
目錄一、創建百萬級小文件1、單核CPU情況2、多核CPU情況3、執行效率對比3.1、單核的順序執行3.2、多核的併發執行二、如何列出/瀏覽這些文件1、查看目錄下文件的數量2、列出?3、ls -f(關閉排序功能)3.1、執行效率對比4、通過重定嚮導入到文件中瀏覽對應的文件名三、如何快速刪除目錄下所有文 ...
目錄
一、創建百萬級小文件
1、單核CPU情況
seq 1000000 |xargs -i dd if=/dev/zero of={}.data bs=1024 count=1 &> /dev/null
#生成一百萬個大小為1KB、內容全為零的文件
seq 1000000 |xargs -i dd if=/dev/urandom of={}.data bs=1024 count=1 &> /dev/null
#生成一百萬大小為1KB,內容為隨機數據的文件
首先通過
seq 1000000生成從1到1000000的序列
|(管道符號): 將前面命令的輸出作為後面命令的輸入。
xargs: 是一個用於將輸入行轉換為命令行參數的工具。
-i: 選項告訴xargs將輸入行中的占位符(預設是{})替換為輸入行的內容。dd是一個強大的複製和轉換數據的命令。
if=/dev/null:指定/dev/zero作為輸入文件,這是一個無限量供應位元組流的特殊文件,所有讀取操作都會返回零值位元組
if=/dev/urandom: 指定了輸入文件為/dev/urandom,這是一個生成隨機數的設備文件,可以提供隨機數據。
of={}.data: 指定了輸出文件的格式,其中{}會被seq生成的數字依次替換,形成如1.data、2.data這樣的文件名
bs=1024: 設置每次讀寫的塊大小為1024位元組。
count=1: 指定只讀寫一次塊,因此每個文件的大小是1KB。
>> /dev/null 2>&1: 這部分重定向了命令的所有輸出(標準輸出和錯誤輸出)到/dev/null。這意味著不論是正常輸出還是錯誤信息都不會顯示在終端上。
2、多核CPU情況
seq 1000000 |xargs -i -P 0 dd if=/dev/zero of={}.data bs=1024 count=1 &> /dev/null
#生成一百萬個大小為1KB、內容全為零的文件
seq 1000000 |xargs -i -P 0 dd if=/dev/urandom of={}.data bs=1024 count=1 &> /dev/null
#生成一百萬大小為1KB,內容為隨機數據的文件
-P 0選項指定了儘可能多地開啟併發進程數量如果要保證最高效率,應當設置併發進程數量等於cpu的核心數量
3、執行效率對比
3.1、單核的順序執行
time seq 1000 |xargs -i dd if=/dev/urandom of={}.data bs=1024 count=1 &> /dev/null

3.2、多核的併發執行
time seq 1000 |xargs -i -P 4 dd if=/dev/urandom of={}.data bs=1024 count=1 &> /dev/null

二、如何列出/瀏覽這些文件
1、查看目錄下文件的數量
ls | wc -l

2、列出?
一般情況下我們會直接使用ls進行列出處理
ls
 |
|---|
 |
但是不難看出鍵入ls命令後終端會卡住
最後所有的文件名會一次性列印在終端的屏幕上
3、ls -f(關閉排序功能)
預設ls命令會在記憶體中對輸出的文件進行排序
[root@localhost test]# man ls | grep -w "\-f"
-f do not sort, enable -aU, disable -ls --color
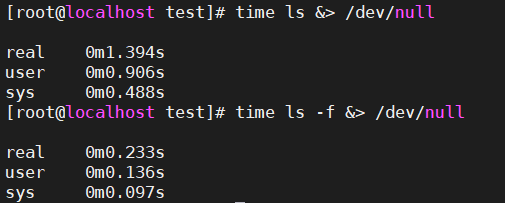
3.1、執行效率對比
[root@localhost test]# time ls &> /dev/null
real 0m1.394s
user 0m0.906s
sys 0m0.488s
[root@localhost test]# time ls -f &> /dev/null
real 0m0.233s
user 0m0.136s
sys 0m0.097s
4、通過重定嚮導入到文件中瀏覽對應的文件名
ls -1 -f > /tmp/filelist.txt
-1:一行一個文件名
-f:關閉排序功能

通過less、more、vim等工具進行瀏覽和搜索
三、如何快速刪除目錄下所有文件
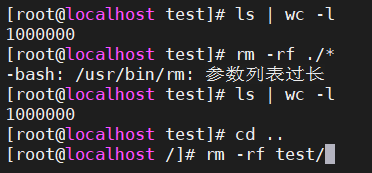
1、rm -f ./* ?
rm -rf ./*
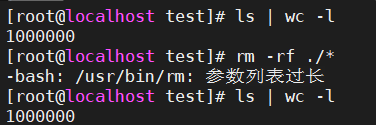
很顯然,rm的參數列表過長,無法執行rm命令
2、將整個目錄名作為參數傳遞給rm命令
rm -rf test
3、使用find配合-delete參數
find /test/ -mindepth 1 -delete

這條命令會從指定目錄開始,查找所有非目錄項(即文件)並刪除它們。
-mindepth 1確保不刪除當前目錄本身,以防萬一你需要保留該目錄結構以便後續檢查或操作。
四、需要保留指定文件怎麼辦
1、創建一個文件列出需要保留的文件名(一行一個文件名)
[root@localhost ~]# cd /tmp/
[root@localhost tmp]# cat > reserved_list.txt <<EOF
> 6.data
> 66.data
> 666.data
> 6666.data
> 66666.data
> EOF
#在一個乾凈的目錄下創建
2、創建一個名為empty的空目錄
[root@localhost tmp]# mkdir empty
3、使用rsync命令
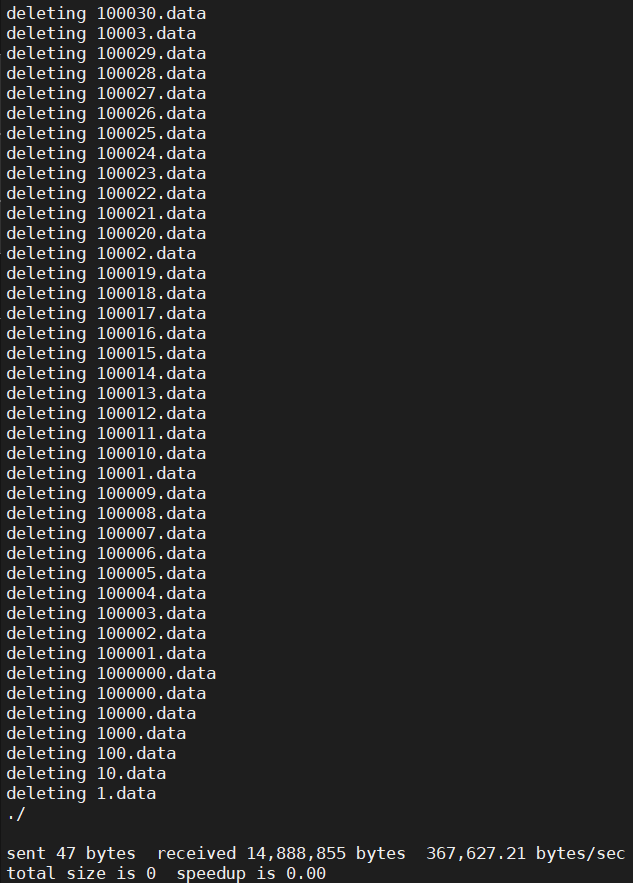
[root@localhost ~]# rsync -av --delete /tmp/empty/ /test/ --exclude-from=/tmp/reserved_list.txt
3.1、命令詳解

rsync: 是一個用於文件傳輸和數據備份的高效工具,它可以鏡像本地或遠程系統上的文件和目錄,並且可以高效地更新差異部分。-av: 這裡有兩個選項:-a或--archive是一個綜合選項,意味著進行歸檔模式的拷貝,它保留了 symbolic links, devices, permissions, owner, groups, timestamps, 和其它文件屬性,並遞歸地拷貝目錄。-v或--verbose表示詳細模式,會讓rsync在執行時輸出更多的信息,比如哪些文件正在被傳輸。
--delete: 這個選項指示rsync它會讓目標目錄(/test/)與源目錄(/tmp/empty/)保持一致,移除目標目錄中多餘的文件。/tmp/empty/: 源目錄,這是一個假設為空的目錄。因為源目錄是空的,結合--delete選項,實際上會導致目標目錄/test/中的所有內容被刪除(除非有排除規則)。/test/: 目標目錄,你想同步到或依據源目錄進行清理的目錄。--exclude-from=/tmp/reserved_list.txt: 這個選項指定了一個文件列表,其中包含了不想被刪除或同步的文件/目錄的模式。rsync會讀取/tmp/reserved_list.txt文件中的每一行作為排除模式,確保這些模式匹配到的文件或目錄不會被刪除。
整個命令的意思是:以歸檔模式並且詳細輸出的形式,同步空目錄 /tmp/empty/ 到目錄 /test/,在同步過程中刪除目標目錄中源目錄不存在的文件,但排除 /tmp/reserved_list.txt 文件中列出的文件或目錄不被刪除。這是一種清理或重置目錄結構的方法,同時保留特定的“保留”文件或目錄不被刪除。
4、檢查源目錄是否保留了指定文件
ls /test/



