
本文深入探討了Kubernetes Pod配置的實戰技巧和常見易錯點。 關註【TechLeadCloud】,分享互聯網架構、雲服務技術的全維度知識。作者擁有10+年互聯網服務架構、AI產品研發經驗、團隊管理經驗,同濟本復旦碩,復旦機器人智能實驗室成員,阿裡雲認證的資深架構師,項目管理專業人士,上億營 ...
前言
在我做開發的這些年,讓我很頭痛的一類問題,不是線上故障,而是數據異常,不知道有沒有程式員跟我感同身受。
大多數的服務故障都有較為直觀的異常日誌,再結合產品表象,相對排查起來還有跡可循,但數據異常的原因就太多了,很多時候連報錯日誌都沒有,排查起來簡直無從下手。
在一個微服務、分散式、前後端分離等概念熱火朝天的年代,雖然給身為程式員的我們帶來了很大便利,但也同時帶來了很多苦惱。分工更加明確,減少了很多工作量,我們大部分的時間和精力專註於自己所負責的模塊即可。
本來一切都很美好,但是在排查一些數據異常類問題時卻遇到了麻煩!
業務的底層邏輯錯綜複雜,一個介面的響應需要經過三四個微服務的協同處理這非常正常,甚至涉及七八個以上的微服務都不罕見。
不少服務是不同的人員,甚至是不同部門的人員在維護,這給排查帶來很多不便,那該如何快速定位問題呢?
行業目前的現狀
如果自身服務有異常日誌,一眼就能確認問題還好說,但如果自身服務一切正常,那排查起來可得費老大勁了。
這種數據異常問題,往往是突然發生,打你一個措手不及。很多時候我們本來就有正常的開發排期,時間也比較緊張,突然再穿插一個數據異常排查的事情進來,這就很讓我們氣憤。
當被產品經理或者部門主管找上門來,總不能跟他說:我的服務沒問題,哪裡的問題我也不知道!
這種問題雖然讓我們頭疼,但是得認真對待,因為以我的經驗來看,稍一疏忽說不定就落下一個業務不熟悉、定位問題能力差的名聲甚至還可能替人背鍋。
冷靜下來分析,既然是數據異常類的問題,不少朋友可能會說,還能咋辦,跑數唄!
跑數,說起來簡單做起來可不簡單,目前各個企業或業務團隊的現狀大概分為幾種情況:
- 1、已經將相關日誌格式化後存儲到數據平臺,可以寫SQL查詢(困難指數:兩顆星);
- 2、日誌沒有格式化,而是落到了磁碟、HDFS或者其他存儲引擎上,需要寫專門的Java、Python或MR或Spark等的任務去解析原始日誌然後再跑數,如果日誌量大一點、日誌格式再混亂一點,工作量可不小(困難指數:五顆星);
- 3、可能連必要的日誌都忘了列印(困難指數:非人力所能及,跑路吧!);
說到這,有些小伙伴覺得:那明白了,知道怎麼辦了,把日誌格式化都寫到數據中台里,有問題就寫SQL查!!!
我想說的是:too young,too simple!
使用數據中台排查此類問題的弊端
使用數據中台寫SQL查詢格式化後的日誌,困難指數是兩顆星,但問題是,這有個前提:得先把日誌格式化後寫到中台里!關鍵問題是這步操作並不簡單。
企業自建或購買的第三方數據中臺大多是OLAP類的數倉/數據湖的解決方案,當然有些企業比較有錢,喜歡用ES來搞。
日誌是非結構化的數據,是比較混亂的一種數據結構。一般來說企業的日誌數據有兩種:一是前端(App/H5/PC)上報的埋點日誌,二是後端業務系統自己輸出的日誌。前端上報的埋點日誌還較好一點,起碼有用戶信息、設備信息、埋點類型等固定參數,此外再加上不同埋點類型對應的自定義參數。
如果數據異常問題只涉及前端埋點日誌,企業也已經搭建好較為完善的埋點日誌存儲和查詢平臺、並且每種埋點類型的日誌都已將關鍵欄位提取後格式化存儲了,那這種情況比較理想基本只要寫SQL就行了,寫SQL看數雖然不夠清晰直觀,但還是可以湊合用的。不過如果企業的數據中台搭建不夠完善或者埋點定義比較混亂的話,那就得寫代碼處理了。
但前端埋點只涉及用戶行為側數據,而很多業務邏輯處理細節的日誌數據就不包含了,這時候就需要基於後端日誌來實現。大家都知道通過後端日誌排查一些異常信息、鏈路追蹤等問題相對容易,
但是後端日誌沒有任何規範可言,後端日誌類型遠遠超過前端日誌,而且會隨時添加、隨時刪除、隨時變更格式。如果想基於後端日誌進行統計分析絕對是一段讓人痛苦不堪、叫苦連天的經歷,如果想把混亂的後端日誌寫入數據平臺再進行統計分析難度超乎尋常的大。
再者來說,從我過往的經驗和教訓來看,很多時候一份數據並不可靠,關鍵數據是需要交叉驗證的!
我列舉兩個小例子,你就明白了:
1、服務A調用服務B的介面,數據監控應該加在服務A側還是服務B側?
或者服務A與服務B通過消息中間件通信,A將數據寫入消息服務,B從消息中間件中讀取數據,統計監控應該加在服務A側還是服務B側?
準確來說,如果業務比較重要的話,應該兩端都加,否則即使對方拿出錯誤的統計數據來質疑你的時候,你可能都難以辯解!
2、App端有個重要的表單提交功能,如果要統計用戶表單提交量,應該用前端埋點的上報量還是後端介面的請求量還是DB的寫入量?
有些朋友可能會覺得:這還用說嗎,業務數據肯定是以DB寫入為準啊。沒錯,不過如果從服務監控和排查問題的角度來看,如果業務較為重要,三個階段的數據監控應該都加,也就是表單埋點上報階段、後端介面被請求時以及後端將表單數據寫入DB時!
完善的服務監控體系,在於數據指標之間的互相印證!
說到這裡,數據中台的弊端就已經較為明顯,我們可以總結一下大概有幾點:
- 數據中台接入困難;
- 為了應對查詢,數據中台內部需要維護龐大量級的日誌數據(前端日誌 + 後端日誌),給企業帶來很大的伺服器費用和維護費用;
- 使用數據中台需要隨時應對日誌的格式、參數變化可能會導致數據中台內欄位的變化;
- 日誌的結構和參數發生變化後,數據中台內部往往會同時存在相同日誌類型,但格式不同的多種數據,這很可能導致統計分析的錯誤;
- 數據中台很難實現對指定日誌類型快速的上下線;
- 使用數據數據中台查詢統計數據,需要寫大量的SQL,很浪費時間而且數據展示不夠直觀;
數據中台臃腫笨拙,即便是一線大廠擁有充足的資金和人力也沒有可能使用數據中台建立起較為全面的服務監控體系。
所以,不管是寫程式還是用數據中台排查此類問題並不能算是一個十分高明的方案,或者說僅僅只是一個還湊合的方案!
我所推薦的方案
現在的產品邏輯、業務邏輯越來越複雜,而數據異常很多時候會涉及企業安身立命的根本,畢竟數據異常很可能會帶來直接或間接的經濟損失和用戶流失!
那還有沒有其他更便捷、更清晰、更立體、更周全的解決方案了呢?
有,當然有,這就是我接下來要鄭重向大家推薦的:開源通用型流式大數據統計系統XL-LightHouse。
絕大多數朋友應該還沒有聽說過它,甚至連通用型流式數據統計都沒有聽說過,那它相比業內目前使用的方案究竟有什麼優勢呢?
我一直偏執的認為:解決此類問題通用型流式數據統計是唯一接近完美的解決方案!
用一句話評價它在排查數據異常類問題的使用體驗,那就是:簡單、簡單、你未曾體驗過的簡單!
XL-LightHouse與眾不同的特點
- 1、輕量級
XL-LightHouse以通用型流式數據統計為切入點,雖然它是一款大數據類系統,但從使用層面上來說,其實是一個非常輕量級,幾乎沒有任何使用門檻的系統。你可以一鍵就將它部署到伺服器上,至於如何使用,那就更簡單了。
只要在Web頁面配置相應的元數據結構、創建統計項,再調用它的API將欄位數據上報上來,然後就可以在Web端查看統計結果了。
它的整個使用流程簡單到幾乎不用看文檔就可以完成,相比OLAP那一套笨拙、複雜的接入流程,它簡直像張白紙一目瞭然。如果你部署完成後5分鐘還沒有弄明白該如何使用,都會讓我覺得這個項目還有極大的優化空間!
相比於OLAP類系統它不支持原始數據明細查詢、不支持多維度欄位隨意組合的即席查詢。
這與它自身定位有關,XL-LightHouse是流式大數據統計系統,它不希望被任何可有可無的功能影響了它的輕便性和它在流式統計方面彪悍的計算性能,它不希望像OLAP那類系統一樣,追求功能的完善,卻把自己搞的笨重不堪,用戶使用起來也感覺非常不便。
XL-LightHouse竭盡所能期望為用戶打造信手拈來的愉悅感和輕鬆駕馭的暢快感。
- 2、功能強大
XL-Lighthouse在流式統計、數據監控等方面的功能可謂十分強大。
- XL-LightHouse目前已涵蓋了各種流式數據統計場景,包括count、sum、max、min、avg、distinct、topN/lastN等多種運算,支持多維度計算,支持分鐘級、小時級、天級多個時間粒度的統計,支持自定義統計周期的配置。
- XL-LightHouse內置豐富的轉化類函數、支持表達式解析,可以滿足各種複雜的條件篩選和邏輯判斷。
- XL-LightHouse提供了完善的可視化查詢功能,對外提供API查詢介面,此外還包括數據指標管理、許可權管理、統計限流等多種功能。
- XL-LightHouse支持時序性數據的存儲和查詢。
元數據欄位可以根據需要隨意指定,一份元數據下有多少統計項可以隨意指定,統計任務上線或下線可以隨意指定,
它的架構設計更加貼合流式統計的運算特點,並對每一種運算單元都進行了很多層面的性能優化,支持超大數據量和超高併發,在它的功能範圍內你幾乎可以隨心所欲的添加和管理你所需要的統計指標。
如何使用XL-LightHouse排查數據異常類問題?
歸根到底是一句話:在任何你有需要的地方加上流式統計。
比如:
- 可以用它統計一個if/else的分支,每分鐘各被執行多少次;
- 可以用它統計一個訂單介面,每5分鐘有多少人下單和下單總金額;
- 微服務A同時調用微服務B、C、D,可以用它統計每天每個微服務各個介面調用量、異常量和耗時情況,甚至每種錯誤碼的返回次數;
- 可以用它統計,前端上報的數據中某個參數為空的請求占比;
- 可以用它統計一個Feed推薦介面,每小時召回帖子的數量、每種召回模型、ABTest策略、不同的地區、不同的內容分類召回帖子的數量;
— 可以用它監控一個KV存儲服務,每天數據寫入量和每天數據查詢量,甚至每個key首碼的寫入量和查詢量;
— 可以用它監控APP的啟動耗時,彈窗廣告的彈出次數; - 可以用它統計APP內某個廣告的下發量、點擊量、點擊UV和點擊率;
- 可以用它監控一個新聞資訊類APP的內容池每小時各個渠道的新增帖子量;
- 可以用它統計一個社交類APP每天聊天消息、聊天表情、紅包的發送量;
- 可以用它統計每天銷售額top100的商戶列表;
- 可以用它統計任意細粒度、任意維度的數據;
- ......
總之,在它的功能範圍之內,你可以根據自己的實際需求隨心所欲的創建統計指標!
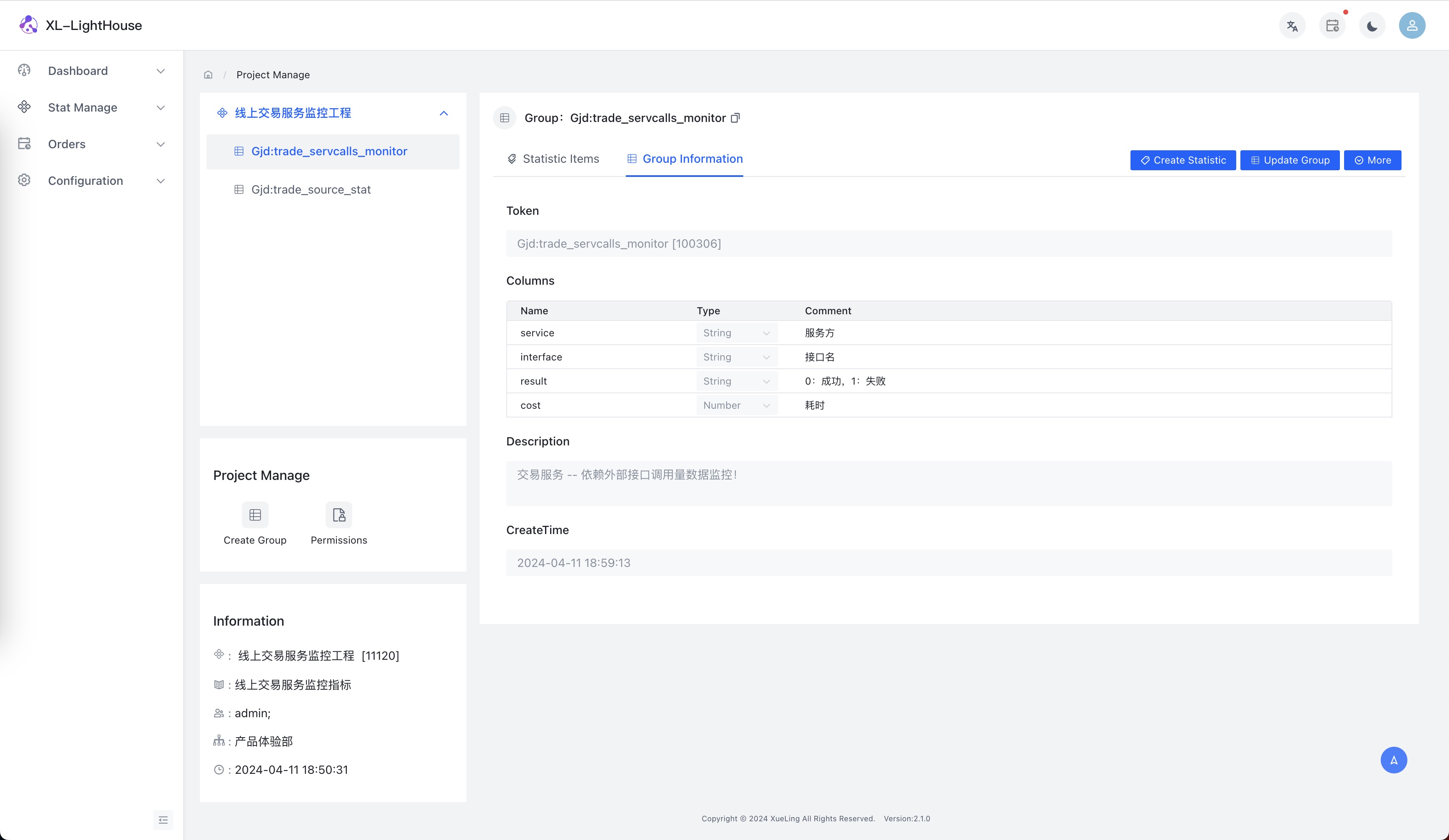
- 示例1:依賴服務介面調用量監控
假設場景:微服務A中要調用其他的服務,我們需要監控各依賴服務的介面調用量、異常量和耗時情況數據。
(有些朋友可能會覺得公司的RPC服務針對各介面的互相調用情況監控數據都已經具備了,為啥還要再監控,我這裡只是舉個例子,其實本質不一樣,公司RPC服務所提供的數據都是定死的一些監控指標,而用XL-LightHouse具有非常強大的靈活性,可以根據自身需求定製!)
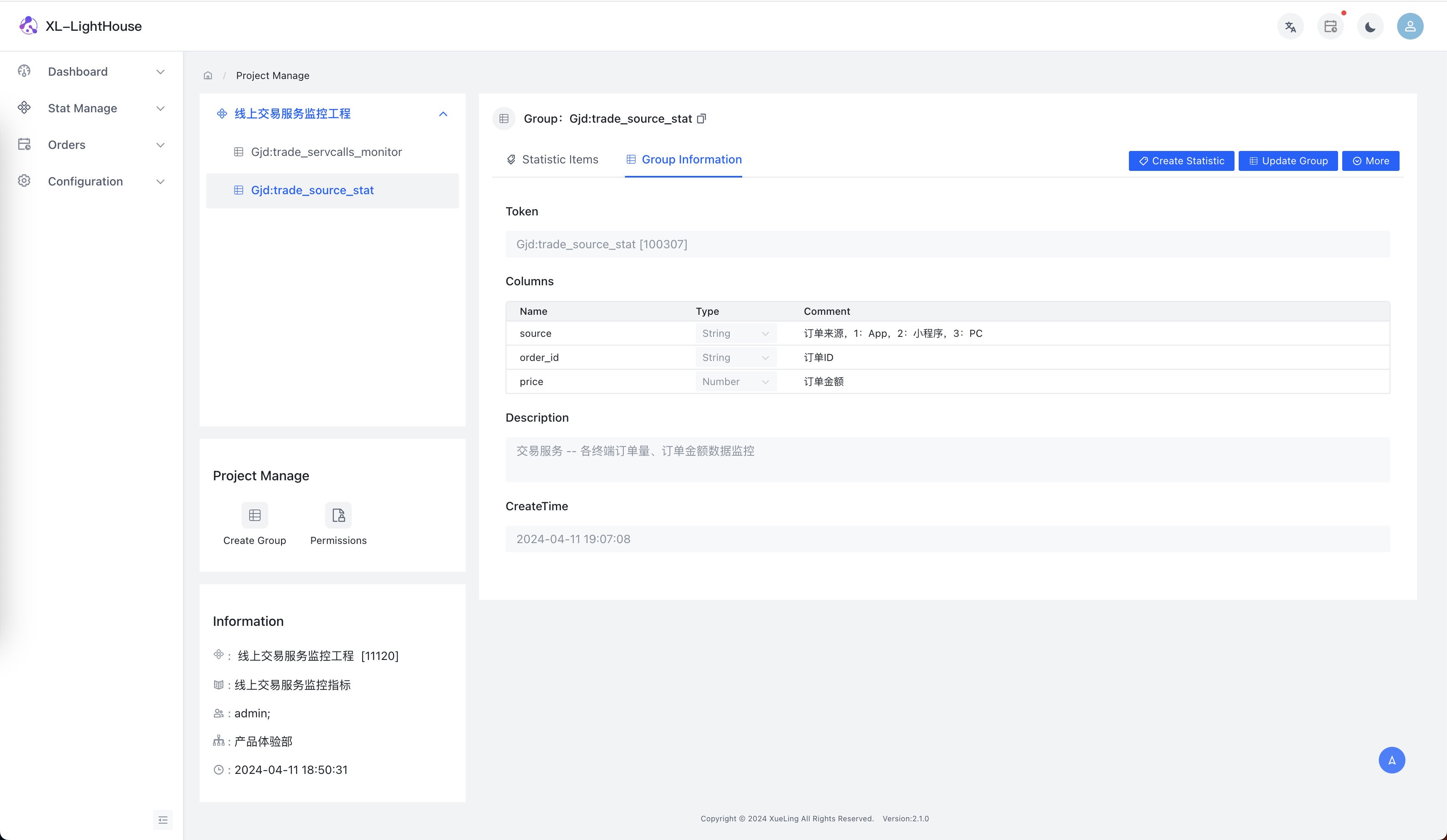
- 示例2:各終端訂單量數據監控
假設場景:交易服務需要監控不同來源下單量的數據。
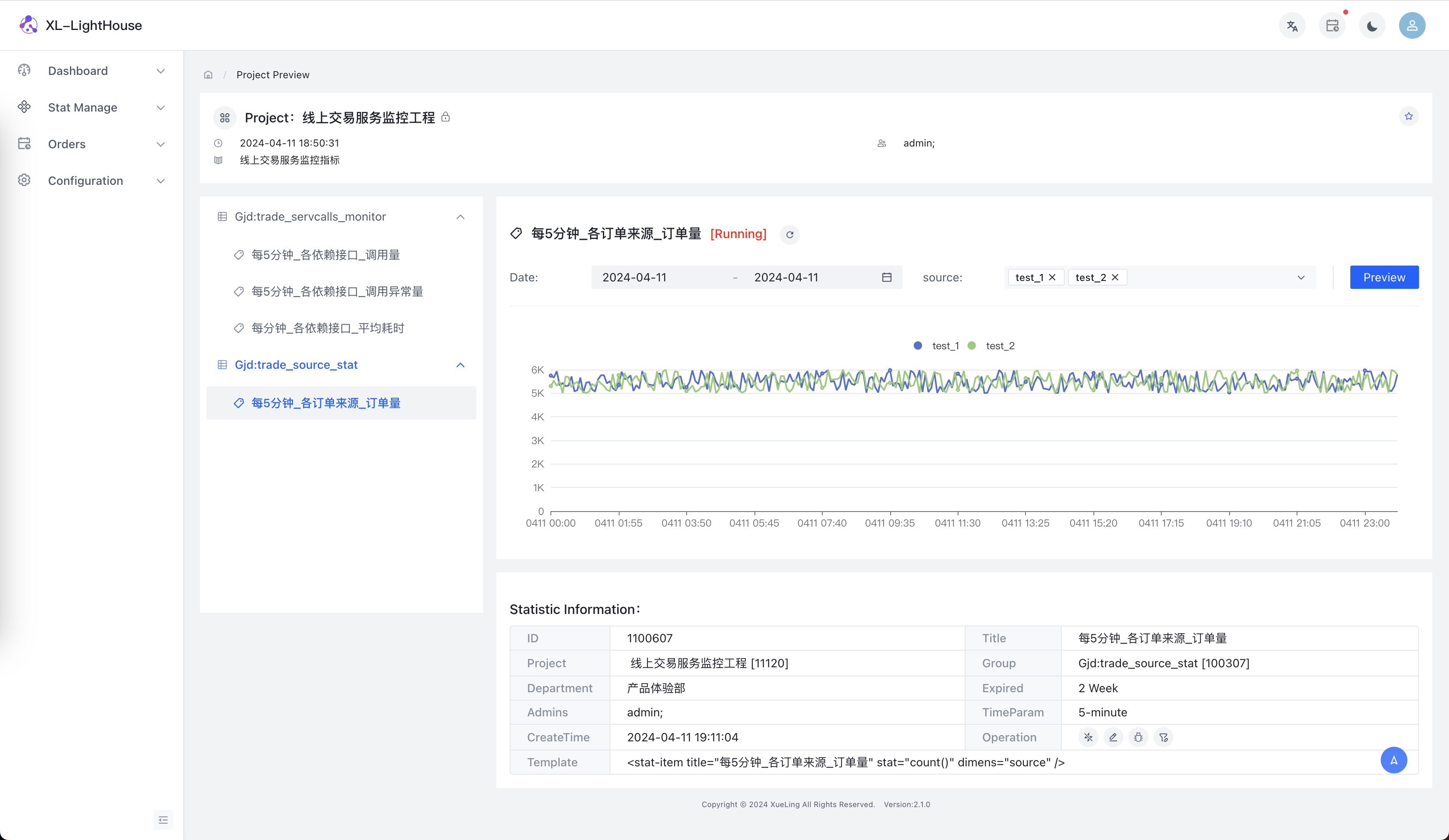
- 模擬數據接入
public class Testing {
static {
try{
//配置RPC服務地址
LightHouse.init("10.206.6.39:4061,10.206.6.21:4061");
}catch (Exception ex){
ex.printStackTrace();
}
}
@Test
public void testStat() throws Exception {
long t = System.currentTimeMillis();
for(int i = 0;i<10000;i++){
//修改統計組參數值、Token和秘鑰
Map<String,Object> map = new HashMap<>();
map.put("source", ThreadLocalRandom.current().nextInt(3));
map.put("order_id",RandomID.id(3));
double price = ThreadLocalRandom.current().nextDouble(1,9999);
map.put("price",String.format("%.2f", price));
LightHouse.stat("Gjd:trade_source_stat","g2BjBuC0g4euWcMzqQXAAlKFcIBPbexQNLovqK9z",map,t);
}
System.out.println("send ok!");
Thread.sleep(30000);
}
}
- 查看結果
擔心代碼侵入怎麼辦?
XL-LightHouse對外提供JavaSDK,如果是Java類系統可以在自己的服務中直接調用API。
有些企業的服務並不是基於Java語言開發或者本身不想在使用時有太多的代碼侵入該怎麼辦?
很簡單,只要再額外部署一套Kafka或者其他的消息組件,自身服務將相關參數數據寫入到消息組件中,然後在消費消息數據時調用xl-lighthouse的sdk就可以了,這套消息服務和消費邏輯可以企業內部共用。
結束語
線上服務監控體系可以根據實際需求陸續創建,等你將監控體系建立完備,這將使你對線上服務的駕馭能力得到空前的提升,五分鐘內定位數據異常問題絕非信口開河,每次線上數據異常都是展示你能力的絕佳機會,升職加薪在向你招手~
本文可以隨意轉載!

