
通過實現一個簡易版本的跳錶,可以加深了對Python編程的理解。跳錶是一種跳躍式的數據結構,通過索引層提供快速查找的能力,提高了查找的效率。在實現跳錶的過程中,會更加熟悉了Python的語法和特性,並且可以更加靈活地運用它來解決實際問題。 ...
前言
之前我已經將Python的基本語法與Java進行了比較,相信大家對Python也有了一定的瞭解。我不會選擇去寫一些無用的業務邏輯來加強對Python的理解。相反,我更喜歡通過編寫一些數據結構和演算法來加深自己對Python編程的理解。學習任何語言都一樣。
通過編寫數據結構和演算法,不僅可以加強我自己的思維能力,還能提高對Python編程語言的熟練程度。在這個過程中,我會不斷地優化我的代碼,以提高演算法的效率和性能。我相信通過這種方式,我能夠更好地掌握Python編程,並且在解決實際問題時能夠更加靈活地運用Python的特性和語法。
跳錶
今天我們來使用Python實現一個簡易版本的跳錶。所謂跳錶就是一種跳躍式的數據結構。
假設你是一點陣圖書館管理員,你需要在圖書館的書架上找到一本特定的書。如果圖書館只是一個普通的書架,你需要逐本書進行查找,這樣會花費很多時間和精力。
然而,如果圖書館採用了跳錶這種數據結構,書架上的書被分成了幾個層次,每一層都有一個索引,上面標註了每本書的位置信息。當你需要找到一本書時,你可以先查看最高層的索引,快速定位到可能包含該書的區域,然後再在該區域內根據索引逐步查找,直到找到目標書籍。
這樣,跳錶的索引層就相當於圖書館的書籍分類系統,它提供了一個快速查找的方法。通過索引層,你可以迅速定位到書籍所在的區域,減少了查找的次數和時間。
跳錶主要的思想是利用索引的概念。因此,每個節點除了保存下一個鏈表節點的地址之外,還需要額外存儲索引地址,用於指示下一步要跳轉的地址。它在有序鏈表的基礎上增加了多層索引,以提高查找效率。
而且這適合於讀多寫少的場景。在實現過程中,無論是在插入數據完畢後重新建立索引,還是在插入數據的同時重新建立索引,都會導致之前建立的索引丟棄,浪費了大量時間。而且,如果考慮多線程的情況,情況會更糟糕。寫這種東西時,通常先實現一個簡單版,然後根據各個環節進行優化,逐步改進演算法。因此,我們今天先實現一個簡單版的跳錶。
具體實現
我們先來實現一個簡單版的跳錶,不動態規定步長。我們可以先定義一個固定的步長,比如2。
為了實現跳錶,我們需要定義一個節點的數據結構。這個節點包含以下信息:當前節點的值(value),指向前一個節點的指針(before_node),指向後一個節點的指針(next_node),以及指向索引節點的指針(index_node)。
class SkipNode:
def __init__(self,value,before_node=None,next_node=None,index_node=None):
self.value = value
self.before_node = before_node
self.next_node = next_node
self.index_node = index_node
head = SkipNode(-1)
tail = SkipNode(-1)
為了方便操作,我先生成了兩個特殊節點,一個是頭節點,另一個是尾節點。頭節點作為跳錶的起始點,尾節點作為跳錶的結束點。
數據插入
在跳錶中插入節點時,我們按照從小到大的升序進行排序。插入節點時,無需維護索引節點。一旦完成插入操作,我們需要重新規劃索引節點,以確保跳錶的性能優化。
def insert_node(node):
if head.next_node is None:
head.next_node = node
node.next_node = tail
node.before_node = head
tail.before_node = node
return
temp = head.next_node
# 當遍歷到尾節點時,需要直接插入
while temp.next_node is not None or temp == tail:
if temp.value > node.value or temp == tail:
before = temp.before_node
before.next_node = node
temp.before_node = node
node.before_node = before
node.next_node = temp
break
temp = temp.next_node
re_index()
重建索引
為了重新規劃索引,我們可以先將之前已經規劃好的索引全部刪除。然後,我們可以使用步長為2的方式重新規劃索引。
def re_index():
step = 2
# 用來建立索引的節點
index_temp = head.next_node
# 用來遍歷的節點
temp = head.next_node
while temp.next_node is not None:
temp.index_node = None
if step == 0:
step = 2
index_temp.index_node = temp
index_temp = temp
temp = temp.next_node
step -= 1
查詢節點
查詢:從頭節點開始查詢,根據節點的值與目標值進行比較。如果節點的值小於目標值,則向右移動到下一個節點或者索引節點繼續比較。如果節點的值等於目標值,則找到了目標節點,返回結果。如果節點的值大於目標值,則則說明目標節點不存在。
def search_node(value):
temp = head.next_node
step = 0
while temp.next_node is not None:
step += 1
if value == temp.value:
print(f"該值已找到,經歷了{step}次查詢")
return
elif value < temp.value:
print(f"該值在列表不存在,經歷了{step}次查詢")
return
if temp.index_node is not None and value > temp.index_node.value:
temp = temp.index_node
else:
temp = temp.next_node
print(f"該值在列表不存在,經歷了{step}次查詢")
遍歷
為了方便查看,我特意編寫了一個用於遍歷和查看當前數據的功能,以便更清楚地瞭解數據的結構和內容。
def print_node():
my_list = []
temp = head.next_node
while temp.next_node is not None:
if temp.index_node is not None:
my_dict = {"current_value": temp.value, "index_value": temp.index_node.value}
else:
my_dict = {"current_value": temp.value, "index_value": None} # 設置一個預設值為None
my_list.append(my_dict)
temp = temp.next_node
for item in my_list:
print(item)
查看結果
所有代碼已經準備完畢,現在我們可以在另一個文件中運行並查看跳錶的內容和數據。讓我們快速進行操作一下。
import skipList
import random
for i in range(0,10):
random_number = random.randint(1, 100)
temp = skipList.SkipNode(random_number)
skipList.insert_node(temp)
skipList.print_node()
skipList.search_node(89)
以下是程式的運行結果。為了方便查看,我特意列印了索引節點的值,以告訴你要跳到哪一個節點。
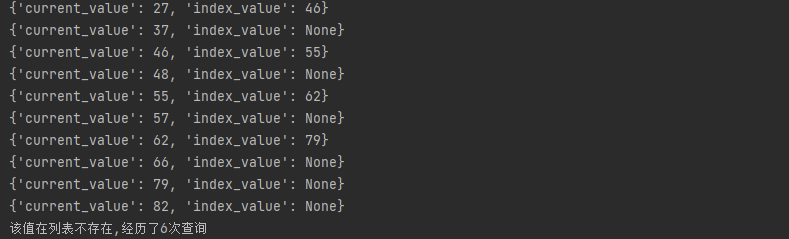
總結
通過實現一個簡易版本的跳錶,可以加深了對Python編程的理解。跳錶是一種跳躍式的數據結構,通過索引層提供快速查找的能力,提高了查找的效率。在實現跳錶的過程中,會更加熟悉了Python的語法和特性,並且可以更加靈活地運用它來解決實際問題。


