
各位朋友聽我一句勸,寫代碼提供方法給別人調用時,不管是內部系統調用,還是外部系統調用,還是被動觸發調用(比如MQ消費、回調執行等),一定要加上必要的條件校驗。千萬別信某些同事說的這個條件肯定會傳、肯定有值、肯定不為空等等。這不,臨過年了我就被坑了一波,弄了個生產事故,年終獎基本是涼了半截。 為了保障 ...
各位朋友聽我一句勸,寫代碼提供方法給別人調用時,不管是內部系統調用,還是外部系統調用,還是被動觸發調用(比如MQ消費、回調執行等),一定要加上必要的條件校驗。千萬別信某些同事說的這個條件肯定會傳、肯定有值、肯定不為空等等。這不,臨過年了我就被坑了一波,弄了個生產事故,年終獎基本是涼了半截。
為了保障系統的高可用和穩定,我發誓以後只認代碼不認人。文末總結了幾個小教訓,希望對你有幫助。
一、事發經過
我的業務場景是:業務A有改動時,發送MQ,然後應用自身接受到MQ後,再組合一些數據寫入到Elasticsearch。以下是事發經過:
-
收到一個
業務A的異常告警,當時的告警如下: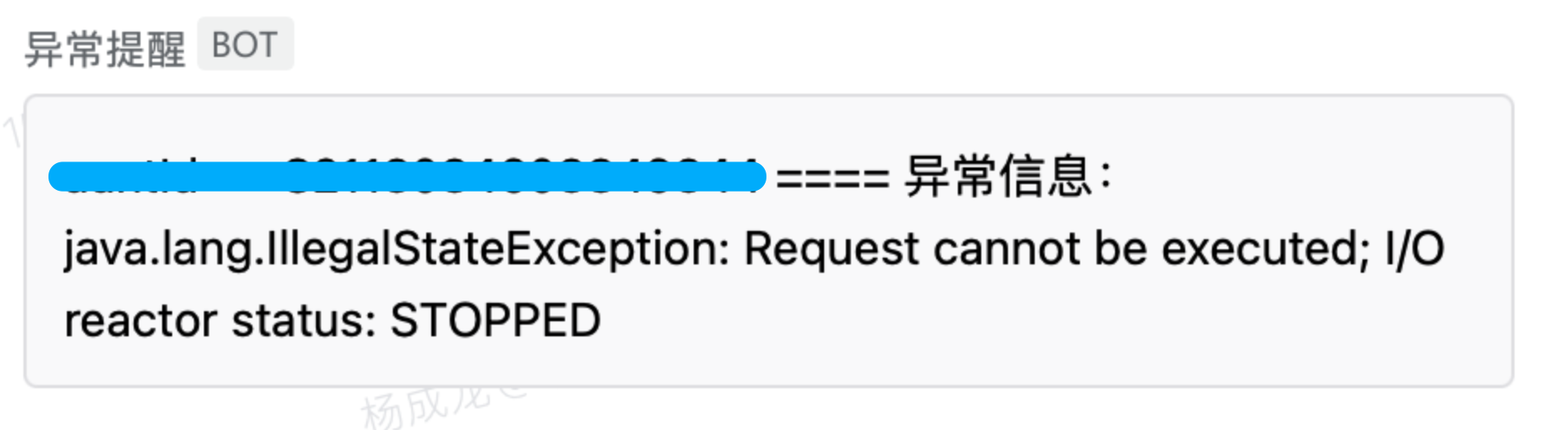
-
咋一看覺得有點奇怪,怎麼會是Redis異常呢?然後自己連了下Redis沒有問題,又看了下Redis集群,一切正常。所以就放過了,以為是偶然出現的網路問題。
-
然後技術問題群里 客服 反饋有部分用戶使用異常,我警覺性的感覺到是系統出問題了。趕緊打開了系統,確實有偶發性的問題。
-
於是我習慣性的看了幾個核心部件:
- 網關情況、核心業務Pod的負載情況、用戶中心Pod的負載情況。
- Mysql的情況:記憶體、CPU、慢SQL、死鎖、連接數等。
-
果然發現了慢SQL和元數據鎖時間過長的情況。找到了一張大表的全表查詢,數據太大,執行太慢,從而導致
元數據鎖持續時間太長,最終資料庫連接數快被耗盡。
SELECT xxx,xxx,xxx,xxx FROM 一張大表
- 立馬Kill掉幾個慢會話之後,發現系統仍然沒有完全恢復,為啥呢?現在資料庫已經正常了,怎麼還沒完全恢復呢?又繼續看了應用監控,發現用戶中心的10個Pod里有2個Pod異常了,CPU和記憶體都爆了。難怪使用時出現偶發性的異常呢。於是趕緊重啟Pod,先把應用恢復。
- 問題找到了,接下來就繼續排查為什麼用戶中心的Pod掛掉了。從以下幾個懷疑點開始分析:
- 同步數據到Elasticsearch的代碼是不是有問題,怎麼會出現連不上Redis的情況呢?
- 會不會是異常過多,導致發送異常告警消息的線程池隊列滿了,然後就OOM?
- 哪裡會對那張
業務A的大表做不帶條件的全表查詢呢?
- 繼續排查
懷疑點a,剛開始以為:是拿不到Redis鏈接,導致異常進到了線程池隊列,然後隊列撐爆,導致OOM了。按照這個設想,修改了代碼,升級,繼續觀察,依舊出現同樣的慢SQL 和 用戶中心被乾爆的情況。因為沒有異常了,所以懷疑點b也可以被排除了。 - 此時基本可以肯定是
懷疑點c了,是哪裡調用了業務A的大表的全表查詢,然後導致用戶中心的記憶體過大,JVM來不及回收,然後直接乾爆了CPU。同時也是因為全表數據太大,導致查詢時的元數據鎖時間過長造成了連接不能夠及時釋放,最終幾乎被耗盡。 - 於是修改了查詢
業務A的大表必要校驗條件,重新部署上線觀察。最終定位出了問題。
二、問題的原因
因為在變更業務B表時,需要發送MQ消息( 同步業務A表的數據到ES),接受到MQ消息後,查詢業務A表相關連的數據,然後同步數據到Elasticsearch。
但是變更業務B表時,沒有傳業務A表需要的必要條件,同時我也沒有校驗必要條件,從而導致了對業務A的大表的全表掃描。因為:
某些同事說,“這個條件肯定會傳、肯定有值、肯定不為空...”,結果我真信了他!!!
由於業務B表當時變更頻繁,發出和消費的MQ消息較多,觸發了更多的業務A的大表全表掃描,進而導致了更多的Mysql元數據鎖時間過長,最終連接數消耗過多。
同時每次都是把業務A的大表查詢的結果返回到用戶中心的記憶體中,從而觸發了JVM垃圾回收,但是又回收不了,最終記憶體和CPU都被乾爆了。
至於Redis拿不到連接的異常也只是個煙霧彈,因為發送和消費的MQ事件太多,瞬時間有少部分線程確實拿不到Redis連接。
最終我在消費MQ事件處的代碼里增加了條件校驗,同時也在查詢業務A表處也增加了的必要條件校驗,重新部署上線,問題解決。
三、總結教訓
經過此事,我也總結了一些教訓,與君共勉:
- 時刻警惕線上問題,一旦出現問題,千萬不能放過,趕緊排查。不要再去懷疑網路抖動問題,大部分的問題,都跟網路無關。
- 業務大表自身要做好保護意識,查詢處一定要增加必須條件校驗。
- 消費MQ消息時,一定要做必要條件校驗,不要相信任何信息來源。
- 千萬別信某些同事說,“這個條件肯定會傳、肯定有值、肯定不為空”等等。為了保障系統的高可用和穩定,咱們只認代碼不認人。
- 一般出現問題時的排查順序:
- 資料庫的CPU、死鎖、慢SQL。
- 應用的網關和核心部件的CPU、記憶體、日誌。
- 業務的可觀測性和告警必不可少,而且必須要全面,這樣才能更快的發現問題和解決問題。
======>>>>>> 關於我 <<<<<<======
本篇完結!歡迎點贊 關註 收藏!!!
原文鏈接:https://mp.weixin.qq.com/s/TvIpTZq0XO8v9ccYSsM37Q


