
AI大模型的相關的一些基礎知識,一些背景和基礎知識。 多模型強應用AI 2.0時代應用開發者的機會。 0 大綱 AI產業的拆解和常見名詞 應用級開發者,在目前這樣一個大背景下的一個職業上面的一些機會 實戰部分的,做這個agent,即所謂智能體的這麼一個虛擬項目,項目需求分析、技術選型等 1 大語言模 ...
AI大模型的相關的一些基礎知識,一些背景和基礎知識。
多模型強應用AI 2.0時代應用開發者的機會。
0 大綱
- AI產業的拆解和常見名詞
- 應用級開發者,在目前這樣一個大背景下的一個職業上面的一些機會
- 實戰部分的,做這個agent,即所謂智能體的這麼一個虛擬項目,項目需求分析、技術選型等
1 大語言模型發展
LLM,Large Language Model,大語言模型。為什麼叫2.0?因為在大語言模型,也就是LLM出現之前,我們把它歸結為1.0時代。那麼1.0時代主要的是NLP(自然語言處理)的各類工程,它其實都是一個特點,就是說通用性比較差。那麼整個AI領域的終極的聖杯,或者說將來它的一個終極的一個希望做到的,是AGI(Artificial General Intelligence,人工通用智能)。1.0可能是一個單任務的這麼一個AI。比如深藍戰勝象棋冠軍,他只會下象棋,而且他的下象棋是學習了很多的這個象棋的這個國際象棋的這個套路,他只會幹這一個事情,而且你問他別的事情他肯定不知道。
2 LLM的特點
大語言模型的特點是啥?大語言模型,它就是說可以像語言一樣跟我們交互,那麼通過語言,它其實可以擴展到很多的場景。那麼未來呢,可能會從依據大語言這種方式,我們可能會發展出來真的發展出來AGI,所謂的通用智能,也就是跟我們人類一樣擁有智慧的這樣的一個智能體。那好,那我們1.0我們AI 1.0我們就不做介紹了,那裡面其實有很多NLP的相關的東西。
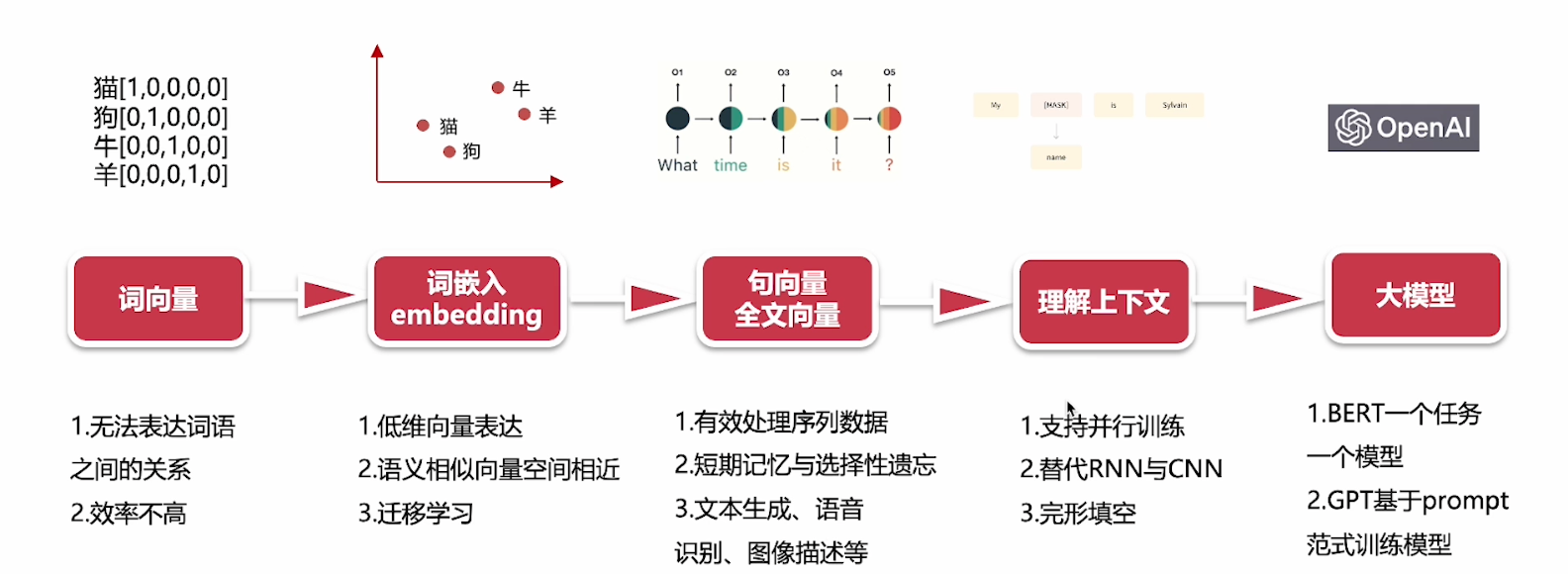
2.0開始介紹,技術層面基本上是一個從點到面的一個過程。那麼最早出現的一個技術,是詞向量技術,把自然語言的詞語,使用向量來表示。向量是一個數學概念,比如貓,這個詞在向量空間裡面,它可能就表示成這樣一個坐標位置。狗可能就跟它有所區別。牛又不一樣。所以可理解為,每一個詞,它在向量空間裡面都有一個唯一坐標,然後就可構成這樣的一個詞語字典。然後使用這種one-hot的方式來表示,如蘋果標註成101這樣的坐標。把自然語言,通過數學語言去給它描述出來,而且它是一個坐標,可精準找到它位置。
3 大模型的不足和解決方案
但有問題,它沒有辦法表達詞語和詞語之間的這個關係。比如貓1這樣一個坐標,和狗這樣01一個坐標,之間什麼關係呢?不知道的。
第二就是效率不是很高。
後面發展中,在這個詞向量的基礎上,出現
4 詞嵌入(embedding)
也繼續叫詞向量也可以,就是對語言模型進行預訓練。我們通過大量現有文章資料,讓我們的這前面這些詞向量,它具備語言信息。那通過了一些訓練的預訓練之後的這個詞向量,它在這個向量空間上,它就帶上了一些額外的信息,它就會有效提升我們模型的效果。而且在後續的其他任務中間,去做一個遷移。那麼這個就是大語言模型的預訓練的這個,一個初始的一個原型。
比如貓、狗,通過坐標標註,讓它有這種低維向量的這種這種表示。還可有這樣語義相似的一個向量空間相近,好比我們認為,比如說貓和狗,通過我們的預訓練的這些大量的文章,資料,我們發現貓和狗都同屬於寵物。那麼有可能這兩個坐標點,在向量空間里就是比較接近。比如說我們找寵物的時候,那麼在這個向量空間裡面,貓和狗就是在寵物這個向量域裡面。牛和羊,都屬於我們的常用的肉吃的家畜,那可能就是在那個向量域裡面。所以呢,我們可以看到詞向量,它就是一個地位向量表示,再一個是語義相似的向量空間,相近的這麼一個特性。還有一個,它可以遷移學習,把這個任務,遷移到其他任務裡面去。深藍的下象棋例子,就可以把它的技能去遷移啦。
在詞嵌入之後出現
5 巨向量和全文向量
根據這個前文信息,去分析下文或根據本文翻譯成另一種語言。那麼它代表的呢,是一些模型,如:
- RNN(Recurrent Neural Network,迴圈神經網路)
- LSTM(Long Short-Term Memory,長短期記憶網路)
它可有效處理這種時序性的,序列數據。"What time is it?",訓練時,它是一層一層的,它第一層這個神經網路,可能先看到"What",然後"time","is","it",看到最後的問號。它會通過這樣的一個順序,去處理這樣的一個語句,去做一個上下文的一個理解。它還可以做到一些短時記憶和選擇性的遺忘,就是RNN和LSTM,那麼它主要應用在像文本生成啊,語音識別啊,圖像描述等等。這個時候就是比如說類似RNN和LSTM這樣的模型出現的時候呢,它其實已經可以做到我們常見的一些AI識別。
再往後就到理解上下文,就是全文的上下文,如"買什麼 什麼is"這個這個模式理解上下文,這個模式代表作是類似比如說這個BERT這樣大模型。到這階段,已經可完成類似完形填空任務。那它就是根據上下文理解當前的代詞,比如說男他女她動物它是什麼,完成這個完形填空。那麼這個時候就屬於所謂的真域訓練模型時代開啟。
特點
支持並行訓練,如說CNN(Convolutional Neural Network,捲積神經網路)這個模型比,就比如說這個"What time is it",只能一層一層處理,不支持並行訓練。必須完成這個事情之後再做下一個事情。
所以呢,它替代RNN和CNN這樣神經網路,更強大,可以實現一些類似語義識別。
最後就是OpenAI這GPT(Generative Pre-trained Transformer)出現,這個模型出現為代表,我們就正式進入了這種超大模型和模型統一的時代。從谷歌T5(Text-to-Text Transfer Transformer)這個模型開始的時候,它是引入了的這樣的一個模式來訓練模型。也就是說,它是把提示詞告訴模型,然後把答案訓練出來,然後不停的用這樣的模式來訓練模型。那麼當我們在問模型這些問題的時候,其實也是通過,通過提示詞,通過prompt的方式來引導它。所以到這個時代的時候呢,那我們以chatgpt為代表,我們發現它的效果非常驚艷。最新的成果就是說,我們的大模型已經支持了多模態,OpenAI開啟的這個大模型時代呢,它其實是把這個,一種基於的這種訓練模型這種方式提了出來。
所以我們為什麼開始一講就是說,它整個的大模型的發展,可以說是從一個從點到面的這麼一個發展過程。大家知道理解就是它最核心,其實最早的是基於這個詞向量的這麼一個技術。那麼通過這個不斷的發展到神經網路,到這種單線的,到並行訓練,最後直到這樣的一個大規模超大規模的這樣一個訓練集,實現了這麼一個大語言的一個模型的發展。
關註我,緊跟本系列專欄文章,咱們下篇再續!
作者簡介:魔都技術專家,多家大廠後端一線研發經驗,在分散式系統、和大數據系統等方面有多年的研究和實踐經驗,擁有從零到一的大數據平臺和基礎架構研發經驗,對分散式存儲、數據平臺架構、數據倉庫等領域都有豐富實踐經驗。
各大技術社區頭部專家博主。具有豐富的引領團隊經驗,深厚業務架構和解決方案的積累。
負責:
- 中央/分銷預訂系統性能優化
- 活動&優惠券等營銷中台建設
- 交易平臺及數據中台等架構和開發設計
- 車聯網核心平臺-物聯網連接平臺、大數據平臺架構設計及優化
目前主攻降低軟體複雜性設計、構建高可用系統方向。
參考:
本文由博客一文多發平臺 OpenWrite 發佈!


