
介紹 作為一名有著大量微服務系統處理經驗的軟體架構師,我經常遇到一個不斷重覆的問題:“我應該使用 RabbitMQ 還是 Kafka?” 出於某種原因,許多開發人員認為這些技術是可以互換的。雖然在某些情況下確實如此,但 RabbitMQ 還是 Kafka 之間存在根本上的差異。 因此,不同的場景需要 ...
介紹
作為一名有著大量微服務系統處理經驗的軟體架構師,我經常遇到一個不斷重覆的問題:“我應該使用 RabbitMQ 還是 Kafka?”
出於某種原因,許多開發人員認為這些技術是可以互換的。雖然在某些情況下確實如此,但 RabbitMQ 還是 Kafka 之間存在根本上的差異。
因此,不同的場景需要不同的,選擇錯誤的方案會嚴重影響我們的系統開發設計以及後續維護。
本系列的第 1 部分解釋了 RabbitMQ 和 Apache Kafka 的內部實現概念。本文作為第二部分將繼續回顧這兩個消息平臺之間的顯著差異。
然後本文將繼續向大家解釋 RabbitMQ 和 Apache Kafka 內部實現,並評估它們之間的使用場景。
推薦一個開源免費的 Spring Boot 實戰項目:
RabbitMQ 和 Kafka 的顯著區別
RabbitMQ 是一個消息代理中間件,而 Apache Kafka 是一個分散式流處理平臺。這種差異可能看起來只是語義上的,但它會帶來嚴重的影響,影響我們方便地實現各種系統功能。
例如 Kafka 最適合處理流數據,在同一主題同一分區內保證消息順序,而 RabbitMQ 對流中消息的順序只提供基本的保證。
不過 RabbitMQ 內置了對重試邏輯和死信交換的支持,而 Kafka 將此類邏輯實現留給了用戶。
消息順序

RabbitMQ 對發送到隊列或交換器的消息的順序性提供了很少的保證。雖然消費者按照生產者發送消息的順序處理消息似乎很合理,但其實並不是這樣。
RabbitMQ 文檔聲明瞭以下有關其消息順序的內容:
“在一個通道中發佈的消息,經過一個交換機、一個隊列和一個傳出通道後,將按照發送的順序被接收。” — RabbitMQ Broker Semantics
換句話說,當我們只有一個消息消費者,它就會按順序接收消息。然而一旦我們有多個消費者從同一個隊列讀取消息,我們就無法保證消息的處理順序。
發生這種缺乏排序保證的情況是因為消費者可能會在讀取消息後將消息返回(或重新傳遞)到隊列(例如在處理失敗的情況下)。
一旦消息返回,另一個消費者就可以拿起它進行處理,即使它已經消費了後面的消息。因此多個消費者之間無法有序處理消息,如下圖所示。
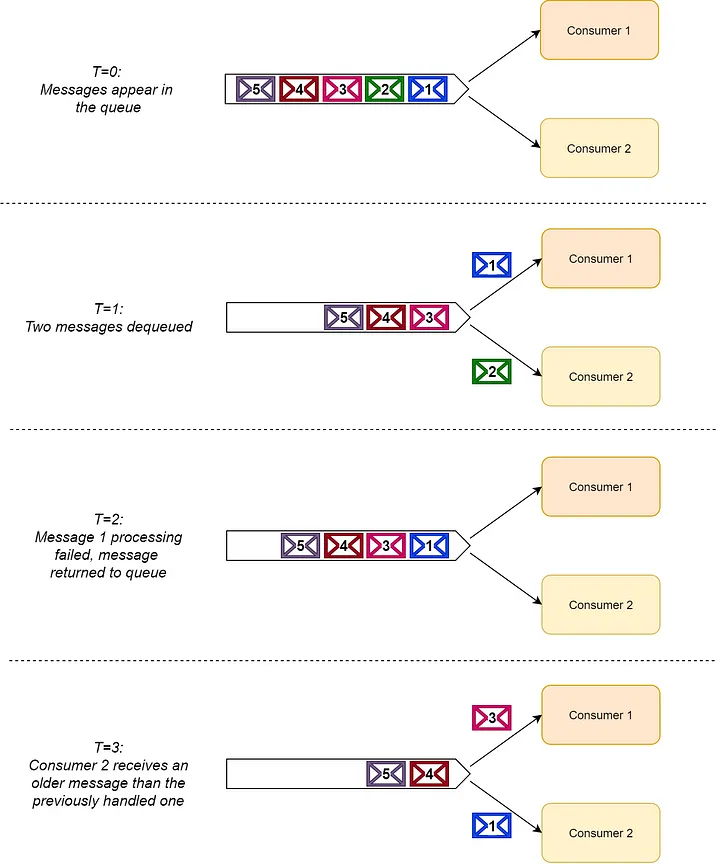
我們可以通過將消費者併發數限製為 1 來重新保證 RabbitMQ 中的消息順序。更準確地說,單個消費者內的線程計數要限製為 1,因為任何並行的消息處理都可能導致消息亂序問題。
如果我們將自己限製為一個單線程消費者雖然能保證消息順序,但這會嚴重影響我們系統擴展消息的處理能力,因此我們不應該輕易的這樣做。
另一方面,Kafka 為消費者在消息處理時提供了可靠的排序保證。Kafka 保證發送到同一主題分區的所有消息都按順序處理。
如果你還記得第 1 部分內容,預設情況下,Kafka 使用迴圈分區程式將消息放置在分區中。但是生產者可以在每個消息上設置分區鍵,以創建邏輯數據流(例如來自同一設備的消息,或屬於同一租戶的消息)。
來自同一數據流的所有消息都會被放置在同一分區中,從而使消費者組按順序處理它們。
我們應該註意到,在消費者組中,每個分區都是由單個消費者的單個線程處理的。因此我們無法擴展單個分區的處理。
不過在 Kafka 中,我們可以擴展主題內的分區數量,從而使每個分區接收更少的消息,併為額外的分區添加額外的消費者。
贏家
Kafka 是明顯的贏家,因為它允許消息按順序處理。RabbitMQ 在這方面只有較弱的保證。
推薦一個開源免費的 Spring Boot 實戰項目:
消息路由

RabbitMQ 可以根據訂閱者定義的路由規則將消息路由到消息交換機的訂閱者。
主題交換(topic exchange)可以基於名為 routing_key 的專用標頭來路由消息。
標頭交換(headers exchange)可以基於任意消息標頭路由消息。這兩種交換都有效地允許消費者指定他們有興趣接收的消息類型,從而為架構師選擇消息平臺提供了極大的靈活性。
- exchange-headers 官網解釋:https://www.rabbitmq.com/tutorials/amqp-concepts.html#exchange-headers
- topic exchange 官網解釋:https://www.rabbitmq.com/tutorials/amqp-concepts.html#exchange-topic
Kafka 不允許消費者在輪詢主題之前過濾主題中的消息。訂閱的消費者無一例外地接收分區中的所有消息。
作為開發人員,你可以使用 Kafka 用於流作業,該作業從主題讀取消息,過濾它們,然後將它們推送到消費者訂閱的另一個主題。儘管也可以實現,但相比與 RabbitMQ 需要更多的努力和維護,並且需要更多的活動部件。
贏家
RabbitMQ 在路由和過濾消息供消費者使用時提供卓越的支持。
消息計時

RabbitMQ 提供了有關延時消息發送到隊列的各種功能:
消息生存時間 (TTL)
TTL 屬性可以與發送到 RabbitMQ 的每條消息相關聯。設置 TTL 可以由發佈者直接完成,也可以作為隊列本身的策略來完成。
指定 TTL 允許系統限制消息的有效期。如果消費者沒有及時處理它,那麼它會自動從隊列中刪除(並轉移到死信交換,稍後會詳細介紹)。
TTL 對於時間敏感但經過一段時間而沒有處理後就變得無關緊要的命令特別有用。
延遲/定時消息
RabbitMQ 通過使用插件支持延遲/預定消息。當在消息交換上啟用此插件時,生產者可以向 RabbitMQ 發送消息,並且生產者可以延遲 RabbitMQ 將此消息路由到消費者隊列的時間。
此功能允許開發人員安排未來的命令,這些命令在此之前不應該被處理。例如當生產者遇到限制規則時,我們可能希望將特定命令的執行延遲到稍後的時間。
Kafka 不支持此類功能。當消息到達時,它將消息寫入分區,消費者可以立即使用它們。
此外 Kafka 沒有為消息提供 TTL 機制,儘管我們可以在應用程式級別實現一種機制。
我們還必須記住,Kafka 分區是一個僅追加的事務日誌。因此它無法操縱消息時間(或分區內的位置)。
贏家
RabbitMQ 毫無疑問地贏得了這一項目的勝利。
消息保留

一旦消費者成功消費消息,RabbitMQ 就會從存儲中刪除消息。此行為幾乎是所有消息代理平臺的一種設計,無法修改。
相比之下,Kafka 根據設計將所有消息保留至每個主題配置的超時時間。在消息保留方面,Kafka 不關心消費者的消費狀態,因為它充當消息日誌。
消費者可以根據需要消費每條消息,並且可以通過操縱分區偏移量“及時”來回移動。Kafka 會定期檢查主題中消息的年齡,並驅逐那些足夠老的消息。
Kafka 的性能不依賴於存儲大小。因此從理論上講,人們幾乎可以無限期地存儲消息,而不會影響性能(只要你的節點足夠大來存儲這些分區)。
贏家
Kafka 設計上就旨在消息保留,而 RabbitMQ 則不然。這裡不需要競爭,Kafka 被宣佈為獲勝者。
故障處理

在處理消息、隊列和事件時,開發人員通常會認為消息處理總是成功。畢竟由於生產者將每條消息都放置在隊列或主題中,即使消費者處理消息失敗,它也可以簡單地重試,直到成功為止。
雖然錶面上確實如此,但我們應該對這個過程進行更多思考。我們應該承認,消息處理在某些情況下可能會失敗。我們應該優雅地處理這些情況,即使部分情況下需要人為干預。
處理消息時可能出現兩類錯誤:
- 瞬時故障 — 由於臨時問題(例如網路連接、CPU 負載或服務崩潰)而發生的故障。我們通常可以通過一遍又一遍地重試來緩解這種失敗。
- 持續性故障 — 由於無法通過額外重試解決的永久性問題而發生的故障。這些失敗的常見原因是軟體錯誤或無效的消息模式(即有害消息)。
作為架構師和開發人員,我們應該問自己:“消息處理失敗時我們應該重試多少次?兩次重試之間應該等待多長時間?我們如何區分暫時性故障和持續性故障?”
最重要的是:“當所有重試都失敗或遇到持續失敗時,我們該怎麼辦?”
雖然這些問題的答案是特定於領域的,但消息傳遞平臺通常為我們提供解決工具。
RabbitMQ 提供了傳遞重試和死信交換 (DLX) 等工具來處理消息處理失敗。
DLX 的主要思想是 RabbitMQ 可以根據適當的配置自動將失敗的消息路由到 DLX,併在此交換中對消息應用進一步的處理規則,包括延遲重試、重試計數以及交付給“人工干預”隊列。
下文提供了有關在 RabbitMQ 中處理重試的可能模式的更多見解。
https://engineering.nanit.com/rabbitmq-retries-the-full-story-ca4cc6c5b493?gi=3b2440cf4efd
這裡要記住的最重要的事情是,在 RabbitMQ 中,當消費者忙於處理和重試特定消息時(甚至在將其返回到隊列之前),其他消費者可以併發處理該消息之後的消息。
當特定消費者重試特定消息時,整個消息處理不會被卡住。因此消息使用者可以根據需要同步重試消息,而不會影響整個系統。
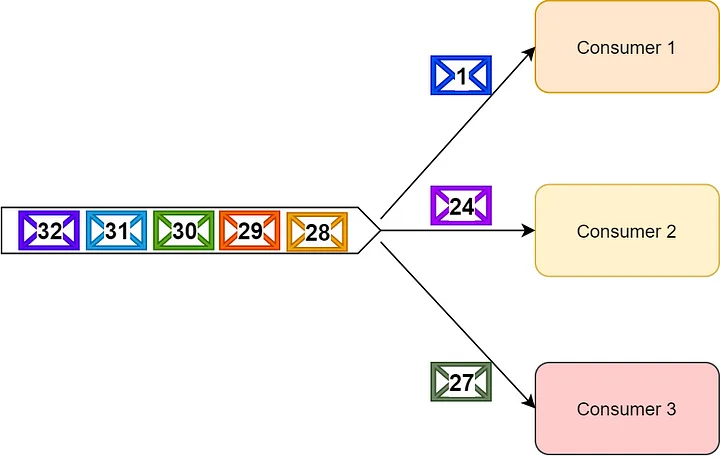
消費者1可以繼續重試消息1,而其他消費者則繼續處理消息
與 RabbitMQ 相反,Kafka 不提供任何開箱即用的此類工具。對於 Kafka 我們需要在應用程式中提供和實現消息重試機制。
另外我們應該註意,當消費者忙於同步重試特定消息時,無法處理來自同一分區的其他消息。
我們無法拒絕並重試特定消息並提交該消息之後的消息,因為消費者無法更改消息順序。正如你所記得的,分區只是一個僅追加日誌。
有一種類型的解決方案是應用程式可以將失敗的消息提交到“重試主題”並從那裡處理重試,不過這樣我們就會失去了消息的順序性。
Uber 工程部提供瞭解決此類問題的示例,可以在 Uber.com 上找到。如果消息處理的延遲不是問題,那麼使用普通 Kafka 可能就足夠了。
Uber.com 地址:https://eng.uber.com/reliable-reprocessing/

如果消費者在重試消息時遇到困難,則不會處理底部分區中的消息
贏家
RabbitMQ 是該項目上的贏家,因為它提供了一種開箱即用的解決此問題的工具。
擴展性

有多個基準測試可以測試 RabbitMQ 和 Kafka 的性能。
雖然通用基準測試對特定情況的適用性有限,但 Kafka 通常被認為比 RabbitMQ 具有更好的性能。Kafka 使用順序磁碟 I/O 來提高性能。
它使用分區的架構意味著它的水平擴展(橫向擴展)比 RabbitMQ 更好,而 RabbitMQ 的垂直擴展(縱向擴展)更好。
大型 Kafka 的集群部署通常每秒可以處理數十萬條消息,甚至每秒處理數百萬條消息。
過去的時間里,Pivotal 團隊發佈了 RabbitMQ 集群可以每秒處理 100 萬條消息的文章如下。然而它是在 30 個節點的集群上實現的,負載以最佳方式分佈在多個隊列和交換器上。
RabbitMQ Hits One Million Messages Per Second on Google Compute Engine,地址:https://tanzu.vmware.com/content/blog/rabbitmq-hits-one-million-messages-per-second-on-google-compute-engine
典型的 RabbitMQ 部署包括三到七個節點集群,這些節點集群不一定能最佳地分配隊列之間的負載。這些典型的集群通常只能每秒處理數萬條消息的負載。
贏家
雖然這兩個平臺都可以處理大量負載,但 Kafka 通常比 RabbitMQ 具有更好的擴展性,並且可以實現更高的吞吐量,從而贏得了這一輪。
然而值得註意的是,大多數系統都不會達到每秒上萬的消息處理量!因此除非你正在構建下一個擁有數百萬用戶的熱門軟體系統,否則你不需要太關心擴展性,因為這兩個平臺都可以很好地為你服務。
消費者複雜性

RabbitMQ 使用智能代理人(smart-broker)和愚蠢消費者(dumb-consumer)的方法。消費者註冊到消費隊列上,RabbitMQ 會在消息進入時向它們推送消息以進行處理。RabbitMQ 消費者還具有主動拉取的功能。不過它使用的比較少。
RabbitMQ 自動向消費者分發消息以及從隊列(可能是 DLX)中刪除消息。消費者無需擔心這些。
RabbitMQ 的結構還意味著,當負載增加時,隊列的消費者組可以有效地從一個消費者擴展到多個消費者,而無需對系統進行任何更改。
 RabbitMQ 消費者有效地擴展和縮小
RabbitMQ 消費者有效地擴展和縮小
另一方面,Kafka 使用愚蠢代理人(dumb-broker)和聰明消費者(smart-consumer)的方法。消費者組中的消費者需要協調它們之間主題分區的約定(以便消費者組中只有一個消費者監聽特定分區)。
消費者還需要管理和存儲其分區的偏移索引。幸運的是 Kafka SDK 為我們處理了這些,所以我們不需要自己管理。
不過當我們的負載較低時,單個消費者需要並行處理和跟蹤多個分區,這需要消費者端有更多的資源。
此外,隨著系統負載的增加,我們只能將消費者組的消費者數量擴大到等於主題中分區數量的程度。不過我們可以通過增加分區數來增加消費者數。
當系統負載減少時,我們無法刪除已經添加的分區,從而浪費了消費者資源。

Kafka分區無法刪除,縮減規模後留給消費者更多的工作
贏家
RabbitMQ 在設計上就是為愚蠢消費者(dumb-consumers)而設計的。所以它成為了這一輪的勝利者。
何時使用哪個?

現在我們面臨一個價值百萬美元的問題:“我們什麼時候應該使用 RabbitMQ,什麼時候應該使用 Kafka?”
如果我們總結以上差異,我們將得出以下結論:
一般情況下,RabbitMQ 是更好的選擇:
- 先進靈活的路由規則。
- 消息計時控制(控制消息過期或消息延遲)。
- 高級故障處理功能,以防消費者無法處理消息(暫時或永久)。
- 更簡單的消費者實現。
當我們需要以下條件時,Kafka 是更好的選擇:
- 嚴格的消息排序。
- 消息保留較長時間,包括重放過去消息的可能性。
- 當傳統解決方案無法滿足我們對擴展性的需求時,Kafka 能夠達到較高的規模。
我們可以使用這兩個平臺來用於大多數軟體系統。然而作為架構師,我們有責任選擇最適合這個系統的工具。在做出這種選擇時,我們應該考慮如上所述的功能差異和非功能限制。
這些非功能限制包括:
- 當前平臺的現有開發人員掌握知識。
- 托管雲解決方案的可用性(如果適用)。
- RabbitMQ 和 Kafka 的運營成本。
- 我們的目標技術棧中 SDK 的可用性。
在開發複雜的軟體系統時,我們可能會傾向於只使用一個消息平臺來實現所有必需的消息傳遞功能。然而根據我的經驗,在同一個系統中,同時使用這兩個消息平臺會帶來很多好處。
例如在基於事件驅動架構的系統中,我們可以使用 RabbitMQ 在服務之間發送命令,再使用 Kafka 來實現業務事件通知。
原因是事件通知通常用於事件溯源、批量操作(ETL 樣式)或審計目的,因此 Kafka 的消息保留功能非常有價值。
命令通常需要在消費者端進行額外的處理,這些處理可能會失敗並且需要高級的故障處理功能,這適用於 RabbitMQ。
最後
我開始寫這兩篇文章系列的初衷是,許多開發人員認為 RabbitMQ 和 Kafka 是可以互換的。我希望大家看到這兩篇文章後,能更加深入瞭解這些消息平臺的內部構造以及它們之間的技術差異。這些差異反過來又會影響這些消息平臺所服務的系統。RabbitMQ 和 Kafka 都很棒,可以適用於多種系統。
最後作為架構師,我們有責任瞭解每個系統的需求,確定其優先順序,並選擇最合適的解決方案。
本文翻譯自國外論壇 medium,原文地址:https://betterprogramming.pub/rabbitmq-vs-kafka-1779b5b70c41
近期熱文推薦:
1.1,000+ 道 Java面試題及答案整理(2022最新版)
4.別再寫滿屏的爆爆爆炸類了,試試裝飾器模式,這才是優雅的方式!!
覺得不錯,別忘了隨手點贊+轉發哦!

