
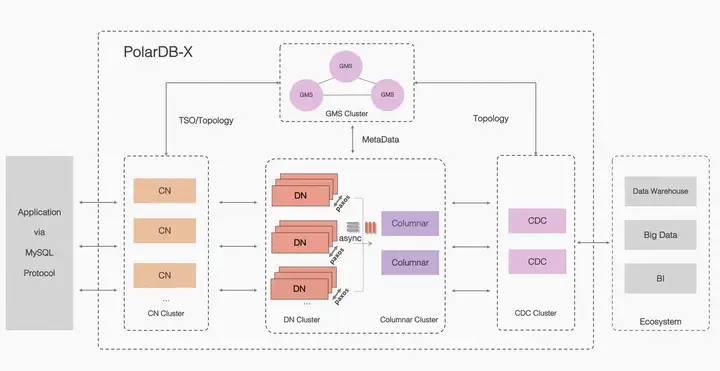
架構簡介 PolarDB-X 採用 Shared-nothing 與存儲分離計算架構進行設計,系統由5個核心組件組成。 PolarDB分散式 架構圖 計算節點(CN, Compute Node) 計算節點是系統的入口,採用無狀態設計,包括 SQL 解析器、優化器、執行器等模塊。負責數據分散式路由、計 ...
架構簡介
PolarDB-X 採用 Shared-nothing 與存儲分離計算架構進行設計,系統由5個核心組件組成。
 PolarDB分散式 架構圖
PolarDB分散式 架構圖
- 計算節點(CN, Compute Node) 計算節點是系統的入口,採用無狀態設計,包括 SQL 解析器、優化器、執行器等模塊。負責數據分散式路由、計算及動態調度,負責分散式事務 2PC 協調、全局二級索引維護等,同時提供 SQL 限流、三權分立等企業級特性。
- 存儲節點(DN, Data Node) 存儲節點負責數據的持久化,基於多數派 Paxos 協議提供數據高可靠、強一致保障,同時通過 MVCC 維護分散式事務可見性。
- 元數據服務(GMS, Global Meta Service) 元數據服務負責維護全局強一致的 Table/Schema, Statistics 等系統 Meta 信息,維護賬號、許可權等安全信息,同時提供全局授時服務(即 TSO)。
- 日誌節點(CDC, Change Data Capture) 日誌節點提供完全相容 MySQL Binlog 格式和協議的增量訂閱能力,提供相容 MySQL Replication 協議的主從複製能力。
- 列存節點 (Columnar) 列存節點提供持久化列存索引,實時消費分散式事務的binlog日誌,基於對象存儲介質構建列存索引,能滿足實時更新的需求、以及結合計算節點可提供列存的快照一致性查詢能力
開源地址:[https://github.com/polardb/polardbx-sql]
版本說明
梳理下PolarDB-X 開源脈絡:
- 2021年10月,在雲棲大會上,阿裡雲正式對外開源了雲原生分散式資料庫PolarDB-X,採用全內核開源的模式,開源內容包含計算引擎、存儲引擎、日誌引擎、Kube等。
- 2022年1月,PolarDB-X 正式發佈 2.0.0 版本,繼 2021 年 10 月 20 號雲棲大會正式開源後的第一次版本更新,更新內容包括新增集群擴縮容、以及binlog生態相容等特性,相容 maxwell 和 debezium 增量日誌訂閱,以及新增其他眾多新特性和修複若幹問題。
- 2022年3月,PolarDB-X 正式發佈 2.1.0 版本,包含了四大核心特性,全面提升 PolarDB-X 穩定性和生態相容性,其中包含基於Paxos的三副本共識協議。
- 2022年5月,PolarDB-X正式發佈2.1.1 版本,重點推出冷熱數據新特性,可以支持業務表的數據按照數據特性分別存儲在不同的存儲介質上,比如將冷數據存儲到Aliyun OSS對象存儲上。
- 2022年10月,PolarDB-X 正式發佈2.2.0版本,這是一個重要的里程碑版本,重點推出符合分散式資料庫金融標準下的企業級和國產ARM適配,共包括八大核心特性,全面提升 PolarDB-X 分散式資料庫在金融、通訊、政務等行業的普適性。
- 2023年3月,PolarDB-X 正式發佈2.2.1版本,在分散式資料庫金融標準能力基礎上,重點加強了生產級關鍵能力,全面提升PolarDB-X面向資料庫生產環境的易用性和安全性,比如:提供數據快速導入、性能測試驗證、生產部署建議等。
- 2023年10月份,PolarDB-X 正式發佈 2.3.0版本,重點推出PolarDB-X標準版(集中式形態),將PolarDB-X分散式中的DN節點提供單獨服務,支持paxos協議的多副本模式、lizard分散式事務引擎,同時可以100%相容MySQL,對應PolarDB-X公有雲的標準版。
2024年4月份,PolarDB-X 正式發佈2.4.0版本,重點推出列存節點Columnar,可以提供持久化列存索引(Clustered Columnar Index,CCI)。PolarDB-X的行存表預設有主鍵索引和二級索引,列存索引是一份額外基於列式結構的二級索引(預設覆蓋行存所有列),一張表可以同時具備行存和列存的數據,結合計算節點CN的向量化計算,可以滿足分散式下的查詢加速的訴求,實現HTAP一體化的體驗和效果。
01 列存索引
隨著雲原生技術的不斷普及,以Snowflake為代表的新一代雲原生數倉、以及資料庫HTAP架構不斷創新,可見在未來一段時間後行列混存HTAP會成為一個資料庫的標配能力,需要在當前資料庫列存設計中面相未來的低成本、易用性、高性能上有更多的思考
PolarDB-X在V2.4版本正式發佈列存引擎,提供列存索引的形態(Clustered Columnar Index,CCI),行存表預設有主鍵索引和二級索引,列存索引是一份額外基於列式結構的二級索引(覆蓋行存所有列),一張表可以同時具備行存和列存的數據。
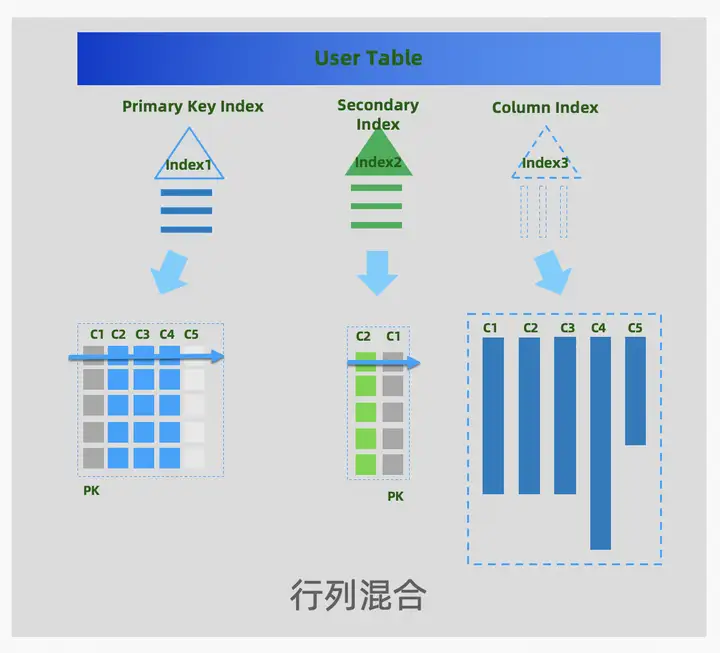 PolarDB-X 列存索引
PolarDB-X 列存索引
相關語法
索引創建的語法:

列存索引創建的DDL語法
- CLUSTERED COLUMNAR:關鍵字,用於指定添加的索引類型為CCI。
- 索引名:索引表的名稱,用於在SQL語句中指定該索引。
- 排序鍵:索引的排序鍵,即數據在索引文件中按照該列有序存儲。
- 索引分區子句:索引的分區演算法,與CREATE TABLE中分區子句的語法一致。
實際例子:
# 先創建表
CREATE TABLE t_order (
`id` bigint(11) NOT NULL AUTO_INCREMENT,
`order_id` varchar(20) DEFAULT NULL,
`buyer_id` varchar(20) DEFAULT NULL,
`seller_id` varchar(20) DEFAULT NULL,
`order_snapshot` longtext DEFAULT NULL,
`order_detail` longtext DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `l_i_order` (`order_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 partition by hash(`order_id`) partitions 16;
# 再創建列存索引
CREATE CLUSTERED COLUMNAR INDEX `cc_i_seller` ON t_order (`seller_id`) partition by hash(`order_id`) partitions 16;- 主表:"t_order" 是分區表,分區的拆分方式為按照 "order_id" 列進行哈希。
- 列存索引:"cc_i_seller" 按照 "seller_id" 列進行排序,按照 "order_id" 列進行哈希。
- 索引定義子句:CLUSTERED COLUMNAR INDEX cc_i_seller ON t_order (seller_id) partition by hash(order_id) partitions 16。
原理簡介
列存索引的數據結構:
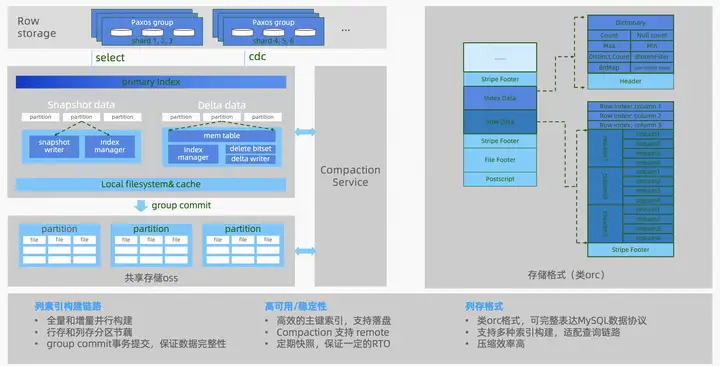 列存數據結構
列存數據結構
列存索引是由列存引擎(Columnar)節點來構造的,數據結構基於Delta+Main(類LSM結構)二層模型,實時更新採用了標記刪除的技術(update轉化為delete標記 + insert),確保了行存和列存之間實現低延時的數據同步,可以保證秒級的實時更新。數據實時寫入到MemTable,在一個group commit的周期內,會將數據存儲到一個本地csv文件,並追加到OSS上對應csv文件的尾部,這個文件稱為delta文件。OSS對象存儲上的.csv文件不會長期存在,而是由compaction線程不定期地轉換成.orc文件。
列存索引的數據流轉:
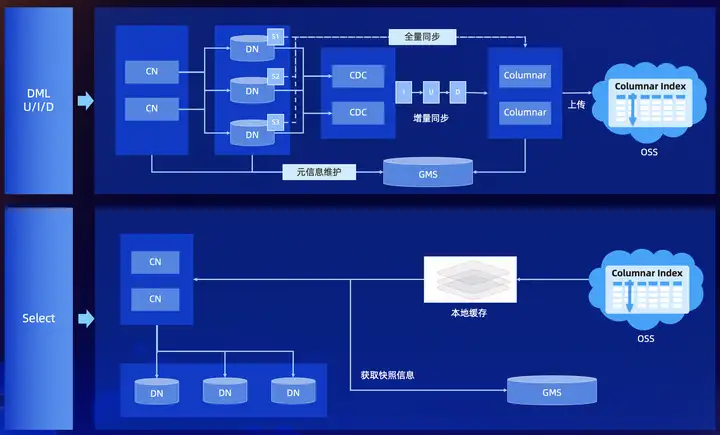 數據流轉
數據流轉
列存索引,構建流程:
- 數據通過CN寫入到DN(正常的行存數據寫入)
- CDC事務日誌,提供實時提取邏輯binlog(獲取事務日誌)
- Columnar實時消費snapshot數據和cdc 增量binlog流,構建列存索引(非同步實現行轉列)
列存索引,查詢流程:
- CN節點,基於一套SQL引擎提供了統一入口
- CN 從GMS獲取當前最新的TSO(事務時間戳)
- CN基於TSO獲取當前列存索引的快照信息(GMS中存儲了列存索引的元數據)
- 從DN或者OSS掃描數據,拉到CN做計算(行列混合計算)
tips. 更多列存引擎相關的技術原理文章,後續會逐步發佈,歡迎大家持續關註。
性能體驗
測試集:TPC-H 100GB 硬體環境:
| 機器用途 | 機型 | 規格 |
| 壓力機 | ecs.hfg7.6xlarge | 24c96g |
| 資料庫機器 | ecs.i4.8xlarge * 3 | 32c256g + 7TB的存儲,單價:7452元/月 |
按照正常導入TPC-H 100GB數據後,執行SQL創建列存索引:
create clustered columnar index `nation_col_index` on nation(`n_nationkey`) partition by hash(`n_nationkey`) partitions 1;
create clustered columnar index `region_col_index` on region(`r_regionkey`) partition by hash(`r_regionkey`) partitions 1;
create clustered columnar index `customer_col_index` on customer(`c_custkey`) partition by hash(`c_custkey`) partitions 96;
create clustered columnar index `part_col_index` on part(`p_size`) partition by hash(`p_partkey`) partitions 96;
create clustered columnar index `partsupp_col_index` on partsupp(`ps_partkey`) partition by hash(`ps_partkey`) partitions 96;
create clustered columnar index `supplier_col_index` on supplier(`s_suppkey`) partition by hash(`s_suppkey`) partitions 96;
create clustered columnar index `orders_col_index` on orders(`o_orderdate`,`o_orderkey`) partition by hash(`o_orderkey`) partitions 96;
create clustered columnar index `lineitem_col_index` on lineitem(`l_shipdate`,`l_orderkey`) partition by hash(`l_orderkey`) partitions 96;場景1:單表聚合場景( count 、 groupby)
| 場景 | 列存 (單位秒) | 行存 (單位秒) | 性能提升 |
| tpch-Q1 | 2.98 | 105.95 | 35.5 倍 |
| select count(*) from lineitem | 0.52 | 19.85 | 38.1 倍 |
tpch-Q1的行存和列存的效果對比圖:
 tpch-Q1
tpch-Q1
select count的行存和列存的效果對比圖:
 count查詢
count查詢
場景2:TPC-H 22條query
基於列存索引的性能白皮書,開源版本可以參考:TPC-H測試報告
TPC-H 100GB,22條query總計25.76秒
詳細數據如下:
| 查詢語句 | 耗時(單位秒) |
| Q1 | 2.59 |
| Q2 | 0.80 |
| Q3 | 0.82 |
| Q4 | 0.52 |
| Q5 | 1.40 |
| Q6 | 0.13 |
| Q7 | 1.33 |
| Q8 | 1.15 |
| Q9 | 3.39 |
| Q10 | 1.71 |
| Q11 | 0.53 |
| Q12 | 0.38 |
| Q13 | 1.81 |
| Q14 | 0.41 |
| Q15 | 0.46 |
| Q16 | 0.59 |
| Q17 | 0.32 |
| Q18 | 3.10 |
| Q19 | 0.88 |
| Q20 | 0.81 |
| Q21 | 1.84 |
| Q22 | 0.79 |
| Total | 25.76 秒 |
02 相容MySQL 8.0.32
PolarDB-X V2.3版本,推出了集中式和分散式一體化架構(簡稱集分一體),在2023年10月公共雲和開源同時新增集中式形態,將分散式中的DN多副本單獨提供服務,支持Paxos多副本、lizard分散式事務引擎,可以100%相容MySQL。 所謂集分一體化,就是兼具分散式資料庫的擴展性和集中式資料庫的功能和單機性能,兩種形態可以無縫切換。在集分一體化資料庫中,數據節點被獨立出來作為集中式形態,完全相容單機資料庫形態。當業務增長到需要分散式擴展的時候,架構會原地升級成分散式形態,分散式組件無縫對接到原有的數據節點上進行擴展,不需要數據遷移,也不需要應用側做改造。
回顧下MySQL 8.0的官方開源,8.0.11版本在2018年正式GA,歷經5年左右的不斷演進,修複和優化了眾多穩定性和安全相關的問題,2023年後的8.0.3x版本後逐步進入穩態。 PolarDB-X在V2.4版本,跟進MySQL 8.0的官方演進,分散式的DN多副本中全面相容MySQL 8.0.32,快速繼承了官方MySQL的眾多代碼優化:
- 更好用的DDL能力,比如:Instant DDL(加列、減列)、Parallel DDL(並行索引創建)
- 更完整的SQL執行能力,比如:Hash Join、視窗函數等
標準版架構
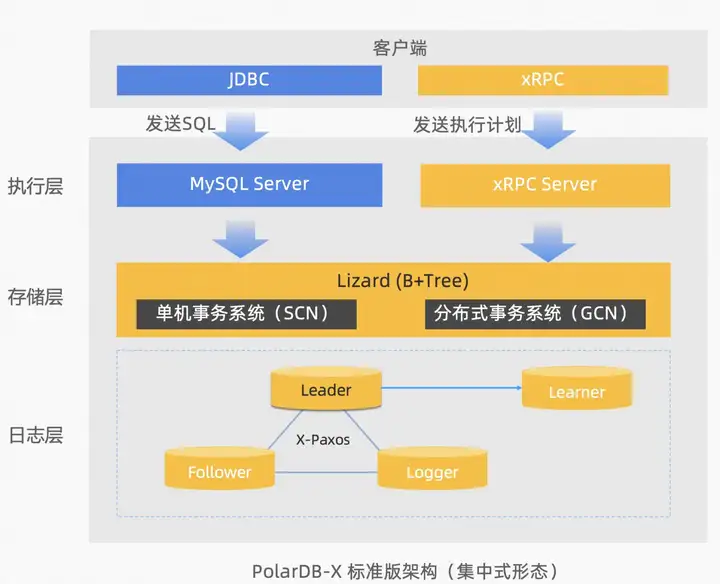
PolarDB-X標準版,採用分層架構:
- 日誌層:採用Paxos的多數派複製協議,基於Paxos consensus協議日誌完全相容MySQL binlog格式。相比於開源MySQL主備複製協議(基於binlog的非同步或半同步),PolarDB-X標準版可以金融級容災能力,滿足機房級故障時,不丟任何數據,簡稱RPO=0。
- 存儲層:自研Lizard事務系統,對接日誌層,可以替換傳統MySQL InnoDB的單機事務系統,分別設計了 SCN 單機事務系統和 GCN 分散式事務系統來解決這些弊端,可以滿足集中式和分散式一體化的事務優化,同時PolarDB-X標準版基於SCN 單機事務系統可以提供完全相容MySQL的事務隔離級別。
- 執行層:類似於MySQL的Server層,自研xRPC Server可以對接PolarDB-X企業版的分散式查詢。同時為完全相容MySQL,也提供相容MySQL Server的SQL執行能力,對接存儲層的事務系統來提供數據操作。
性能體驗
硬體環境:
| 機器用途 | 機型 | 規格 |
| 壓力機 | ecs.hfg7.6xlarge | 24c96g |
| 資料庫機器 | ecs.i4.8xlarge * 3 | 32c256g + 7TB的存儲,單價:7452元/月 |
TPCC場景:對比開源MySQL(採用相同的主機硬體部署)
| 場景 | 併發數 | MySQL 8.0.34 主備非同步複製 |
PolarDB-X 標準版 8.0.32 Paxos多數派 |
性能提升 |
| TPCC 1000倉 | 300併發 | 170882.38 tpmC | 236036.8 tpmC | ↑38% |
03 全球資料庫 GDN
資料庫容災架構設計是確保企業關鍵數據安全和業務連續性的核心。隨著數據成為企業運營的命脈,任何數據丟失或服務中斷都可能導致重大的財務損失。在規劃容災架構時,企業需要考慮數據的恢復時間目標(RTO)和數據恢復點目標(RPO),以及相關的成本和技術實現的複雜性。
常見容災架構
異地多活,主要指跨地域的容災能力,可以同時在多地域提供讀寫能力。金融行業下典型的兩地三中心架構,更多的是提供異地容災,日常情況下異地並不會直接提供寫流量。但隨著數字化形式的發展,越來越多的行業都面臨著容災需求。比如,運營商、互聯網、游戲等行業,都對異地多活的容災架構有比較強的訴求。 目前資料庫業界常見的容災架構:
- 同城3機房,一般是單地域多機房,無法滿足多地域多活的訴求
- 兩地三中心,分為主地域和異地災備地域,流量主要在主地域,異地主要承擔災備容災,異地機房日常不提供多活服務。
- 三地五中心,基於Paxos/Raft的多地域複製的架構
- Geo-Partitioning,基於地域屬性的partition分區架構,提供按用戶地域屬性的就近讀寫能力
- Global Database,構建全球多活的架構,寫發生在中心,各自地域提供就近讀的能力
總結一下容災架構的優劣勢:
| 容災架構 | 容災範圍 | 最少機房要求 | 數據複製 | 優缺點 |
| 同城3機房 | 單機房級別 | 3機房 | 同步 | 比較通用,業務平均RT增加1ms左右 |
| 兩地三中心 | 機房、地域 | 3機房 + 2地域 | 同步 | 比較通用,業務平均RT增加1ms左右 |
| 三地五中心 | 機房、地域 | 5機房 + 3地域 | 同步 | 機房建設成本比較高,業務平均RT會增加5~10ms左右(地域之間的物理距離) |
| Geo-Partitioning | 機房、地域 | 3機房 + 3地域 | 同步 | 業務有適配成本(表分區增加地域屬性),業務平均RT增加1ms左右 |
| Global Database | 機房、地域 | 2機房 + 2地域 | 非同步 | 比較通用,業務就近讀+ 遠程轉發寫,適合異地讀多寫少的容災場景 |
PolarDB-X的容災能力
PolarDB-X 採用數據多副本架構(比如3副本、5副本),為了保證副本間的強一致性(RPO=0),採用Paxos的多數派複製協議,每次寫入都要獲得超過半數節點的確認,即便其中1個節點宕機,集群也仍然能正常提供服務。Paxos演算法能夠保證副本間的強一致性,徹底解決副本不一致問題。
PolarDB-X V2.4版本以前,主要提供的容災形態:
- 單機房(3副本),能夠防範少數派1個節點的故障
- 同城3機房(3副本),能夠防範單機房故障
- 兩地三中心(5副本),能夠防範城市級的故障
阿裡集團的淘寶電商業務,在2017年左右開始建設異地多活的架構,構建了三地多中心的多活能力,因此在PolarDB-X V2.4我們推出了異地多活的容災架構,我們稱之為全球資料庫(Global Database Network,簡稱GDN)。 PolarDB-X GDN 是由分佈在同一個國家內多個地域的多個PolarDB-X集群組成的網路,類似於傳統MySQL跨地域的容災(比如,兩個地域的資料庫採用單向複製、雙向複製 , 或者多個地域組成一個中心+單元的雙向複製等)。
常見的業務場景:
- 基於GDN的異地容災
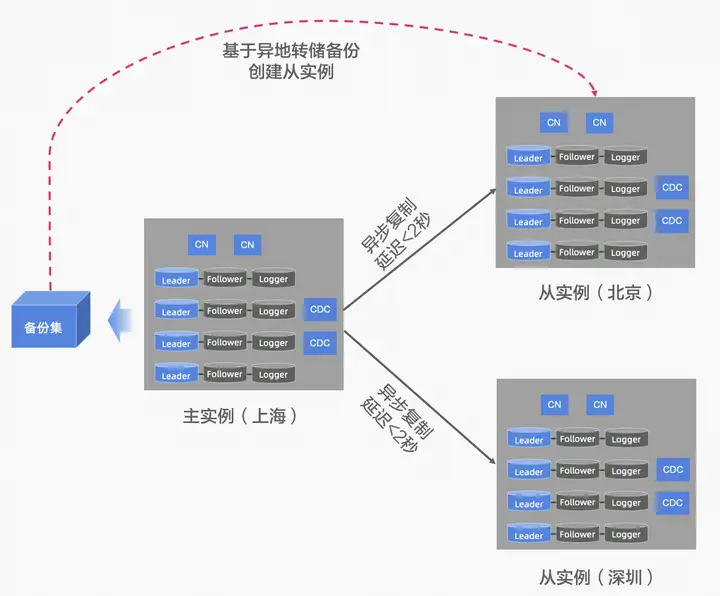 異地容災
異地容災
業務預設的流量,讀寫都集中在中心的主實例,異地的從實例作為災備節點,提供就近讀的服務能力 PolarDB-X 主實例 和 從實例,採用雙向複製的能力,複製延遲小於2秒,通過備份集的異地備份可以快速創建一個異地從實例。 當PolarDB-X 中心的主實例出現地域級別的故障時,可以手動進行容災切換,將讀寫流量切換到從實例
2. 基於GDN的異地多活
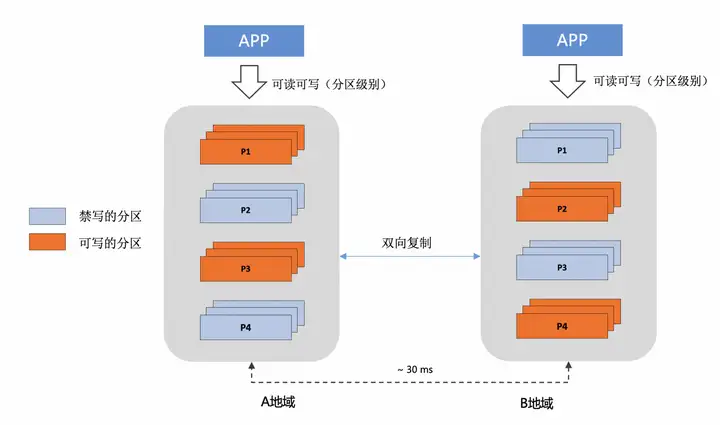 異地多活
異地多活
業務適配單元化分片,按照數據分片的粒度的就近讀和寫,此時主實例和從實例,均承擔讀寫流量 PolarDB-X 主實例 和 從實例,採用雙向複製的能力,複製延遲小於2秒 當PolarDB-X 中心的主實例出現地域級別的故障時,可以手動進行容災切換,將讀寫流量切換到從實例
使用體驗
PolarDB-X V2.4版本,暫時僅提供基於GDN的異地容災,支持跨地域的主備複製能力(異地多活形態會在後續版本中發佈)。GDN是一個產品形態,其基礎和本質是數據複製,PolarDB-X提供了高度相容MySQL Replica的SQL命令來管理GDN,簡單來說,會配置MySQL主從同步,就能快速的配置PolarDB-X GDN。
1. 可以使用相容MySQL的CHANGE MASTER命令,搭建GDN複製鏈路
CHANGE MASTER TO option [, option] ... [ channel_option ]
option: {
MASTER_HOST = 'host_name'
| MASTER_USER = 'user_name'
| MASTER_PASSWORD = 'password'
| MASTER_PORT = port_num
| MASTER_LOG_FILE = 'source_log_name'
| MASTER_LOG_POS = source_log_pos
| MASTER_LOG_TIME_SECOND = source_log_time
| SOURCE_HOST_TYPE = {RDS|POLARDBX|MYSQL}
| STREAM_GROUP = 'stream_group_name'
| WRITE_SERVER_ID = write_server_id
| TRIGGER_AUTO_POSITION = {FALSE|TRUE}
| WRITE_TYPE = {SPLIT|SERIAL|TRANSACTION}
| MODE = {INCREMENTAL|IMAGE}
| CONFLICT_STRATEGY = {OVERWRITE|INTERRUPT|IGNORE|DIRECT_OVERWRITE}
| IGNORE_SERVER_IDS = (server_id_list)
}
channel_option:
FOR CHANNEL channel
server_id_list:
[server_id [, server_id] ... ]2. 可以使用相容MySQL的SHOW SLAVE STATUS命令,監控GDN複製鏈路
SHOW SLAVE STATUS [ channel_option ]
channel_option:
FOR CHANNEL channel3. 可以使用相容MySQL的CHANGE REPLICATION FILTER命令,配置數據複製策略
CHANGE REPLICATION FILTER option [, option] ... [ channel_option ]
option: {
REPLICATE_DO_DB = (do_db_list)
| REPLICATE_IGNORE_DB = (ignore_db_list)
| REPLICATE_DO_TABLE = (do_table_list)
| REPLICATE_IGNORE_TABLE = (ignore_table_list)
| REPLICATE_WILD_DO_TABLE = (wild_do_table_list)
| REPLICATE_WILD_IGNORE_TABLE = (wile_ignore_table_list)
| REPLICATE_SKIP_TSO = 'tso_num'
| REPLICATE_SKIP_UNTIL_TSO = 'tso_num'
| REPLICATE_ENABLE_DDL = {TRUE|FALSE}
}
channel_option:
FOR CHANNEL channel4. 可以使用相容MySQL的START SLAVE 和 STOP SLAVE命令,啟動和停止GDN複製鏈路
START SLAVE [ channel_option ]
channel_option:
FOR CHANNEL channel
STOP SLAVE [ channel_option ]
channel_option:
FOR CHANNEL channel5.可以使用相容MySQL的RESET SLAVE,刪除GDN複製鏈路
RESET SLAVE ALL [ channel_option ]
channel_option:
FOR CHANNEL channel擁抱生態,提供相容MySQL的使用方式,可以大大降低使用門檻,但PolarDB-X也需要做最好的自己,我們在相容MySQL的基礎上,還提供了很多定製化的功能特性。
| 功能特性 | 功能描述 |
| 一鍵創建多條GDN複製鏈路 | 在 CHANGE MASTER 語句中,指定 STREAM_GROUP 選項,即PolarDB-X多流binlog集群的流組名稱,可以一鍵創建多條複製鏈路(具體取決於binlog流的數量),帶來極簡的使用體驗。什麼是多流binlog?參見binlog日誌服務 |
| 基於時間戳的複製鏈路搭建 | 在 CHANGE MASTER 語句中,指定 MASTER_LOG_TIME_SECOND 選項,可以基於指定的時間點,來構建複製鏈路,相比通過指定file name和file positiion的方式,更加靈活。 比如在搭建GDN時,一般的流程為先通過全量複製或備份恢復的方式準備好從實例,然後啟動增量複製鏈路,通過指定 MASTER_LOG_TIME_SECOND 顯然更加簡便。尤其是當對接的是PolarDB-X多流binlog時,為每條鏈路分別指定file name和file position,相當繁瑣,而結合STREAM_GROUP和MASTER_LOG_TIME_SECOND,則相當簡便。 |
| 多種模式的 DML 複製策略 | 在 CHANGE MASTER 語句中,指定 WRITE_TYPE 選項,可以指定DML的複製策略,可選策略如下 - TRANSACTION:嚴格按照binlog中的事務單元,進行原樣回放,適用於對數據一致性、事務完整性有高要求的場景 - SERIAL:打破binlog中的事務單元,重新組織事務單元,進行串列回放,適用於對事務完整性要求不高,但仍需要串列複製的場景 - SPLIT:打破binlog中的事務單元,依賴內置的數據衝突檢測演算法,進行全並行回放,適用於高吞吐、高併發的場景 |
| 全量增量一體化複製搭建 | 誰說 CHANGE MASTER 只能創建增量同步?在 CHANGE MASTER 語句中,指定 MODE 選項,可以指定鏈路的搭建模式 - INCREMENTAL: 直接創建增量複製鏈路 - IMAGE: 先完成全量複製,再基於全量複製開始的時間點,啟動增量複製鏈路 |
| 原生的輕量級雙向複製能力 | 在 CHANGE MASTER 語句中,組合使用 WRITE_SERVER_ID 和 IGNORE_SERVER_IDS 選項,可配置基於server_id的防流量迴環雙向複製鏈路,相比需要額外引入事務表的方案,不僅使用簡單,而且性能無損。 |
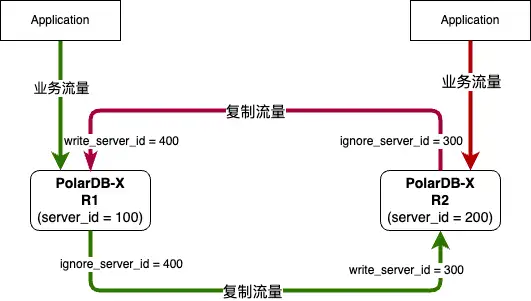
原生的輕量級雙向複製能力,舉例來說:
- PolarDB-X實例 R1 的server_id為100
- PolarDB-X實例 R2 的server_id為200
- 構建 R1 到 R2的複製鏈路時,在R2上執行CHANGE MASTER並指定WRITE_SERVER_ID = 300、IGNORE_SERVER_IDS = 400
- 構建R2 到 R1的複製鏈路時,在R1上執行CHANGE MASTER並指定WRITE_SERVER_ID = 400、IGNORE_SERVER_IDS = 300
GDN場景下,保證主從實例之間的數據一致性是最為關鍵的因素,提供便捷的數據校驗能力則顯得尤為關鍵,V2.4版本不僅提供了完善的主從複製能力,還提供了原生的數據校驗能力,在從實例上執行相關SQL命令,即可實現線上數據校驗。V2.4版本暫時只支持直接校驗模式(校驗結果存在誤報的可能),基於sync point的快照校驗能力(校驗結果不會出現誤報),會在下個版本進行開源。
#開啟校驗
CHECK REPLICA TABLE {`test_db`.`test_tb`} | {`test_db`}
[MODE='direct' | 'tso']
FOR CHANNEL xxx;
#查看校驗進度
CHECK REPLICA TABLE [`test_db`.`test_tb`] | [`test_db`] SHOW PROGRESS;
#查看差異數據
CHECK REPLICA TABLE {`test_db`.`test_tb`} | {`test_db`} SHOW DIFFERENCE;此外,數據的一致性不僅體現在數據內容的一致性上,還體現在schema的一致性上,只有二者都保證一致,才是真正的一致,比如即使丟失一個索引,當發生主從切換後,也可能引發嚴重的性能問題。PolarDB-X GDN支持各種類型的DDL複製,基本覆蓋了其所支持的全部DDL類型,尤其是針對PolarDB-X特有schema的DDL操作,更是實現了充分的支持,典型的例子如:sequenc、tablegroup等DDL的同步。
除了數據一致性,考量GDN能力的另外兩個核心指標為RPO和RTO,複製延遲越低則RPO越小,同時也間接影響了RTO,本次V2.4版本提供了RPO <= 2s、RTO分鐘級的恢復能力,以Sysbench和TPCC場景為例,GDN單條複製鏈路在不同網路延遲條件(0.1ms ~ 20ms之間)下可以達到的最大RPS分佈在2w/s 到 5w/s之間。當業務流量未觸達單條複製鏈路的RPS瓶頸時,用單流binlog + GDN的組合來實現容災即可,而當觸達瓶頸後,則可以選擇多流binlog + GDN的組合來提升擴展性,理論上只要網路帶寬沒有瓶頸,不管多大的業務流量,都可實現線性擴展,PolarDB-X GDN具備高度的靈活性和擴展性,以及在此基礎之上的高性能表現。
04 開源生態完善
快速運維部署能力
PolarDB-X支持多種形態的快速部署能力,可以結合各自需求盡心選擇
| 部署方式 | 說明 | 安裝工具的快速安裝 | 依賴項 |
| RPM包 | 零組件依賴,手工快速部署 | RPM下載、RPM安裝 | rpm |
| PXD | 自研快速部署工具,通過yaml文件配置快速部署 | PXD安裝 | python3、docker |
| K8S | 基於k8s operator的快速部署工具 | K8S安裝 | k8s、docker |
polardbx-operator是基於k8s operator架構,正式發佈1.6.0版本,提供了polardb-x資料庫的部署和運維能力,生產環境優先推薦,可參考polardbx-operator運維指南。
polardbx-operator 1.6.0新版本,圍繞數據安全、HTAP、可觀測性等方面完善集中式與分散式形態的運維能力,支持標準版的備份恢復,透明加密(TDE),列存只讀(HTAP)、一鍵診斷工具、CPU 綁核等功能。同時相容了8.0.32 新版本內核,優化了備份恢復功能的穩定性。詳見:Release Note。
pxd 是基於開源用戶物理機裸機部署的需求,提供快速部署和運維的能力, 可參考pxd運維。
發佈pxd 0.7新版本,圍繞版本升級、備庫重搭,以及相容8.0.32新版本內核。
標準版生態
V2.3版本開始,為方便用戶進行快速體驗,提供rpm包的下載和部署能力,可以一鍵完成標準版的安裝,參考鏈接:
- 基於rpm包部署polardbx-標準版 (https://doc.polardbx.com/zh/deployment/topics/deploy-by-rpm-std.html)
- 【PolarDB-X開源】基於Paxos的MySQL三副本(https://zhuanlan.zhihu.com/p/669301230)
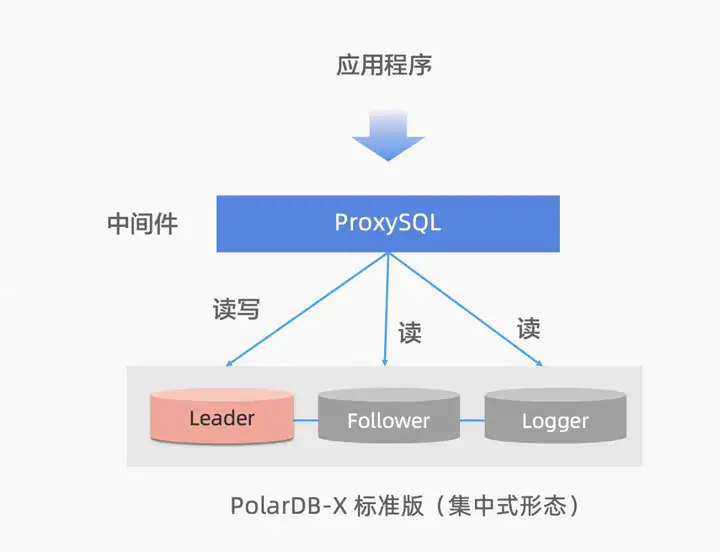
PolarDB-X標準版,基於Paxos協議實現多副本,基於Paxos的選舉心跳機制,MySQL自動完成節點探活和HA切換,可以替換傳統MySQL的HA機制。如果PolarDB-X替換MySQL,作為生產部署使用,需要解決生產鏈路的HA切換適配問題,開發者們也有自己的一些嘗試(比如HAProxy 或 自定義proxy)。 在V2.4版本,我們正式適配了一款開源Proxy組件。
ProxySQL作為一款成熟的MySQL中間件,能夠無縫對接MySQL協議支持PolarDB-X,並且支持故障切換,動態路由等高可用保障,為我們提供了一個既可用又好用的代理選項,更多信息可參考文檔:使用開源ProxySQL構建PolarDB-X標準版高可用路由服務
本文為阿裡雲原創內容,未經允許不得轉載。


