
Redis大家都不陌生,就算是沒用過,也都聽說過了。 作為最廣泛使用的KV記憶體資料庫之一,在當今的大流量時代,單機模式略顯單薄,免不了要有一些拓展的方案。 筆者下文會對各種方案進行介紹,並且給出場景,實現 等等概述,還會提到一些新手常見的誤區。 正文 先從基礎的拓展方式開始,這樣更便於理解較高級的模 ...
Redis大家都不陌生,就算是沒用過,也都聽說過了。
作為最廣泛使用的KV記憶體資料庫之一,在當今的大流量時代,單機模式略顯單薄,免不了要有一些拓展的方案。
筆者下文會對各種方案進行介紹,並且給出場景,實現 等等概述,還會提到一些新手常見的誤區。
正文
先從基礎的拓展方式開始,這樣更便於理解較高級的模式。
ps: 本文背景是以筆者落筆時官網最新穩定版5.0.8為準,雖然還沒寫完就變成了6.0.1。
分區
概述
分區(Partitioning)是一種最為簡單的拓展方式。
在我們面臨單機的存儲空間瓶頸時,第一點就能想到像傳統的關係型資料庫一樣,進行數據分區。
或者假設手中有N台機器可以作為Redis伺服器 所有機器記憶體總和有256G, 而客戶端正好也需要一個大記憶體的存儲空間。
我們除了可以把記憶體條都拆下來焊到一個機器上,也可以選擇分區使用,這樣又拓展了計算能力。
單指分區來講,即將全部數據分散在多個Redis實例中,每個實例不需要關聯,可以是完全獨立的。
使用方式
- 客戶端處理 和傳統的資料庫分庫分表一樣,可以從key入手,先進行計算,找到對應數據存儲的實例在進行操作。範圍角度,比如orderId:1orderId:1000放入實例1,orderId:1001orderId:2000放入實例2...哈希計算,就像我們的hashmap一樣,用hash函數加上位運算或者取模,高級玩法還有一致性Hash等操作,找到對應的實例進行操作
- 使用代理中間件 我們可以開發獨立的代理中間件,屏蔽掉處理數據分片的邏輯,獨立運行。當然也有他人已經造好的輪子,Redis也有優秀的代理中間件,譬如Twemproxy,或者codis,可以結合場景選擇是否使用。
缺點
- 無緣多key操作,key都不一定在一個實例上,那麼多key操作或者多key事務自然是不支持。
- 維護成本,由於每個實例在物理和邏輯上,都屬於單獨的一個節點,缺乏統一管理。
- 靈活性有限,範圍分片還好,比如hash+MOD這種方式,如果想動態調整Redis實例的數量,就要考慮大量數據遷移,這就非常麻煩了。
同為開發者,深知我們雖然總能“曲線救國”的完成一些當前環境不支持的功能,但是總歸要麻煩一些。
推薦一個開源免費的 Spring Boot 實戰項目:
主從
概述數據遷移
常說的主從(Master-Slave),也就是複製(Replication)方式,怎麼稱呼都可以。
同上面的分區一樣,也是Redis高可用架構的基礎,新手可能會誤以為這類基礎模式即是“高可用”,這並不是十分正確的。
分區暫時能解決單點無法容納的數據量問題,但是一個Key還是只在一個實例上,在大流量時代顯得不那麼可靠。
主從就是另一個緯度的拓展,節點將數據同步到從節點,就像將實例“分身”了一樣,可靠性又提高了不少。
[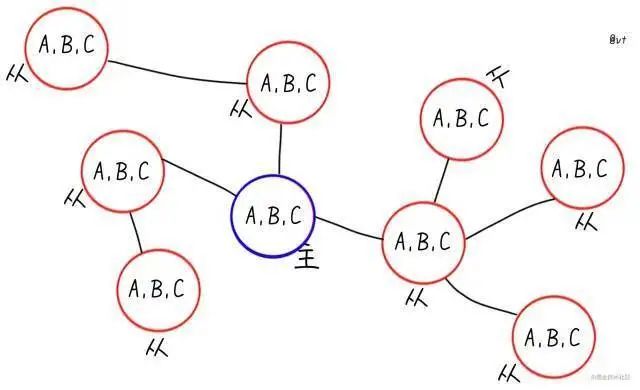
圖畫的有些誇張了,主要還是想體現結構靈活,是一主一從,還是一主多從,還是一主多從多從... 看你心情
有了“實例分身”,自然就可以做讀寫分離,將讀流量均攤在各個從節點。
使用方式

高手雲集的時代,聊天軟體難免要備上這麼一張表情包。
這表情包和使用方式有什麼關係呢?首先看看使用方式:
- 作為主節點的Redis實例,並不要求配置任何參數,只需要正常啟動
- 作為從節點的實例,使用配置文件或命令方式
REPLICAOF 主節點Host 主節點port即可完成主從配置
是不是和表情包一樣,“dalao”沒動,我去“抱大腿”。
這樣一個主從最小配置就完成了,主從實例即可對外提供服務。
命令里的“主節點”是相對的,slave也可以抱slave大腿,也就是上文提到的結構靈活。
缺點
- slave節點都是只讀的,如果寫流量大的場景,就有些力不從心了。那我把slave節點只讀關掉不就行了?當然不行,數據複製是由主到從,從節點獨有數據同步不到主節點,數據就不一致了。
- 故障轉移不友好,主節點掛掉後,寫處理就無處安放,需要手工的設定新的主節點,如使用
REPLICAOF no one(誰大腿我都不抱了) 晉升為主節點,再梳理其他slave節點的新主配置,相對來說比較麻煩。
哨兵
概述
主從的手工故障轉移,肯定讓人很難接受,自然就出現了高可用方案-哨兵(Sentinel)。
我們可以在主從架構不變的場景,直接加入Redis Sentinel,對節點進行監控,來完成自動的故障發現與轉移。
並且還能夠充當配置提供者,提供主節點的信息,就算發生了故障轉移,也能提供正確的地址。

哨兵本身也是Redis實例的一種,但不作為數據存儲方使用,啟動命令也是不一樣的。
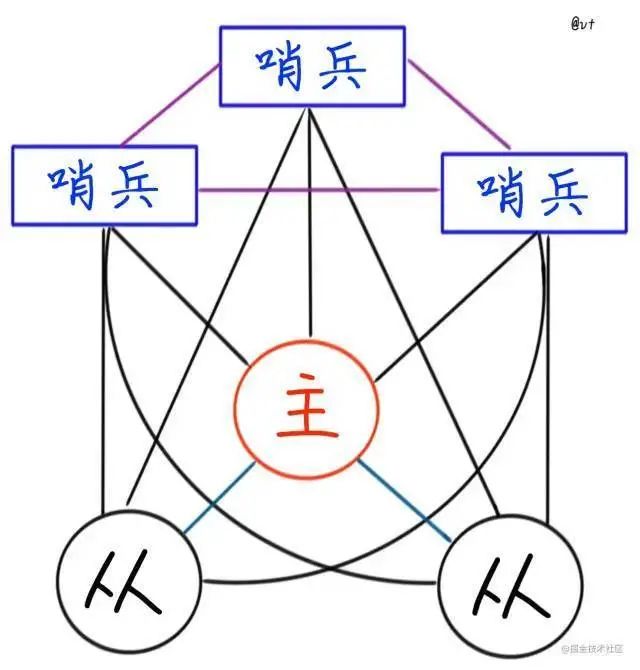
雖然圖有些複雜,看起來像要召喚光能使者。
其實實際使用起來是很便捷的。
使用方式
Sentinel的最小配置,一行即可:
sentinel monitor <主節點別名> <主節點host> <主節點埠> <票數>
只需要配置master即可,然後用redis-sentinel <配置文件> 命令即可啟用。
Redis官網提到的“最小配置”是如下所示,除了上面提到的一行,還有其它的一些配置:
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel down-after-milliseconds mymaster 60000
sentinel failover-timeout mymaster 180000
sentinel parallel-syncs mymaster 1
sentinel monitor resque 192.168.1.3 6380 4
sentinel down-after-milliseconds resque 10000
sentinel failover-timeout resque 180000
sentinel parallel-syncs resque 5
這是因為官網加了一個修飾詞,是“典型的最小配置”,把重要參數和多主的例子都寫出來了,照顧大家CV大法的時候,不要忘記重要參數,其實都是有預設值的。
正如該例所示,設置主節點別名就是為了監控多主的時候,與其額外配置項能夠與其對應, 以及sentinel一些命令,如SENTINEL get-master-addr-by-name就要用到別名了。
哨兵數量建議在三個以上且為奇數,在Redis官網也提到了各種情況的“佈陣”方式,非常值得參考。
更多
既然是高可用方案,並非有嚴格意義上的“缺點”,還需配合使用場景進行考量。
- 故障轉移期間短暫的不可用,但其實官網的例子也給出了
parallel-syncs參數來指定並行的同步實例數量,以免全部實例都在同步出現整體不可用的情況,相對來說要比手工的故障轉移更加方便。 - 分區邏輯需要自定義處理,雖然解決了主從下的高可用問題,但是Sentinel並沒有提供分區解決方案,還需開發者考慮如何建設。
- 既然是還是主從,如果異常的寫流量搞垮了主節點,那麼自動的“故障轉移”會不會變成自動“災難傳遞”,即slave提升為Master之後掛掉,又進行提升又被掛掉。不過最後這點也是筆者猜測,並沒有聽說過出現這種案例,可不必深究。
集群
概述
Redis Cluster是官方在3.0版本後推出的分散式方案。
對開發者而言,“官方支持”一詞是大概率非常美好的,小到issue,大到feature。自定義去解決問題,成本總是要高一些。
有了官方的正式集群方案,從請求路由、故障轉移、彈性伸縮幾個緯度的使用上,將更為容易。
Cluster不同於哨兵,是支持分區的。有說法Cluster是哨兵的升級,這是不嚴謹的。
二者緯度不一樣,如果因為Cluster也有故障轉移的功能,就說它是哨兵的升級款,略顯牽強。
Cluster在分區管理上,使用了“哈希槽”(hash slot)這麼一個概念,一共有16384個槽位,每個實例負責一部分槽,通過CRC16(key)&16383這樣的公式,計算出來key所對應的槽位。

雖然在節點和key二者中又引入了槽的概念,看起來不易理解,實際上因為顆粒度更細了,減少了節點的擴容和收縮難度,相比傳統策略還是很有優勢。
當然,“槽”是虛擬的概念,節點自身去維護“槽”的關係,並不是要真正下載啟動個“槽服務”在跑。
使用方式
Redis的各種玩法,都是從配置文件著手,集群也不例外。
cluster-enabled yes
cluster-config-file "redis-node.conf"
關鍵配置簡潔明瞭,有兩步
- 開啟集群
- 指定集群配置文件
集群配置文件(cluster-config-file)為內部使用,可以不去指定,Redis會幫助創建一個。啟動還是普通的方式redis-server redis.conf
首先以集群方式啟動了N台Redis實例,這當然還沒完事。
接下來的步驟筆者稱為“牽線搭橋分配槽”,聽起來還算順口。
“牽線搭橋分配槽”的方式也在不斷升級,從直接用原始命令來處理,到使用腳本,以及現在的Redis-cli官方支持,使用哪種方式都可以。
redis-cli --cluster create 127.0.0.1:7000 127.0.0.1:7001 \
127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 \
--cluster-replicas 1
上方的命令即是Redis官網給出的redis-cli的方式用法,一行命令完成“三主三從”以及自動分配槽的操作。
這樣集群就搭建完成了,當然,使用官方提供的check命令檢查一下,也是有必要的。
redis-cli --cluster check 127.0.0.1:7001
更多
- 雖然是對分區良好支持,但也有一些分區的老問題,譬如:如果不在同一個“槽”的數據,是沒法使用類似mset的多鍵操作。
- 在select命令頁有提到, 集群模式下只能使用一個庫,雖然平時一般也是這麼用的,但是要瞭解一下。
- 運維上也要謹慎,俗話說得好,“使用越簡單底層越複雜”,啟動搭建是很方便,使用時面對帶寬消耗,數據傾斜等等具體問題時,還需人工介入,或者研究合適的配置參數。
結尾
趣談
在寫“主從”方案的時候,發現有一個有趣的事情:
筆者開始是記得主從的關鍵命令是SLAVEOF,後來查閱官方的時候,發現命令已經更改為REPLICAOF,雖然SLAVEOF還能用。
官網的一些描述辭彙,有的地方還是Slave,也有些是用Replication。
好奇的筆者查了一下相關的資料,並看了些Redis作者antirez的有關此時博客,發現已經是兩年前的事情了。
其實就是“Slave”這個變數名給了一些人機會,藉此“噴”了一波作者,作者也做出了一部分妥協。
有興趣的盆友可以自己搜搜看,技術外的東西就不做評價了,看個樂呵就行。
筆者的主要目的還是:看官方文檔的時候,別讓不同的“辭彙”迷惑了。
來源 | https://juejin.cn/post/6844904147943161869
更多文章推薦:
2.2,000+ 道 Java面試題及答案整理(2024最新版)
3.免費獲取 IDEA 激活碼的 7 種方式(2024最新版)
覺得不錯,別忘了隨手點贊+轉發哦!


