
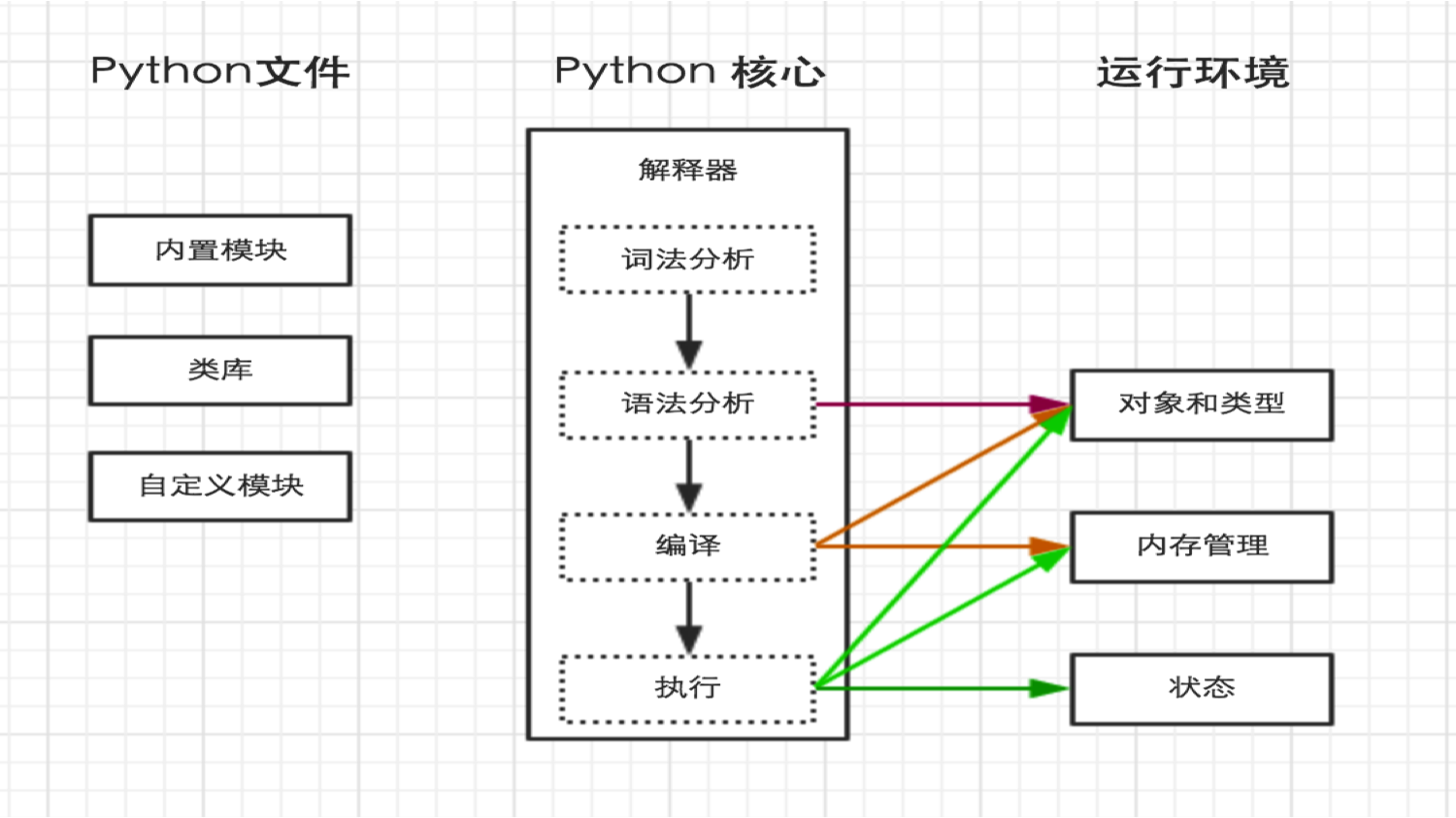
python內部執行流程 編碼 預設情況下,Python3源碼文件以UTF-8編碼,所有字元串都是Unicode字元串。當然也可以為源碼文件指定不同的編碼: # -*- coding: cp-1252 –*- 1. ASCII python2的解釋器在載入.py文件中的代碼時,會對內容進行編碼(預設... ...
python內部執行流程
編碼
預設情況下,Python3源碼文件以UTF-8編碼,所有字元串都是Unicode字元串。當然也可以為源碼文件指定不同的編碼:
# -*- coding: cp-1252 –*-
1. ASCII
python2的解釋器在載入.py文件中的代碼時,會對內容進行編碼(預設ASCII)
ASCII是基於拉丁字母的一套電腦編碼系統,主要用於顯示現代英語和其他西歐語言,其最多只能用8位來表示(1個位元組),即:2**8=256.所有ASCII碼最多只能表示256個符號


2. Unicode
Unicode(統一碼、萬國碼、單一碼)是電腦科學領域里的一項業界標準,包括字元集、編碼方案等。Unicode 是為瞭解決傳統的字元編碼方案的局限而產生的,它為每種語言中的每個字元設定了統一併且唯一的二進位編碼,以滿足跨語言、跨平臺進行文本轉換、處理的要求。Unicode規定所有的字元和符號最少由16位來表示(2個位元組),即:2**16=65536
3.UTF-8
UTF-8(8-bit Unicode Transformation Format)是一種針對Unicode的可變長度字元編碼。由Ken Thompson於1992年創建。現在已經標準化為RFC 3629。UTF-8用1到4個位元組編碼UNICODE字元。用在網頁上可以同一頁面顯示中文簡體繁體及其它語言(如英文,日文,韓文)。它不在使用最少兩個位元組,而是對所有的字元和符號進行分類:ASCII碼中的內容使用1個位元組、歐洲字元使用2個位元組、東亞字元使用3個位元組……
標識符
在編程語言中,標識符就是程式員自己規定的具有特殊含義的詞,比如:類名、函數名、屬性名、變數名等。
- 第一個字元必須是字母表中的字元或者下劃線“_”
- 標識符的其他部分可以由字母、數字和下滑線組成
- 標識符區分大小寫
- python3中,非ASCII標識符也是允許的
以下劃線開頭的標識符具有特殊意義。以單下劃線開頭(_foo)的代表不能直接訪問的類屬性,需通過類提供的介面進行訪問,不能用“from *** import ***”而導入;以雙下劃線開頭的(__foo)代表類的私有成員;以雙下劃線開頭和結尾的(__foo__)代表python里的特殊方法專用的標識,如__int__()代表類的構造函數。
python保留字
保留字即關鍵字,不能把保留字用作任何標識符名稱。Python的標準庫提供了一個keyword module,可以輸出當前版本的所有關鍵字:
>>> import keyword >>> keyword.kwlist ['False', 'None', 'True', 'and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']
註釋
Python中的單行註釋以#開頭
#!/usr/bin/env python # coding=utf-8 # 第一行註釋 print("hello world!") # 第一行註釋 """ 多行 註釋 """ ''' 多行 註釋 '''
行與縮進
python中通過使用縮進來表示代碼塊,不需要使用大括弧“{}”,縮進的空格數是可變的,但是同一個代碼塊語句的縮進空格數必須一致。
if True: print("True") else: print("False")如果縮進不一致,會導致運行錯誤
#!/usr/bin/python3 # -*- coding: UTF-8 -*- # 文件名:test.py if True: print("Answer") print("True") else: print("Answer") # 沒有嚴格縮進,在執行時保持 print("False")le "/****/****", line 10 print("False") ^ IndentationError: unexpected indent
單語句多行
python通常一行寫完一個語句,但如果語句很長,可以使用反斜杠“\”來實現多行語句,例如:
A = "a" B = "b" C = "c" abc = A + \ B + \ C在”[]”、”{}”、”()”中的不需要使用反斜杠“\”,例如:
A = {"a", "b", "c"} B = """keep live""" C = '''home work'''
數據類型
- 數字
- 布爾值
- 字元串
- 列表
- 字典
- 元組
空行
函數之間或類的方法之間用空行分隔,表示一段新的代碼的開始。類和函數的入口之間也用一行空行分隔,以突出函數入口的開始。空行與代碼縮進不同,空行並不是python語法的一部分。書寫時不插入空行,python解釋器也不會報錯。但是空行可以分隔兩段不同功能或含義的代碼,便於日後的維護和重構。
註:空行也是程式代碼的一部分
多語句單行
python中可以在同一行中使用多條語句,語句之間使用分號“;”分隔。
如下實例:
#!/usr/bin/python3 import sys; x = 'runoob'; sys.stdout.write(x + '\n')
多個語句構成代碼組
縮進相同的一組語句構成一個代碼塊,我們稱之為代碼組。像if、while、def、class這樣的複合語句,首行以關鍵字開始,以冒號“:”結束,該行之後的一行或多長代碼構成代碼組。我們將首行及後面的代碼組成為一個子句(clause)。
如下實例:
if expression : suite elif expression : suite else : suite
.pyc文件
執行Python代碼時,如果導入了其他的.py文件,那麼在執行過程中會自動生成一個與其同名的.pyc文件,該文件就是python解釋器編譯之後產生的位元組碼
註:代碼經過編譯可以產生位元組碼,位元組碼通過反編譯也可以得到代碼


