
目錄文件操作介面說明標準IO標準IO函數介紹打開文件:fopen()fopen使用相關知識補充關閉文件:fclose讀取數據字元讀取(fgetc)按行讀取按塊讀取寫入文件字元寫入字元串寫入按塊寫入讀取文件位置設置位移獲取位移格式訪問 文件操作介面說明 Linux系統為了簡化不同類型文件的操作流程,在 ...
目錄
文件操作介面說明
Linux系統為了簡化不同類型文件的操作流程,在設計訪問介面時也遵循POSIX標準,而POSIX標準就是對不同操作系統的訪問介面做出統一的規範,目的是提高程式的相容性和可移植性。
大家經常使用的C語言同樣具有語法標準,並且C語言標準在發佈的時候也會發佈對應的庫函數提供給用戶。這些庫函數也同樣遵循POSIX標準進行設計,而遵循POSIX標準設計出來的函數的集合也被稱為標準庫,比如大家使用的標準C庫中提供了標準的輸入輸出函數,這些函數在Linux系統可以使用,同樣也可以在Windows系統中使用。用戶可以根據標準輸入輸出頭文件<stdio.h>中的函數聲明進行調用,Linux系統下該頭文件路徑為 /user/include。
另外,由於任何一種操作系統都會有訪問磁碟文件的需求,所以POSIX標準中同樣對訪問文件的輸入輸出介面做出了約束,這些訪問文件的函數介面在C語言標準中都有具體的描述。
標準IO
標準C庫中關於文件輸入輸出的函數介面一般被稱為標準IO,訪問文件常用的標準IO函數有fopen()、fread()、fwrite()、fclose()、fgetc()、fputc()、fgets()、fputs()、fprintf()、fscanf()等。
標準IO函數介紹
打開文件:fopen()
想要對文件進行讀寫訪問的前提是必須先打開文件,標準IO中提供了一個函數叫做fopen(),用戶只需要包含標準輸入輸出頭文件 #include <stdio.h> 即可調用。
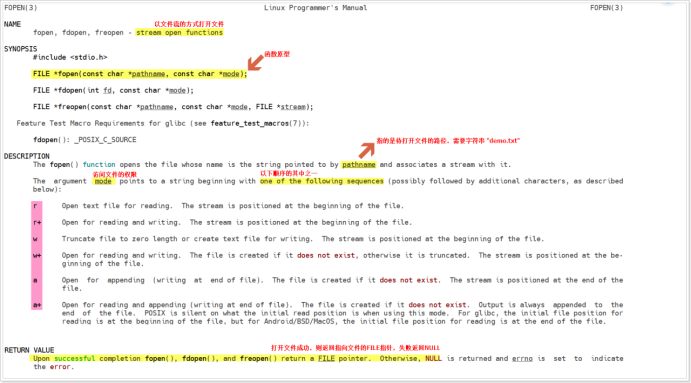
如上圖所示,調用fopen時需要傳入兩個參數,前者為即將要打開的文件,格式為 “xxx.c”,在未標明路徑的前提下,預設打開當前路徑下的文件,若是想要打開別的路徑下文件,需要加上路徑名,格式為“/demo/demo.c”;後者為需要以怎樣的方式打開該文件,具體分類如下圖:
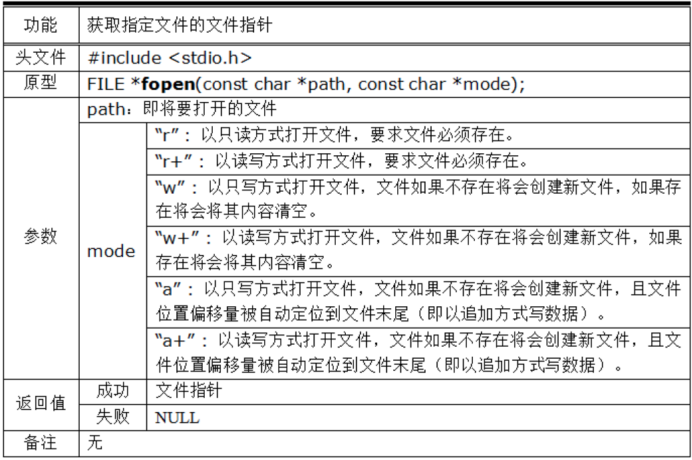
fopen函數是有返回值的,如果文件打開成功,則返回值返回指向該文件的文件流指針,如果文件打開失敗,則返回值為NULL。
fopen使用相關知識補充
- 為什麼某些情況下,打開的文件大小與Linux內儲存文件大小不同?
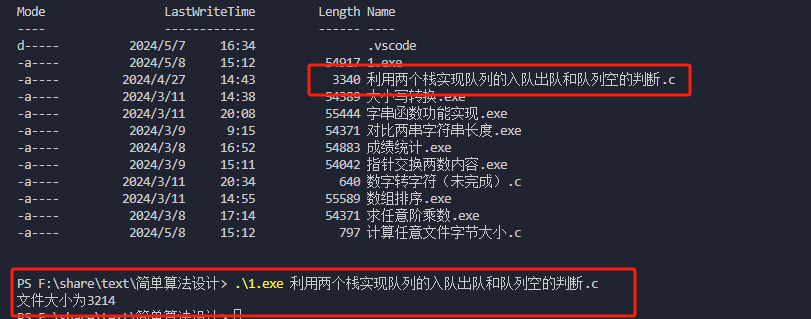
原因:因為在使用上圖mode打開文件時,預設是將文件以文本(.txt)形式打開,該打開過程中,系統會對文件內容進行解釋轉換,最終導致兩個文件大小不一致
解決辦法:在C99標準中,提供了幾個mode,其與上圖mode的區別在於,打開文件時是以二進位形式打開,此時打開方式與linux一致,便不會出現上圖中文件大小不一致的情況。其他特性與不加b的mode保持一致。

註意:
- 多出來的mode只在C99後標準有效,在C89標準中,使用無效,系統還是會按照文本形式打開文件。
- 使用"a"與”a+“打開文件時,游標會被定位至文件末尾,而其餘模式,游標則是會被定位至文件開頭。
- fopen函數的返回值是一個指向被打開文件的FILE類型的指針,請問FILE類型是什麼?
回答:
FILE類型其實是一個結構體數據類型,它包含了標準 I/O 庫函數為管理文件所需要的所有信息,比如包括用於實際I/O 的文件描述符、指向文件緩衝區的指針、緩衝區的長度、當前緩衝區中的位元組數以及出錯標誌等。頭文件stdio.h中有關於FILE類型的相關描述,如:

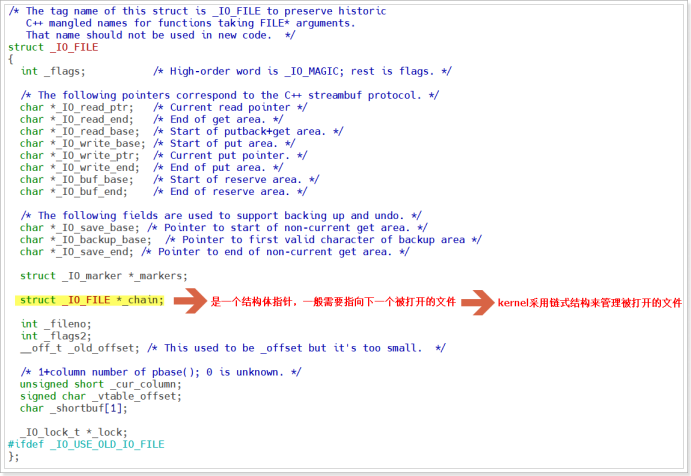
- 可以看到FILE類型其實就是一個結構體,結構體類型名稱為struct _IO_FILE,但是經過查找之後發現頭文件stdio.h中並沒有關於該結構體的定義,那這個結構體中到底都有哪些成員?
回答:閱讀stdio.h中的條件編譯選項可以發現在stdio.h中還包含了另一個頭文件<libio.h>,這個頭文件中才有關於FILE結構體類型的定義,該頭文件的路徑同樣在Linux系統的/user/include目錄下。

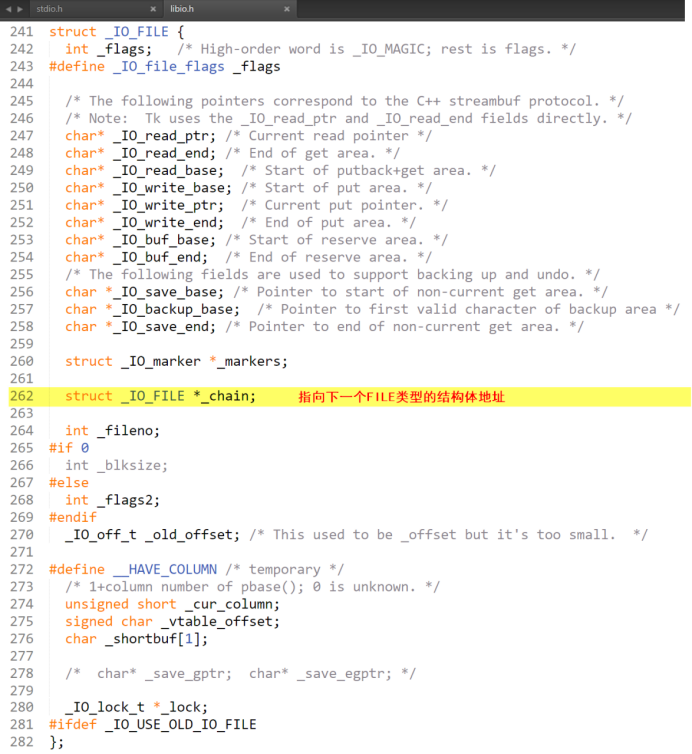
可以看到FILE結構體類型中有一個成員是FILE類型的指針變數chain,該指針可以指向下一個被打開文件的文件信息區,也就是可以把FILE類型當做數據結構中的鏈表的結點,結點中除了可以存儲數據域之外,還可以利用指針域存儲下一個結點的地址。
簡單理解:用戶可以在一個程式中利用fopen函數打開多個文件,每次打開一個文件,內核就會從*堆記憶體*中申請一塊FILE結構體大小的空間用來存儲文件的所有信息,然後按照文件打開的順序把每個打開的文件的結構體形成一條鏈表,然後使用鏈表頭進行管理。
註意:打開文件的目的無非就是對文件進行讀寫操作,所以每次當程式運行的時候已經有三個文件流被打開,分別是標準輸入stdin、標準輸出stdout、標準出錯stderr,這三者在stdio.h中也是FILE指針。
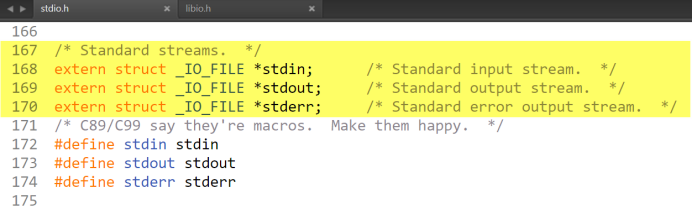
所以內核在管理被打開文件的時候,鏈表中已經有三個結點存在,然後再把新節點頭插入到鏈表中。
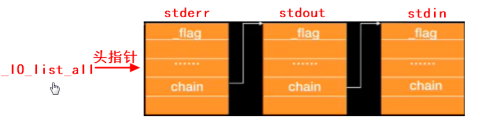
- 請問為什麼內核在為文件流申請記憶體的時候是申請的堆記憶體?請問有什麼具體依據?
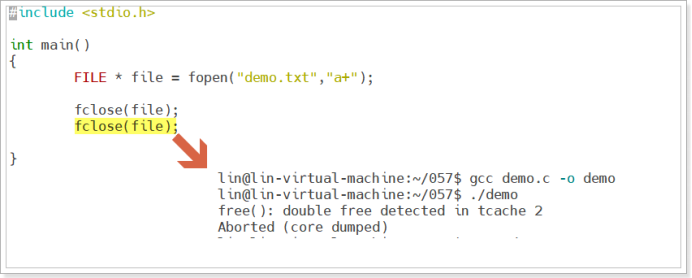
回答:如上圖所示,當我們對打開的一個文件進行兩次關閉時,系統在執行時會報不能兩次釋放該記憶體的錯誤,我們可知,fclose實際上是間接調用了free函數進行文件的關閉,側面驗證了內核為文件流申請記憶體時申請的是堆記憶體。
註意:
- 使用標準IO的時候,是不可以反覆關閉相同的文件,因為釋放已經被釋放的堆記憶體,會導致段錯誤!!
- 但是可以反覆打開同一文件,只不過申請的堆記憶體的地址是在變化的,且關閉時需要一一對應關閉,即打開幾次就需要關閉幾次。
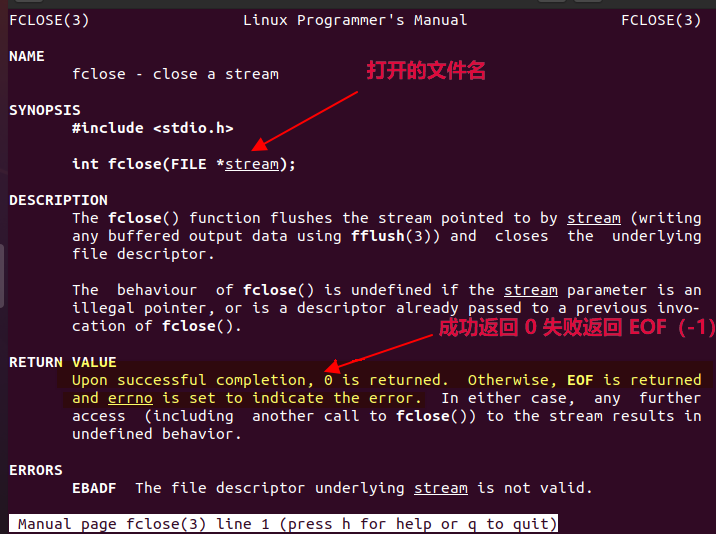
關閉文件:fclose
利用fopen()打開文件之後內核會申請一塊堆記憶體用來存儲文件信息,申請的堆記憶體大小就是FILE結構體類型的大小,那麼如果用戶完成了對文件的讀寫訪問之後,則需要利用fclose()函數來關閉文件,這樣這塊堆記憶體就會被內核先從鏈表中刪除,然後再釋放掉。
讀取數據
用戶打開文件後可以從文件中讀取數據,標準C庫中提供了多個讀取函數來滿足用戶的不同需求,這些函數大體分為三類:字元讀取(fgetc)、按行讀取(fgets)、按塊讀取(fread)。
字元讀取(fgetc)


標準庫中提供了一個fgetc函數,通過C99標準可以知道該函數的作用是從文件指針stream指向的文件中讀取一個字元,併在讀取一個位元組後把文件的游標位置向後移一個位元組,然後把讀取到的字元所對應的ASCII碼通過返回值返回。
在調用該函數時如果文件的游標已經到達文件末尾或者遇到讀取錯誤時,則函數會返回EOF,EOF是文件結束標誌,其實是個巨集定義,巨集定義的值為 -1,在頭文件libio.h中有相關描述。

另外,在標準庫中還提供了另一個*函數getc()*,這個函數的作用等效於fgetc()函數,只不過getc()函數的實現是利用巨集定義而已。二者的作用是一致的,總體上來說這兩個函數是等價的,但是fgetc函數的使用頻率會更高。


而還有一個函數可以完成讀取字元的工作---getchar(),但是該函數相較於fgetc()和getc()來說,存在局限性,getchar()函數只能從stdin(標準輸入)中讀取一個字元。

註意:
- 某種特殊情況下,三個函數的作用一致,如:
getchar() == fgetc(stdin) == getc(stdin)
- 當讀取數據失敗時,我們無法通過返回值判斷是到達文件末尾還是遇到了錯誤
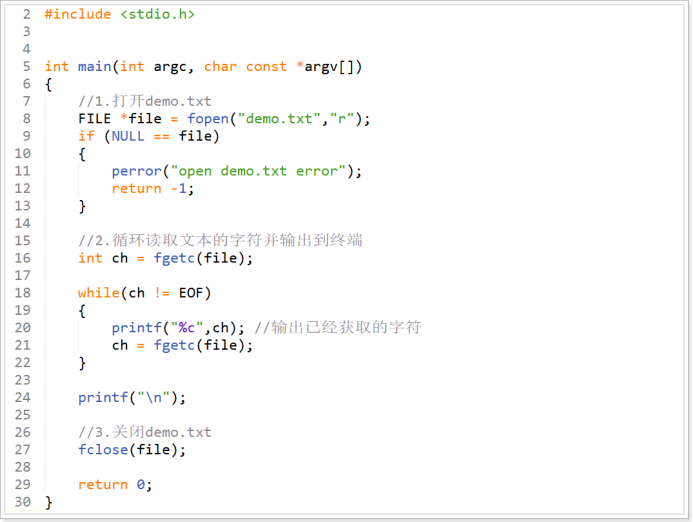
練習:在本地磁碟打開一個存儲少量數據的文本demo.txt,利用fgetc函數把文本中的字元輸出到屏幕,當文本中所有字元都輸出完成後就結束程式。
按行讀取

標準庫中提供了一個*fgets*函數,通過C99標準可以知道該函數的作用是從文件指針stream指向的文件中讀取一行字元,並把讀取的字元存儲在指針s所指向的字元串內,n為自定義的緩衝區大小,FILE *為需要讀取的目標文件。讀取成功後,返回自定義緩衝區指針s,讀取失敗時,返回NULL;
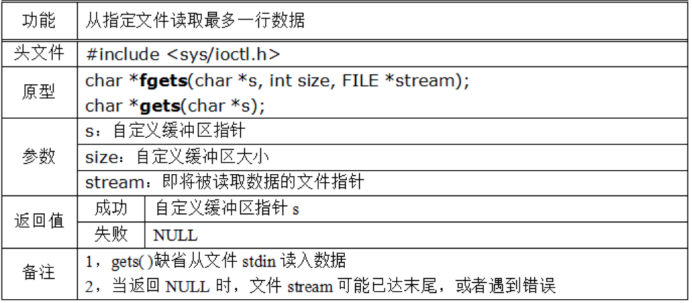
fgets讀取結束情況:
- 當讀取到n-1個字元時
- 已經讀取到文件末尾(EOF)
- 讀取到換行符’\n’時
**思考: ** 為什麼fgets函數讀取到換行符\n時會結束?fgets函數中的參數n的意義是什麼??
回答:用戶調用fopen打開文件之後,可以把數據寫入到文件中以及從文件中讀取數據,但是實現讀取和寫入的過程中其實內核並沒有直接操作文件,而是在操作指向文件的結構體指針FILE,也就是用戶寫入的數據和讀取的數據會先存儲在FILE結構體的*緩衝區*中,當用戶調用刷新緩衝區的函數或者其他讀寫函數時,FILE結構體的緩衝區會被刷新,數據才會被系統寫入文件。
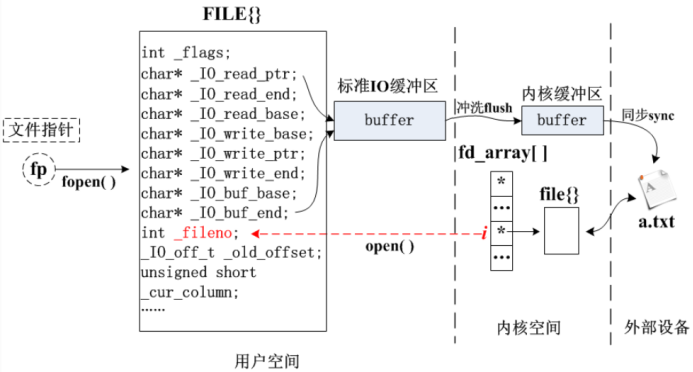
可以看到,每當使用標準IO的讀操作函數,試圖將數據從文件 a.txt讀取出來時,數據都會流過標準*輸入**緩衝區*,然後再在適當的時刻沖洗(或稱刷新,flush)到內核緩衝區,最後才真正得到數據。
思考:什麼是緩衝區?為什麼要有緩衝區?
緩衝區的出現其實就是由於輸入設備和輸出設備對於數據的讀寫速度比較慢,其實就是CPU為了降低輸入輸出次數,目的是為了提高運行效率,避免長時間的等待,所以內核就在記憶體中提供了一塊空間作為緩衝區,緩衝區也可以稱為緩存(Cache),是屬於記憶體空間的一部分。
根據IO設備的不同,可以把緩衝區分為輸入緩衝區和輸出緩衝區【也可以叫做讀緩存區和寫緩衝區】,同樣,根據刷新形式的不同,可以把緩衝區分為三種:全緩衝、行緩衝、無緩衝。
- 全緩衝:指的是當緩衝區被填滿就立即把數據沖刷到文件、或者在關閉文件、讀取文件內容以及修改緩衝區類型時也會立即把數據沖刷到文件,一般讀寫文件的時候會採用
- 無緩衝:指的是沒有緩衝區,直接輸出,一般linux系統的標準出錯stderr就是採用無緩衝,這樣可以把錯誤信息直接輸出。
- 行緩衝:指的是當緩衝區被填滿(一般緩衝區為4KB,就是4096位元組)或者緩衝區中遇到換行符’\n’時,或者在關閉文件、讀取文件內容以及修改緩衝區類型時也會立即把數據沖刷到文件中,一般操作IO設備時會採用,比如printf函數就是採用行緩衝。
當然,全緩衝和行緩衝除了以上幾種情況外,當程式結束時緩衝區也會被刷新,另外,也可以採用函數庫中的fflush函數手動刷新緩衝區。

註意:
| 緩衝類型 | 全緩衝 | 無緩衝 | 行緩衝 |
|---|---|---|---|
| 例子 | 普通文件 | stderr(標準出錯) | stdout(標準輸出) |
按塊讀取
標準庫中提供了一個fread函數,通過C99標準可以知道該函數的作用是從給定的文件輸入流stream中讀取最多nmemb個對象到指針ptr指向的字元串中,每個對象的大小為size位元組,函數返回成功讀取的對象個數,若出現錯誤或到達文件末尾,則可能小於nmemb。即讀取是否成功需要拿返回值與預計值進行比較。
註意:若size或nmemb為零,則fread函數返回0且不進行其他動作。但是這樣使用並不會報錯,只是意義而已。


思考:可以知道函數的返回值如果小於nmemb則說明可能出現讀取錯誤或者到達文件末尾,那應該如何區分這兩種情況?
回答:可以通過標準庫中提供的兩個函數區分,一個函數是feof(),另一個則是ferror函數。
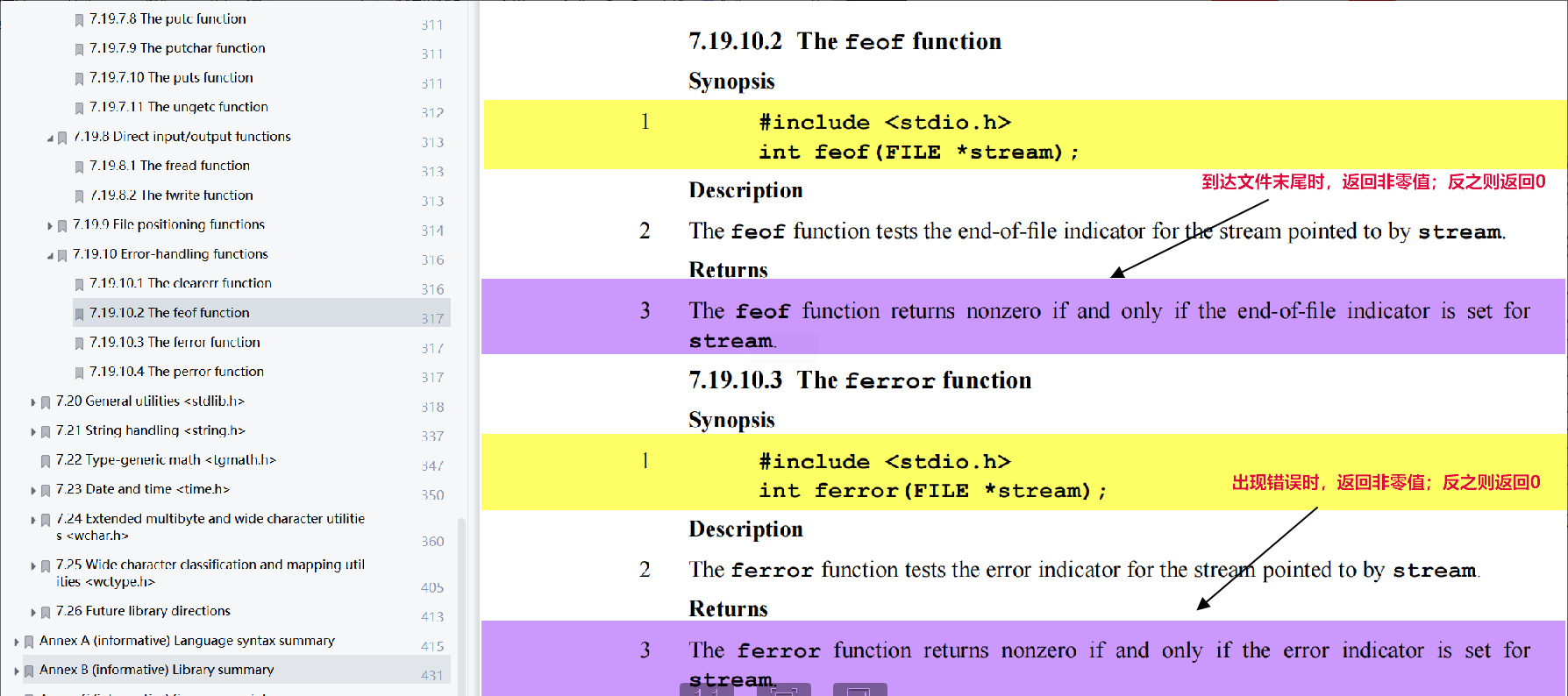
註意:
feof 函數在C語言中用於檢測文件結束標誌是否設置。但是, feof 的行為可能會讓人有些誤解,因為它並不直接檢測文件是否已到達未尾。相反,它檢測的是在上一次調用文件讀取函數(如 fgetc、fread 等)時是否遇到了文件結束(EOF)標記。
也就是說,feof並不是通過此時游標所在位置來判斷是否到達文件末尾,所以並不能通過結合使用fseek函數來判斷是否到達文件末尾。
具體來說,feof 的工作原理是這樣的:
1.當你嘗試讀取一個文件時,如果文件尚未到達末尾,feof 將返回0(假)
2.當你讀取到文件的末尾時,並不會立即設置文件結束標誌。相反,當你嘗試再次讀取(即超過文件的未尾)時,文件結束標誌會被設置,並且此時 feof 將返回非0值(真)。
3.如果你在讀取文件末尾後沒有再次嘗試讀取,那麼 feof 仍然會返回0(假),!即使文件實際上已經讀取完畢。
因此,在使用 feof 時,,一個常見的做法是在一個迴圈中讀取文件,併在迴圈結束後檢查 feof 的值來確定是否已到達文件末尾。但是,請請註意,如果文件讀取操作因為其他原因(如磁碟錯誤、許可權問題等)而失敗,feof 也可能返回非0值。因此,通常還需要檢查 ferror 函數來確定是否發生了錯誤。
寫入文件
字元寫入


註意:
特殊情況下,三種函數作用一致,如:
putchar(a) == fputc(a, stdout) == putc(a, stdout)
字元串寫入


註意:
- 字元串寫入時,fputs和puts均遇到'\0'便會結束寫入
- puts函數擁有著自動換行和自動刷新緩衝區的特性
按塊寫入

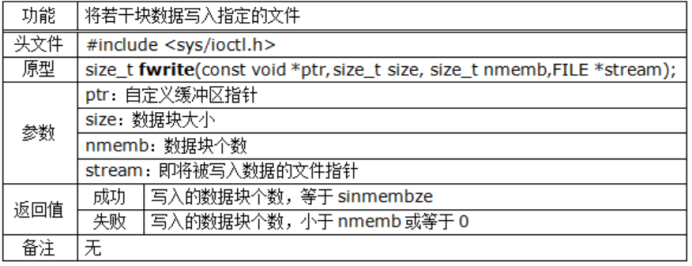
與按塊讀取函數fread特性大體一致,均是依靠返回值與目標值比較來判斷是否寫入成功,且若size或nmemb為零,則fread函數返回0且不進行其他動作。但是這樣使用並不會報錯,只是意義而已。
讀取文件位置
每個被打開文件的結構體中都有一個位置指示器(簡單理解:位置指示器是文件游標),註意:被打開的文件的游標預設是在文件開頭的。除非打開的模式是“a"或者"a+"。
設置位移

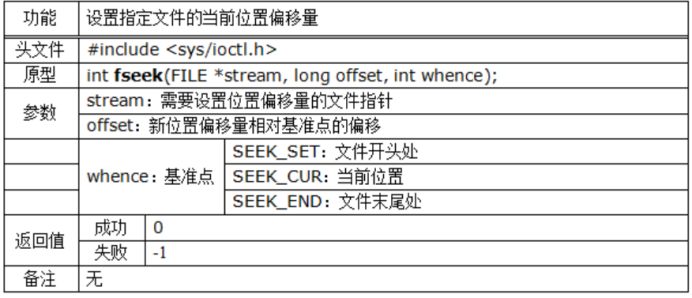
註意:
該設置游標位置可以靈活使用,來滿足當前需要的條件。如:
當我們利用模式“a”打開文件後,又需要將游標偏移至文件首部,則可以利用 fseek(p,0,SEEK_SET)指令
獲取位移

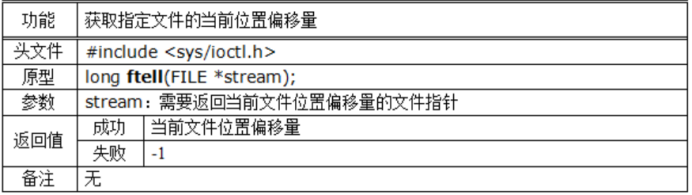
註意:
該函數返回的文件位置偏移量是相對於文件開頭來說的
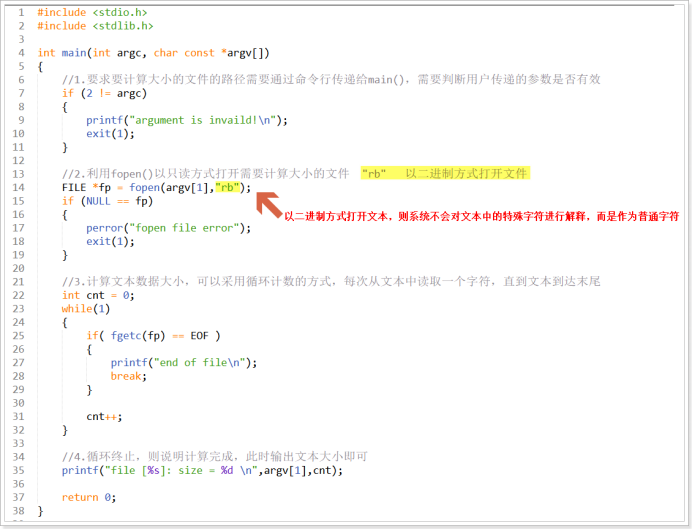
練習:
要求利用標準IO函數介面實現計算一個本地磁碟某個文件的大小,要求文件名稱通過命令行進行傳遞,併進行驗證是否正確( ls -l)。

格式訪問
標準庫中除了以上關於文件讀寫的函數之外,還提供了一些可以對文件進行格式化讀寫的函數介面,在C99標準中有關於這些函數的描述,如下:
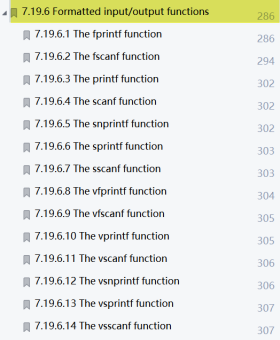
註意:一般常用的關於文件IO的格式化函數有printf、fprintf、scanf、fscanf、sprintf、snprintf。




