指標屬性,併在加工指標的時候進行填寫,提升指標使用體驗。
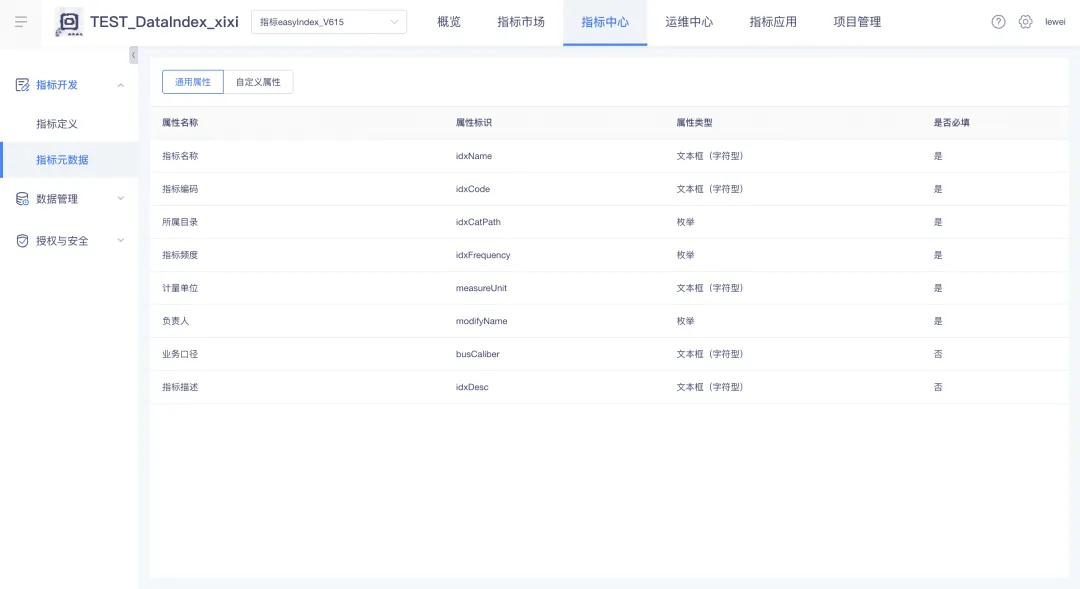
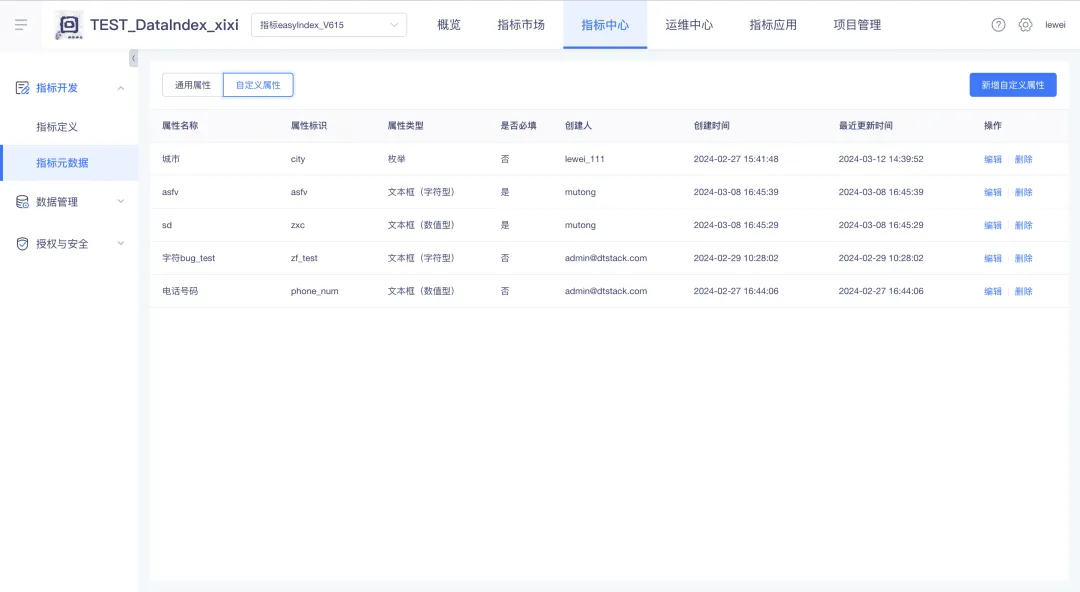
新增功能說明:在【指標開發】中新增【指標元數據】功能,用戶可以在【指標元數據】界面中查看通用屬性(即平臺內置屬性),查看和管理自定義屬性。
功能優化
1.行級許可權根據動態值選擇匹配欄位時,可選到用戶管理中的所有欄位
之前僅支持選到用戶管理中的固有屬性欄位,現在增加支持選到自定義屬性欄位。
《行業指標體系白皮書》下載地址:https://www.dtstack.com/resources/1057?src=szsm
《數棧產品白皮書》下載地址:https://www.dtstack.com/resources/1004?src=szsm
《數據治理行業實踐白皮書》下載地址:https://www.dtstack.com/resources/1001?src=szsm
想瞭解或咨詢更多有關大數據產品、行業解決方案、客戶案例的朋友,瀏覽袋鼠雲官網:https://www.dtstack.com/?src=szbky


