
如果讓你來做一個有狀態流式應用的故障恢復,你會如何來做呢? 單機和多機會遇到什麼不同的問題? Flink Checkpoint 是做什麼用的?原理是什麼? ...
如果讓你來做一個有狀態流式應用的故障恢復,你會如何來做呢?
單機和多機會遇到什麼不同的問題?
Flink Checkpoint 是做什麼用的?原理是什麼?
一、什麼是 Checkpoint?
Checkpoint 是對當前運行狀態的完整記錄。程式重啟後能從 Checkpoint 中恢復出輸入數據讀取到哪了,各個運算元原來的狀態是什麼,並繼續運行程式。
即用於 Flink 的故障恢復。
這種機制保證了實時程式運行時,即使突然遇到異常也能夠進行自我恢復。
二、如何實現 Checkpoint 功能?
如果讓你來設計,對於流式應用如何做到故障恢復?
我們從最簡單的單機單線程看起。
一)單機情況
同步執行,每次只處理一條數據
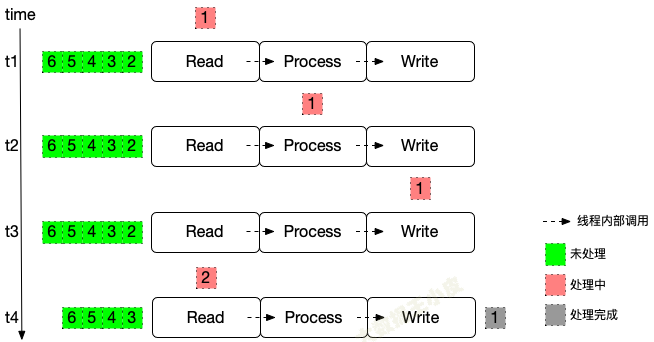
很簡單,這種情況下,整個流程一次只處理一條數據。
- 數據到 Write 階段結束,各個運算元記錄一次各自狀態信息(如讀取的 offset、中間運算元的狀態)
- 遇到故障需要恢復的時候,從上一次保存的狀態開始執行
- 當然為了降低記錄帶來的開銷,可以攢一批之後再記錄。
同時處理多條數據
每個計算節點還是只處理一條數據,但該節點空閑就可以處理下一條數據。
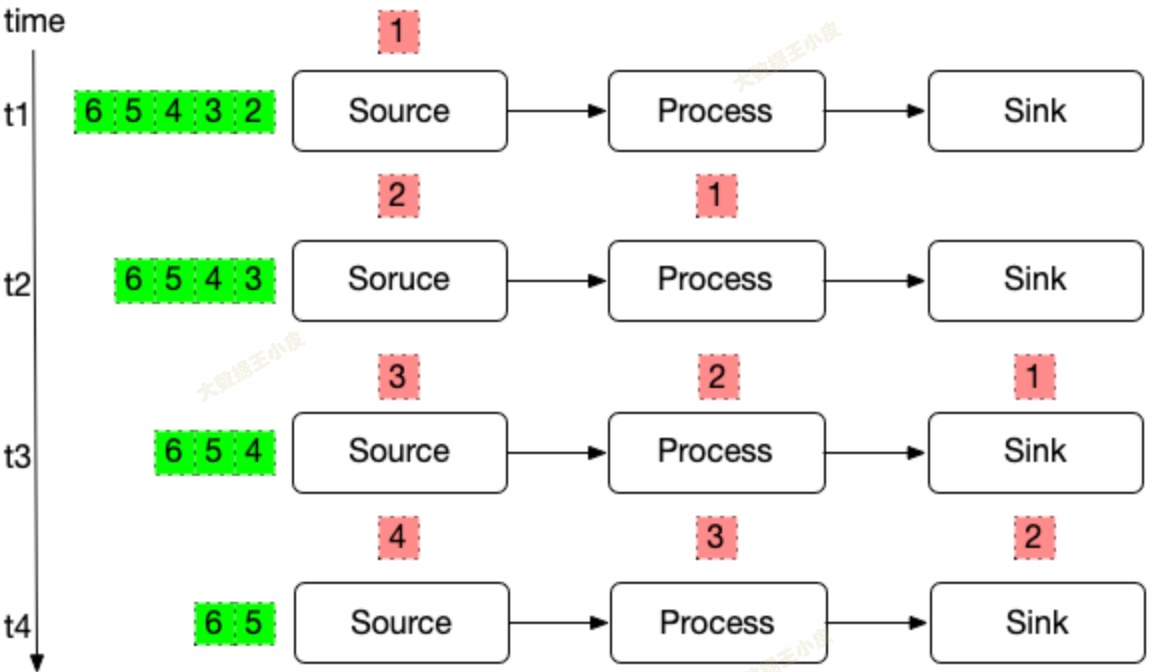
如果還按照一個數據 Write 階段結束開始保存狀態,就會出現問題:
- 前面節點的狀態,在處理下一個數據時被改過了
- 從此時保存的記錄恢復,前面的節點會出現重覆處理的問題
- 此時被稱為 - 確保數據不丟(At Least Once)
一種解決方式:
- 在輸入數據中,定期插入一個 barrier。
- 各運算元遇到 barrier 就開始做狀態保留,並且不再接收新數據的計算。
- 當前運算元狀態保留後,將 barrier 傳遞給下一個運算元,並重覆上面的步驟。
- 當 barrier 傳遞到最後一個運算元,並完成狀態保留後,本次狀態保留完成。
這樣,各個節點保存的都是相同數據節點時的狀態。
故障恢復時,能做到不重覆處理數據,也就是精確一次(Exactly-once)。
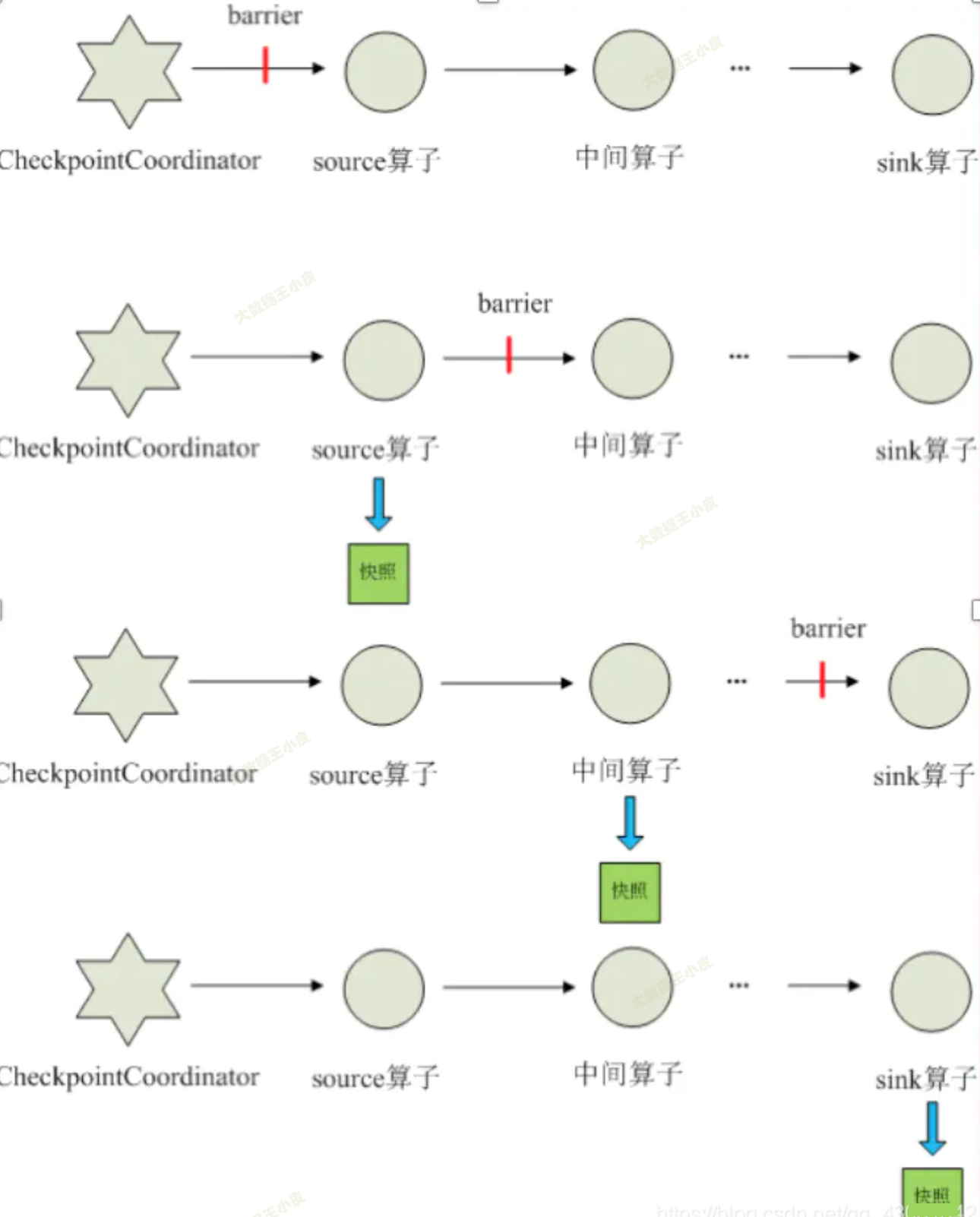
但這裡,你可能會發現一個問題:
- 數據已經寫出了怎麼辦?在兩個保存點之間,已經把結果寫到外部了,重啟後不是又把部分數據再寫了一次?
這裡實際是「程式內部精確一次」和「端到端精確一次」。
那麼如何做到「端到端精確一次」?
- 方案一:最後一個 sink 運算元不直接向外部寫出,等到 barrier 來了,才把這一批數據批量寫出去
- 方案二:兩階段提交。需要 sink 端支持(如 kafka)。
- 方式類似於 MySQL 的事務。
- sink 端正常向外部寫出,不過輸出端處於 pre-commit 狀態,這些數據還不可讀取
- 當 sink 端等到 barrier 時,將輸出端數據變為 committed,下游輸出端的數據才正式可讀
不過以上方法為了做到端到端精確一次,會帶來數據延遲問題。(因為要等 Checkpoint 做完,數據才實際可讀)。
解決數據延遲有一種方案:
- 方案:冪等寫入。同樣一條數據,無論寫入多少次對輸出端看來都是一樣的。(比如按照主鍵重覆寫這一條數據,並且數據本身沒變化)
二)重要概念介紹
一致性級別
前面的例子中,我們提到了部分一致性級別,這裡我們總結下。在流處理中,一致性可以分為 3 個級別:
- at-most-once(最多一次): 這其實是沒有正確性保障的委婉說法——故障發生之後,計數結果可能丟失。
- at-least-once (至少一次): 這表示計數結果可能大於正確值,但絕不會小於正確值。也就是說,計數程式在發生故障後可能多算,但是絕不會少算。
- exactly-once (精確一次): 這指的是系統保證在發生故障後得到的計數結果與正確值一致。恰好處理一次是最嚴格的保證,也是最難實現的。
按區間分:
- 程式(Flink)內部精確一次
- 端到端精確一次
Checkpoint 中保留的是什麼信息?


