
實時識別關鍵詞是一種能夠將搜索結果提升至新的高度的API介面。它可以幫助我們更有效地分析文本,並提取出關鍵詞,以便進行進一步的處理和分析。 該介面是挖數據平臺提供的,有三種模式:精確模式、全模式和搜索引擎模式。不同的模式在分詞的方式上有所不同,適用於不同的場景。 首先是精確模式。這種模式會儘量將句子 ...

實時識別關鍵詞是一種能夠將搜索結果提升至新的高度的API介面。它可以幫助我們更有效地分析文本,並提取出關鍵詞,以便進行進一步的處理和分析。
該介面是挖數據平臺提供的,有三種模式:精確模式、全模式和搜索引擎模式。不同的模式在分詞的方式上有所不同,適用於不同的場景。
首先是精確模式。這種模式會儘量將句子最精確地切分開,以便更準確地分析文本。它適合用於對文本進行深入分析和理解。

接下來是全模式。全模式會將句子中所有可以成詞的詞語都掃描出來,速度非常快。然而,它不能解決歧義,因此在某些場景下可能會出現誤解的情況。
最後是搜索引擎模式,它在精確模式的基礎上,對長詞再次切分,以提高召回率。這種模式適合用於搜索引擎分詞,可以更好地適應用戶的搜索需求。
使用這個API介面可以幫助我們更好地理解和分析文本內容。例如,我們可以將一篇新聞文章傳入介面,然後接收到分析後的關鍵詞。這些關鍵詞可以幫助我們瞭解文章的主題、重點和相關性,併在後續的處理中發揮重要作用。
在實際使用中,我們可以通過調用相關的API介面來實現關鍵詞的提取。以下是一個示例代碼的說明,以幫助大家更好地理解如何使用這個介面:
import requests # 設置介面的請求URL url = "https://api.wapi.cn/v1/keyword/extract" # 設置請求參數 params = { "text": "這是一篇測試文本", "mode": "accurate" } # 發送請求 response = requests.get(url, params=params) # 解析返回的結果 result = response.json() # 列印關鍵詞 keywords = result["data"] for keyword in keywords: print(keyword)
在上面的示例代碼中,我們首先設置了介面的請求URL和請求參數。然後,使用requests庫發送了一個GET請求,並解析了返回的結果。最後,我們列印出了提取出的關鍵詞。
通過這樣的方式,我們可以輕鬆地調用這個API介面,並獲得關鍵詞的提取結果。這些關鍵詞將幫助我們更好地理解和分析文本內容,從而提升搜索結果的準確性和相關性。
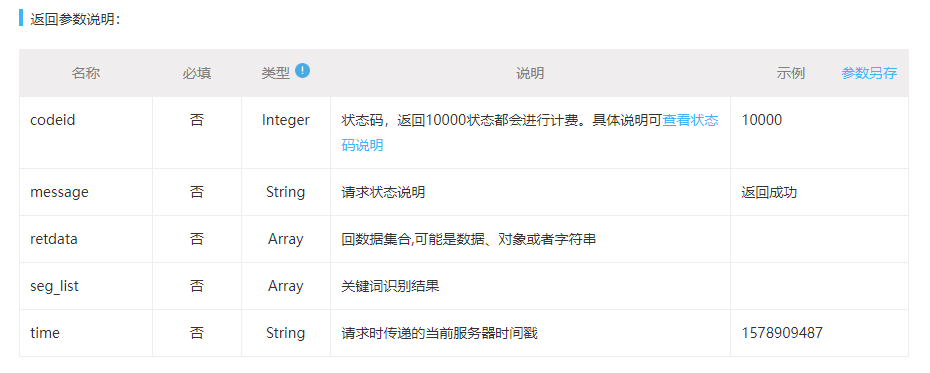
總之,實時識別關鍵詞API介面是一個非常有用的工具,它可以幫助我們更好地處理和分析文本內容。通過調用這個介面,我們可以輕鬆地提取出關鍵詞,並應用於各種場景中,從而提升搜索結果的質量和效果。


