
在剛剛過去的2024春季發佈會上,袋鼠雲帶來了數棧產品V6.2版本的全新發佈。其中,EasyMR 作為數棧V6.2中的一項關鍵能力,代表了袋鼠雲對大數據生態的深入理解和持續創新。 EasyMR(後文統稱EMR)是袋鼠雲基於 Hadoop、Hive、Spark、Flink、HBase 等開源組件,構建 ...
在剛剛過去的2024春季發佈會上,袋鼠雲帶來了數棧產品V6.2版本的全新發佈。其中,EasyMR 作為數棧V6.2中的一項關鍵能力,代表了袋鼠雲對大數據生態的深入理解和持續創新。
EasyMR(後文統稱EMR)是袋鼠雲基於 Hadoop、Hive、Spark、Flink、HBase 等開源組件,構建的彈性計算引擎,提供安全可靠、彈性伸縮、低成本的大數據存儲與計算服務。其中自主研發的 EasyManager 企業級大數據運維管理平臺支持 Hadoop 集群的一站式創建、管理、部署、運維與監控功能,提供高效搭建數據中台解決方案。
面對企業日益增長的數據處理和分析需求,EMR6.2版本,將為用戶提供更為出色的大數據運維服務及計算性能優化。以下是針對 EMR6.2 版本四大功能優化的詳細介紹,幫助用戶全面瞭解這一創新產品。
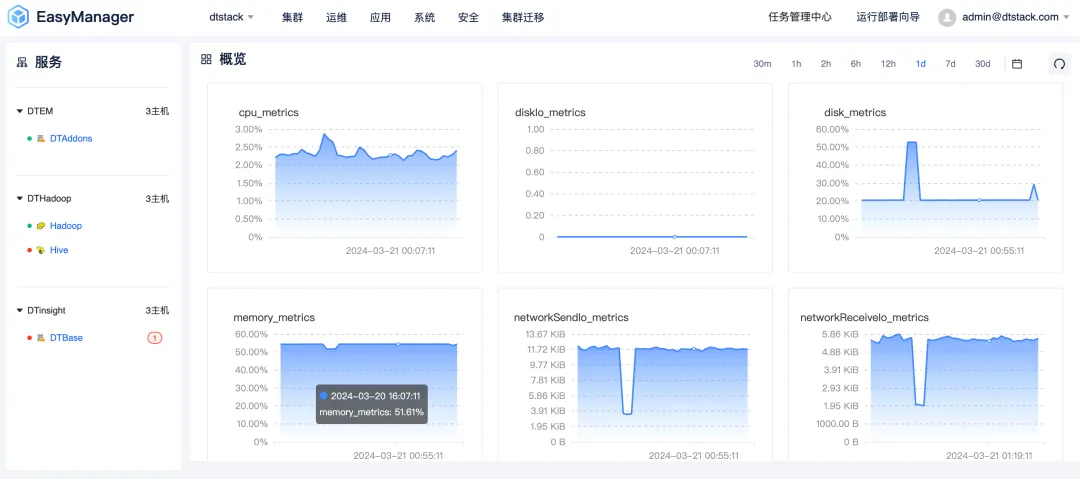
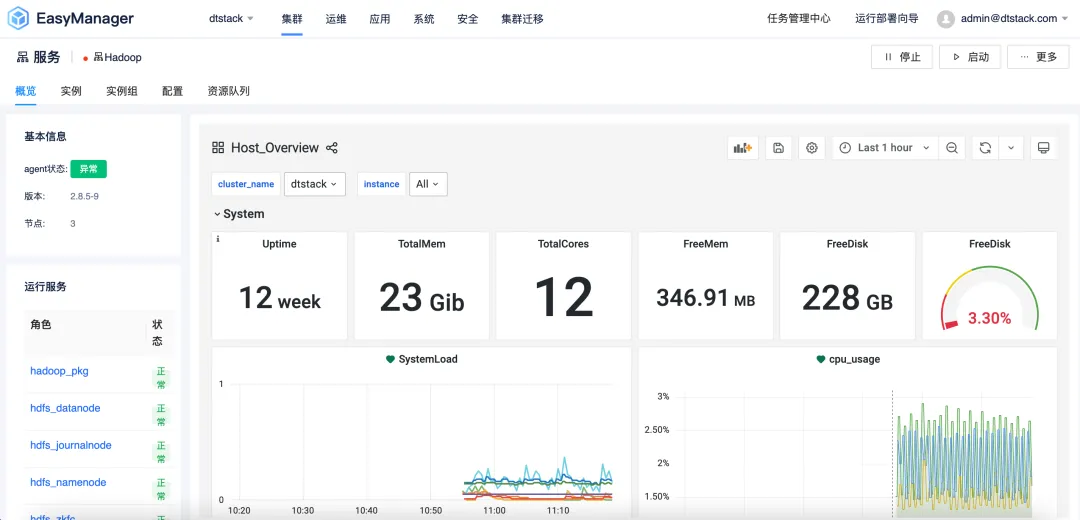
UI全面煥新升級:簡約舒適的交互體驗
袋鼠雲深知用戶體驗的重要性,因此在 EMR6.2 版本中,我們對 UI 界面進行了全面的煥新升級。新的界面設計遵循了簡約而不失優雅的風格,旨在為用戶提供一個直觀、舒適的交互體驗。無論是新手還是資深用戶,都能迅速上手,輕鬆管理複雜的大數據集群。
此外,我們還優化了界面的響應速度和操作流暢性,確保用戶在集群運維時能夠享受到更加順滑的操作體驗。
差異化配置:滿足多樣化需求
EMR6.2 版本引入了實例組-差異化配置功能,允許用戶根據自己的具體需求定製集群配置。用戶可以把 EMR 集群中的不同節點構建獨立實例組,實例組中設置特定的配置參數,以實現更好的性能、資源利用和任務調度。
無論是對於成本敏感的初創企業,還是對於性能有更高要求的大型企業,EMR6.2 都能提供靈活的配置選項,滿足不同用戶的需求。
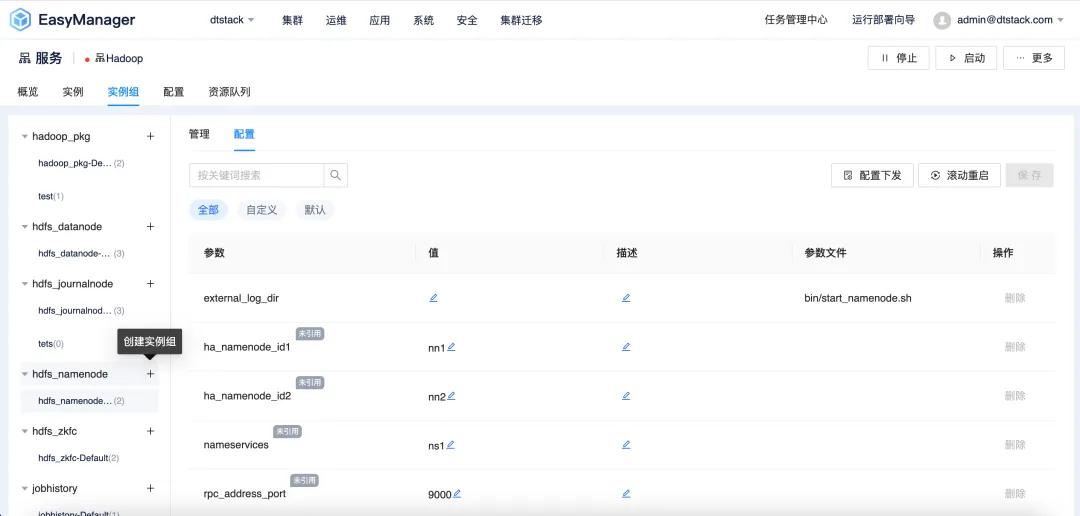
針對實例組實行差異化配置策略,其具體優勢包括但不限於以下幾點:
● 資源分配
差異化配置能有效針對各類任務的獨特需求進行精細化資源配置,涵蓋計算、存儲和網路資源等多個層面。避免資源浪費,同時提高資源利用率,確保集群的各項任務都能得到合適的資源支持。
● 任務調度優化
針對不同類型的任務或作業,可以根據其特點設定不同的配置參數,以優化任務調度和執行效率。
● 容錯與穩定性
通過差異化配置,可以提高集群的容錯能力和穩定性。根據節點或實例組的重要性和負載情況,可以設置不同的容錯機制和故障處理策略,確保集群在面對異常情況時能夠保持穩定運行。
● 成本管理
差異化配置還可以幫助管理成本,根據業務需求和預算限制,對集群中的不同實例組進行合理配置,避免資源浪費,降低運維成本,併在性能和成本之間找到平衡點。
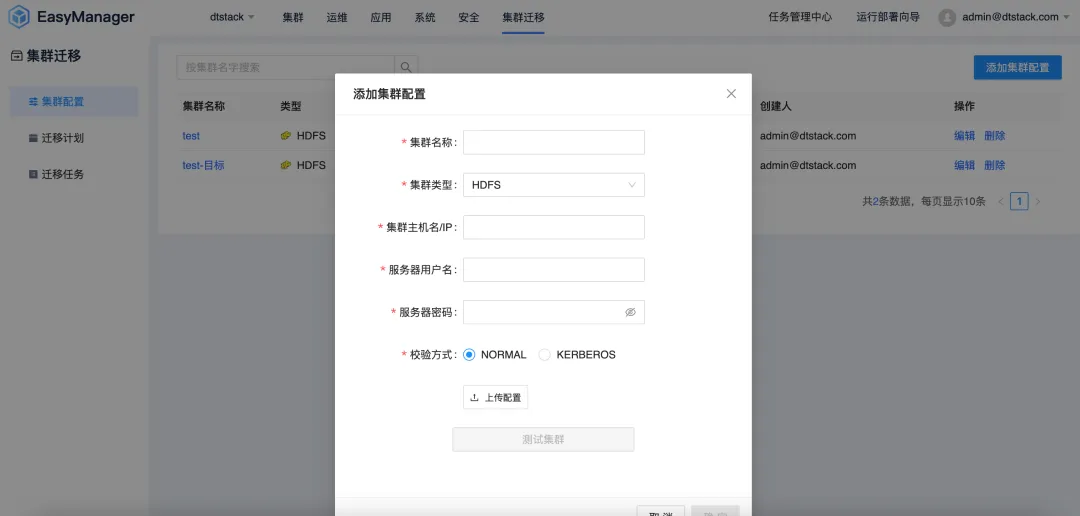
集群遷移:無縫過渡,業務不中斷
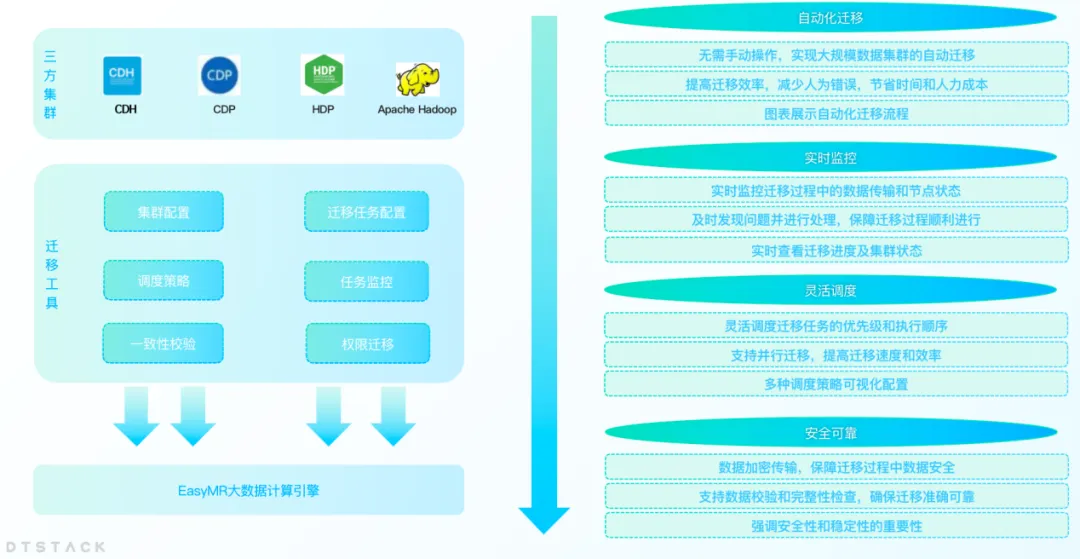
隨著企業的業務發展,不斷增長的數據量往往會導致數據中心的容量不足或者數據中心變更等問題,企業需要將數據從一個數據中心遷移到另一個數據中心。同時在國產化平替背景下,越來越多的企業將 CDH、HDP、CDP 等非信創平臺遷移到國產化大數據平臺。因此 EMR 推出了大數據集群遷移功能,可以幫助企業高效地完成數據中心的遷移。
集群遷移功能支持用戶在不同的數據中心或雲服務之間無縫遷移他們的大數據集群,而無需擔心數據丟失或業務中斷。通過這一功能,企業可以更加靈活地調整其IT基礎設施,以適應不斷變化的市場需求。
引擎升級大揭秘:性能飛躍,全新體驗
最令人激動的是,EMR6.2 版本在計算引擎性能上實現了重大突破。我們不僅對現有的 Spark、Flink 計算引擎進行了問題優化,還引入了新的演算法和技術,以提高數據處理速度和計算效率。這意味著用戶可以在更短的時間內完成更複雜的數據分析任務,從而加快決策過程,提升企業競爭力。
● Spark3 支持 Z-oreder 索引優化
Z-Order 是一種可以將多維數據壓縮到一維的技術,對於一條數據來說,我們可以將其多個要排序的欄位看作是數據的多個維度,Z-Order 可以通過一定的規則將多維數據映射到一維數據上。
具體表現為通過一定的規則構建 z-value 值,該 z-value 值可以理解為上文所提到的一維數據,此時我們就可以基於該一維數據進行排序。如下圖所示:
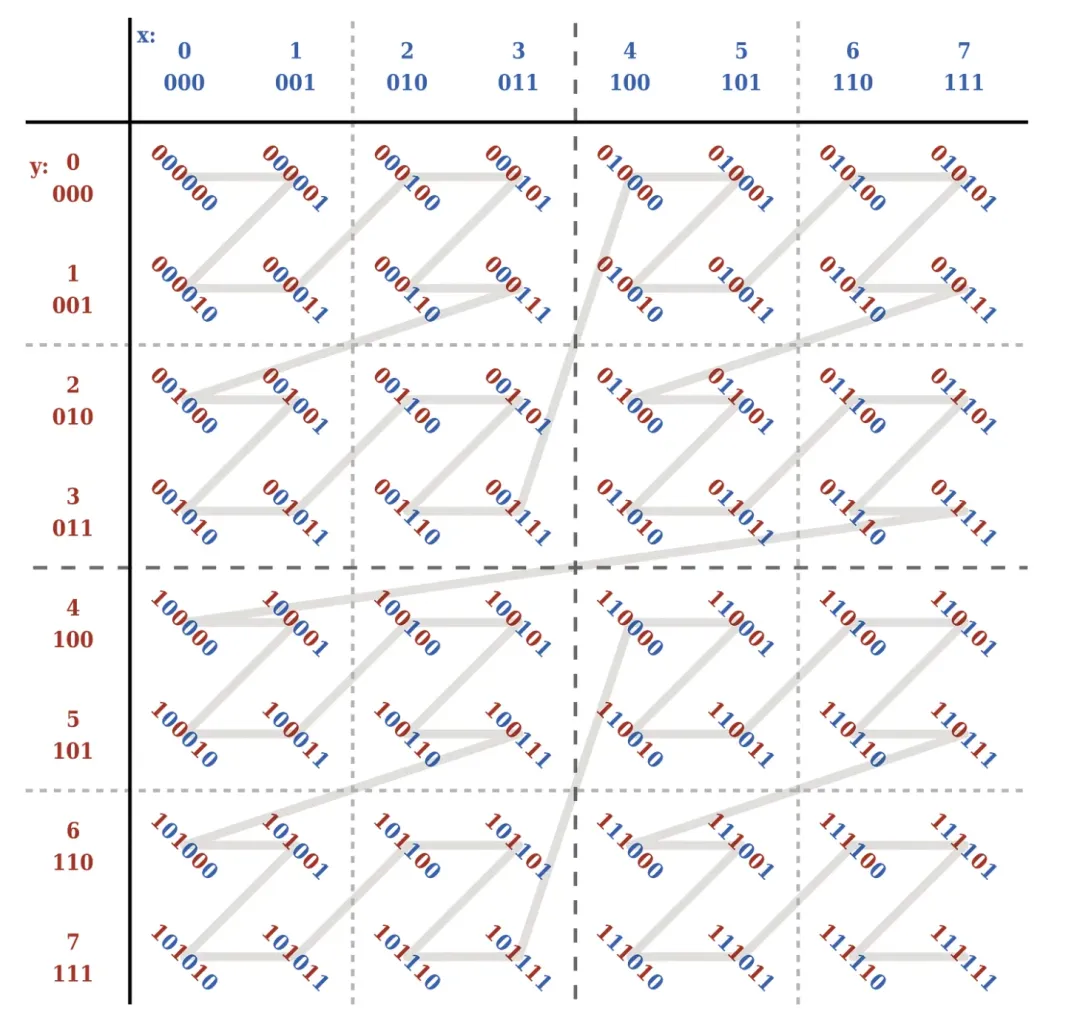
在 Spark SQL 中,袋鼠雲新增 OPTIMIZE XX ZORDER BY 語法來支持 Z-Order 索引,實現了 INSERT INTO table 、INSERT OVERWRITE table、CREATE TABLE table AS SELECT、DISTINCT 等 SQL 的 Z-Order 索引優化。
Spark3 支持 Z-order 優化後極大提高了數據處理和查詢的效率,減少 IO 開銷,加速作業的執行速度。特別是在需要處理大規模數據集和複雜查詢操作的場景下,Z-order 優化可以發揮重要作用。在解決文件壓縮率的問題上,使用 Z-order 優化後,文件壓縮率相比手動優化提升了近 20%,相比原始任務提升了近10倍, 對比開源 Spark3 的任務也有近 30% 的性能提升,極大提升了離線作業的性能和效率。
● Flink Per-job 任務熱更新
實際的生產作業中,往往會出現實時任務參數變更或者運算元、函數調優等情況,通常只能先取消當前任務,再選擇 CheckPoint 恢復或者重新運行,整個過程大概需要3-5分鐘等待,極大浪費任務開發時間。
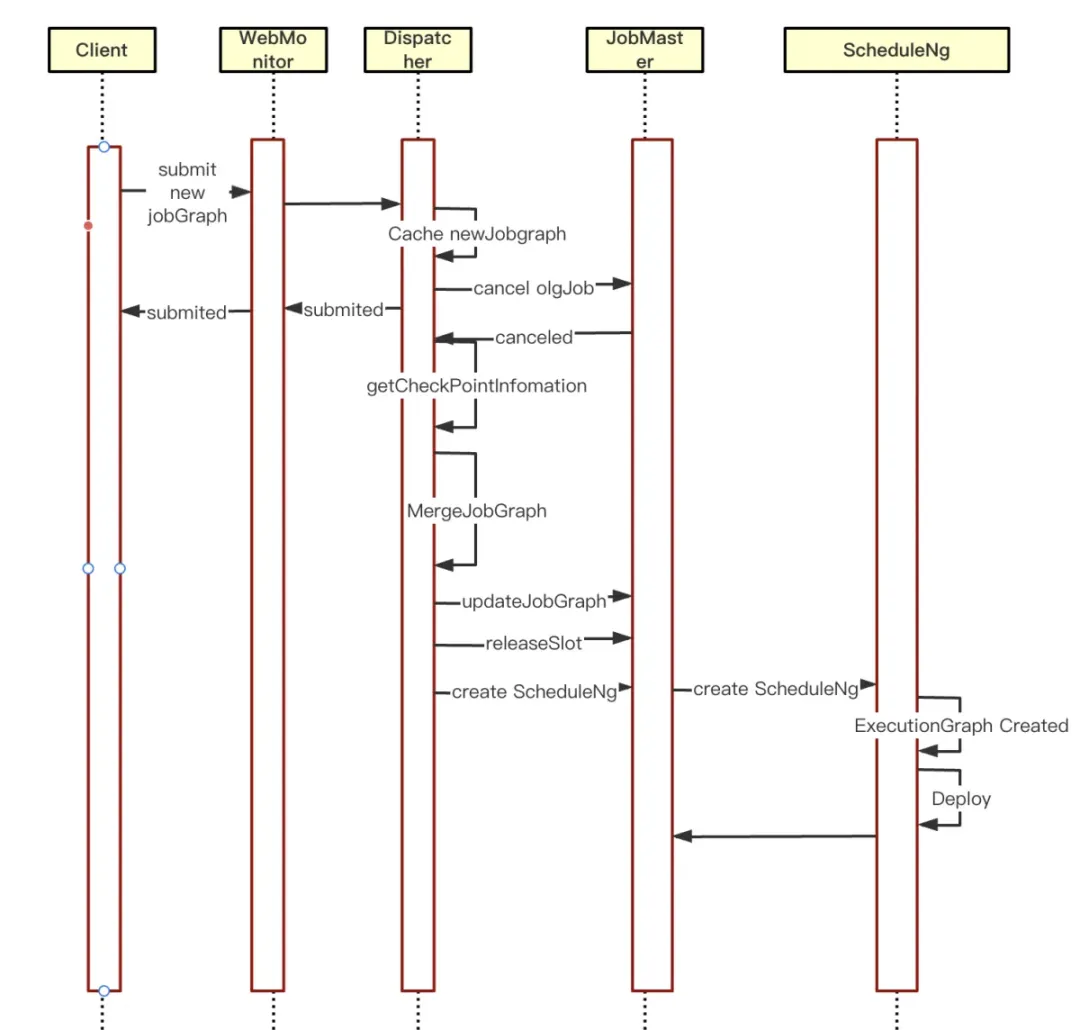
為瞭解決傳統 Per-Job 模式下任務更新導致的服務中斷問題,提高任務的穩定性和系統的可用性,滿足生產環境中對業務連續性和高可用性的要求。袋鼠雲引擎團隊進行了相關探索及源碼的改進,在 Per-Job 任務取消的非同步回調里進行任務的熱重啟優化:
①首先判斷當前是否存在新的 JobGraph 緩存,存在緩存時進入熱重啟邏輯
②獲取取消任務的 CheckPoint 信息,填充到新的 JobGraph
③將 JobGrap 更新到 JobMaster,清理 JobGraph 的緩存信息
④清除 JobMaster 里 SloyPool 管理的資源
⑤JobMaster 重新創建 ScheduleNg 並調度運行,至此開啟新的 JobGraph 調度運行
Flink Per-job 任務熱更新優化之後顯著提高了開發效率,減少停機時間並提升了應用程式的靈活性和可靠性。對於需要快速迭代和動態調整的實時應用程式,帶來極致的效率體驗。
· 提高開發效率: 開發人員可以快速測試和迭代代碼,而無需經歷繁瑣的停止和重啟過程,這加快了開發周期,並允許更頻繁的發佈
· 減少停機時間: 熱更新可以最大限度地減少應用程式的停機時間,從而提高服務的可用性,對於關鍵任務和實時應用程式,尤為重要
· 動態調整參數: 可以動態調整作業配置參數,例如並行度或運算元參數,而無需重啟作業,允許根據實時數據流或負載情況進行靈活調整
● 其他功能開發
此外,在引擎側我們還進行了 Spark Ranger 對接、Spark 物化視圖優化、Flink Session 模式類載入隔離等功能開發,提升引擎計算性能的同時增強引擎的任務安全性和可擴展性。
總結
總結而言,EMR6.2 版本的發佈,標志著袋鼠雲在大數據服務領域的又一重要里程碑。通過UI全面煥新升級、差異化配置、集群遷移以及引擎升級等四大功能的優化,EMR6.2 為用戶提供了一個更加強大、靈活和高效的大數據計算引擎平臺,助力企業在數據管理和分析方面實現質的飛躍。
《行業指標體系白皮書》下載地址:https://www.dtstack.com/resources/1057?src=szsm
《數棧產品白皮書》下載地址:https://www.dtstack.com/resources/1004?src=szsm
《數據治理行業實踐白皮書》下載地址:https://www.dtstack.com/resources/1001?src=szsm
想瞭解或咨詢更多有關大數據產品、行業解決方案、客戶案例的朋友,瀏覽袋鼠雲官網:https://www.dtstack.com/?src=szbky


