
性能優化是一場永無止境的旅程。到家門店系統,作為到家核心基礎服務之一,門店C端介面有著調用量高,性能要求高的特點。C端服務經過演進,核心介面先查詢本地緩存,如果本地緩存沒有命中,再查詢Redis。本地緩存命中率99%,服務性能比較平穩。 ...
一、背景
性能優化是一場永無止境的旅程。
到家門店系統,作為到家核心基礎服務之一,門店C端介面有著調用量高,性能要求高的特點。
C端服務經過演進,核心介面先查詢本地緩存,如果本地緩存沒有命中,再查詢Redis。本地緩存命中率99%,服務性能比較平穩。
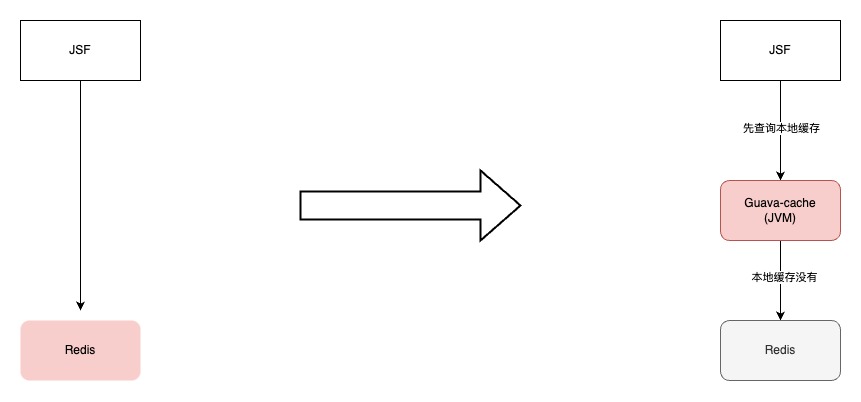
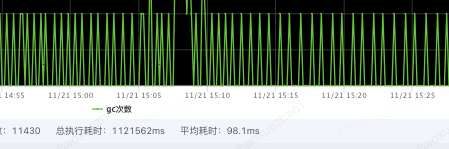
隨著門店數據越來越多,本地緩存容量逐漸增大到3G左右。雖然對垃圾回收器和JVM參數都進行調整,由於本地緩存數據量越來越大,本地緩存數據對於應用GC的影響越來越明顯,YGC平均耗時****100ms,特別是大促期間調用方介面毛刺感知也越來越明顯。
由於本地緩存在每台機器上容量是固定的,即便是將機器擴容,對與GC毛刺也沒有明顯效果。
二、初識此物心已驚-OHC初識
本地緩存位於應用程式的記憶體中,讀取和寫入速度非常快,可以快速響應請求,無需額外的網路通信,但是一般本地緩存存在JVM內,數據量過多會影響GC,造成GC頻率、耗時增加;如果用Redis的話有網路通信的開銷。
| 框架 | 簡介 | 特點 | 堆外緩存 | 性能(一般情況) |
|---|---|---|---|---|
| Guava Cache | Guava Cache是Google的本地緩存庫,提供了基本的緩存功能。它簡單易用、輕量級,並支持基本的緩存操作。 | ·支持最大容量限制 ·支持兩種過期刪除策略(插入時間和訪問時間) ·支持簡單的統計功能 ·基於LRU演算法實現 | 不支持 | 性能中等 |
| Caffeine | Caffeine是一個高性能的本地緩存庫,提供了豐富的功能和配置選項。它支持高併發性能、低延遲和一些高級功能,如緩存過期、非同步刷新和緩存統計等。 | ·提供了豐富的功能和配置選項;高併發性能和低延遲;支持緩存過期、非同步刷新和緩存統計等功能; ·基於java8實現的新一代緩存工具,緩存性能接近理論最優。 ·可以看作是Guava Cache的增強版,功能上兩者類似,不同的是Caffeine採用了一種結合LRU、LFU優點的演算法:W-TinyLFU,在性能上有明顯的優越性 | 不支持 | 性能出色 |
| Ehcache | Encache是一個純Java的進程內緩存框架,具有快速、精幹等特點,是Hibernate中預設的CacheProvider。同Caffeine和Guava Cache相比,Encache的功能更加豐富,擴展性更強 | ·支持多種緩存淘汰演算法,包括LRU、LFU和FIFO ·緩存支持堆記憶體儲、堆外存儲、磁碟存儲(支持持久化)三種 ·支持多種集群方案,解決數據共用問題 | 支持 | 性能一般 |
| OHC | OHC(Off-Heap Cache)是一個高性能的堆外緩存庫,專為高併發和低延遲而設計。它使用堆外記憶體和自定義的數據結構來提供出色的性能 | ·針對高併發和低延遲進行了優化;使用自定義數據結構和無鎖併發控制;較低的GC開銷; ·在高併發和低延遲的緩存訪問場景下表現出色 | 支持 | 性能最佳 |
通過對本地緩存的調研,堆外緩存可以很好兼顧上面的問題。堆外緩存把數據放在JVM堆外的,緩存數據對GC影響較小,同時它是在機器記憶體中的,相對與Redis也沒有網路開銷,最終選擇OHC。
三\習得技能心自安-OHC使用
talk is cheap, show me the code! OCH是騾子是馬我們遛一遛。
1.引入POM
OHC 存儲的是二進位數組,需要實現OHC序列化介面,將緩存數據與二進位數組之間序列化和反序列化。
這裡使用的是Protostuff,當然也可以使用kryo、Hession等,通過壓測驗證選擇適合的序列化框架。
<!--OHC相關-->
<dependency>
<groupId>org.caffinitas.ohc</groupId>
<artifactId>ohc-core</artifactId>
<version>0.7.4</version>
</dependency>
<!--OHC 存儲的是二進位數組,所以需要實現OHC序列化介面,將緩存數據與二進位數組之間序列化和反序列化-->
<!--這裡使用的是protostuff,當然也可以使用kryo、Hession等,通過壓測驗證選擇適合的-->
<dependency>
<groupId>io.protostuff</groupId>
<artifactId>protostuff-core</artifactId>
<version>1.6.0</version>
</dependency>
<dependency>
<groupId>io.protostuff</groupId>
<artifactId>protostuff-runtime</artifactId>
<version>1.6.0</version>
</dependency>
2.創建OHC緩存
OHC緩存創建
OHCache<String, XxxxInfo> basicStoreInfoCache = OHCacheBuilder.<String, XxxxInfo>newBuilder()
.keySerializer(new OhcStringSerializer()) //key的序列化器
.valueSerializer(new OhcProtostuffXxxxInfoSerializer()) //value的序列化器
.segmentCount(512) // 分段數量 預設=2*CPU核數
.hashTableSize(100000)// 哈希表大小 預設=8192
.capacity(1024 * 1024 * 1024) //緩存容量 單位B 預設64MB
.eviction(Eviction.LRU) // 淘汰策略 可選LRU\W_TINY_LFU\NONE
.timeouts(false) //不使用過期時間,根據業務自己選擇
.build();
自定義序列化器,這裡key-String 序列化器,這裡直接復用OCH源碼中測試用例的String序列化器;
value-自定義對象序列化器,這裡用Protostuff實現,也可以自己選擇使用kryo、Hession等實現;
//key-String 序列化器,這裡直接復用OCH源碼中測試用例的String序列化器
public class OhcStringSerializer implements CacheSerializer<String> {
@Override
public int serializedSize(String value) {
return writeUTFLen(value);
}
@Override
public void serialize(String value, ByteBuffer buf) {
// 得到字元串對象UTF-8編碼的位元組數組
byte[] bytes = value.getBytes(Charsets.UTF_8);
buf.put((byte) ((bytes.length >>> 8) & 0xFF));
buf.put((byte) ((bytes.length >>> 0) & 0xFF));
buf.put(bytes);
}
@Override
public String deserialize(ByteBuffer buf) {
int length = (((buf.get() & 0xff) << 8) + ((buf.get() & 0xff) << 0));
byte[] bytes = new byte[length];
buf.get(bytes);
return new String(bytes, Charsets.UTF_8);
}
static int writeUTFLen(String str) {
int strlen = str.length();
int utflen = 0;
int c;
for (int i = 0; i < strlen; i++) {
c = str.charAt(i);
if ((c >= 0x0001) && (c <= 0x007F)){
utflen++;}
else if (c > 0x07FF){
utflen += 3;}
else{
utflen += 2;
}
}
if (utflen > 65535) {
throw new RuntimeException("encoded string too long: " + utflen + " bytes");
}
return utflen + 2;
}
}
//value-自定義對象序列化器,這裡用Protostuff實現,可以自己選擇使用kryo、Hession等實現
public class OhcProtostuffXxxxInfoSerializer implements CacheSerializer<XxxxInfo> {
/**
* 將緩存數據序列化到 ByteBuffer 中,ByteBuffer是OHC管理的堆外記憶體區域的映射。
*/
@Override
public void serialize(XxxxInfo t, ByteBuffer byteBuffer) {
byteBuffer.put(ProtostuffUtils.serialize(t));
}
/**
* 對堆外緩存的數據進行反序列化
*/
@Override
public XxxxInfo deserialize(ByteBuffer byteBuffer) {
byte[] bytes = new byte[byteBuffer.remaining()];
byteBuffer.get(bytes);
return ProtostuffUtils.deserialize(bytes, XxxxInfo.class);
}
/**
* 計算字序列化後占用的空間
*/
@Override
public int serializedSize(XxxxInfo t) {
return ProtostuffUtils.serialize(t).length;
}
}
為了方便調用和序列化封裝為工具類,同時對代碼通過FastThreadLocal進行優化,提升性能。
public class ProtostuffUtils {
/**
* 避免每次序列化都重新申請Buffer空間,提升性能
*/
private static final FastThreadLocal<LinkedBuffer> bufferPool = new FastThreadLocal<LinkedBuffer>() {
@Override
protected LinkedBuffer initialValue() throws Exception {
return LinkedBuffer.allocate(4 * 2 * LinkedBuffer.DEFAULT_BUFFER_SIZE);
}
};
/**
* 緩存Schema
*/
private static Map<Class<?>, Schema<?>> schemaCache = new ConcurrentHashMap<>();
/**
* 序列化方法,把指定對象序列化成位元組數組
*/
@SuppressWarnings("unchecked")
public static <T> byte[] serialize(T obj) {
Class<T> clazz = (Class<T>) obj.getClass();
Schema<T> schema = getSchema(clazz);
byte[] data;
LinkedBuffer linkedBuffer = null;
try {
linkedBuffer = bufferPool.get();
data = ProtostuffIOUtil.toByteArray(obj, schema, linkedBuffer);
} finally {
if (Objects.nonNull(linkedBuffer)) {
linkedBuffer.clear();
}
}
return data;
}
/**
* 反序列化方法,將位元組數組反序列化成指定Class類型
*/
public static <T> T deserialize(byte[] data, Class<T> clazz) {
Schema<T> schema = getSchema(clazz);
T obj = schema.newMessage();
ProtostuffIOUtil.mergeFrom(data, obj, schema);
return obj;
}
@SuppressWarnings("unchecked")
private static <T> Schema<T> getSchema(Class<T> clazz) {
Schema<T> schema = (Schema<T>) schemaCache.get(clazz);
if (Objects.isNull(schema)) {
schema = RuntimeSchema.getSchema(clazz);
if (Objects.nonNull(schema)) {
schemaCache.put(clazz, schema);
}
}
return schema;
}
}
3.壓測及參數調整
通過壓測並逐步調整OHC配置常見參數(segmentCount、hashTableSize、eviction,參數含義見附錄)
MAX對比降低10倍

GC時間對比降低10倍
優化前
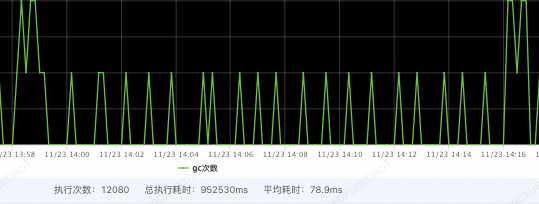
優化後
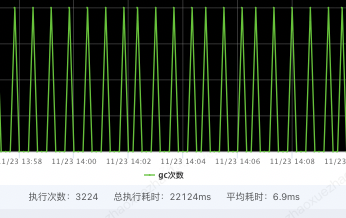
4.OHC緩存狀態監控
OHC緩存的命中次數、記憶體使用狀態等存儲在OHCacheStats中,可以通過OHCache.stats()獲取。
OHCacheStates信息:
hitCount:緩存命中次數,表示從緩存中成功獲取數據的次數。
missCount:緩存未命中次數,表示嘗試從緩存中獲取數據但未找到的次數。
evictionCount:緩存驅逐次數,表示因為緩存空間不足而從緩存中移除的數據項數量。
expireCount:緩存過期次數,表示因為緩存數據過期而從緩存中移除的數據項數量。
size:緩存當前存儲的數據項數量。
capacity:緩存的最大容量,表示緩存可以存儲的最大數據項數量。
free:緩存剩餘空閑容量,表示緩存中未使用的可用空間。
rehashCount:重新哈希次數,表示進行哈希表重新分配的次數。
put(add/replace/fail):數據項添加/替換/失敗的次數。
removeCount:緩存移除次數,表示從緩存中移除數據項的次數。
segmentSizes(#/min/max/avg):段大小統計信息,包括段的數量、最小大小、最大大小和平均大小。
totalAllocated:已分配的總記憶體大小,表示為負數時表示未知。
lruCompactions:LRU 壓縮次數,表示進行 LRU 壓縮的次數。
通過定期採集OHCacheStates信息,來監控本地緩存數據、命中率=[命中次數 / (命中次數 + 未命中次數)]等,並添加相關報警。同時通過緩存狀態信息,來判斷過期策略、段數、容量等設置是否合理,命中率是否符合預期等。
四.剖析根源見真諦-OHC原理
堆外緩存框架(Off-Heap Cache)是將緩存數據存儲在 JVM 堆外的記憶體區域,而不是存儲在 JVM 堆中。在 OHC(Off-Heap Cache)中,數據也是存儲在堆外的記憶體區域。
具體來說,OHC 使用 DirectByteBuffer 來分配堆外記憶體,並將緩存數據存儲在這些 DirectByteBuffer 中。
DirectByteBuffer 在 JVM 堆外的記憶體區域中分配一塊連續的記憶體空間,緩存數據被存儲在這個記憶體區域中。這使得 OHC 在處理大量數據時具有更高的性能和效率,因為它可以避免 JVM 堆的垃圾回收和堆記憶體限制。
OHC 核心OHCache介面提供了兩種實現:
- OHCacheLinkedImpl: 實現為每個條目單獨分配堆外記憶體,最適合中型和大型條目。
- OHCacheChunkedImpl:實現為每個散列段作為一個整體分配堆外記憶體,並且適用於小條目。(實驗性的,不推薦,不做關註)
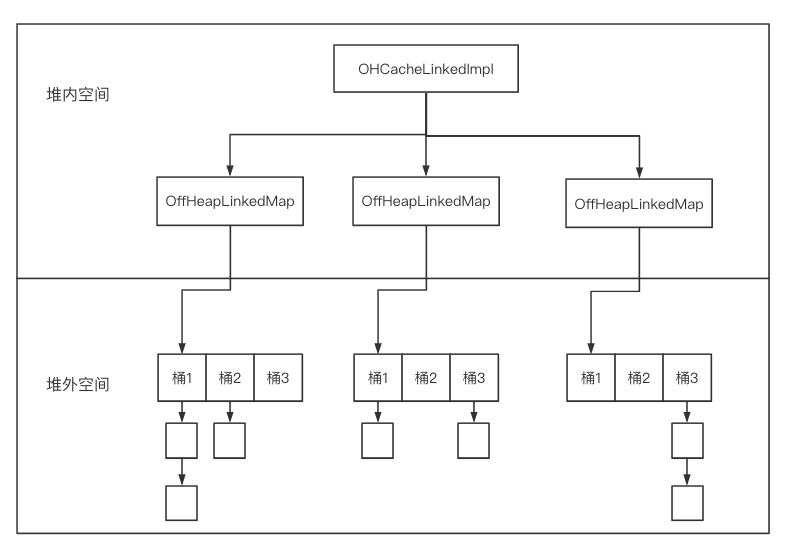
可以看到OHCacheLinkedImpl中包含多個段,每個段用OffHeapLinkedMap來表示。同時,OHCacheLinkedImpl將Java對象序列化成位元組數組存儲在堆外,在該過程中需要使用用戶自定義的CacheSerializer。
OHCacheLinkedImpl的主要工作流程如下:
-
計算key的hash值,根據hash值計算段號,確定其所處的OffHeapLinkedMap
-
從OffHeapLinkedMap中獲取該鍵值對的堆外記憶體地址(指針)
-
對於get操作,從指針所指向的堆外記憶體讀取byte[],把byte[]反序列化成對象
-
對於put操作,把對象序列化成byte[],並寫入指針所指向的堆外記憶體
可以將OHC理解為一個key-value結果的map,只不過這個map數據存儲是指向堆外記憶體的記憶體指針。
指針在堆內,指針指向的緩存數據存儲在堆外。那麼OHC最核心的其實就是對堆外記憶體的地址引用的put和get以及發生在其中記憶體空間的操作了。
對OHCacheLinkedImpl的put、get本地調試
1.put

put核心操作就是
1.申請堆外記憶體
2.將申請地址存入map;
3.異常時釋放記憶體
第2步其實就是map數據更新、擴容等的一些實現這裡不在關註,我們重點關註怎麼申請和釋放記憶體的
1.申請記憶體
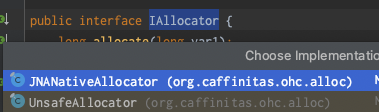
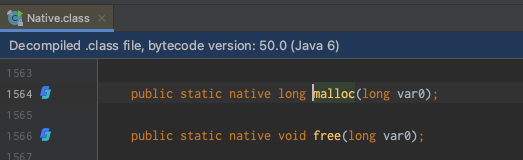
通過深入代碼發現是調用的IAllocator介面的JNANativeAllocator實現類,最後調用的是com.sun.jna.Native#malloc實現

2.釋放記憶體
通過上面可知釋放記憶體操作的代碼

2.get
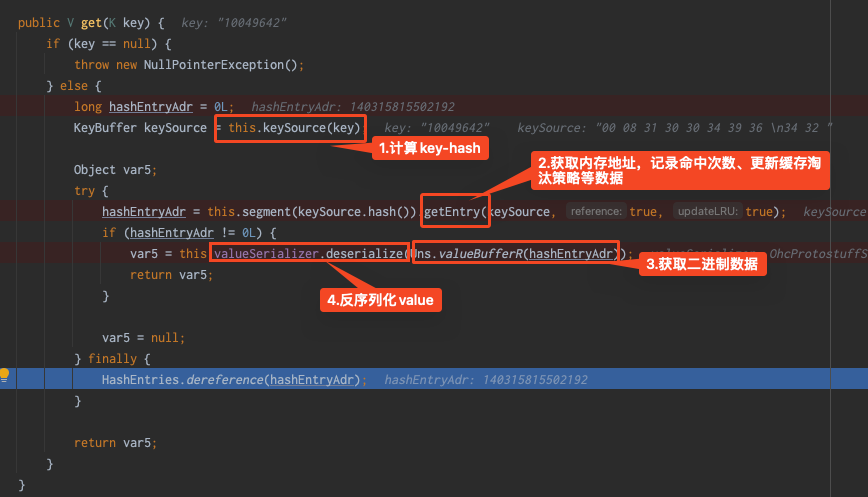
3.Q&A
在put操作時,上面看到IAllocator有兩個實現類,JNANativeAllocator和UnsafeAllocator兩個實現類,他們有什麼區別?為什麼使用JNANativeAllocator?
區別:UnsafeAllocator對記憶體操作使用的是Unsafe類

為什麼使用JNANativeAllocator:Native比Unsafe性能更好,差3倍左右,OHC預設使用JNANativeAllocator;
在日常我們知道通過ByteBuffer#allocateDirect(int capacity)也可以直接申請堆外記憶體,通過ByteBuffer源碼可以看到內部使用的就是Unsafe類


可以看到,同時DirectByteBuffer內部會調用 Bits.reserveMemory(size, cap);
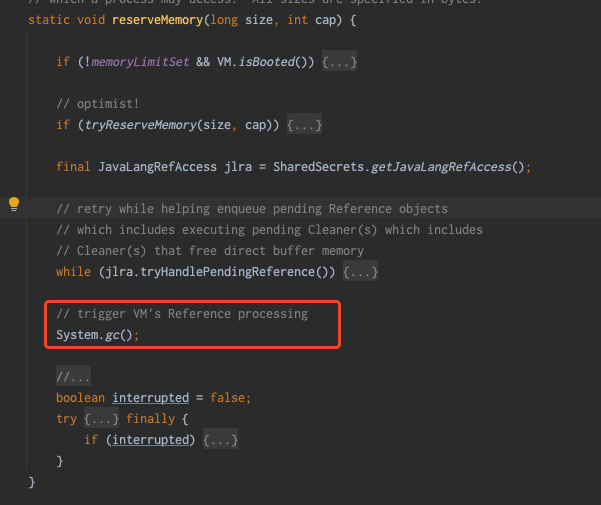
Bits.reserveMemory方法中,當記憶體不足時可能會觸發fullgc,多個申請記憶體的線程同時遇到這種情況時,對於服務來說是不能接受的,所以這也是OHC自己進行堆外記憶體管理的原因。
如果自己進行實現堆外緩存框架,要考慮上面這種情況。
五.總結
1.OHC使用建議
-
對於OHC的參數配置、序列化器的選擇,沒有固定的推薦。可以通過壓測逐步調整到最優。
-
由於OHC需要把key和value序列化成位元組數組存儲到堆外,因此需要選擇合適的序列化工具。
-
在存儲每個鍵值對時,會調用CacheSerializer#serializedSize計算序列化後的記憶體空間占用,從而申請堆外記憶體。另外,在真正寫入堆外時,會調用CacheSerializer#serialize真正進行序列化。因此,務必在這兩個方法中使用相同的序列化方法,防止序列化的大小與計算出來的大小不一致,導致記憶體存不下或者多申請,浪費記憶體空間。
2.緩存優化建議
-
當本地緩存影響GC時,可以考慮使用OHC減少本地緩存對GC的影響;
-
區分熱點數據,對緩存數據進行多級拆分,如堆內->堆外->分散式緩存(Reids )等;
-
將較大緩存對象拆分或者按照業務維度將不同熱點數據緩存到不同介質中,減少單一存儲介質壓力;
-
減小緩存對象大小,如緩存JSON字元,可對欄位名進行縮寫 ,減少存儲數據量,降低傳輸數據量,同時也能保證數據一定的私密性。
對象:{"paramID":1,"paramName":"John Doe"} 正常JSON字元串:{"paramID":1,"paramName":"John Doe"} 壓縮欄位名JSON字元串:
Hold hold , One more thing....
在使用Guava時,存儲25w個緩存對象數據占用空間485M
使用OHCache時,儲存60w個緩存對象數據占用數據387M
為什麼存儲空間差別那麼多吶?
Guava 存儲的對象是在堆記憶體中的,對象在 JVM 堆中存儲時,它們會占用一定的記憶體空間,並且會包含對象頭、實例數據和對齊填充等信息。對象的大小取決於其成員變數的類型和數量,以及可能存在的對齊需求。同時當對象被頻繁創建和銷毀時,可能會產生記憶體碎片。
而 OHC 它將對象存儲在 JVM 堆外的直接記憶體中。由於堆外記憶體不受 Java 堆記憶體大小限制,OHC 可以更有效地管理和利用記憶體。此外,OHC 底層存儲位元組數組,存儲位元組數組相對於直接存儲對象,可以減少對象的創建和銷毀,在一些場景下,直接操作位元組數組可能比操作對象更高效,因為它避免了對象的額外開銷,如對象頭和引用,減少額外的開銷。同時將對象序列化為二進位數組存儲,記憶體更加緊湊,減少記憶體碎片的產生。
綜上所述,OHC 在存儲大量對象時能夠更有效地利用記憶體空間,相對於 Guava 在記憶體占用方面具有優勢。
另外一個原因,不同序列化框架性能不同,將對象序列化後的占用空間的大小也不同。
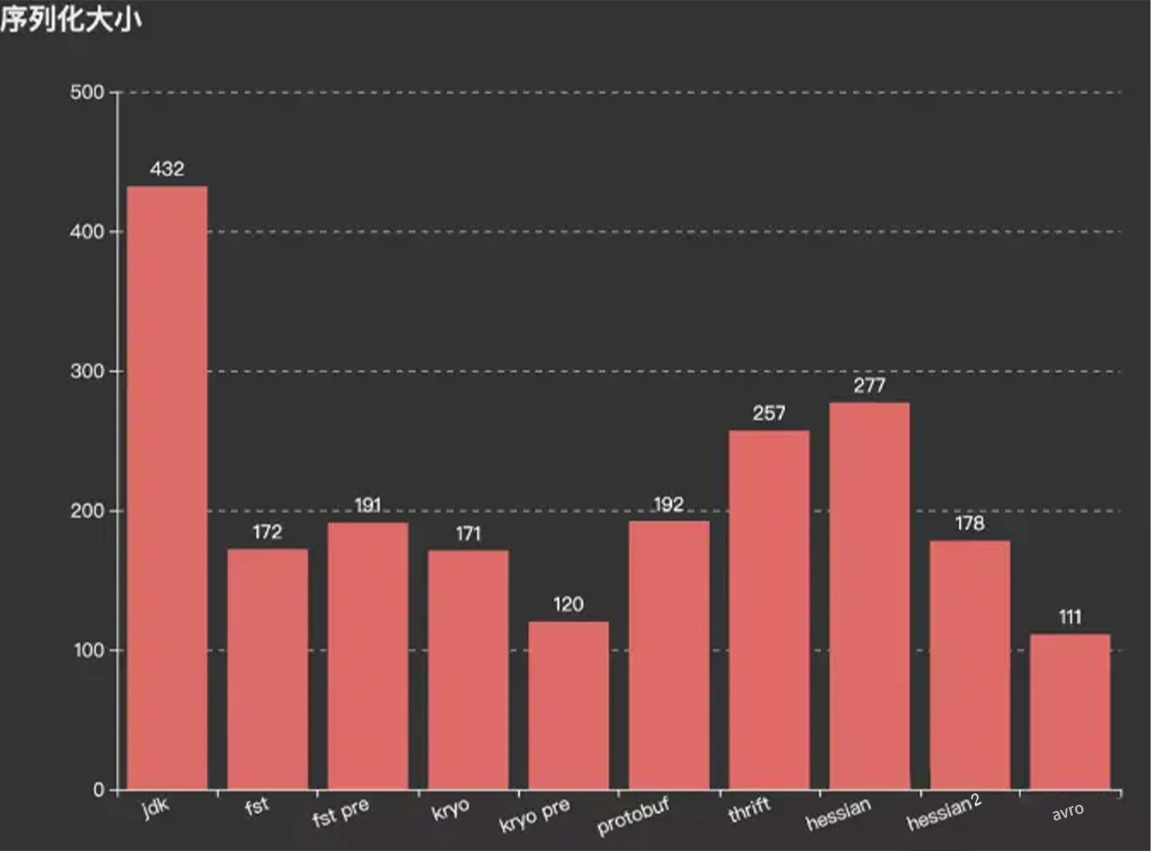
參考及附錄
1.OHC常見參數
| name | 預設值 | 描述 |
|---|---|---|
| keySerializer | 需要開發者實現 | Key序列化實現 |
| valueSerializer | 需要開發者實現 | Value序列化實現 |
| capacity | 64MB | 緩存容量單位B |
| segmentCount | 2倍CPU核心數 | 分段數量 |
| hashTableSize | 8192 | 哈希表的大小 |
| loadFactor | 0.75 | 負載因數 |
| maxEntrySize | capacity/segmentCount | 緩存項最大位元組限制 |
| throwOOME | false | 記憶體不足是否拋出OOM |
| hashAlgorighm | MURMUR3 | hash演算法,可選性MURMUR3、 CRC32, CRC32C (Jdk9以上支持) |
| unlocked | false | 讀寫數據是否加鎖,預設是加鎖 |
| eviction | LRU | 驅逐策略,可選項:LRU、W_TINY_LFU、NONE |
| frequencySketchSize | hashTableSize數量 | W_TINY_ LFU frequency sketch 的大小 |
| edenSize | 0.2 | W_TINY_LFU 驅逐策略下使用 |
2.JNI faster than Unsafe?
https://mail.openjdk.org/pipermail/hotspot-dev/2015-February/017089.html
3.OHC源碼
4.參考文檔
• 序列化框架對比
作者:京東零售 趙雪召
來源:京東雲開發者社區 轉載請註明來源


