文件系統結構 unix的文件系統相關知識 unix將可用的磁碟空間劃分為兩種主要類型的區域:inode區域和數據區域。 unix為每個文件分配一個inode,其中保存文件的關鍵元數據,如文件的stat屬性和指向文件數據塊的指針。 數據區域中的空間會被分成大小相同的數據塊(就像記憶體管理中的分頁)。數據 ...
文件系統結構
unix的文件系統相關知識
- unix將可用的磁碟空間劃分為兩種主要類型的區域:inode區域和數據區域。
- unix為每個文件分配一個inode,其中保存文件的關鍵元數據,如文件的stat屬性和指向文件數據塊的指針。
- 數據區域中的空間會被分成大小相同的數據塊(就像記憶體管理中的分頁)。數據塊中存儲文件數據和目錄元數據。
- 目錄條目包含文件名和指向inode的指針
jos的文件系統
jos對文件系統進行了簡化——不使用inode。文件的所有元數據存儲在目錄條目中。
jos中的數據區域也會被劃分為“塊”
磁碟上的數據結構
磁碟不可能以位元組為單位進行讀寫,而是以扇區為單位進行讀寫。jos 中扇區為512位元組。
硬體層面,磁碟驅動以扇區為單位進行數據讀寫。
軟體層面,操作系統以“塊”為單位進行數據分配。
jos 中塊的大小為4096位元組。
超級塊 superblocks
如上文所述,jos 的數據區域被劃分為塊。
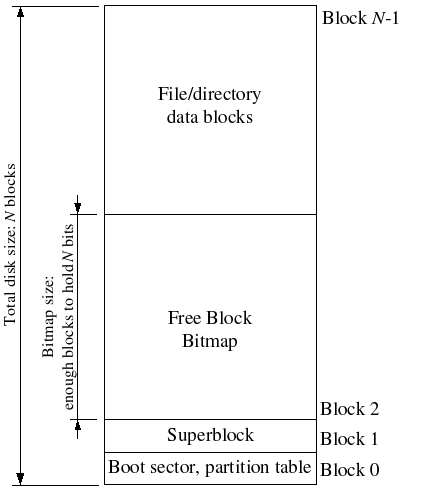
jos 還會有一個超級塊,位於磁碟的第1個塊(第0個塊中存放 引導載入器和分區表),由 inc/fs.h 中的 struct super 定義。內容如下:
struct Super {
uint32_t s_magic; // Magic number: FS_MAGIC
uint32_t s_nblocks; // Total number of blocks on disk
struct File s_root; // Root directory node
};
其中包含磁碟中存放的塊的總量和文件系統的根目錄。
超級塊可能一個塊存不下,所以會占據多個塊。
文件元數據 File Meta data
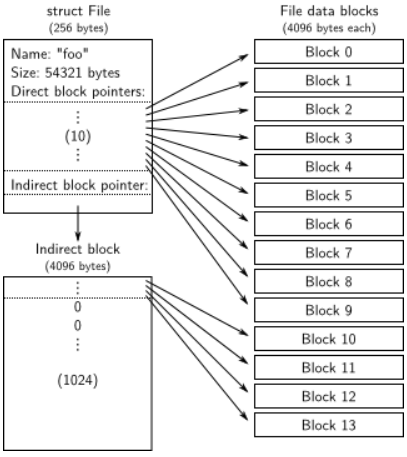
文件元數據定義在 inc/fs.h 中的 struct File , 內容如下:
struct File {
char f_name[MAXNAMELEN]; // filename
off_t f_size; // file size in bytes
uint32_t f_type; // file type
// Block pointers.
// A block is allocated iff its value is != 0.
uint32_t f_direct[NDIRECT]; // direct blocks
uint32_t f_indirect; // indirect block
// Pad out to 256 bytes; must do arithmetic in case we're compiling
// fsformat on a 64-bit machine.
uint8_t f_pad[256 - MAXNAMELEN - 8 - 4*NDIRECT - 4];
} __attribute__((packed)); // required only on some 64-bit machines
其中包含文件名、大小、類型、數據塊指針,以及pad(該結構保持256位元組大小)。
一個 File struct 對應的數據塊分為兩種:直接塊、間接塊。
- 直接塊有10個,可以存儲40kb的文件,存儲在 File struct 的數據塊指針數組 f_direct 中。
- 間接塊最多可以有1024個,如果直接塊不夠用, File struct 會被分配一個數據塊(地址存儲在 f_indirect ),裡面全都用於保存數據塊指針。(一個數據塊大小為4096位元組,一個數據塊指針占據4位元組,故間接塊可以有4096/4=1024個)
因此 jos 的文件最多可以 1034個塊, 可以存儲 $1034 \times 4096kb$ 的數據。
File的結構體的情況可以用下麵的圖片來理解:
目錄文件和普通文件
jos 的 File struct 既可以用來表示普通文件,也可以代表目錄文件,由 File struct 的 f_type 欄位來區分。
文件系統管理普通文件和目錄文件的方式完全相同,具體來說,文件系統不解析普通文件內的數據,但解析目錄文件內的數據,因為其中是該目錄下的文件的數據。
超級塊中包含一個 File struct , 其中包含了文件系統根目錄的元數據。
文件系統
磁碟訪問
在之前的 lab 中,我們通過彙編的 in 和 out 指令,向磁碟設備發送讀寫信號。但是這樣果然還是好麻煩, jos 將 IDE 磁碟驅動程式作為用戶級進程來實現。(傳統的策略是將磁碟驅動加入至內核,然後以系統調用的形式供進程調用)。
為了能夠讓用戶級進程在不使用磁碟中斷的前提下,擁有執行特殊設備I/O指令的許可權,需要使用 EFLAG 寄存器中的 IOPL 位。
因此,操作系統在創建我們的 用戶級文件系統 進程時,應該對其 env struct 中的 eflag 成員置位。因此,我們需要對 lab3 編寫的 env_create 進行修改。由於我們只允許 用戶及文件系統進程 進行磁碟IO,所以需要將其他進程和 用戶級文件系統進程 進行區分, jos 的方案是專為 用戶及文件系統進程 設立一個 ENV_TYPE_FS 。具體任務見練習1.
塊緩存(練習2@fs/bc.c)
在之前的 lab 中,我們訪問磁碟是通過分區號來訪問的。但是這樣果然好麻煩,要是能像記憶體一樣用線性地址訪問就好了。
塊緩存的編址
為了實現上面的目標, jos 將 用戶級文件系統進程的虛擬地址空間中 0x1000_0000 (DISKMAP) 到 0xD000_0000 (DISKMAP+DISKMAX) 部分用於和磁碟的存儲空間進行映射。
具體來說,首先將塊號和記憶體地址進行映射,當我們訪問塊緩存中的地址時,先將地址轉化為塊號,然後再進行讀寫。然後將塊緩存的地址通過頁表、頁目錄進行管理。
順帶一提,DISKMAX 大小為 0xC000_0000B = 3GB , 因此 jos 僅支持 3GB 大小的磁碟存儲空間。
塊緩存的同步方案
為了同步記憶體中的磁碟數據,和磁碟中實際存儲的數據,我們利用 PTE 的 PTE_D 位追蹤數據是否被改動。(當記憶體地址addr所指頁被改動時,MMU會將其對應的PTE中的 PTE_D 置位)。
將整個磁碟都讀入記憶體很浪費時間,我們可以參考“寫時複製”實現一種“讀時載入”的頁錯誤處理程式。當程式讀取的塊緩存地址對應的數據尚未被載入時,觸發頁錯誤,然後將對應的數據從磁碟中載入到其塊緩存地址。
塊緩存的是同步的實現,即是練習2的內容。
塊緩存的實現
jos 對塊緩存的實現,主要位於 fs/bc.c 中。其中包含如下函數:
void * diskaddr(uint32_t blockno)
將塊號轉化為對應的塊緩存地址
void*
diskaddr(uint32_t blockno)
{
if (blockno == 0 || (super && blockno >= super->s_nblocks))
panic("bad block number %08x in diskaddr", blockno);
return (char*) (DISKMAP + blockno * BLKSIZE);
}
bool va_is_mapped(void *va)
檢查塊緩存 va 是否已經被映射到頁目錄。
具體方法:檢查 va 對應的 PDE 和 PTE 的 PTE_P 是否置位。
bool
va_is_mapped(void *va)
{
return (uvpd[PDX(va)] & PTE_P) && (uvpt[PGNUM(va)] & PTE_P);
}
bool va_is_dirty(void *va)
檢查塊緩存 VA 是否"臟"。臟指的是數據是否被改動。
具體方法:檢查 va 對應的 PTE 的 PTE_D 是否置位。
bool
va_is_dirty(void *va)
{
return (uvpt[PGNUM(va)] & PTE_D) != 0;
}
static void bc_pgfault(struct UTrapframe *utf)
缺頁中斷,當塊緩存範圍內地址觸發頁錯誤時會被調用。
static void
bc_pgfault(struct UTrapframe *utf)
{
void *addr = (void *) utf->utf_fault_va; //取出引發錯誤的地址
uint32_t blockno = ((uint32_t)addr - DISKMAP) / BLKSIZE; //轉化為塊號
int r;
// 檢查地址是否越界
if (addr < (void*)DISKMAP || addr >= (void*)(DISKMAP + DISKSIZE))
panic("page fault in FS: eip %08x, va %08x, err %04x",
utf->utf_eip, addr, utf->utf_err);
// 檢查塊號是否越界
if (super && blockno >= super->s_nblocks)
panic("reading non-existent block %08x\n", blockno);
// Allocate a page in the disk map region, read the contents
// of the block from the disk into that page.
// Hint: first round addr to page boundary. fs/ide.c has code to read
// the disk.
//
// LAB 5: you code here:
//申請一塊物理頁,將其映射到addr處
addr = ROUNDDOWN(addr, PGSIZE); //對齊需要讀取的地址
sys_page_alloc(0, addr, PTE_W|PTE_U|PTE_P); //調用page_alloc的syscall,申請記憶體頁
// 將磁碟中的數據讀入記憶體
// 磁碟以扇區為單位讀取數據,一個扇區512位元組
// 文件系統以塊為單位管理數據,一個塊4096位元組(一頁)
if((r=ide_read(blockno * BLKSECTS, addr, BLKSECTS))<0) //從硬碟讀取數據到記憶體頁
panic("ide_read: %e" ,r);
//由於,上面的操作對addr進行記憶體寫操作,PTE_D被置位
//如果坐視不管,後面會被文件系統認為,需要寫回磁碟,這肯定是不合理的
//因此通過sys_page_map的方式清空臟位(?為什麼sys_page_map可以清空臟位)
if ((r = sys_page_map(0, addr, 0, addr, uvpt[PGNUM(addr)] & PTE_SYSCALL)) < 0)
panic("in bc_pgfault, sys_page_map: %e", r);
// Check that the block we read was allocated. (exercise for
// the reader: why do we do this *after* reading the block
// in?)
//(這裡我不是很明白)
if (bitmap && block_is_free(blockno))
panic("reading free block %08x\n", blockno);
}
void flush_block(void *addr)
刷新塊緩存地址 addr
void
flush_block(void *addr)
{
//將addr轉換位塊號
uint32_t blockno = ((uint32_t)addr - DISKMAP) / BLKSIZE;
//檢查addr是否越界
if (addr < (void*)DISKMAP || addr >= (void*)(DISKMAP + DISKSIZE))
panic("flush_block of bad va %08x", addr);
// LAB 5: Your code here.
// panic("flush_block not implemented");
//addr向下對齊
addr = ROUNDDOWN(addr, PGSIZE);
//檢查數據是否已經讀入,數據頁是否有臟位
if(!va_is_mapped(addr) || !va_is_dirty(addr))
{
return ;
}
int r = 0;
//將數據寫回至磁碟
if((r = ide_write(blockno*BLKSECTS, addr, BLKSECTS))<0)
{
panic("in flush_block, ide_write() : %e",r);
}
//清空臟位
if((r=sys_page_map(0, addr, 0, addr, uvpt[PGNUM(addr)] & PTE_SYSCALL))<0)
panic("in bc_pgfault, sys_page_map: %e", r);
}
boid bc_init(void)
初始化塊緩存
void
bc_init(void)
{
struct Super super;
//設置文件系統的缺頁處理函數
set_pgfault_handler(bc_pgfault);
check_bc();
// cache the super block by reading it once
// 對super塊的塊緩存地址讀取,並給super
// 首先會觸發缺頁中斷,將block#1載入至diskaddr(1)處
// 然後再進行memmove,將讀取到的數據填充super struct
memmove(&super, diskaddr(1), sizeof super);
}
塊點陣圖
為什麼需要塊點陣圖?
塊緩存實現之後,我們擁有了從磁碟中讀寫、改寫數據塊的能力。接下來考慮一個問題,我們如何刪除某個塊的內容?將其數據用0覆蓋嗎?磁碟的磁頭聽到這種方案內心一定是麻的。一種簡單的方案是用一個點陣圖來表示所有塊的狀態,每個位代表一個塊,1代表空閑,0代表占用。這樣,當我們要"刪除"一個塊的數據時,只要在點陣圖中將對應位置0即可。
塊點陣圖本身也是占用磁碟數據空間的, jos 的塊點陣圖存儲在磁碟的第2個塊以及之後,塊點陣圖一個塊存不下。(手冊中只有一張示意圖提到這個點)
jos 的點陣圖是一個u32int型數組,一個u32int有32個位,對應32個塊。3GB磁碟空間共有 $$\frac{3\times 1024 \times 1024 \times 1024 B}{4\times 1024 B} = 768\times 1024 個$$一個塊共有 $4096\times 8bit = 32 \times 1024 bit$ 因此,bitmap應該占據 $\frac{768}{32} = 24$ 個塊
磁碟的存儲空間示意圖如下:
維護塊點陣圖 (練習3@fs/fs.c)
當我們想要使用 free 的塊時,需要將對應位置0。當我們想釋放 non-free 塊時,應將對應位置1。 練習3 讓我們實現 fs/fs.c 中的 free_block 和 alloc_block 來實現這些內容。值得註意的是,無論是 free_block 還是 alloc_block 我們一定都會影響 bitmap 占用的block,因此需要調用 flush_block 刷新 bitmap 占用的 block。
void free_block(uint32_t blockno)
void
free_block(uint32_t blockno)
{
// Blockno zero is the null pointer of block numbers.
if (blockno == 0)
panic("attempt to free zero block");
bitmap[blockno/32] |= 1<<(blockno%32); //修改bitmap,標記為未使用
}
free_block 中最核心的就是 bitmap[blockno/32] |= 1<<(blockno%32);
blockno/32 得到 blockno 在bitmap 的哪個uint32_t,因為 bitmap 的定義如下:
//bitmap 是一個uint32_t類型的數組
uint32_t *bitmap; // bitmap blocks mapped in memory
blockno%32 得到 blockno 位於這個uint32_t 的哪一位
int alloc_block(void)
allock_block 根據塊點陣圖尋找一個空閑塊,返回這個空閑塊的塊號,並更新塊點陣圖
int
alloc_block(void)
{
uint32_t bitmap_start = 2;
//一個block大小為4096B,bitmap的一項是uint32_t,大小為4B,故一個block夠裝下4096/4項
uint32_t bitmap_item_num_in_block = 4096/4;
for (uint32_t blockno = 0; blockno < super->s_nblocks; blockno++) {//遍歷整個bitmap,尋找空閑塊
if(block_is_free(blockno)){
bitmap[blockno / 32] &= ~(1 << (blockno % 32)); //將該塊置位"已使用"
//blockno/32 得到該block在bitmap的下標位置
uint32_t bitmap_item = blockno / 32;
//blockno % 32 得到block在 bitmap_item 中的第幾個比特位
uint32_t bitmap_item_bit = blockno % 32;
//1 << bitmap_item_bit 得到 bitmap_item_bit 的掩碼
bitmap[bitmap_item] &= ~(1 << bitmap_item_bit);
//bitmap_item / bitmap_item_num_in_block 得到 bitmap_item 位於bitmap後的第幾個block
//然後調用flush_block把該項所在的bitmap塊寫回
flush_block(diskaddr(bitmap_start + bitmap_item / bitmap_item_num_in_block));
return blockno;
}
}
//沒有找到空閑block, 則返回-E_NO_SIAK
return -E_NO_DISK;
}
文件操作(練習4@fs/fs.c)
有了塊緩存和塊點陣圖機制,我們現在有了以塊為單位的讀寫硬碟數據的能力。但是塊中的數據是以文件的形式存儲。jos 在 fs/fs.c 中還有一些函數,用來實現對文件的基本操作。包括:
- 從塊中解析文件結構
- 掃描目錄中的文件條目
- 從根目錄尋找指定文件
練習4 讓我們實現file_block_walk、file_get_block,並且通讀fs/fs.c
file_block_walk : 從文件中的快便宜映射到結構文件中該塊的指針或間接塊
file_get_block : 映射到實際的磁碟塊
static int file_block_walk
根據文件 File f 內的塊號 filebno,尋找該塊對應的硬碟塊號 ppdiskbno
如果 File f 的 indirects 沒有初始化,且 alloc 置位,則初始化 indirects
如果輸入合法,這個函數保證一定完成 filebno 到 diskbno 的映射,但不保證 diskbno 所指的塊已經在塊點陣圖中申請。
申請工作由 file_get_block 負責
static int
file_block_walk(struct File *f, uint32_t filebno, uint32_t **ppdiskbno, bool alloc)
{
uint32_t * indirects;
if(filebno >= NDIRECT + NINDIRECT) //檢查 filebno 是否超出 File結構體 能存儲的上限
return -E_NO_DISK;
if(filebno < NDIRECT)
{
*ppdiskbno = &(f->f_direct[filebno]); //如果 filebno 位於 直接塊內,直接返回
}
else if(f->f_indirect) // 如果 filebno 位於 非直接塊,且該File已經申請了直接塊
{
indirects = diskaddr(f->f_indirect); //獲取非直接塊所在的地址
*ppdiskbno = &(indirects[filebno - NDIRECT]);
}
else if(alloc) // 如果 filebno 位於 非直接塊,且該File未申請非直接塊,且alloc置位
{
int bn;
if ((bn = alloc_block()) < 0)
return bn; //如果沒有剩餘空閑塊,返回E_NO_DISK
f->f_indirect = bn; //初始化 indirect
flush_block(diskaddr(bn)); //刷新 indirect塊 不太理解為什麼要刷新這個塊,這個塊應該是未修改的
indirects = diskaddr(bn);
*ppdiskbno = &(indirects[filebno - NDIRECT]);
}
else // 如果 filebno 位於 非直接塊,且該File未申請非直接塊,且alloc未置位
{
return -E_NOT_FOUND;
}
return 0;
}
file_get_block
負責讀取文件 File f 的第 filebnoe 個塊,將數據存儲在 blk 所指記憶體地址。
int
file_get_block(struct File *f, uint32_t filebno, char **blk)
{
uint32_t * pdiskbno;
int r;
//先通過 file_block_walk 獲取 filebno 對應的 diskbno
if((r = file_block_walk(f, filebno, &pdiskbno, true)) < 0)
return r;
int bn;
//如果 filebno 對應的塊尚未申請,則通過 alloc_block 進行申請
if(*pdiskbno == 0)
{
if((bn = alloc_block()) < 0)
return bn;
*pdiskbno = bn;
flush_block(diskaddr(bn));
}
//將塊中的數據讀取到 blk 所指空間
*blk = diskaddr(*pdiskbno);
return 0;
}
static int dir_lookup
查找 dir 中文件名為 name 的文件,保存在 file 中。
static int
dir_lookup(struct File *dir, const char *name, struct File **file)
{
int r;
uint32_t i, j, nblock;
char *blk;
struct File *f;
assert((dir->f_size % BLKSIZE) == 0);
nblock = dir->f_size / BLKSIZE; //dir中共有 nblock 個塊
for (i = 0; i < nblock; i++) {
if ((r = file_get_block(dir, i, &blk)) < 0) //從dir中獲取第i個塊
return r;
f = (struct File*) blk;
for (j = 0; j < BLKFILES; j++) //遍歷 當前blk中存放的所有 File結構體
if (strcmp(f[j].f_name, name) == 0) { //順找是否存在這個name
*file = &f[j];
return 0;
}
}
return -E_NOT_FOUND;
}
static int dir_alloc_file
在目錄 dir 下申請一個文件 file
static int
dir_alloc_file(struct File *dir, struct File **file)
{
int r;
uint32_t nblock, i, j;
char *blk;
struct File *f;
assert((dir->f_size % BLKSIZE) == 0);
nblock = dir->f_size / BLKSIZE;
//遍歷 dir 中所有的塊
for (i = 0; i < nblock; i++) {
if ((r = file_get_block(dir, i, &blk)) < 0)
return r;
f = (struct File*) blk;
//遍歷塊中的所有 File
for (j = 0; j < BLKFILES; j++)
//如果存在空閑的 File ,則保存至 f 並返回
if (f[j].f_name[0] == '\0') {
*file = &f[j];
return 0;
}
}
//如果 dir 中已申請的塊沒有空閑空間,則申請塊並更新 f_size
dir->f_size += BLKSIZE;
if ((r = file_get_block(dir, i, &blk)) < 0)
return r;
//返回新塊 blk 的第一個 File 的地址
f = (struct File*) blk;
*file = &f[0];
return 0;
}
static int walk_path
從根目錄搜索 path 所指的文件,將最終搜索結果的最底層目錄存放在 pdir , 文件則存放在 pf ,
static int
walk_path(const char *path, struct File **pdir, struct File **pf, char *lastelem)
{
const char *p;
char name[MAXNAMELEN];
struct File *dir, *f;
int r;
path = skip_slash(path); //跳過一開始的 '/'
f = &super->s_root; //從 super 中讀取根目錄文件
dir = 0; //dir 指向上層目錄,dir應當是個目錄類型
name[0] = 0;
if (pdir)
*pdir = 0;
*pf = 0;
while (*path != '\0') {
dir = f;
p = path; //自頂向下地處理 path ,p 指向當前層次目錄名的開頭
while (*path != '/' && *path != '\0') //用path指向當前層次目錄名的尾後
path++;
if (path - p >= MAXNAMELEN)
return -E_BAD_PATH;
memmove(name, p, path - p); //用p和path切下當前層次目錄名,copy到name
name[path - p] = '\0';
path = skip_slash(path); //更新path,讓path指向下一個層次地目錄名開頭
if (dir->f_type != FTYPE_DIR) //檢查dir是否是目錄類型
return -E_NOT_FOUND;
if ((r = dir_lookup(dir, name, &f)) < 0) { //在dir中尋找name
if (r == -E_NOT_FOUND && *path == '\0') { //如果沒找到,就將 pdir 設置為最後有效的目錄,
if (pdir) //lastelem 設置為最後遍歷到的條目
*pdir = dir;
if (lastelem)
strcpy(lastelem, name);
*pf = 0;
}
return r;
}
}
if (pdir)
*pdir = dir;
*pf = f;
return 0;
}
int file_create
int file_create(const char *path, struct File **pf)
在 path 處創建文件 pf
int
file_create(const char *path, struct File **pf)
{
char name[MAXNAMELEN];
int r;
struct File *dir, *f;
if ((r = walk_path(path, &dir, &f, name)) == 0) //嘗試獲取 path 所指文件的 File結構體
return -E_FILE_EXISTS; //如果那個位置已經存在則返回錯誤碼 E_FILE_EXISTS
if (r != -E_NOT_FOUND || dir == 0) //如果存在其他問題,則返回對應錯誤碼
return r;
if ((r = dir_alloc_file(dir, &f)) < 0) //申請一個 File結構體,並將它記錄在 dir 之下
return r;
strcpy(f->f_name, name); //file_create 只負責填充 File結構體的 name欄位
*pf = f;
file_flush(dir); //file_create 只改動了磁碟中的 dir 所指文件的 File結構體
return 0; //因此只需要刷新該部分
}
file_open
打開 path 所在的文件,其實就是直接調用 walk_path
int
file_open(const char *path, struct File **pf)
{
return walk_path(path, 0, pf, 0);
}
file_read
將 File 的數據中第 offset 個位元組後 count 個位元組存儲到 buf 中
ssize_t
file_read(struct File *f, void *buf, size_t count, off_t offset)
{
int r, bn;
off_t pos;
char *blk;
if (offset >= f->f_size)
return 0;
count = MIN(count, f->f_size - offset);
for (pos = offset; pos < offset + count; ) {
// 獲取 pos 所在的塊
// pos/BLKSIZE 可以得到需要讀的數據在第幾個塊
if ((r = file_get_block(f, pos / BLKSIZE, &blk)) < 0)
return r;
// bn為當前塊剩餘全部位元組,或讀取count還未讀完的位元組
bn = MIN(BLKSIZE - pos % BLKSIZE, offset + count - pos);
memmove(buf, blk + pos % BLKSIZE, bn);
pos += bn;
buf += bn;
}
return count;
}
file_write
int
file_write(struct File *f, const void *buf, size_t count, off_t offset)
{
int r, bn;
off_t pos;
char *blk;
// Extend file if necessary
if (offset + count > f->f_size) //如果文件不夠大,擴展文件大小
if ((r = file_set_size(f, offset + count)) < 0)
return r;
for (pos = offset; pos < offset + count; ) {
if ((r = file_get_block(f, pos / BLKSIZE, &blk)) < 0)
return r;
bn = MIN(BLKSIZE - pos % BLKSIZE, offset + count - pos);
memmove(blk + pos % BLKSIZE, buf, bn);
pos += bn;
buf += bn;
}
return count;
}
file_free_block
static int
file_free_block(struct File *f, uint32_t filebno)
{
int r;
uint32_t *ptr;
if ((r = file_block_walk(f, filebno, &ptr, 0)) < 0) //獲取目標塊所在的位置
return r;
if (*ptr) {
free_block(*ptr); //釋放掉塊
*ptr = 0;
}
return 0;
}
static void file_truncate_blocks
將 File 的塊數量調整到 newsize 大小
static void
file_truncate_blocks(struct File *f, off_t newsize)
{
int r;
uint32_t bno, old_nblocks, new_nblocks;
old_nblocks = (f->f_size + BLKSIZE - 1) / BLKSIZE;
new_nblocks = (newsize + BLKSIZE - 1) / BLKSIZE;
for (bno = new_nblocks; bno < old_nblocks; bno++)
if ((r = file_free_block(f, bno)) < 0)
cprintf("warning: file_free_block: %e", r);
if (new_nblocks <= NDIRECT && f->f_indirect) {
free_block(f->f_indirect);
f->f_indirect = 0;
}
}
int file_set_size
設置 File f 的大小為 newsize
int
file_set_size(struct File *f, off_t newsize)
{
if (f->f_size > newsize)
file_truncate_blocks(f, newsize);
f->f_size = newsize;
flush_block(f);
return 0;
}
void file_flush
刷新 f 中的所有塊
void
file_flush(struct File *f)
{
int i;
uint32_t *pdiskbno;
for (i = 0; i < (f->f_size + BLKSIZE - 1) / BLKSIZE; i++) {
if (file_block_walk(f, i, &pdiskbno, 0) < 0 ||
pdiskbno == NULL || *pdiskbno == 0)
continue;
flush_block(diskaddr(*pdiskbno));
}
flush_block(f); //刷新f所在的塊
if (f->f_indirect)
flush_block(diskaddr(f->f_indirect)); //刷新f_indirect所在的塊
}
void fs_sync(void)
刷新整個根目錄
void
fs_sync(void)
{
int i;
for (i = 1; i < super->s_nblocks; i++)
flush_block(diskaddr(i));
}
文件系統介面
jos 的文件系統是一個用戶級進程,以 RPC 的形式,開放給客戶端調用。
文件系統架構和文件客戶端
文件系統提供 read 、 write 、 stat 等介面。這些介面可以對所有類型的文件進行操作,這些函數組成了文件操作的客戶端。
如下圖:
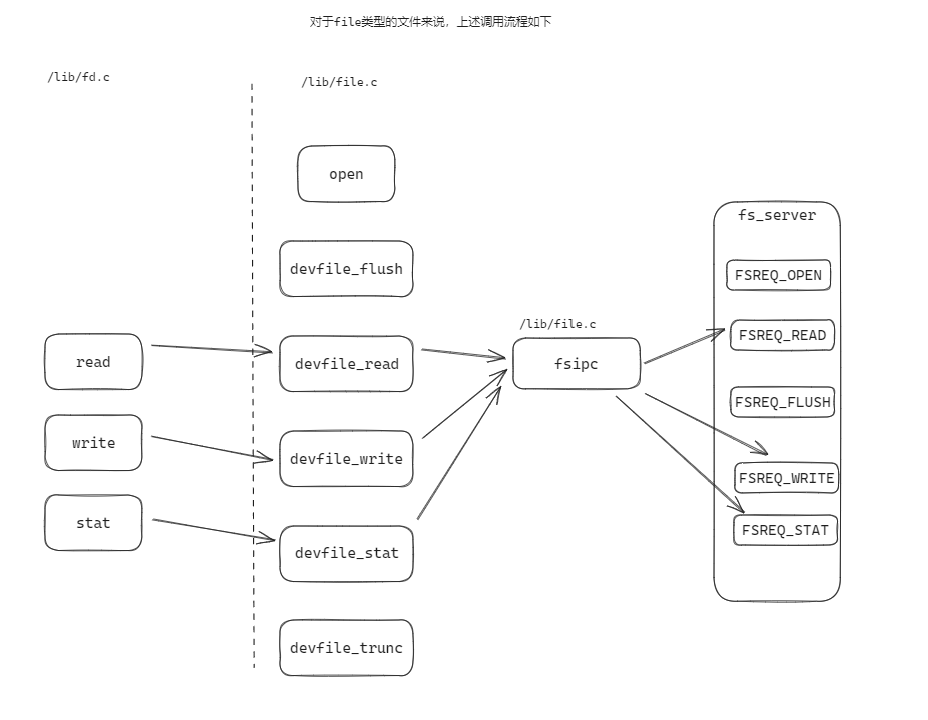
read 會根據文件的具體類型,調用不同的處理函數,其工作內容只是簡單地將讀取任務分發給 與文件描述符類型 對應的設備讀取函數。(file 類型的設備讀取函數是 devfile_read , pipe 類型的設備讀取函數是 devpipe_read )如下圖:
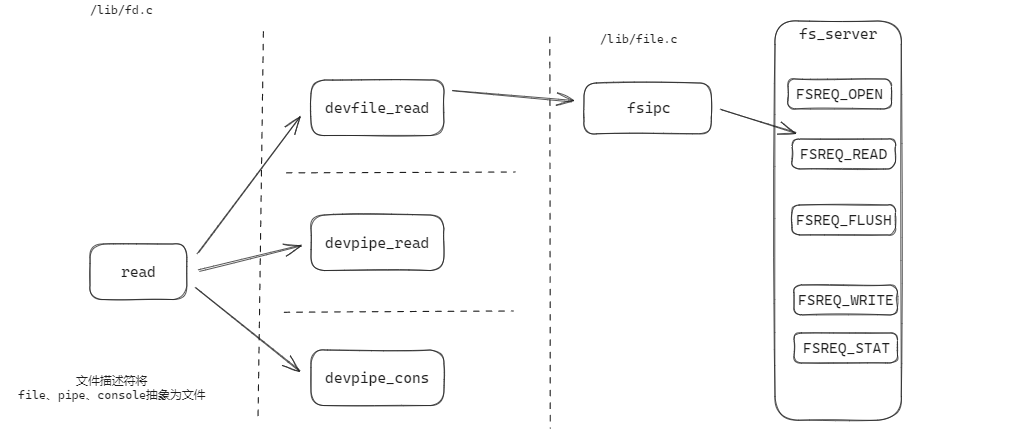
這些設備處理函數的操作方式基本相同:
- 將上層介面函數( read 、write 、 stat )的形參,填寫到請求專用的結構體中,
- 然後將這個結構體作為參數調用 fsipc ,
- fsipc 以 ipc 的形式,將 IPC 請求發送給 fs_server
- fsipc 接收 fs_server 的處理結果,返回給設備處理函數。
文件系統的相關調用的結構如下圖所示:
Regular env FS env
+---------------+ +---------------+
| read | | file_read |
| (lib/fd.c) | | (fs/fs.c) |
...|.......|.......|...|.......^.......|...............
| v | | | | RPC mechanism
| devfile_read | | serve_read |
| (lib/file.c) | | (fs/serv.c) |
| | | | ^ |
| v | | | |
| fsipc | | serve |
| (lib/file.c) | | (fs/serv.c) |
| | | | ^ |
| v | | | |
| ipc_send | | ipc_recv |
| | | | ^ |
+-------|-------+ +-------|-------+
| |
+-------------------+
客戶端函數 lab 直接提供了,沒要求編寫代碼,但是。相關文件如下:
| path | 備註 |
|---|---|
/lib/fd.c |
對各種設備類型的抽象fd的實現,以及高層 file 介面(read) |
/lib/file.c |
fsipc 的實現、file 類型設備的操作(devfile_read) |
/lib/pipe.c |
pipe 的實現、pipe 類型設備的操作(devpipe_read) |
文件系統服務(練習5@fs/serv.c fs/fs.c)
文件系統的維護三種數據結構: struct File 、 struct Fd 、 struct OpenFile
struct File 的結構我們已經很熟悉了,struct File 會被映射到記憶體中,用於映射磁碟。
struct Fd 位於 /inc/fd.h ,對於每一個 jos 中打開了的文件,文件系統都會為它維護一個 struct Fd,從 FILEVA 0xD000_0000 開始的記憶體被用來存儲 Fd ,定義如下:
struct FdFile {
int id;
};
struct Fd {
int fd_dev_id; //設備類型
off_t fd_offset; //文件偏移
int fd_omode; //文件模式
union {
// File server files
struct FdFile fd_file;
};
};
struct OpenFile 將 struct File 和 struct Fd 關聯起來。伺服器維護一個打開所有文件的數組,通過 file ID 索引起來。客戶端使用 file ID 來與伺服器通信。 openfile_lookup 可以將文件的 ID 傳遞給 struct OpenFile
OpenFile 以全局數組的形式定義於 serv.c ,如下:
// Max number of open files in the file system at once
#define MAXOPEN 1024
#define FILEVA 0xD0000000
// initialize to force into data section
struct OpenFile opentab[MAXOPEN] = {
{ 0, 0, 1, 0 }
};
void serv_init
文件系統在 serve_init從 FILEVA 0xD000_0000 開始的記憶體被用來存儲為 Fd ,定義如下:
void
serve_init(void)
{
int i;
uintptr_t va = FILEVA;
for (i = 0; i < MAXOPEN; i++) {
opentab[i].o_fileid = i;
opentab[i].o_fd = (struct Fd*) va; //沒有使用 fd_alloc ,而是直接分配空間
va += PGSIZE; //一個fd占用一頁
}
}
int openfile_alloc
serve_init 在初始化 opentab 的時候給每一個 struct OpenFile 的 Fd 成員分配地址,但這些地址可能還沒有被分配物理頁。
openfile_alloc 負責從 opentab 中申請一個空閑的 struct OpenFile , 同時將對應的 Fd 初始化:
- 如果沒有映射物理頁,則先申請物理頁。
- 將頁面內容置零。
int
openfile_alloc(struct OpenFile **o)
{
int i, r;
// Find an available open-file table entry
for (i = 0; i < MAXOPEN; i++) {
switch (pageref(opentab[i].o_fd)) {
case 0://如果這個頁還沒有映射,說明該 struct OpenFile 是空閑的,先申請物理頁
if ((r = sys_page_alloc(0, opentab[i].o_fd, PTE_P|PTE_U|PTE_W)) < 0)
return r;
/* fall through */
case 1:
opentab[i].o_fileid += MAXOPEN;
*o = &opentab[i];
memset(opentab[i].o_fd, 0, PGSIZE); //整個記憶體頁清零
return (*o)->o_fileid;
}
}
return -E_MAX_OPEN;
}
int openfile_lookup
獲取 fileid 所指的 struct OpenFile
int
openfile_lookup(envid_t envid, uint32_t fileid, struct OpenFile **po)
{
struct OpenFile *o;
o = &opentab[fileid % MAXOPEN];
if (pageref(o->o_fd) <= 1 || o->o_fileid != fileid)
return -E_INVAL;
*po = o;
return 0;
}
int serve_read(練習 5)
根據 union Fsipc 的參數,讀取指定文件的數據
int
serve_read(envid_t envid, union Fsipc *ipc)
{
struct Fsreq_read *req = &ipc->read;
struct Fsret_read *ret = &ipc->readRet;
int r;
if (debug)
cprintf("serve_read %08x %08x %08x\n", envid, req->req_fileid, req->req_n);
// Lab 5: Your code here:
int fileid = req->req_fileid;
int count = req->req_n;
struct OpenFile * o;
if((r = openfile_lookup(envid, fileid, &o))<0)
return r;
if((r = file_read(o->o_file, ret->ret_buf, count, o->o_fd->fd_offset))<0)
return r;
count = r;
o->o_fd->fd_offset += count;
return count;
}
int serve_write
int
serve_write(envid_t envid, struct Fsreq_write *req)
{
if (debug)
cprintf("serve_write %08x %08x %08x\n", envid, req->req_fileid, req->req_n);
// LAB 5: Your code here.
// panic("serve_write not implemented");
int r;
struct OpenFile * o;
if((r = openfile_lookup(envid, o->o_fileid, &o)) < 0)
return r;
//調用 file_write 將 req 中所指 buf 的數據寫入 File 的 offset 所指記憶體中
if((r = file_write(o->o_file, req->req_buf, req->req_n, o->o_fd->fd_offset)) < 0)
return r;
o->o_fd->fd_offset += r;
return r;
}
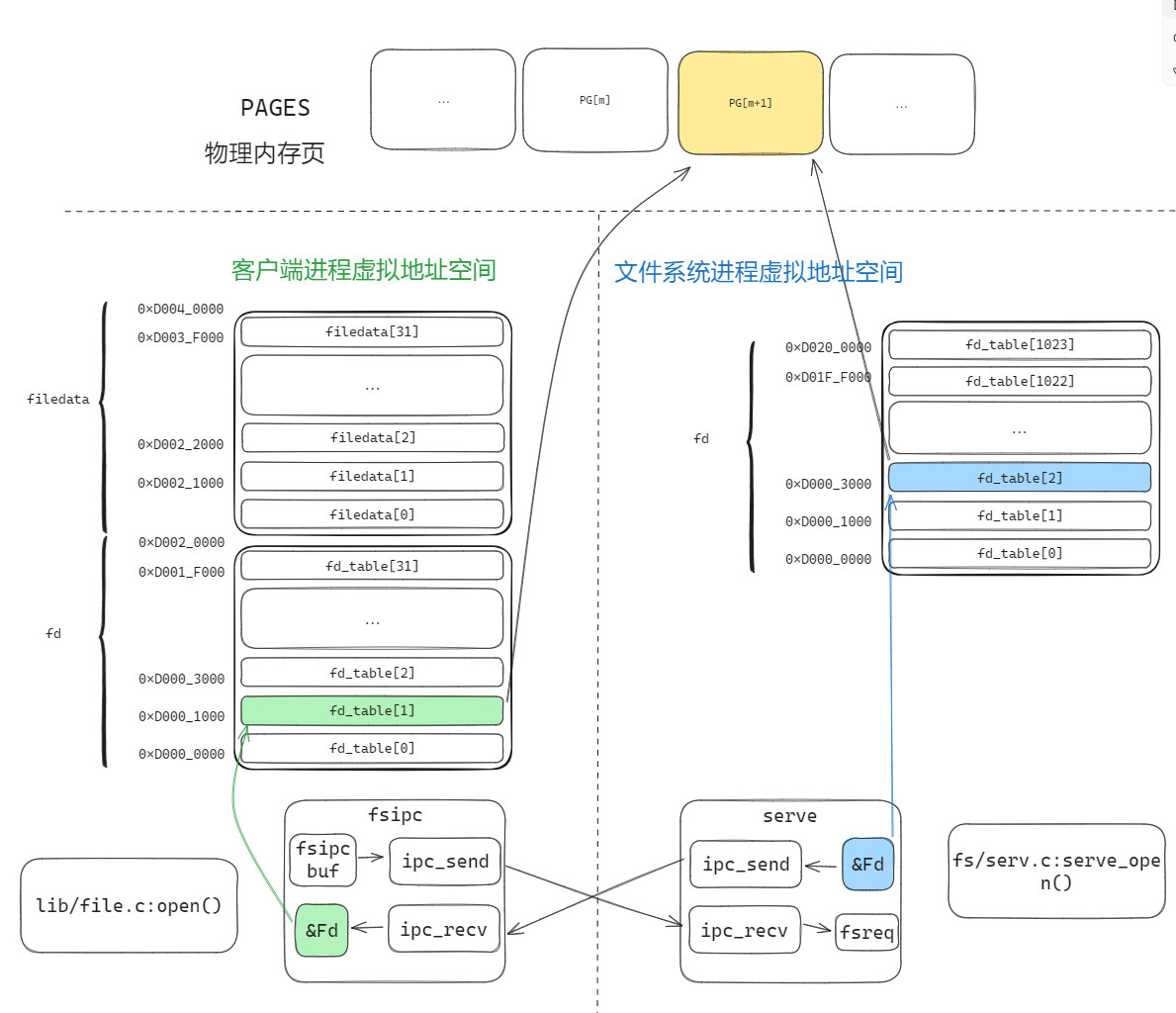
理解open的過程
open調用後,會從客戶端的 fd_table 中取一個空閑槽 fd_table[n],然後由文件系統的 serv_open 來分配物理頁,同時文件西痛的地址空間中也會映射這個 fd 頁面。