
Slow Log 簡介 用於記錄執行時間超過指定值的 SQL 語句的詳細信息,多用於調試和監控。 配置 因為開啟會略微影響性能,所以預設沒有開啟,所以需要配置。 查看是否開啟 show variables like '%slow%'; + + + | Variable_name | Value | ...
Slow Log
簡介
用於記錄執行時間超過指定值的 SQL 語句的詳細信息,多用於調試和監控。
配置
因為開啟會略微影響性能,所以預設沒有開啟,所以需要配置。
查看是否開啟
show variables like '%slow%';
+---------------------+-------------------------------------+
| Variable_name | Value |
+---------------------+-------------------------------------+
| slow_launch_time | 2 |
| slow_query_log | OFF |
| slow_query_log_file | .../slow.log |
+---------------------+-------------------------------------+
若沒有開啟,在命令行執行,註意給足文件所在目錄的許可權。
set global slow_query_log = on;
set global slow_launch_time= 1;
set global slow_query_log_file = /var/log/mysql/slow.log;
想要永久生效,可在/etc/my.cnf中寫入,註意給足文件所在目錄的許可權。
slow_query_log = 1
slow_query_log_file = /var/log/mysql/slow.log
long_query_time = 2
打開日誌驗證:
# Time: 2024-02-21T12:18:10.954969Z
# User@Host: root[root] @ localhost [::1] Id: 3
# Query_time: 20.001907 Lock_time: 0.000000 Rows_sent: 1 Rows_examined: 0
SET timestamp=1708517890;
select sleep(20);
Redo Log
簡介
重做日誌,記錄了資料庫中發生的每次修改,如增、刪、改、對數據頁的更改。這些修改被記錄在 redo 日誌中,以便在資料庫崩潰或意外關閉時能夠恢復到最近的一致狀態。
解決了什麼問題
在宕機或者斷電等其它異常的情況下,確保數據的一致性,持久性,增加高可用性。
必須提前知道一些背景:讀數據頁時,需要把磁碟上的頁緩存到記憶體中的buffer pool中,所有的變更,也是先更新緩衝池,此時並沒有持久化到磁碟,稱之為臟頁,然後臟頁通過checkpoint機制去刷盤。
如果實時刷盤,代價太大,用戶改了1位元組的數據,都需要整頁刷盤,如果用戶改了大量的數據,就需要立即同步到多個頁上,隨機io性能低下。所以採用了非實時刷盤的策略。
假定一秒刷一次盤,第0.9秒時機器斷電或被強制停止,這0.9秒的進度在記憶體中就丟失了,為了保證高可用,所以MySQL採用redo log的方式來保證這0.9秒的進度不丟失。
InnoDB採用的是WAL技術,在事務提交時先寫入日誌(Redo Log)記錄事務所做的修改操作,再寫磁碟,如果期間斷電,下次啟動時,也可以使用redo log來恢複數據進度。
註意上面的事務提交,不僅僅是顯式聲明的事務,只要auto commit已打開,每個單獨的DML語句(增、刪、改)通常會被視為一個獨立的事務。
寫redo log的代價比同步臟頁到磁碟的代價要小。
配置
查看記憶體上的重做緩衝大小(預設16MB,最大4096MB,最小1MB):
select @@innodb_log_buffer_size; 或 show variables like 'innodb_log_buffer_size';
設置記憶體上的重做緩衝大小(低版本只讀,不支持修改):
set global innodb_log_buffer_size = 16777216 ;
也可在配置文件中
[mysqld]
innodb_log_buffer_size = 16777216
架構
組成:
redo log可以分為兩部分,記憶體上的的重做日誌緩衝,和磁碟上的重做日誌文件。
磁碟上的重做日誌在設置的datadir目錄下,通常叫做ib_logfile0,ib_logfile1,兩個大小一致的文件(預設48MB)。
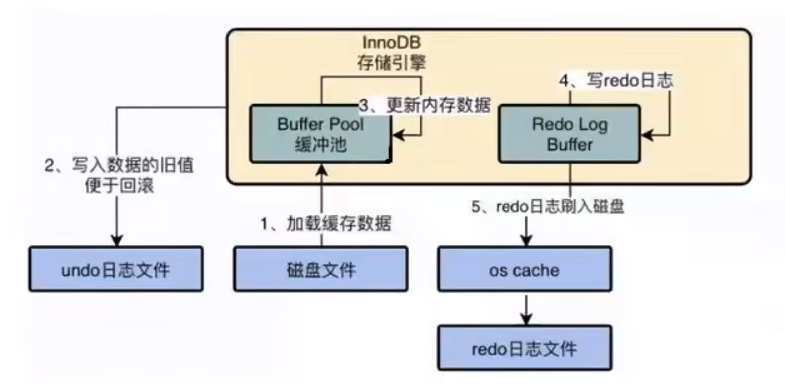
執行流程,假設執行update語句:
- 先寫redo log到redo log buffer。
- 更新記憶體中的數據頁(改的是SQL,不是redo)。
- 事務提交時,用追加寫的方式,將記憶體中的重做日誌緩衝,寫入重做日誌(改的是redo,不是SQL)。
- 通過一些checkpoint策略,定期將記憶體中修改的update數據刷新到磁碟(改的是SQL,不是redo)。
從redo log buffer到 redo log file的刷盤策略
從redo log寫入磁碟,MySQL提供了一個線程來處理redo log 的寫入操作,可以減少對主線程的影響。
通過 innodb_flush_log_at_trx_commit配置來變更刷盤策略,預設為1,安全性最好,性能最差。
0 :不管事務是否提交,每隔1秒將redo log buffer寫入到 redo log file。
1 :每次事務提交時,都將redo log buffer寫入到 redo log file。
2 :每次事務提交時,只把redo log buffer寫入操作系統的page cache(page cache的控制權是操作系統,page cache也是記憶體,此舉是讓操作系統自主控制從記憶體刷入磁碟的動作),這個階段MySQL的任務完成了,所以MySQL掛了不會丟數據,伺服器系統掛了會丟失數據。
註意,修改這個值為0,會極大提高MySQL InnoDB引擎的寫入速度,適合對對事務持久性要求較低的場景。
用插入數據實測(不想開虛擬機,用的windows),改成0的速度比改成2快2倍,比改成1快57倍。
Undo Log
簡介
回滾日誌,用於記錄事務所做的更改,以便在事務回滾或發生回滾操作時能夠撤銷事務中的修改。
如果使用undo log回滾,這個回滾的動作,也會產生redo log,用於保證數據的高可用。
解決了什麼問題
如果一個事務執行了一部分,突然SQL執行出錯了,進程被強制幹掉了,斷電了,或者回滾,這種情況下沒有undo log,則無法完成原子性回滾操作。
提供MVCC的支持。
架構
組成:
日誌通常在ibdata1文件里。
相關配置:
innodb_undo_directory: undo日誌文件的存儲路徑,預設為 ./,表示與數據文件存儲在同一目錄下。
innodb_undo_tablespaces: undo表空間的數量,預設為 2。每個undo表空間包含多個undo日誌文件,可以根據需要增加或減少undo表空間的數量。
innodb_max_undo_log_size: 單個undo日誌文件的最大大小,預設為 10MB。可以根據實際需求調整此參數,適當增大以減少 UNDO 日誌文件的頻繁創建和刪除。
innodb_undo_logs: UNDO 日誌的數量,預設為 128。可以根據系統負載和事務頻率適當增加undo日誌的數量,以提高併發處理能力。
innodb_undo_log_truncate: 控制是否開啟 undo日誌的截斷功能,預設為 on。開啟後,可以定期截斷舊的undo日誌,釋放空間並提高性能。
執行流程,假設執行update語句:
- 定位要更新數據,將其加入到緩衝池中。
- 將舊的數據寫入undo log,為數據回滾做準備。
- 更新緩衝池中的數據(SQL)。
- 隨後記錄redo log,走redo log那套邏輯。
Bin Log
簡介:
二進位日誌,記錄所有DDL、DML的日誌,用於主從伺服器之間的數據同步。
也可用於MySQL意外停止情況下的數據恢復。
解決了什麼問題
沒它做不了主從複製。
binlog做數據備份與恢復
配置
查看相關配置
show variables like 'log_bin%';
+---------------------------------+-------+
| Variable_name | Value |
+---------------------------------+-------+
| log_bin | OFF |
| log_bin_basename | |
| log_bin_index | |
| log_bin_trust_function_creators | OFF |
| log_bin_use_v1_row_events | OFF |
+---------------------------------+-------+
各個欄位含義:
log_bin:是否啟用binlog。
log_bin_basename:二進位日誌文件目錄。
log_bin_index:二進位日誌索引文件的路徑。
log_bin_trust_function_creators:是否信任二進位日誌中的函數創建者,例如在主機上執行now();和從機上執行now();有一些時間誤差。
log_bin_use_v1_row_events:值為0表示正在使用版本2的行事件格式,值為1表示正在使用版本1的行事件格式。版本2比版本1提供了更好的性能和更好的可讀性。
推薦直接改配置文件,以下簡單的幾行配置就可以,如果需更多的自定義配置,可以再添加
vim /etc/my.cnf
[mysqld]
server_id=1 設置 MySQL 伺服器唯一 ID,每個伺服器要求唯一的 ID
log_bin=mysql-bin 啟用二進位日誌並設置日誌文件名
binlog_format=ROW 設置二進位日誌格式
expire_logs_days=7 設置二進位日誌過期時間,單位為天
保存完後重啟,然後在data目錄就有mysql-bin.000001文件了。
使用binlog恢複數據
-
根據時間恢復(用當前時區就好):
mysqlbinlog --start-datetime="開始時間年月日時分秒" --stop-datetime="結束時間年月日時分秒" binlog文件 | mysql -u用戶名 -p密碼 -v 資料庫名
可加--database=資料庫名,限制資料庫 -
按偏移量恢復(不建議用,pos偏移量不容易定位):
查看偏移量:show binlog events in "binlog文件";
mysqlbinlog --start-position=偏移量數字 --stop-position=偏移量數字 binlog文件 | mysql -u用戶名 -p密碼 -v 資料庫名
可加--database=資料庫名,限制資料庫。
日誌操作
- 新增:每重啟一次,就會新增一個binlog文件。
- 刪除(按文件名):
purge master logs to 'binlog文件名'刪除的是小於此編號名稱的binlog文件。 - 刪除(按時間):
purge master logs before 'YYYY-MM-DD HH:II:SS'刪除的是小於此編號名稱的binlog文件。 - 修改:直接運行DDL或DML語句吧。
- 查看:
show binary logs;
兩階段提交
redo log事務執行時就會寫入,binlog事務提交時才會寫入,寫入的時機不一樣,小概率事件,會造成數據不一致的問題。假如寫完redo log後bin log寫入異常,這可能導致主機數據正常,但是從機數據不一致。
可以使用兩階段提交的方式,就是說寫入bin log前後分別進行redo log寫入,但是redo log明明只需寫入一次就夠了,兩次又怎麼處理呢?
prepare redo log階段會寫入日誌,然後等bin log執行完畢後,在commit redo log階段判斷 bin log是否寫入成功,如果沒有寫入成功,回滾redo log,重新走以上流程。
Relay Log
簡介:
MySQL的主從複製,主伺服器會把自己的binlog發送到從伺服器。從伺服器會將接收到的binlog後,會寫入自己的中繼日誌中,然後再應用到自己的資料庫中。
相當於快遞送到了驛站。
中繼日誌只有從伺服器有,預設在data目錄下。
General log
簡介:
普通日誌,記錄日常執行過的命令,預設關閉,不建議開啟,因為每執行一個SQL就記錄一條日誌,占空間還降低性能。
若真想做SQL的調試,推薦使用編程框架的機制,自定義封裝一個日誌功能,因為MySQL日誌屬於運維層,框架日誌屬於開發層,更容易自定義和接觸的到。
解決了什麼問題
配合業務做資料庫調試使用。
配置
查看相關狀態
show variables like 'general_log%'
+------------------+--------------------------------+
| Variable_name | Value |
+------------------+--------------------------------+
| general_log | OFF |
| general_log_file | .... /你的用戶名.log |
+------------------+--------------------------------+
臨時修改全局配置
set global general_log = on;
set global general_log_file = path;
持久化配置
vim /etc/my.cnf
[mysqld]
general_log = 1
general_log_file = /var/log/mysql/mysql.log
示例日誌如下,格林尼治時間
2024-03-04T18:07:35.824760Z 8 Query select * from cs
2024-03-04T18:08:27.707305Z 8 Query select * from cs
2024-03-04T18:08:28.136048Z 8 Query select * from cs
2024-03-04T18:08:28.477068Z 8 Query select * from cs
Error log
簡介
錯誤日誌就是出錯的時候出現的日誌,對於異常排查,十分有用。
解決了什麼問題
運維,伺服器管理人員,做排查使用。
配置
show variables like 'log_error%';
+---------------------+--------------------------------+
| Variable_name | Value |
+---------------------+--------------------------------+
| log_error | ... /你的用戶名.err |
| log_error_verbosity | 3 |
+---------------------+--------------------------------+
log_error_verbosity是錯誤的等級
1:記錄錯誤信息,但不包含錯誤堆棧跟蹤。
2:記錄錯誤信息,並包括簡短的錯誤堆棧跟蹤。
3:記錄錯誤信息,並包括完整的錯誤堆棧跟蹤和源代碼行號。
內容如下:
2023-01-02T06:57:05.481440Z 0 [Note] ...mysqld (mysqld 5.7.24) starting as process 11088 ...
2023-02-18T15:51:49.645048Z 0 [Warning] Insecure configuration for --secure-file-priv: Current value does not restrict location of generated files. Consider setting it to a valid, non-empty path.
2023-02-18T15:51:49.645900Z 0 [Note] ...mysqld (mysqld 5.7.24) starting as process 4924 ...
補充:
Redo Log對比Undo Log
作用差不多,但是側重點不同。
redo log:偏向物理操作的日誌,比如針對頁的操作,保證事務的持久性。
undo log:偏向邏輯操作的日誌,記錄的是每個增、刪、改的逆向操作,以便於事務回滾,保證事務的原子性。
Redo/Undo Log對比Bin log
Redo log對比Bin log,都有持久化的功能,但是側重點不一樣,redo log偏向回滾的備份,bin log偏向主從賦值,DML、DDL操作的恢復。
redo log事務執行時就會寫入,binlog事務提交時才會寫入。
redo和undo,對比bin,前者是為了保證高可用,防止進度丟失,後者也是為了數據備份,但是也偏向主從複製。
Redo log,與DML語句結果刷盤順序?
先寫redo日誌到磁碟,在把sql執行後要寫入的數據寫入到磁碟中。
如果Redo log準備寫入磁碟時斷電,會導致進度丟失嗎?
這會導致當前執行的sql無效, 這個過程SQL 語句的修改結果,並未寫入到磁碟。
所以為了保證高可用,推薦UPS不間斷電源,通過硬體層面的加持,達到高可用。

