
mysql在windows下配置root用戶遠程訪問 1,管理員打開CMD 2,cd到mysql的bin cd C:\Program Files\MySQL\MySQL Server 8.0\bin 3,登錄mysql mysql -u root -p 4,執行sql查看當前用戶 use mysql ...

概念解釋
集群
集中式系統就是把一整個系統的所有功能,包括資料庫等等全部都部署在一起,通過一個整套系統對外提供服務
在多台不同的伺服器中部署相同應用或服務模塊,構成一個集群,通過負載均衡設備對外提供服務。
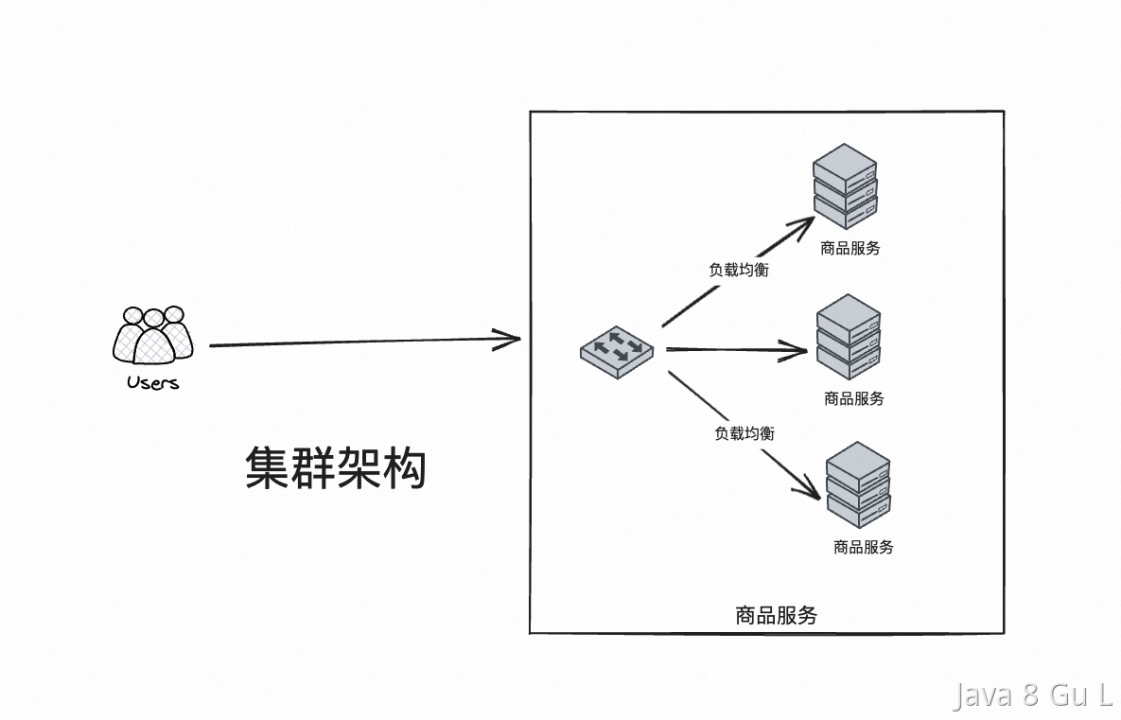
- 集中式系統存在系統大而複雜、難於維護、容易發生單點故障、擴展性差等問題
分散式
分散式是針對集中式來說的,就是把一個集中式系統拆分成多個系統,每一個系統單獨對外提供部分功能,整個分散式系統整體對外提供一整套服務
在多台不同的伺服器中部署不同的服務模塊,通過遠程調用協同工作,對外提供服務
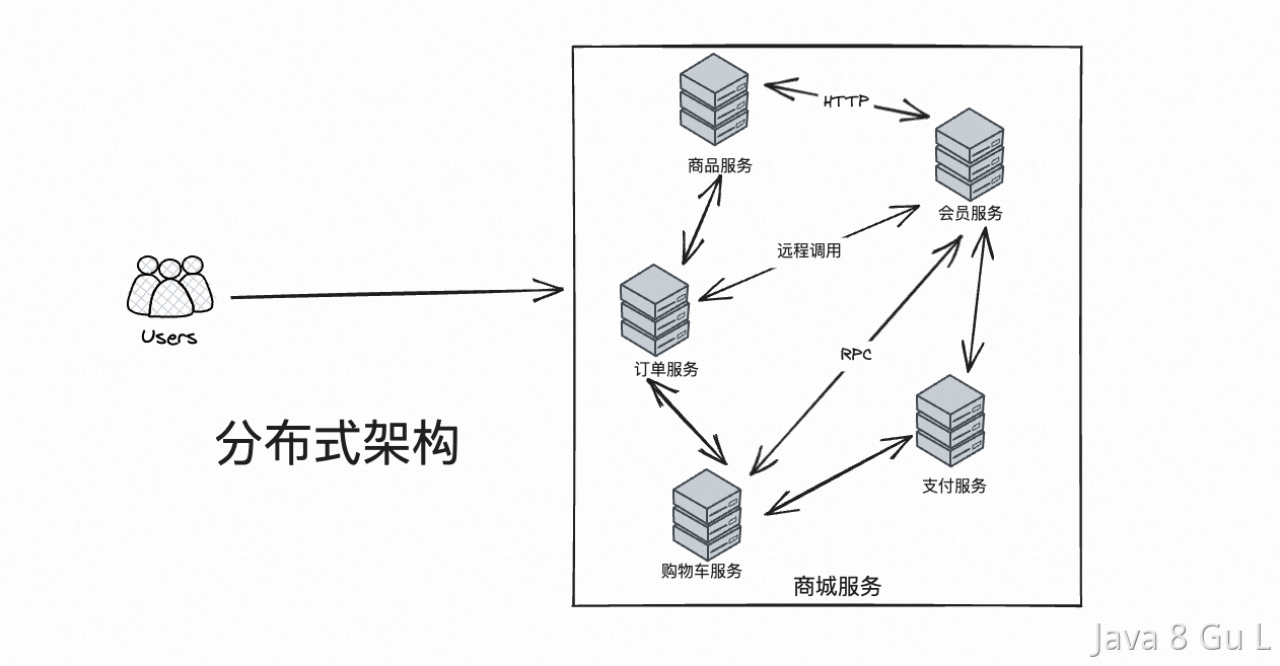
- 電腦越多,CPU、記憶體、存儲資源等也就越多,能夠處理的併發訪問量也就越大
- 但是分散式系統中也存在著網路通信延遲、數據一致性等問題
- 一致性
(Consistency)
CAP理論
組成
• 每次讀取都會收到最新的寫入數據或錯誤信息。
- 可用性
(Availability)
• 每個請求都會收到(非錯誤的)響應,但不能保證響應包含最新的寫入數據。
- 分區容忍性
(Partition Tolerance)
• 儘管網路節點之間會丟棄(或延遲)任意數量的消息,系統仍然能夠繼續運行
選擇權衡
- CA without P
• 這種情況在分散式系統中幾乎是不存在的。首先在分散式環境下,網路分區是一個自然的事實。因為分區是必然的,所以如果捨棄P,意味著要捨棄分散式系統。那也就沒有必要再討論CAP理論了。這也是為什麼在CAP證明中,我們以系統滿足P為前提論述了無法同時滿足C和A
• 比如我們熟知的關係型資料庫,如My Sql和Oracle就是保證了可用性和數據一致性,但是他並不是個分散式系統。一旦關係型資料庫要考慮主備同步、集群部署等就必須要把P也考慮進來。
• 對於一個分散式系統來說。P是一個基本要求,CAP三者中,只能在CA兩者之間做權衡,並且要想盡辦法提升P
• 無法通過降低CA來提升P。要想提升系統的分區容錯性,需要通過提升基礎設施的穩定性來保障
- CP without A
• 不要求強的可用性,即容許系統停機或者長時間無響應
• 設計成CP的系統其實也不少,其中最典型的就是很多分散式資料庫,在發生極端情況時,優先保證數據的強一致性,代價就是捨棄系統的可用性。如HBase,還有分散式系統中常用的Zookeeper也是在CAP三者之中選擇優先保證CP的。
- AP wihtout C
• 為了保證高可用,需要在用戶訪問時可以馬上得到返回,則每個節點只能用本地數據提供服務,而這樣會導致全局數據的不一致性。
• 很多網站大都是選擇的優先保證高可用犧牲了一致性,比如淘寶的購物,12306的買票,你購買的時候提示你是有票的(但是可能實際已經沒票了),你也正常的去輸入驗證碼,下單了。但是過了一會系統提示你下單失敗,餘票不足
• 其實捨棄的只是強一致性。退而求其次保證了最終一致性,也就是說,雖然下單的瞬間,關於車票的庫存可能存在數據不一致的情況,但是過了一段時間,還是要保證最終一致性的。
• 對於支付能需要準確保證數據的還是選擇的是強一致性,如支付寶
BASE理論
BASE理論是對CAP理論的延伸,核心思想是即使無法做到強一致性(Strong Consistency,CAP的一致性就是強一致性),但應用可以採用適合的方式達到最終一致性(Eventual Consitency)
BASE是指基本可用(Basically Available)、軟狀態( Soft State)、最終一致性( Eventual Consistency)
- 基本可用
• 降級
• 指分散式系統在出現故障的時候,允許損失部分可用性(降級),即保證核心可用。
• 電商大促時,為了應對訪問量激增,部分用戶可能會被引導到降級頁面,服務層也可能只提供降級服務。這就是損失部分可用性的體現。
- 軟狀態
• 中間狀態
• 指允許系統存在中間狀態,而該中間狀態不會影響系統整體可用性。分散式存儲中一般一份數據至少會有三個副本,允許不同節點間副本同步的延時就是軟狀態的體現。mysql replication的非同步複製也是一種體現。
• 其實就是中間狀態,比如當前INIT,然後處理中推進到PROCESSING,然後可以基於這個PROCESSING不斷重試,直到推進到SUCCESS
- 最終一致性
• 重試
• 指系統中的所有數據副本經過一定時間後,最終能夠達到一致的狀態。弱一致性和強一致性相反,最終一致性是弱一致性的一種特殊情況。
拜占庭將軍問題
拜占庭帝國的一支軍隊要攻打一個城市,攻打的成功需要不同將軍協同決策,但是有些將軍是不忠誠的,他們可能會發送虛假信息或者故意阻礙其他將軍的決策。問題是如何讓忠誠的將軍在不知道其他將軍是否忠誠的情況下做出正確的決策。
拜占庭將軍問題的本質是分散式系統中的協同問題,即如何使得分散式系統中的不同節點能夠在相互獨立的情況下達成共識
解決拜占庭將軍問題有許多方法,比較常見的就是通過投票演算法、共識演算法來解決,但是這些演算法其實背後都基於了一個思想,那就是超過半數。
- 基於多數表決的解決方案:假設總共有N個將軍,每個將軍發送自己的意見給其他將軍,然後將軍們根據收到的意見進行投票,如果有超過N/2個將軍投票一致,則採取投票的結果。這個方案的前提是假設叛徒的數量不超過總將軍數的一半,因為如果超過一半的將軍都是叛徒,則無法保證多數投票的結果是正確的。這種解決方案在很多演算法中都有實踐,如Raft、ZAB、Paxos等。
- 系統保證每個讀操作都將返回最近的寫操作的結果,即任何時間點,客戶端都將看到相同的數據視圖。這包括線性一致性(Linearizability)、順序一致性(Sequential Consistency)和嚴格可串列性(Strict Serializability)等子模型。強一致性模型通常犧牲了可用性來實現數據一致性
分散式系統一致性
指數據在多個副本之間是否能夠保持一致的特性
分散式系統中的一致性模型是一組管理分散式系統行為的規則。它決定了在分散式系統中如何訪問和更新數據,以及如何將這些更新提供給客戶端。面對網路延遲和局部故障等分散式計算難題,分散式系統的一致性模型對保證系統的一致性和可靠性起著關鍵作用
大分類
強一致性模型
• 線性一致性
• 是一種最強的一致性模型,它強調在分散式系統中的任何時間點,讀操作都應該返回最近的寫操作的結果。
• 比如,如果操作A在操作B之前成功完成,那麼操作B在序列化中應該看起來在操作A之後發生,即操作A應該在操作B之前完成。線性一致性強調實時性,確保操作在實際時間上的順序保持一致
• 順序一致性
• 順序一致性也是一種強一致性模型,但相對於線性一致性而言,它放寬了一些限制。在順序一致性模型中,系統維護一個全局的操作順序,以確保每個客戶端看到的操作順序都是一致的
• 與線性一致性不同,順序一致性不強調實時性,只要操作的順序是一致的,就可以接受一些延遲。
• 主要區別在於強調實時性。線性一致性要求操作在實際時間上的順序保持一致,而順序一致性只要求操作的順序是一致的,但不一定要求操作的實際時間順序
弱一致性模型
- 弱一致性模型放寬了一致性保證,它允許在不同節點之間的數據訪問之間存在一定程度的不一致性,以換取更高的性能和可用性。這包括因果一致性(Causal Consistency)、會話一致性(Session Consistency)和單調一致性(Monotonic Consistency)等子模型。弱一致性模型通常更註重可用性,允許一定程度的數據不一致性。
- 最終一致性模型是一種最大程度放寬了一致性要求的模型。它允許在系統發生分區或網路故障後,經過一段時間,系統將最終達到一致狀態。這個模型在某些情況下提供了很高的可用性,但在一段時間內可能會出現數據不一致的情況。
最終一致性模型
• 在時間上,雖然順序一致性和最終一致性都不強要求實時性,但是最終一致性的時間放的會更寬。並且最終一致性其實並不強調順序,他只需要保證最終的結果一致就行了,而順序一致性要求操作順序必須一致。
• 順序一致性還是一種強一致性,比如在Zookeeper中,其實就是通過ZAB演算法來保證的順序一致性,即各個節點之間的寫入順序要求一致。並且要半數以上的節點寫入成功才算成功。所以,順序一致性的典型應用場景就是資料庫管理系統以及分散式系統。
負載均衡
演算法分類
靜態負載均衡演算法
- 輪詢
• 順序迴圈將請求一次順序迴圈地連接每個伺服器
- 比率
• 給每個伺服器分配一個加權值為比例,根椐這個比例,把用戶的請求分配到每個伺服器。
- 優先權
• 給所有伺服器分組,給每個組定義優先權,BIG-IP 用戶的請求,分配給優先順序最高的伺服器組(在同一組內,採用輪詢或比率演算法,分配用戶的請求)
• 當最高優先順序中所有伺服器出現故障,BIG-IP 才將請求送給次優先順序的伺服器組。這種方式,實際為用戶提供一種熱備份的方式。
動態負載均衡演算法
- 最少連接數
• 傳遞新的連接給那些進行最少連接處理的伺服器
- 最快響應速度
• 傳遞連接給那些響應最快的伺服器
- 觀察模式
• 連接數目和響應時間以這兩項的最佳平衡為依據為新的請求選擇伺服器
- 預測法
• BIG-IP利用收集到的伺服器當前的性能指標,進行預測分析,選擇一臺伺服器在下一個時間片內,其性能將達到最佳的伺服器相應用戶的請求
- 動態性能分配
• BIG-IP 收集到的應用程式和應用伺服器的各項性能參數,動態調整流量分配。
- 動態伺服器補充
• 當主伺服器群中因故障導致數量減少時,動態地將備份伺服器補充至主伺服器群。
- 服務質量
• 按不同的優先順序對數據流進行分配
- 服務類型
• 按不同的服務類型(在Type of Field中標識)負載均衡對數據流進行分配
- 規則模式
• 針對不同的數據流設置導向規則,用戶可自行定製
OSI模型
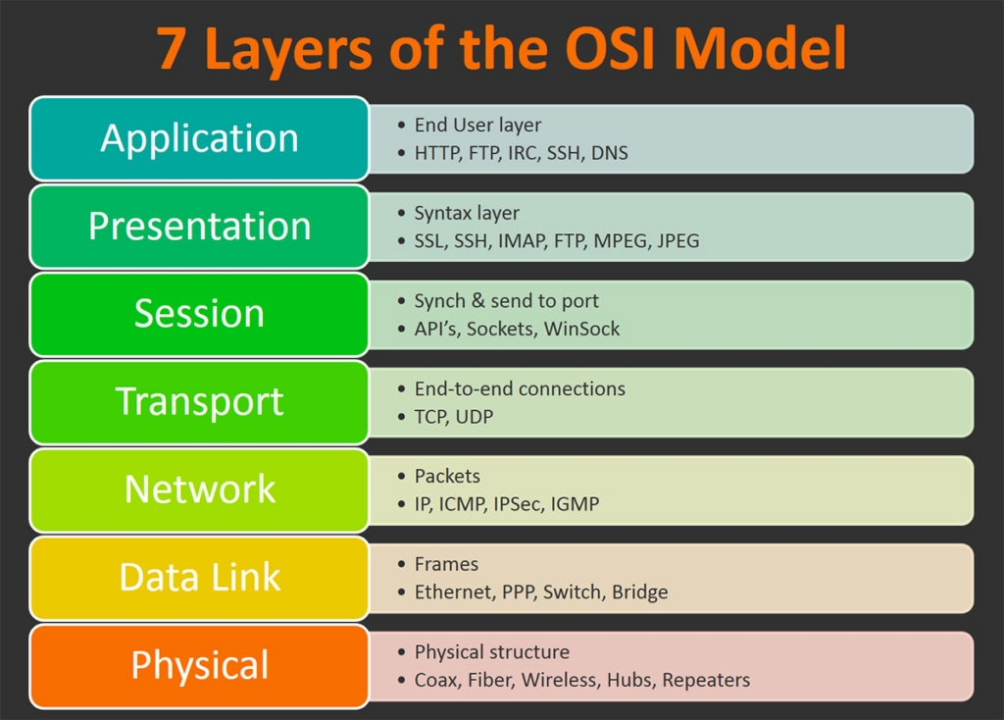
- 高層(即7、6、5、4層)定義了應用程式的功能,下麵3層(即3、2、1層)主要面向通過網路的端到端的數據流。
- telnet、HTTP、FTP、NFS、SMTP、DNS等屬於第七層應用層的概念。
TCP、UDP、SPX等屬於第四層傳輸層的概念。
IP、IPX等屬於第三層網路層的概念。
ATM、FDDI等屬於第二層數據鏈路層的概念。 - 負載均衡伺服器對外依然提供一個VIP(虛IP),集群中不同的機器採用相同IP地址,但是機器的MAC地址不一樣。當負載均衡伺服器接受到請求之後,通過改寫報文的目標MAC地址的方式將請求轉發到目標機器實現負載均衡。
- 和二層負載均衡類似,負載均衡伺服器對外依然提供一個VIP(虛IP),但是集群中不同的機器採用不同的IP地址。當負載均衡伺服器接受到請求之後,根據不同的負載均衡演算法,通過IP將請求轉發至不同的真實伺服器。
- 四層負載均衡工作在OSI模型的傳輸層,由於在傳輸層,只有TCP/UDP協議,這兩種協議中除了包含源IP、目標IP以外,還包含源埠號及目的埠號。四層負載均衡伺服器在接受到客戶端請求後,以後通過修改數據包的地址信息(IP+埠號)將流量轉發到應用伺服器。
- 七層負載均衡工作在OSI模型的應用層,應用層協議較多,常用http、radius、dns等。七層負載就可以基於這些協議來負載。這些應用層協議中會包含很多有意義的內容。比如同一個Web伺服器的負載均衡,除了根據IP加埠進行負載外,還可根據七層的URL、瀏覽器類別、語言來決定是否要進行負載均衡。
- LVS(Linux Virtual Server),也就是Linux虛擬伺服器, 是一個由章文嵩博士發起的自由軟體項目。使用LVS技術要達到的目標是:通過LVS提供的負載均衡技術和Linux操作系統實現一個高性能、高可用的伺服器群集,它具有良好可靠性、可擴展性和可操作性。從而以低廉的成本實現最優的服務性能。
負載均衡分類
二層負載均衡
三層負載均衡
四層負載均衡 (常用)
七層負載均衡 (常用)
負載均衡工具
LVS
• 主要用來做四層負載均衡
Nginx
- 是一個網頁伺服器,它能反向代理HTTP, HTTPS, SMTP, POP3, IMAP的協議鏈接,以及一個負載均衡器和一個HTTP緩存。
• 主要用來做七層負載均衡
HAProxy
- 是一個使用C語言編寫的自由及開放源代碼軟體,其提供高可用性、負載均衡,以及基於TCP和HTTP的應用程式代理。
• 主要用來做七層負載均衡
業務冪等
一鎖、二判、三更新
一鎖
- 第一步,先加鎖。可以加分散式鎖、或者悲觀鎖都可以。但是一定要是一個互斥鎖
- 第二步,進行冪等性判斷。可以基於狀態機、流水錶、唯一性索引等等進行重覆操作的判斷
- 第三步,進行數據的更新,將數據進行持久化。
- 依賴悲觀鎖以及資料庫表記錄來實現
二判
三更新
分散式鎖
實現方式
通過資料庫
• 基於資料庫表
• 創建一張鎖表,當我們要鎖住某個方法或資源時,我們就在該表中增加一條記錄,想要釋放鎖的時候就刪除這條記錄
• CREATE TABLE `methodLock` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主鍵',
`method_name` varchar(64) NOT NULL DEFAULT '' COMMENT '鎖定的方法名',
`desc` varchar(1024) NOT NULL DEFAULT '備註信息',
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '保存數據時間,自動生成',
PRIMARY KEY (`id`),
UNIQUE KEY `uidx_method_name` (`method_name `) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='鎖定中的方法';
• 要鎖住某個方法時,執行以下SQL:
insert into methodLock(method_name,desc) values (‘method_name’,‘desc’)
要釋放鎖的話,需要執行以下Sql:
delete from methodLock where method_name ='method_name'
• 問題
• 這把鎖強依賴資料庫的可用性,資料庫是一個單點,一旦資料庫掛掉,會導致業務系統不可用。
• 這把鎖沒有失效時間,一旦解鎖操作失敗,就會導致鎖記錄一直在資料庫中,其他線程無法再獲得到鎖。
• 這把鎖只能是非阻塞的,因為數據的insert操作,一旦插入失敗就會直接報錯。沒有獲得鎖的線程並不會進入排隊隊列,要想再次獲得鎖就要再次觸發獲得鎖操作。
• 這把鎖是非重入的,同一個線程在沒有釋放鎖之前無法再次獲得該鎖。因為數據中數據已經存在了。
• 解決
• 資料庫是單點?搞兩個資料庫,數據之前雙向同步。一旦掛掉快速切換到備庫上。
• 沒有失效時間?只要做一個定時任務,每隔一定時間把資料庫中的超時數據清理一遍。
• 非阻塞的?搞一個while迴圈,直到insert成功再返回成功
• 非重入的?在資料庫表中加個欄位,記錄當前獲得鎖的機器的主機信息和線程信息,那麼下次再獲取鎖的時候先查詢資料庫,如果當前機器的主機信息和線程信息在資料庫可以查到的話,直接把鎖分配給他就可以了。
• 基於資料庫排他鎖
• 加鎖
• public boolean lock(){
connection.setAutoCommit(false)
while(true){
try{
result = select * from methodLock where method_name=xxx for update;
if(result==null){
return true;
}
}catch(Exception e){
}
}
return false;
}
• 解鎖
• connection.commit();
• 問題
• 雖然我們對method_name 使用了唯一索引,並且顯示使用for update來使用行級鎖。但是,MySql會對查詢進行優化,即便在條件中使用了索引欄位,但是否使用索引來檢索數據是由 MySQL 通過判斷不同執行計劃的代價來決定的,如果 MySQL 認為全表掃效率更高,比如對一些很小的表,它就不會使用索引,這種情況下 InnoDB 將使用表鎖,而不是行鎖。如果發生這種情況就悲劇了
• 使用排他鎖來進行分散式鎖的lock,那麼一個排他鎖長時間不提交,就會占用資料庫連接。一旦類似的連接變得多了,就可能把資料庫連接池撐爆
• 評價
• 優點
• 不依賴三方組件且容易理解直觀
• 缺點
• 操作資料庫需要一定的開銷,性能問題需要考慮
• 資料庫的行級鎖並不一定靠譜,尤其是當我們的鎖表並不大的時候
• 問題解決複雜
Redis
- 使用setnx、redission以及redlock實現
- 依賴他提供的臨時有序節點來實現
Zookeeper
• 大致思想即為:每個客戶端對某個方法加鎖時,在zookeeper上的與該方法對應的指定節點的目錄下,生成一個唯一的瞬時有序節點。 判斷是否獲取鎖的方式很簡單,只需要判斷有序節點中序號最小的一個。 當釋放鎖的時候,只需將這個瞬時節點刪除即可。同時,其可以避免服務宕機導致的鎖無法釋放,而產生的死鎖問題。
鎖的要求
同一個方法在同一時間只能被一臺機器上的一個線程執行
是一把可重入鎖(避免死鎖)
一把阻塞鎖(可選)
有高可用的獲取鎖和釋放鎖功能
獲取鎖和釋放鎖的性能要好
分散式session
客戶端存儲
用戶登錄後,將Session信息保存在客戶端,用戶在每次請求的時候,通過客戶端的cookie把session信息帶過來。這個方案因為要把session暴露給客戶端,存在安全風險
基於分散式存儲(最常用)
將Session數據保存在分散式存儲系統中,如分散式文件系統、分散式資料庫等。不同伺服器可以共用同一個分散式存儲,通過Session ID查找對應的Session數據。唯一的缺點就是需要依賴第三方存儲,如Redis、資料庫等。
粘性Session
把一個用戶固定的路由到指定的機器上,這樣只需要這台伺服器中保存了session即可,不需要做分散式存儲。但是這個存在的問題就是可能存在單點故障的問題
Session複製
當用戶的Session在某個伺服器上產生之後,通過複製的機制,將他同步到其他的伺服器中。這個方案的缺點是有可能有延遲。
- tomcat支持session複製
- 各版本介紹
分散式ID
特點
全局唯一、高性能&高可用、遞增
方案
UUID
• V1. 基於時間戳的UUID
• 基於時間的UUID通過計算當前時間戳、隨機數和機器MAC地址得到。由於在演算法中使用了MAC地址,這個版本的UUID可以保證在全球範圍的唯一性。
• 使用MAC地址會帶來安全性問題,如果應用只是在區域網中使用,也可以使用退化的演算法,以IP地址來代替MAC地址。
• V2. DCE(Distributed Computing Environment)安全的UUID
• 和基於時間的UUID演算法相同,但會把時間戳的前4位置換為POSIX的UID或GID,這個版本的UUID在實際中較少用到。
• V3. 基於名稱空間的UUID(MD5)
• 基於名稱的UUID通過計算名稱和名稱空間的MD5散列值得到。
• 這個版本的UUID保證了:相同名稱空間中不同名稱生成的UUID的唯一性;不同名稱空間中的UUID的唯一性;相同名稱空間中相同名稱的UUID重覆生成得到的結果是相同的。
• V4. 基於隨機數的UUID
• 根據隨機數,或者偽隨機數生成UUID,並不適合數據量特別大的場景
• V5. 基於名稱空間的UUID(SHA1)
• 和版本3的UUID演算法類似,只是散列值計算使用SHA1(Secure Hash Algorithm 1)演算法。
• 總結
• Version 1和Version 2 這兩個版本的UUID,主要基於時間和MAC地址,所以比較適合應用於分散式計算環境下,具有高度唯一性。
• Version 3和 Version 5 這兩種UUID都是基於名稱空間的,所以在一定範圍內是唯一的,而且如果有需要生成重覆UUID的場景的話,這兩種是可以實現的。
• Version 4 這種是最簡單的,只是基於隨機數生成的,但是也是最不靠譜的。適合數據量不是特別大的場景下
- 優缺點
• 優點
• 性能比較高,不依賴網路,本地就可以生成,使用起來也比較簡單。
• 缺點
• 長度過長、沒有任何含義、無序
資料庫自增ID
- 優點
• 簡單且不依賴三方組件
- 缺點
• 單點故障問題
• 高併發訪問資料庫會帶來阻塞問題
號段模式
- 每次去資料庫中取ID的時候取出來一批,並放在緩存中,然後下一次生成新ID的時候就從緩存中取。這一批用完了再去資料庫中拿新的。
- 為了防止多個實例之間發生衝突,需要採用號段的方式,即給每個客戶端發放的時候按號段分開,如客戶端A取的號段是1-1000,客戶端B取的是1001-2000
- 缺點
• 沒辦法保證全局順序遞增
• 單點故障問題
基於Redis 實現
- 缺點
• redis持久化方式決定存在數據丟失的情況
雪花演算法
- 基於時間戳+數據中心標識+機器標識+序列號,就保證了在不同進程中主鍵的不重覆,在相同進程中主鍵的有序性。
- 缺點限制
• 每個節點的機器ID和數據中心ID都是硬編碼在代碼中的,而且這些ID是全局唯一的。當某個節點出現故障或者需要擴容時,就需要更改其對應的機器ID或數據中心ID,但是這個過程比較麻煩
還有就是,如果某個節點的機器ID或數據中心ID被設置成了已經被分配的ID,那麼就會出現重覆的ID,這樣會導致系統的錯誤和異常。
• Snowflake演算法中,需要使用zookeeper來協調各個節點的ID生成(非必要),但是ZK的部署其實是有挺大的成本的,並且zookeeper本身也可能成為系統的瓶頸。
• 依賴於系統時間的一致性,如果系統時間被回撥,或者不一致,可能會造成 ID 重覆
• 解決
• 美團 Leaf 引入了 Zookeeper 來解決時鐘回撥問題,其大致思路為:每個 Leaf 運行時定時向 zk 上報時間戳。每次 Leaf 服務啟動時,先校驗本機時間與上次發 ID 的時間,再校驗與 zk 上所有節點的平均時間戳。如果任何一個階段有異常,那麼就啟動失敗報警。
• 百度的UidGenerator中有兩種UidGenerator,其中DefautlUidGenerator使用了System.currentTimeMillis()獲取時間與上一次時間比較,當發生時鐘回撥時,拋出異常。而CachedUidGenerator使用是放棄了對機器的時間戳的強依賴,而是改用AtomicLong的incrementAndGet()來獲取下一次時間,從而脫離了對伺服器時間的依賴。
第三方ID生成工具
- 百度的UidGenerator
- 美團的Leaf
• Leaf是美團的分散式ID框架,他有2種生成ID的模式,分別是Snowflake和Segment
• Segment(號段)模式
• 每次去資料庫中取ID的時候取出來一批,並放在緩存中,然後下一次生成新ID的時候就從緩存中取
• 缺點
• 如果多個緩存中剛好用完了號段,同時去請求資料庫獲取新的號段時可能會導致併發爭搶影響性能,另外,DB如果宕機時間過長,緩存中號段耗盡也會有可用性問題。
• 解決
• Leaf還引入了雙buff,當號段消費到某個閾值時就非同步的把下一個號段載入到記憶體中,而不需要定好耗盡才去更新,這樣可以避免取號段的時候導致沒有號碼分配影響可用性及性能。
• Snowflake模式
• 相對Snowflake優化點
• 數據中心ID和機器ID的配置方式
• Snowflake需要在代碼中硬編碼數據中心ID和機器ID,而Leaf通過配置文件的方式進行配置,可以動態配置數據中心ID和機器ID,降低了配置的難度
• 引入區間概念
• 每次從zookeeper獲取一段ID的數量(比如1萬個),之後在這個區間內產生ID,避免了每次獲取ID都要去zookeeper中獲取,減輕了對zookeeper的壓力,並且也可以減少對ZK的依賴,並且也能提升生成ID的效率。
• 自適應調整
• Leaf支持自適應調整ID生成器的參數,比如每個區間的ID數量、ID生成器的工作線程數量等,可以根據實際情況進行動態調整,提高了系統的性能和靈活性。
• 支持多種語言
• Leaf不僅提供了Java版本的ID生成器,還提供了Python和Go語言的版本,可以滿足不同語言的開發需求。
• 時鐘回撥解決
• 每個 Leaf 運行時定時向 zk 上報時間戳。每次 Leaf 服務啟動時,先校驗本機時間與上次發 ID 的時間,再校驗與 zk 上所有節點的平均時間戳。如果任何一個階段有異常,那麼就啟動失敗報警。
• 生成過程
• 1、Leaf生成器啟動時,會從配置文件中讀取配置信息,包括數據中心ID、機器ID等。
• 2、Leaf生成器會向zookeeper註冊自己的信息,包括IP地址、埠號等。
• 3、應用程式需要生成一個ID時,會向Leaf生成器發送一個請求。
• 4、Leaf生成器會從zookeeper中讀取可用的區間信息,並分配一批ID。
• 5、Leaf生成器將分配的ID返回給應用程式。
• 6、應用程式可以使用返回的ID生成具體的業務ID。
• 7、當分配的ID用完後,Leaf生成器會再次向zookeeper請求新的區間。
- 滴滴的Tinyid


