
作者,祝青平,華為雲資料庫內核高級工程師。擅長資料庫優化器內核研發,9年資料庫內核研發經驗,參與多個TP以及AP資料庫的研發工作。 近日,華為雲資料庫社區下麵有這樣一條用戶提問留言:請問,如何通過MySQL提升DISTINCT,尤其是多表連接下DISTINCT的查詢效率? 在回答這個問題之前,我們先 ...
作者,祝青平,華為雲資料庫內核高級工程師。擅長資料庫優化器內核研發,9年資料庫內核研發經驗,參與多個TP以及AP資料庫的研發工作。
近日,華為雲資料庫社區下麵有這樣一條用戶提問留言:請問,如何通過MySQL提升DISTINCT,尤其是多表連接下DISTINCT的查詢效率?
在回答這個問題之前,我們先瞭解一下DISTINCT。
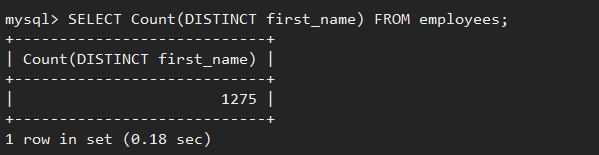
在SQL語句中,DISTINCT關鍵詞用於返回唯一不同的值,使用場景多,應用頻繁。它可以用於做單列數據去重,例如,對公司雇員按照”first_name”去重後,得到1275條記錄。
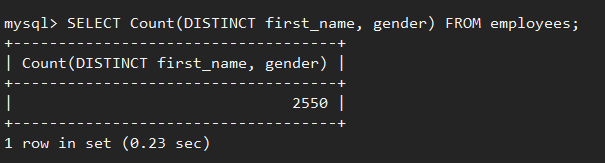
也可以做多列去重,即只有所有指定列的信息都相同時,才會被認為是重覆的信息,例如,對公司雇員按照”first_name”和”gender”兩列去重後得到2550條記錄。
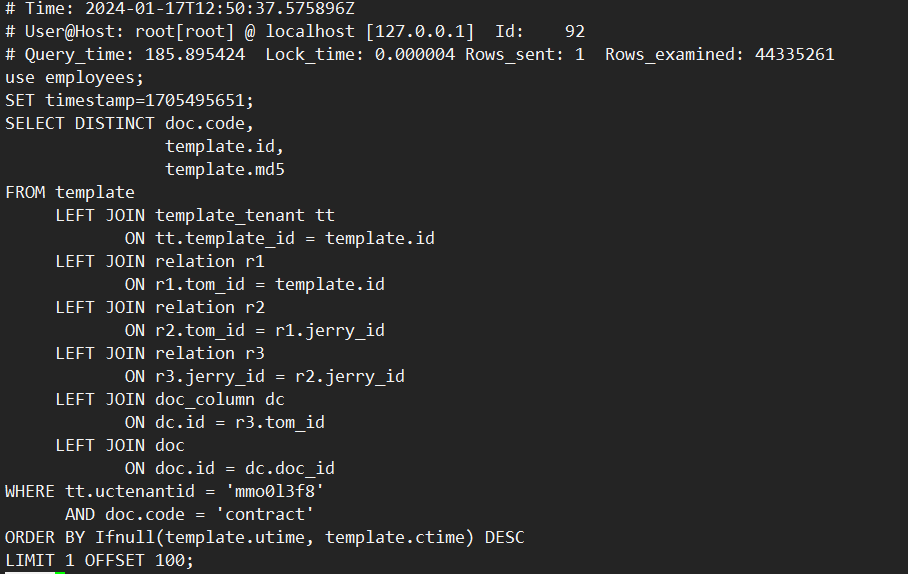
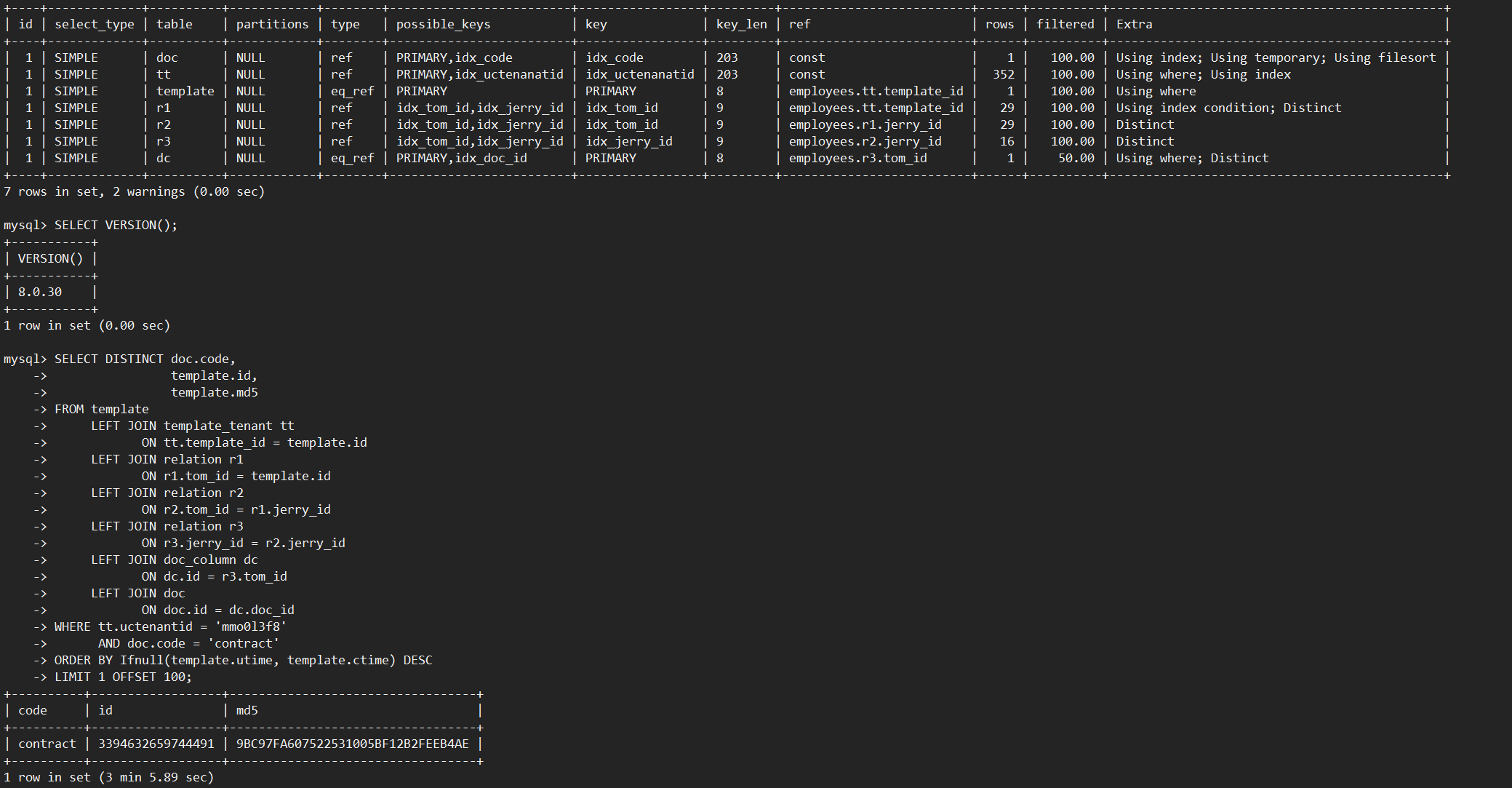
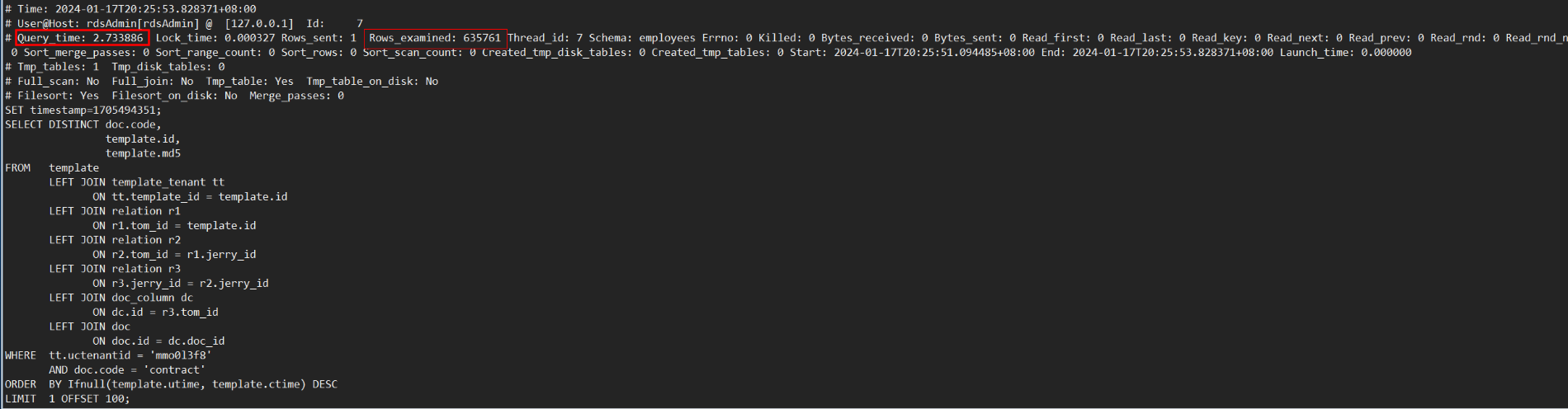
對於“多表連接+DISTINCT”場景,MySQL 8.0需要掃描表連接後的結果。當表連接數量多或基表數據量大時,掃描的數據量也會很大,會導致執行效率很低。如下示例,對7個表連接後的結果做DISTINCT,使用MySQL 8.0.30社區版本,執行耗時186秒,通過查看慢日誌信息,發現掃描了約4400萬行數據。
為了提升DISTINCT,尤其多表連接下DISTINCT的查詢效率,GaussDB(for MySQL)在執行優化器中加入了剪枝功能,可以去除不必要的掃描分支,節省查詢耗時。
GaussDB(for MySQL)剪枝方案
以下麵的SQL執行為例,表t1有4行數據1,2,5,6。執行如下多表連接+DISTINCT:
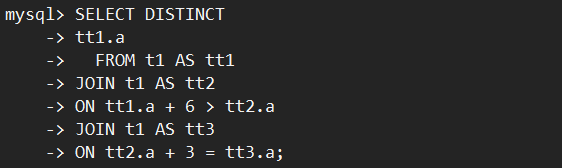
表連接執行邏輯如下:

上述例子中,在MySQL 8.0.30社區版本執行器需要掃描60行數據才能獲得結果集。找到滿足條件的唯一結果{i=1,j=2,k=5}後,不會停止本輪掃描,而是繼續掃描{i=1,j=5,k=1}及後續無用的數據,導致執行時間長。詳細的執行流程參見下圖:
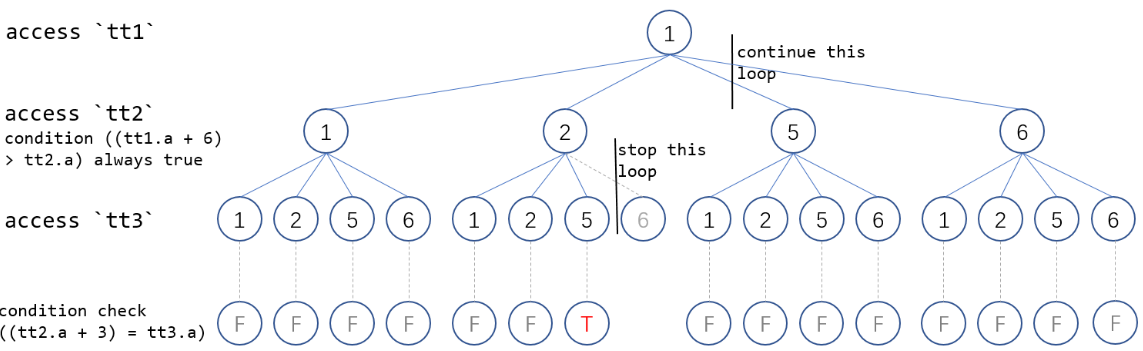
針對如上的多表連接+DISTINCT執行效率慢的問題,GaussDB(for MySQL)在火山模型的執行器上實現了提前減枝優化,當找到滿足的條件的DISTINCT值之後,通過全局變數判斷是否可以提前結束本輪迭代,並層層退出,大幅減少了掃描工作量。
以上述SQL為例,在掃描{1,1,1},{1,1,2},{1,1,5},{1,1,8},{1,2,1},{1,2,2},{1,2,5} 7組數據後,找到滿足DISTINCT 條件值 tt1.a "1",立即結束本輪迭代,並停止上一層迭代。該例子中只需要掃描28行數據就可獲得最終結果集,相比MySQL 8.0社區版本掃描60行,GaussDB(for MySQL)性能顯著提升。
GaussDB(for MySQL)剪枝特性使用方法
打開特性開關:SET rds_nlj_distinct_optimize=ON;
通過”EXPLAIN FORMAT=TREE”查看特性是否生效,執行計劃中出現” join with distinct optimization”關鍵字說明特性生效,查詢過程中可進行減枝優化,提升多表JOIN+DISTINCT執行效率。
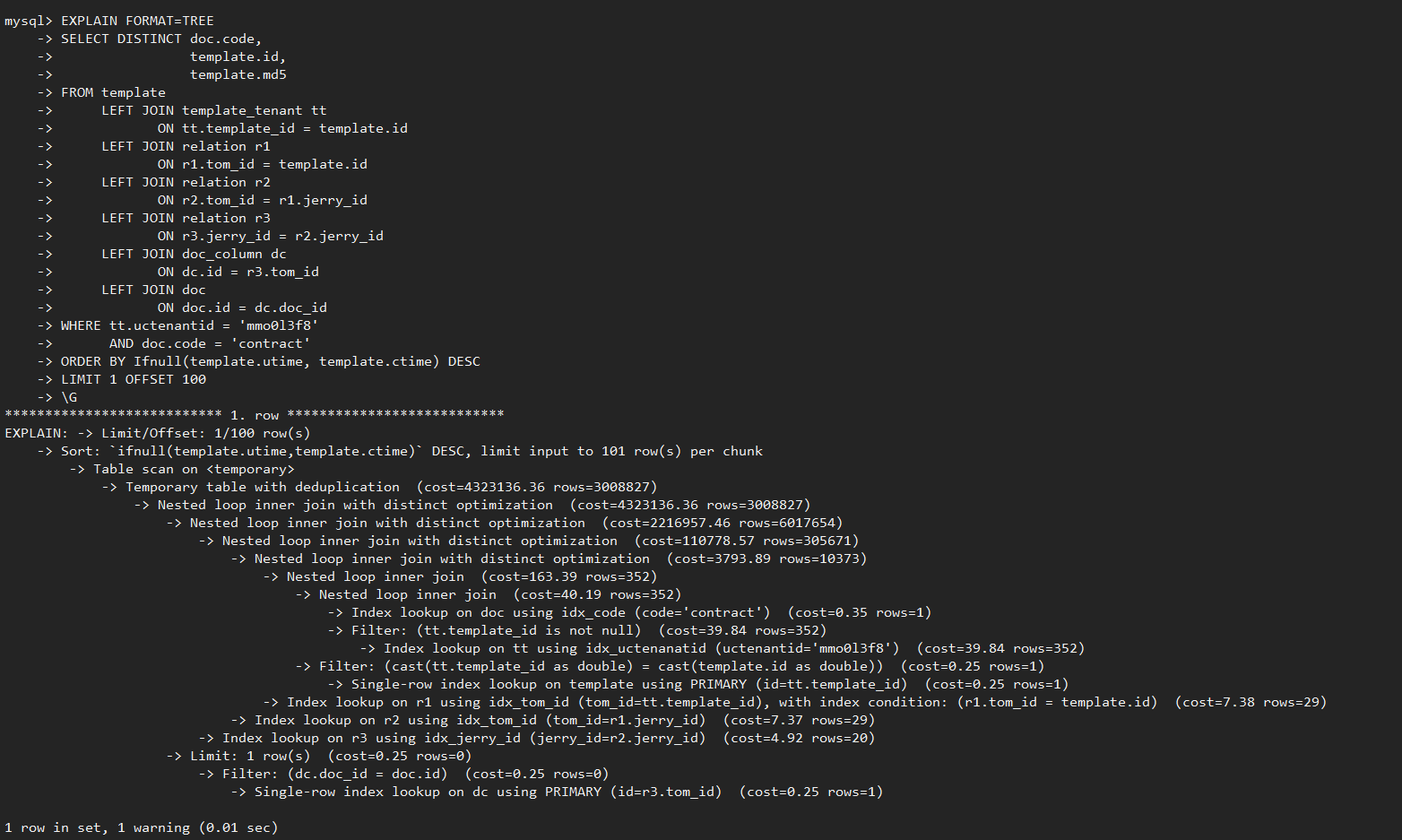
GaussDB(for MySQL)剪枝典型場景測試對比
前面提到的測試樣例中,GaussDB(for MySQL)執行耗時2.7秒完成,只需要掃描數據量約61萬行;相比MySQL 8.0 社區版本執行耗時約186秒,掃描數據量4400萬,執行耗時和掃描數據量減少近70倍,實現了執行效率飛躍式提升。如下圖所示:
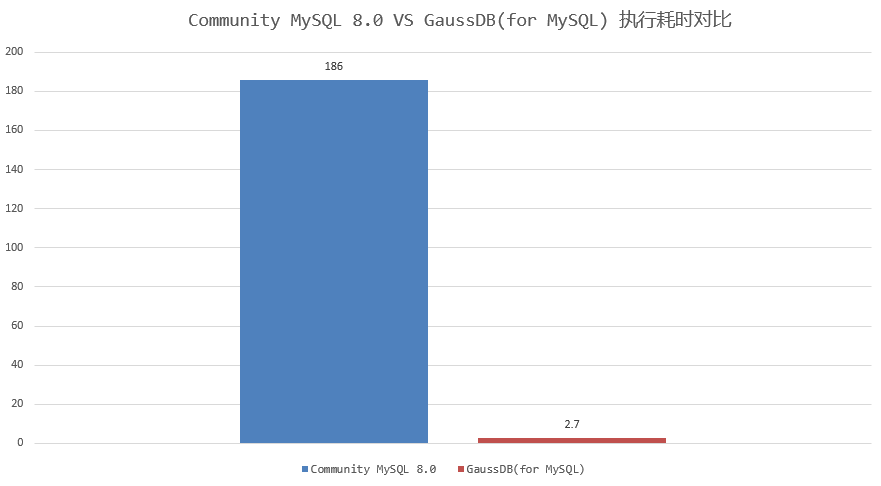
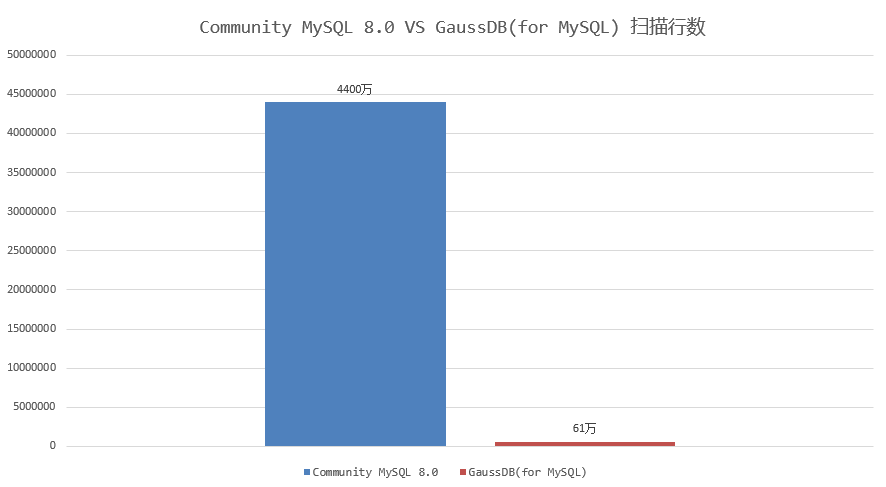
因此,針對“多表連接+DISTINCT”的場景,GaussDB(for MySQL)在執行過程中動態剪枝,裁剪掉大量無用數據,減少執行過程中掃描數據量,是提升查詢效率的秘密武器。
總結:
以上通過對GaussDB(for MySQL)剪枝方案、剪枝特性使用方法、典型場景測試對比結果的詳細呈現,剖析了“多表連接+DISTINCT”場景中,GaussDB(for MySQL)大幅提升查詢效率的原因。如果對華為雲GaussDB(for MySQL)更多功能感興趣的話,可以查看官方產品文檔,瞭解更多:https://support.huaweicloud.com/gaussdbformysql/index.html


