
C++語言相比C語言最重要的功能就是支持面向對象編程,為了實現面向對象編程,C++增加了類的封裝和多態、繼承等特性,那麼這些特性的加入是否會造成對象的記憶體成本增加?如果增加了,那麼到底增加了多少? ...
在C語言中,數據和數據的處理操作(函數)是分開聲明的,在語言層面並沒有支持數據和函數的內在關聯性,我們稱之為過程式編程範式或者程式性編程範式。C++相容了C語言,當然也支持這種編程範式。但C++更主要的特點在支持基於對象(object-based, OB)和麵向對象(object-oriented, OO),OB和OO的基礎是對象封裝,所謂封裝就是將數據和數據的操作(函數)組織在一起,在語言層面保證了數據的訪問和操作的一致性,這樣從代碼上更能表現出數據和函數的關係。在這裡先不討論在軟體工程上這幾種編程範式的優劣,我們先來分析對象加上封裝後的記憶體佈局,C++相對於C語言是否需要占用更多的記憶體空間,如果有,那麼到底增加了多少記憶體成本?本文接下來將對各種情形進行分析。
空對象的記憶體佈局
請看下麵的代碼,你覺得答案應該輸出多少?
#include <iostream>
using namespace std;
class Object {
// empty
};
int main() {
Object object;
cout << "The size of object is: " << sizeof(object) << endl;
return 0;
}
答案是會輸出:The size of object is: 1,是的,答案是1位元組。在C++中,即使是空對象也會占用一定的空間,通常是1個位元組。這個位元組用來確保每個對象都有唯一的地址,以便在程式中進行操作。
含有數據成員的對象的記憶體佈局
- 非靜態數據成員
現在再往這個類裡面加入一些非靜態的數據成員,來看看加入非靜態的數據成員之後記憶體佈局占用多少空間。
#include <iostream>
using namespace std;
class Object {
public:
int a;
int b;
};
int main() {
Object object;
cout << "The size of object is: " << sizeof(object) << endl;
cout << "The address of object: " << &object << endl;
cout << "The address of object.a: " << &object.a << endl;
cout << "The address of object.b: " << &object.b << endl;
return 0;
}
運行結果輸出的是:
The size of object is: 8
The address of object: 0x16f07f464
The address of object.a: 0x16f07f464
The address of object.b: 0x16f07f468
現在object對象總共占用了8位元組。int類型在我測試的機器上占用4位元組的空間,這個跟測試的機器有關,有的機器有可能是8位元組,在一些很老的機器上也有可能是2位元組。
看後面三行的地址,可以看出,數據成員a的地址跟對象的地址是一樣的,也就是說它是排列在對象的開始處,接下來是隔了4個位元組後的地址,也就是數據成員b的地址,這說明數據成員a和b是順序且緊密排列在一起的,並且是從對象的起始處開始的。結果表明,在這種情況下,C++的對象的記憶體佈局跟C語言的結構的記憶體佈局是一樣的,並不會比C語言多占用一些記憶體空間。
- 靜態數據成員
C++的類也支持在類裡面定義靜態數據成員,那麼定義了靜態數據成員之後類對象的記憶體佈局是怎麼樣的呢?在上面的類中加入一個靜態數據成員,如以下代碼:
class Object {
public:
int a;
int b;
static int static_a;
};
運行結果輸出:
The size of object is: 8
The address of object: 0x16b25f464
The address of object.a: 0x16b25f464
The address of object.b: 0x16b25f468
The address of object.static_a: 0x104ba8000
對象的大小結果還是8位元組,說明靜態成員變數並不會增加對象的記憶體占用空間。看下它們各個的地址,從結果可以看出,靜態成員變數的地址跟非靜態成員變數的地址相差很大,推斷肯定不是和它們排列在一起的。在main函數中增加如下代碼:
Object obj2;
cout << "The size of obj2 is: " << sizeof(obj2) << endl;
cout << "The address of obj2.static_a: " << &obj2.static_a << endl;
輸出結果為:
The size of obj2 is: 8
The address of obj2.static_a: 0x104ba8000
定義了第2個對象,這個對象的大小也還是8位元組,說明靜態對象不是存儲在每個對象中的,而是存在某個地方,由所有的同一個的類對象所共有的。從第2行輸出的地址可以看出來,它的地址和第1個對象輸出的地址是一樣的,說明它們指向的是同一個變數。其實類中的靜態數據成員是和全局變數一樣存放在數據段中的,它的地址是在編譯的時候就已經確定的了,每次運行都是一樣的。它和全局變數一樣,地址在編譯時確定,所以訪問它沒有任何性能損失,和全局變數的區別是它的作用域不一樣,類的靜態數據成員的作用域只有在類中可見,訪問許可權受它在類中定義時的訪問許可權區段所控制。
含有成員函數的對象的記憶體佈局
上面所討論的都是類裡面只有數據成員的情況,如果在類里再加上成員函數時,類對象的記憶體佈局會有什麼變化?在類中增加一個public的成員函數和一個靜態成員函數,代碼修改如下:
#include <iostream>
#include <cstdio>
using namespace std;
class Object {
public:
void print() {
cout << "The address of a: " << &a << endl;
cout << "The address of b: " << &b << endl;
cout << "The address of static_a: " << &static_a << endl;
}
static void static_func() {
cout << "This is a static member function.\n";
}
private:
int a;
int b;
static int static_a;
};
int Object::static_a = 1;
int main() {
Object object;
cout << "The size of object is: " << sizeof(object) << endl;
printf("The address of print: %p\n", &Object::print);
printf("The address of static_func: %p\n", &Object::static_func);
object.print();
object.static_func();
return 0;
}
運行輸出結果如下:
The size of object is: 8
The address of print: 0x102d93120
The address of static_func: 0x102d931c4
The address of a: 0x16d06f464
The address of b: 0x16d06f468
The address of static_a: 0x102d98000
This is a static member function.
類對象的大小還是沒變,還是8位元組。說明增加成員函數並沒有增加類對象的記憶體占用,無論是普通成員函數還是靜態成員函數都一樣。其實類中的成員函數並不存儲在每個類對象中的,而是跟類的定義相關的,它是存放在可執行二進位文件中的代碼段里的,由同一個類所產生出來的所有對象所共用。從上面輸出結果中兩個函數的地址來看,它們的地址很相近,說明普通成員函數和靜態成員函數都是一樣的,都存放在代碼段中,地址在編譯時就已確定。調用它們跟調用一個普通的函數沒有什麼區別,不會有性能上的損失。
含有虛函數的對象的記憶體佈局
面向對象主要的特征之一就是多態,而多態的基礎就是支持虛函數的機制。那麼虛函數的支持對對象的記憶體佈局會產生什麼影響呢?這裡先不分析虛函數的實現機制,我們先來分析記憶體佈局的成本。在上面的例子中加入兩個虛函數:一個普通的虛函數和虛析構函數,代碼如下:
virtual ~Object() {
cout << "Destructor...\n";
}
virtual void virtual_func() {
cout << "Call virtual_func\n";
}
// 在main函數里增加兩行列印
printf("The address of object: %p\n", &object);
printf("The address of virtual_func: %p\n", &Object::virtual_func);
編譯運行,看看輸出:
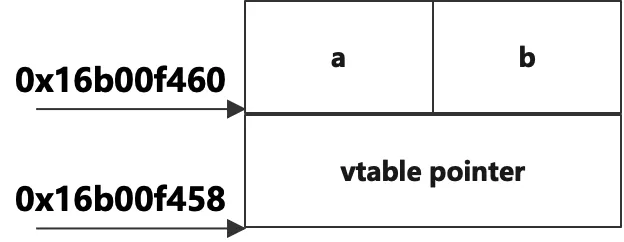
The size of object is: 16
The address of object: 0x16f97f458
The address of print: 0x100482f74
The address of static_func: 0x10048301c
The address of virtual_func: 0x10
The address of a: 0x16f97f460
The address of b: 0x16f97f464
The address of static_a: 0x100488000
Destructor...
在沒有增加任何數據成員的情況下,對象的大小增加到了16位元組,這說明虛函數的加入改變了對象的記憶體佈局。那麼增加的內容是什麼呢?我們看到輸出的列印中對象的首地址為0x16f97f458,而數據成員a的地址為0x16f97f460,這中間剛好差了8位元組。而從上面的分析我們知道,原來a的地址是和對象的首地址是一樣的,也就是說對象的記憶體佈局是從a開始排列的,而現在在對象的起始地址和成員變數a之間空了8個位元組,那麼排在a之前的這8個位元組的內容是什麼呢?我們加點代碼把它的內容輸出出來,在main函數中加入以下代碼:
long* p = (long*)&object;
long* vptr = (long*)*p;
printf("vptr is %p\n", vptr);
輸出結果:
The size of object is: 16
The address of object: 0x16b00f458
The address of print: 0x104df2f68
The address of static_func: 0x104df3010
The address of virtual_func: 0x10
The address of a: 0x16b00f460
The address of b: 0x16b00f464
The address of static_a: 0x104df8000
vptr is 0x104df4110
Destructor...
它的內容是0x104df4110,它其實是一個指針,在我的機器上占用8位元組,在某些機器上可能是4位元組。這個指針指向的其實是一個虛函數表,虛函數表是一個表格,表格裡的每一項的內容存放的是每個虛函數的地址,這個地址指向虛函數真正的地址,在上面的列印中虛函數列印出來的地址是0x10,這個其實不是它的真正地址,是它在表格中的偏移地址。可以看到這個虛函數表地址和靜態成員static_a的地址非常相近,其實虛函數表也是存放在數據段裡面的,它在編譯的時候由編譯器確定好內容,並且編譯器會自動擴充一些代碼,在構造對象的時候把虛函數表的首地址插入到對象的起始位置。虛函數的詳細分析在這裡先不展開,後面再詳細分析。從這裡的分析可以看到,類裡面增加虛函數,會在對象的起始位置上插入一個指針,對象的大小會增加一個指針的大小,為8位元組或者4位元組。如下麵的示意圖:
繼承體系下的對象的記憶體佈局
繼承是C++中很重要的一個功能,按照不同的形式有單一繼承、多重繼承、虛繼承,按照繼承許可權有public、protected、private。下麵我們一一來分析,為簡單起見,我們只分析public繼承。
- 單一繼承
#include <iostream>
#include <cstdio>
using namespace std;
class point2d {
public:
int x() { return x_; }
int y() { return y_; }
protected:
int x_;
int y_;
};
class point3d: public point2d {
public:
int z() { return z_; }
void print() {
printf("The address of x: %p\n", &x_);
printf("The address of y: %p\n", &y_);
printf("The address of z: %p\n", &z_);
}
protected:
int z_;
};
int main() {
point2d p2d;
point3d p3d;
cout << "The size of p2d is: " << sizeof(p2d) << endl;
cout << "The size of p3d is: " << sizeof(p3d) << endl;
cout << "The address of p3d: " << &p3d << endl;
p3d.print();
return 0;
}
上面的代碼編譯運行輸出:
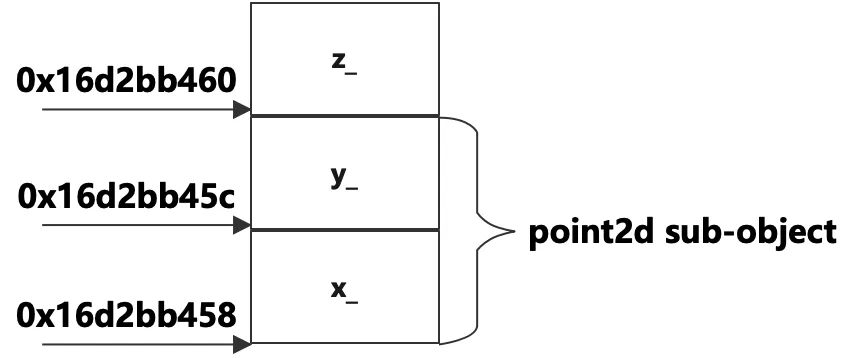
The size of p2d is: 8
The size of p3d is: 12
The address of p3d: 0x16d2bb458
The address of x: 0x16d2bb458
The address of y: 0x16d2bb45c
The address of z: 0x16d2bb460
類point3d只有一個數據成員z_,但大小卻有12位元組,很明顯它的大小是加上父類point2d的大小8位元組的。從輸出的地址看,p3d的地址是0x16d2bb458,從父類繼承而來的x_的地址也是0x16d2bb458,這說明從父類繼承而來的數據成員排列在前面,從對象的首地址開始,按照它們在類中的聲明順序依次排序,接著是子類自己的數據成員,從上面的結果看起來對象中的數據成員在記憶體中是按照順序且緊湊的排列在一起的,如下圖所示:
我們再來驗證一下,把數據成員的聲明類型改為char型,修改後輸出結果:
The size of p2d is: 2
The size of p3d is: 3
The address of p3d: 0x16ba63467
The address of x: 0x16ba63467
The address of y: 0x16ba63468
The address of z: 0x16ba63469
看起來似乎我們的猜測是正確的,我們再繼續修改,把x_改為int型,其它兩個為char型,聲明順序還是跟之前一樣,這次的輸出結果:
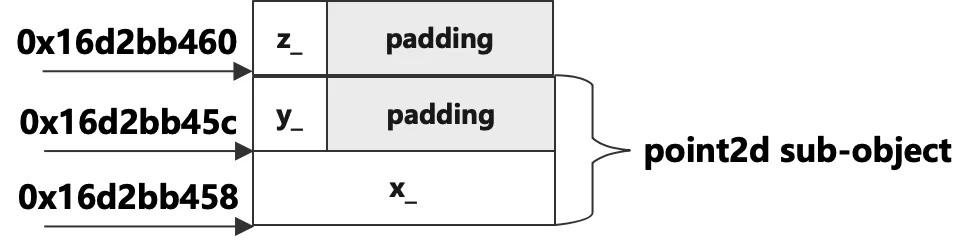
The size of p2d is: 8
The size of p3d is: 12
The address of p3d: 0x16d033458
The address of x: 0x16d033458
The address of y: 0x16d03345c
The address of z: 0x16d033460
這次跟我們想要的結果不一樣了,p2d的大小不是5位元組而是8位元組,p3d的大小不是6位元組而是12位元組,看起來編譯器填充了記憶體空間使得他們的大小變大了。其實這時編譯器為了訪問效率選擇了對齊,為了讓變數的地址是4的倍數,它會填充中間的空擋,這些行為跟編譯器有很大的關係,不同的編譯器有不同的行為,類中數據成員的不同聲明順序和不同的數據類型可能就導致不同的結果。佈局示意圖如下:
- 多重繼承
接下來看看一個類繼承了多個父類,它的記憶體佈局是怎麼樣的。請看下麵的代碼:
#include <iostream>
#include <cstdio>
using namespace std;
class Base1 {
public:
int b1;
};
class Base2 {
public:
int b2;
};
class Derived: public Base1, public Base2 {
public:
int d;
void print() {
printf("The address of b1: %p\n", &b1);
printf("The address of b2: %p\n", &b2);
printf("The address of d: %p\n", &d);
}
};
int main() {
Derived obj;
printf("The size of obj is: %lu\n", sizeof(obj));
printf("The address of obj: %p\n", &obj);
obj.print();
return 0;
}
輸出結果:
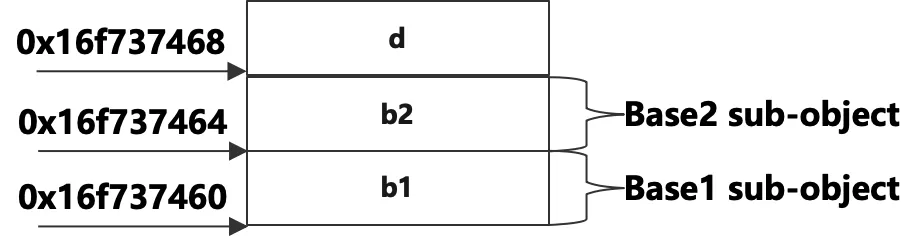
The size of obj is: 12
The address of obj: 0x16f737460
The address of b1: 0x16f737460
The address of b2: 0x16f737464
The address of d: 0x16f737468
對象的總大小是12位元組,它是子類自身擁有的一個數據成員4位元組加上分別從兩個父類繼承而來的兩個數據成員共8位元組的總和。從輸出的地址可以看出來,從父類Base1繼承來的成員b1和對象的首地址相同,接著是從父類Base2繼承而來b2,最後是子類自己的成員d,說明對象的佈局是從b1開始,然後是b2,最後是d,這個跟繼承的順序有關,第一繼承而來的數據成員排在最前面,按照在類中聲明的順序依次排列,其次是第二繼承而來的數據成員,以此類推,最後是子類自己的數據成員。佈局示意圖如下:
- 父類帶虛函數的繼承
如果父類中帶有虛函數,那麼對子類的記憶體佈局有何影響?在上面的代碼中的兩個父類各加上一個虛函數,而子類暫時先不加虛函數,如下代碼:
// 在class Base1中加入以下代碼
virtual void virtual_func1() {
printf("This is virtual_func1\n");
}
// 在class Base2中加入以下代碼
virtual void virtual_func2() {
printf("This is virtual_func2\n");
}
編譯運行,輸出結果:
The size of obj is: 32
The address of obj: 0x16b807448
The address of b1: 0x16b807450
The address of b2: 0x16b807460
The address of d: 0x16b807464
這次對象的大小竟然是32位元組,比上面的例子增加了20位元組,這裡並沒有增加任何數據成員,只是僅僅在父類增加了虛函數,根據上面的分析,增加虛函數會引入虛函數表指針,指針占8位元組的大小,那為什麼會增加這麼多呢?我們可以藉助工具來分析一下,編譯器一般會提供一些輔助分析工具供開發人員使用,其中有一個功能是把每個類的佈局給列印出來,gcc、clang、vs都有類似的命令,clang可以使用下麵的命令來查看:
clang -Xclang -fdump-record-layouts -stdlib=libc++ -std=c++11 -c filename.cpp
輸出的結果很多,我截取關鍵的一部分:
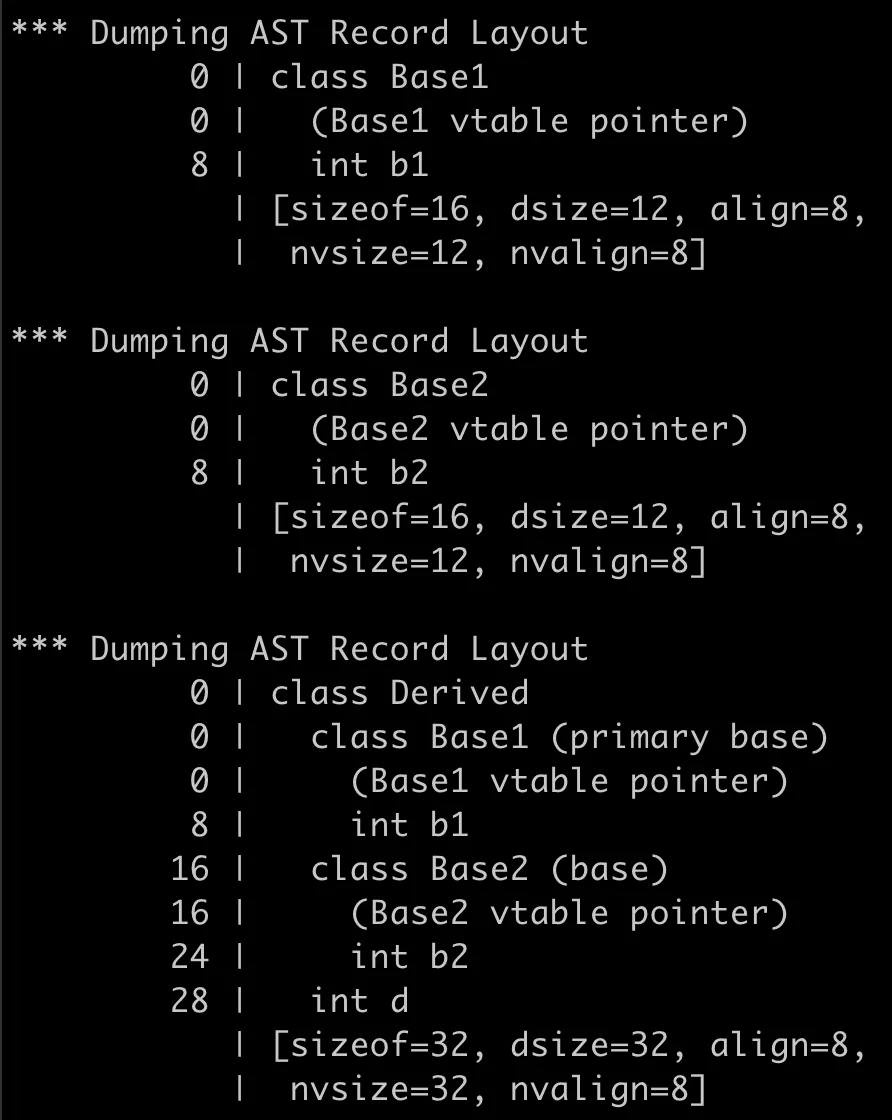
上圖中,左邊的數字就是對象的成員相對於對象的起始地址的偏移量。從上圖我們可以得出以下的結論:
1.父類中各有一個虛函數表以及一個指向它的虛函數表指針,子類分別從父類中繼承下來,父類有多少個虛函數表,子類就有多少個虛函數表。這裡額外插一句,子類雖然繼承了父類的虛函數表,但子類的虛函數表不會和父類的虛函數表是同一個,就運算元類沒有覆蓋父類的任何虛函數,編譯器也會複製多一份虛函數表出來,儘管它們的虛函數表的內容是一模一樣的,但是一般情況下子類都會覆蓋父類的虛函數,不然也沒有必要用虛函數了,虛函數具體的分析以後再講。
2.編譯器為了訪問效率選擇了8位元組的對齊,也就是說成員變數b1占了8位元組,數據本身占了4位元組,為了對齊填充了4位元組,使得下一個虛函數表指針可以對齊訪問。
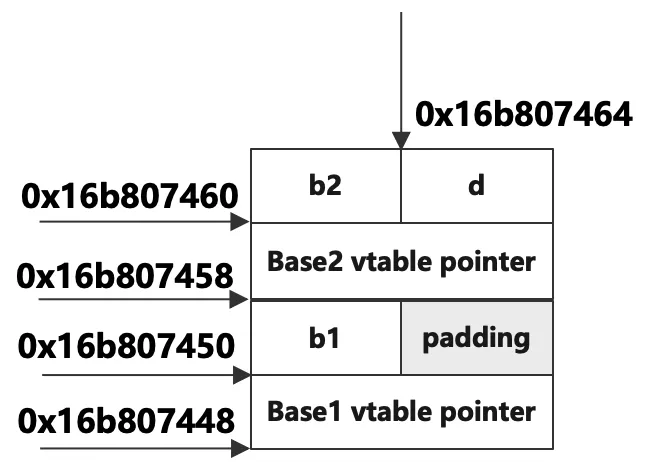
所以,分析的結論就是子類對象的記憶體佈局是這樣的,首先是從Base1父類繼承來的虛函數表指針,占用8位元組,接著是繼承來的b1成員變數,加上填充的4位元組共占用了8位元組,再接著是從父類Base2繼承來的虛函數表指針,占用8位元組,之後是繼承的b2成員變數,占用4位元組,子類自己的成員變數d緊跟著排列在後面,總共32位元組。佈局示意圖如下:
虛繼承的對象的記憶體佈局
虛繼承是為瞭解決棱形繼承情形下重覆繼承的問題提出來的解決辦法,如下麵的代碼:
#include <iostream>
#include <cstdio>
using namespace std;
class Grand {
int a;
};
class Base1: public Grand {
};
class Base2: public Grand {
};
class Derived: public Base1, public Base2 {
};
int main() {
Grand g;
Base1 b1;
Base2 b2;
Derived obj;
//obj.a = 1; // 這行編譯不過。
printf("The size of g is: %lu\n", sizeof(g));
printf("The size of b1 is: %lu\n", sizeof(b1));
printf("The size of b2 is: %lu\n", sizeof(b2));
printf("The size of obj is: %lu\n", sizeof(obj));
return 0;
}
上面的代碼中如果不把第23行代碼屏蔽掉是編譯不過的,因為Base1和Base2都繼承了Grand,Derived又繼承了Base1和Base2,Grand中的成員a將會被重覆繼承兩次,這時在子類Derived中就存在了兩個成員a,這時從Derived訪問a就會出現錯誤,因為編譯器不知道你要訪問的是哪一個a,出現了名字衝突的問題。屏蔽掉第23行後編譯運行,看下輸出結果:
The size of g is: 4
The size of b1 is: 4
The size of b2 is: 4
The size of obj is: 8
從結果中也可以驗證,子類Derived占了兩倍的大小。為瞭解決像這種重覆繼承了兩次的問題,辦法是引入虛繼承,我們修改下代碼繼續分析:
#include <iostream>
#include <cstdio>
using namespace std;
class Grand {
public:
int a;
};
class Base1: virtual public Grand {
public:
int b;
};
class Base2: virtual public Grand {
public:
int c;
};
class Derived: public Base1, public Base2 {
public:
int d;
};
int main() {
Grand g;
Base1 b1;
Base2 b2;
Derived obj;
obj.a = 1;
printf("The size of g is: %lu\n", sizeof(g));
printf("The size of b1 is: %lu\n", sizeof(b1));
printf("The size of b2 is: %lu\n", sizeof(b2));
printf("The size of obj is: %lu\n", sizeof(obj));
printf("The address of obj: %p\n", &obj);
printf("The address of obj.a: %p\n", &obj.a);
printf("The address of obj.b: %p\n", &obj.b);
printf("The address of obj.c: %p\n", &obj.c);
printf("The address of obj.d: %p\n", &obj.d);
return 0;
}
這時訪問Derived類的對象中的成員變數a就沒有衝突了,如上面代碼的第30行,上面代碼的輸出結果:
The size of g is: 4
The size of b1 is: 16
The size of b2 is: 16
The size of obj is: 40
The address of obj: 0x16d70b420
The address of obj.a: 0x16d70b440
The address of obj.b: 0x16d70b428
The address of obj.c: 0x16d70b438
The address of obj.d: 0x16d70b43c
改為虛繼承後,obj.a = 1;這行代碼能編譯通過了,不會出現名字衝突了。我們來看看孫子類Derived的對象的大小,竟然是40位元組,增大了這麼多,還是使用上面的命令來dump出對象的記憶體佈局,結果如下圖,截取部分:
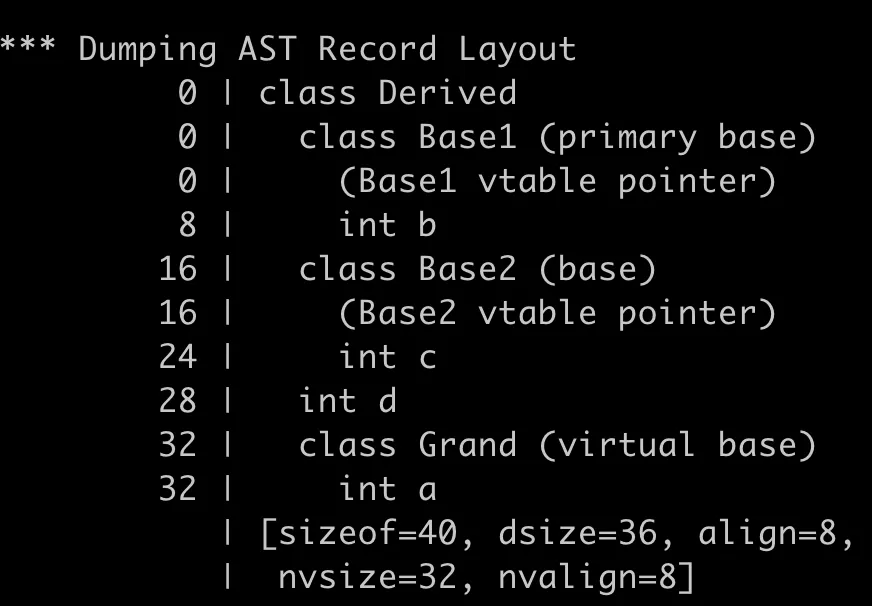
這裡先補充一點,虛繼承是藉助於虛基類表來實現,被虛繼承的父類的成員變數會放在虛基類表中,通過在對象中插入的虛基類表指針來訪問虛基類表,有點類似於虛函數表,實現方式不同的編譯器採用不一樣的方式,gcc和clang是虛函數表和虛基類表共用一個表,稱為虛表,所以只需要一個指針指向它,叫做虛表指針,而Windows平臺的Visual Studio是採用兩個表,所以Windows下對象里會有兩個指針,一個虛函數表指針和一個虛基類表指針,虛基類的實現細節後面再詳細分析。
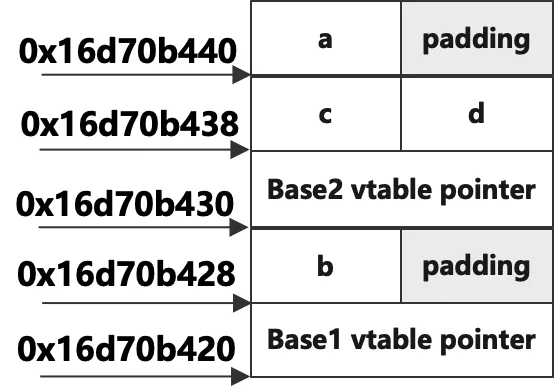
從上圖可以看到,孫子類Derived的對象的記憶體里擁有兩個虛表指針,因為父類Base1和Base2分別虛繼承了爺爺類Grand,每一個虛繼承將會產生一個虛表指針,按照繼承的順序依次排列,首先是Base1子對象的內容,包含了一個虛表指針和成員變數b,b之後會填充4位元組到8位元組對齊,然後是Base2子對象的內容,同樣也包含了一個虛表指針和成員變數c,再之後是孫子類Derived自己的成員變數d,它是緊湊的排列在c之後的,最後是爺爺類Grand中的成員變數a,可以看到虛繼承下來的成員變數被安排到最後的位置了,從列印的地址也可以看出來。佈局示意圖如下:
此篇文章同步發佈於我的微信公眾號:C++對象封裝後的記憶體佈局
如果您感興趣這方面的內容,請在微信上搜索公眾號iShare愛分享或者微信號iTechShare並關註,以便在內容更新時直接向您推送。

