
主從延遲調優思路 1、什麼是主從延遲? 本質是從庫的回放跟不上主庫,回放階段的延遲 2、主從延遲常見的原因有哪些? 1、大事務,從庫回放時間較長,導致主從延遲 2、主庫寫入過於頻繁,從庫回放跟不上 3、參數配置不合理 4、主從硬體差異 5、網路延遲 6、表沒有主鍵或者索引大量頻繁的更新 7、一些讀寫 ...
主從延遲調優思路
1、什麼是主從延遲?
本質是從庫的回放跟不上主庫,回放階段的延遲

2、主從延遲常見的原因有哪些?
1、大事務,從庫回放時間較長,導致主從延遲
2、主庫寫入過於頻繁,從庫回放跟不上
3、參數配置不合理
4、主從硬體差異
5、網路延遲
6、表沒有主鍵或者索引大量頻繁的更新
7、一些讀寫分離的架構,從庫的壓力比較大
3、解決主從延遲有哪些方法
1、對於大事務,拆分成小事務
2、開啟並行複製
3、升級從庫硬體
4、儘量都有主鍵
4、什麼是並行複製,參數有哪些?
回顧MySQL並行複製的路程
MySQL5.6 是基於資料庫級別的並行複製
slave-parallel-type=DATABASE(不同庫的事務,沒有鎖衝突)

MySQL5.7 基於group commit的並行複製
slave-parallel-type=LOGICAL_CLOCK : Commit-Parent-Based模式(同一組的事務[last-commit相同]沒有鎖衝突. 同一組,肯定沒有衝突,否則沒辦法成為同一組)
上面是從庫的配置,並行複製依賴於主庫的組提交(註意區分組複製)
greatsql> show variables like '%group%delay%';
+-----------------------------------------+-------+
| Variable_name | Value |
+-----------------------------------------+-------+
| binlog_group_commit_sync_delay | 0 |
| binlog_group_commit_sync_no_delay_count | 0 |
+-----------------------------------------+-------+
2 rows in set (0.01 sec)
-
binlog_group_commit_sync_delay:等待多少時間後才進行組提交 -
binlog_group_commit_sync_no_delay_count:等待多少個事務後才進行組提交
以上參數都依賴於主庫業務繁忙的情況下,如果業務不頻繁,就會很尷尬
binlog_group_commit_sync_no_delay_count:這個參數設置成2個
比如只有一個線程執行一個事務,第二個事務在24h之後執行,那麼這個事務需要等待24h才能提交,十分坑
binlog_group_commit_sync_delay
假如設置成200ms,只有一個線程執行一個事務,本來10ms可以提交,還必須等待200ms才可以
線上一般是兩個都設置,舉個例子,就像是小船運人過河
假設我們的參數這麼設置:
binlog_group_commit_sync_delay=200;
binlog_group_commit_sync_no_delay_count=2
要麼滿足200ms直接走,要麼滿足2個人直接走,這麼人性化了很多,但是在業務不繁忙的情況下依然尷尬

MySQL8.0 基於write-set的並行複製
基於主鍵的衝突檢測(binlog_transaction_depandency_tracking = COMMIT_ORDERE|WRITESET|WRITESET_SESSION, 修改的row的主鍵或非空唯一鍵沒有衝突,即可並行)
事務檢測演算法:transaction_write_set_extraction = XXHASH64
MySQL會有一個變數來存儲已經提交的事務HASH值,所有已經提交的事務所修改的主鍵(或唯一鍵)的值經過hash後都會與那個變數的集合進行對比,來判斷改行是否與其衝突,並以此來確定依賴關係
這裡說的變數,可以通過這個設置大小:binlog_transaction_dependency_history_size
這樣的粒度,就到了 row 級別了,就是此時並行的粒度更加精細,並行的速度會更快,某些情況下,說slave的並行度超越master也不為過(master是單線程的寫,slave也可以並行回放)
簡單來說就是基於行去並行回放,rc級別下不同的行不會有鎖衝突
組提交的表現:
看主庫binlog的last_committed值是否一致,一致就可以並行回放,不一致只能串列

5、實戰分析
5.1 查看線上主從延遲
Seconds_Behind_Master: 48828
可見延遲很高,接近14個小時,此時主庫也在不斷的寫數據,大概是6分鐘一個binlog,一個為500M
5.2 查看當前的複製配置
查看從庫配置:
greatsql> show variables like '%slave%para%';
+------------------------+---------------+
| Variable_name | Value |
+------------------------+---------------+
| slave_parallel_type | LOGICAL_CLOCK |
| slave_parallel_workers | 128 |
+------------------------+---------------+
2 rows in set (0.02 sec)
延遲現象:
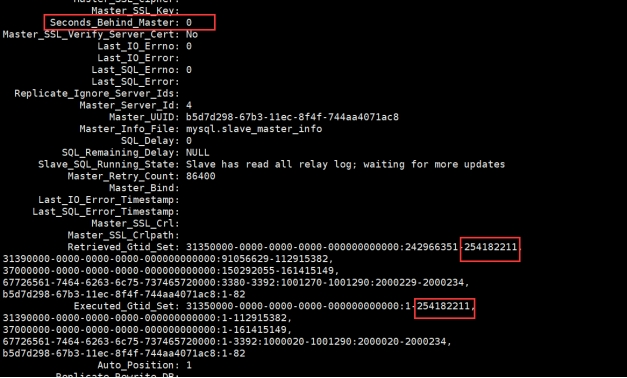
從庫一直在追,說明不是大事務,但是Seconds_Behind_Master延遲一直在增長
Retrieved_Gtid_Set: 00000000-0000-0024-0046-41a8003b4b99:242966351-253068975,
00000000-0000-0040-0095-5fff003b4b99:91056629-110569633,
00000000-0000-005c-0ced-7bae003b4b99:150292055-160253193,
31f4399f-ade5-11ed-a544-00163ebdeb51:1-12,
Executed_Gtid_Set: 00000000-0000-0024-0046-41a8003b4b99:1-252250235,
00000000-0000-0040-0095-5fff003b4b99:1-109120315,
00000000-0000-005c-0ced-7bae003b4b99:1-159504296,
31f4399f-ade5-11ed-a544-00163ebdeb51:1-12,
Auto_Position: 1
此時懷疑並沒有並行複製,主庫可能沒設置組提交(只是一個猜想)
5.3 進一步驗證,查看主庫的binlog
查看主庫的參數配置:還是為組提交的規則
greatsql> show variables like '%binlog_transac%';
+--------------------------------------------+----------+
| Variable_name | Value |
+--------------------------------------------+----------+
| binlog_transaction_compression | OFF |
| binlog_transaction_compression_level_zstd | 3 |
| binlog_transaction_dependency_history_size | 25000 |
| binlog_transaction_dependency_tracking | WRITESET |
+--------------------------------------------+----------+
4 rows in set (0.02 sec)
再看其組提交的配置:表示沒有開組提交
greatsql> show variables like '%group%delay%';
+-----------------------------------------+-------+
| Variable_name | Value |
+-----------------------------------------+-------+
| binlog_group_commit_sync_delay | 0 |
| binlog_group_commit_sync_no_delay_count | 0 |
+-----------------------------------------+-------+
2 rows in set (0.01 sec)
進一步驗證,看其binlog,發現果然last_committed都不一樣,表示不能並行
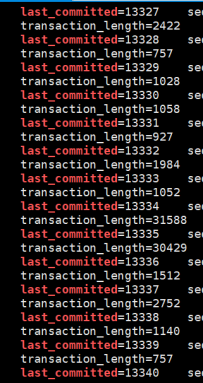
5.4 主庫設置參數,再次解析其binlog
將binlog_transaction_dependency_tracking改為WRITESET模式
greatsql> show variables like '%transaction%';
+----------------------------------------------------------+-----------------+
| Variable_name | Value |
+----------------------------------------------------------+-----------------+
| binlog_direct_non_transactional_updates | OFF |
| binlog_transaction_compression | OFF |
| binlog_transaction_compression_level_zstd | 3 |
| binlog_transaction_dependency_history_size | 25000 |
| binlog_transaction_dependency_tracking | WRITESET |
| kill_idle_transaction | 300 |
| performance_schema_events_transactions_history_long_size | 10000 |
| performance_schema_events_transactions_history_size | 10 |
| replica_transaction_retries | 10 |
| session_track_transaction_info | OFF |
| slave_transaction_retries | 10 |
| transaction_alloc_block_size | 8192 |
| transaction_allow_batching | OFF |
| transaction_isolation | REPEATABLE-READ |
| transaction_prealloc_size | 4096 |
| transaction_read_only | OFF |
| transaction_write_set_extraction | XXHASH64 |
+----------------------------------------------------------+-----------------+
17 rows in set (0.00 sec)
再次查看其binlog,看到有很多都可以並行回放

5.5 優化完成
即使主庫在大批量的寫入,但延遲正在慢慢縮減,追上只是時間問題,今天就是0了
Enjoy GreatSQL

