
線程池 線程池簡介 線程池(thread pool):一種線程的使用模式。線程過多會帶來調度的開銷,進而影響局部和整體性能。而線程池維護多個線程,等待著監督管理者分派併發執行的任務。這避免了在處理短時間任務時創建和銷毀線程的代價。線程池不僅能夠保證內核的充分使用,還能防止過分調度線程。 10多年前的 ...
go的map在面試時候經常會被問到。
最近看到群里有個被問到為什麼map的每個桶中只裝8個元素?
map 的結構
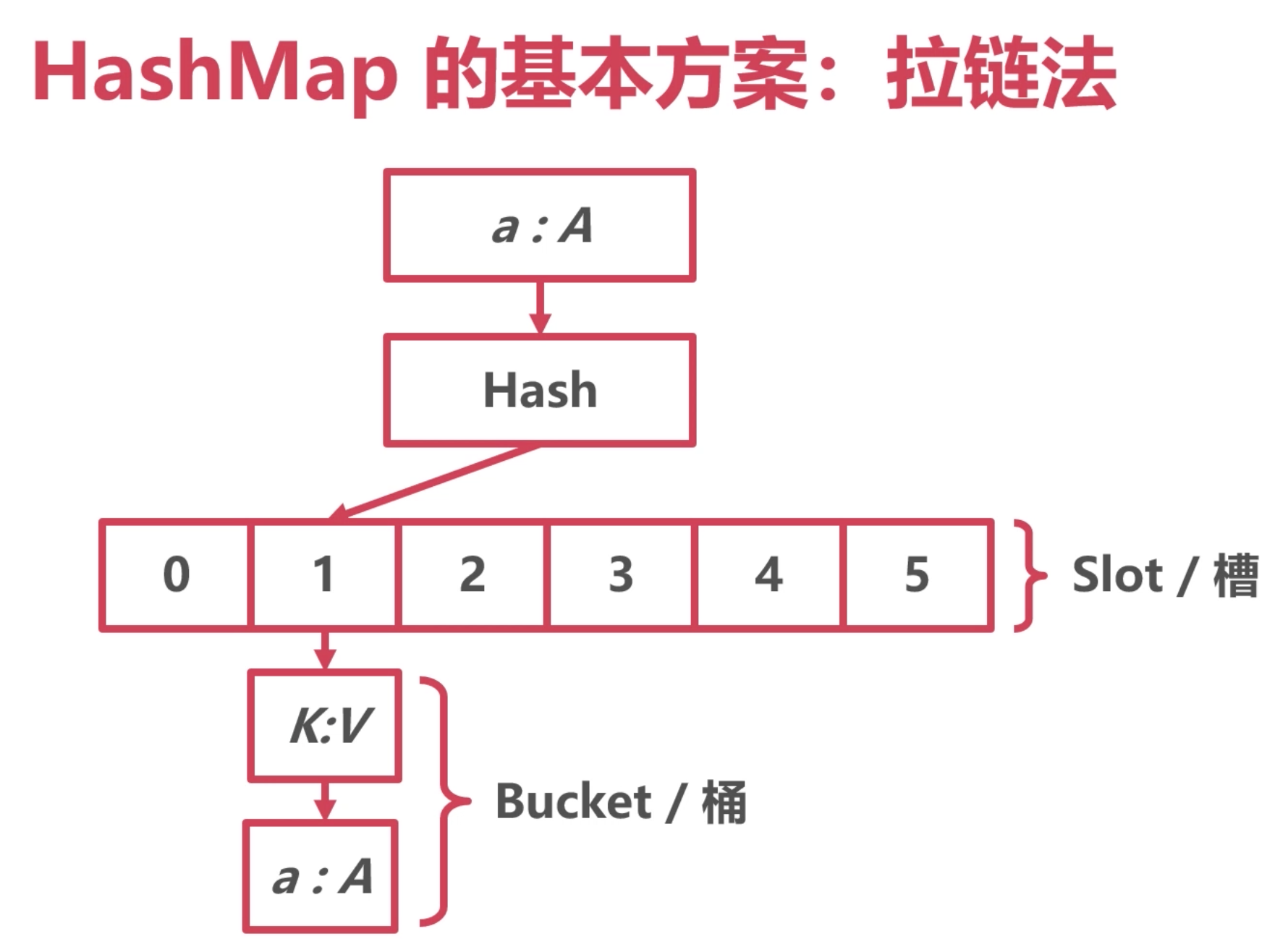
註:解決hash衝突還有一些別的方案:開放地址法 (往目標地址後面放)、再哈希法(再次hash)
底層定義
// A header for a Go map.
type hmap struct {
// 個數 size of map,當使用len方法,返回就是這個值
count int // # live cells == size of map. Must be first (used by len() builtin)
flags uint8
// 桶的以2為底的對數,後面在查找和擴容都用到這個值
B uint8 // log_2 of # of buckets (can hold up to loadFactor * 2^B items)
// 溢出桶的數量 這裡講了 approximate 不是精準的
noverflow uint16 // approximate number of overflow buckets; see incrnoverflow for details
// 哈希的種子,在進行哈希運算演算法是要用到
hash0 uint32 // hash seed
// 桶的數組,是 2^B個數,和B的定義對上了
buckets unsafe.Pointer // array of 2^B Buckets. may be nil if count==0.
// 擴容時用於保存之前 buckets 的欄位
oldbuckets unsafe.Pointer // previous bucket array of half the size, non-nil only when growing
// 指示擴容進度,小於此地址的 buckets 遷移完成
nevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated)
extra *mapextra // optional fields
}
跟進看 buckets的結構:
bucketCnt = abi.MapBucketCount =8
// A bucket for a Go map.
type bmap struct {
tophash [bucketCnt]uint8
// Followed by bucketCnt keys and then bucketCnt elems.
// Followed by an overflow pointer.
}
每個桶 定義了 有8個哈希值的容量。 這裡就解釋了為什麼一個桶只能放八個元素。
至於元素的存儲,在這裡沒有定義,主要是不能寫死類型。
但是在編譯期間,會把要存儲的key 和value寫進來;
最後還跟了一個 溢出指針。
整體的結構是這樣:

bmap的數量根據B確定,如果B為2,那麼bmap為4個,圖中B為3。
每個bmap容量為8,超過8個就要用到溢出桶。 意味著每個桶最多只能存儲8個元素。
map的創建
func main() {
m := make(map[string]string, 10)
fmt.Println(m)
}
看下是如何創建的:
通過看下彙編,發現最終調用了runtime.makemap()方法
go build -gcflags -S main.go
MOVL $10, BX
XORL CX, CX
PCDATA $1, $0
NOP
CALL runtime.makemap(SB)
func makemap(t *maptype, hint int, h *hmap) *hmap {
mem, overflow := math.MulUintptr(uintptr(hint), t.Bucket.Size_)
// initialize Hmap 初始化 hmap
if h == nil {
h = new(hmap)
}
h.hash0 = fastrand()
// 對B進行賦值
B := uint8(0)
for overLoadFactor(hint, B) {
B++
}
h.B = B
if h.B != 0 {
var nextOverflow *bmap
// 這裡創建一個bucket的數組,而且也創建了一些溢出桶,用extra 存儲。
h.buckets, nextOverflow = makeBucketArray(t, h.B, nil)
if nextOverflow != nil {
h.extra = new(mapextra)
h.extra.nextOverflow = nextOverflow
}
}
return h
}
這裡可以返回去看下 bmap 的最後一個參數:
extra *mapextra // optional fields
type mapextra struct {
overflow *[]*bmap
oldoverflow *[]*bmap
nextOverflow *bmap
}
通過上面能看到,給 h.extra.nextOverflow = nextOverflow 存放了下一個可用的溢出桶的位置。

map的訪問
1. 計算桶位
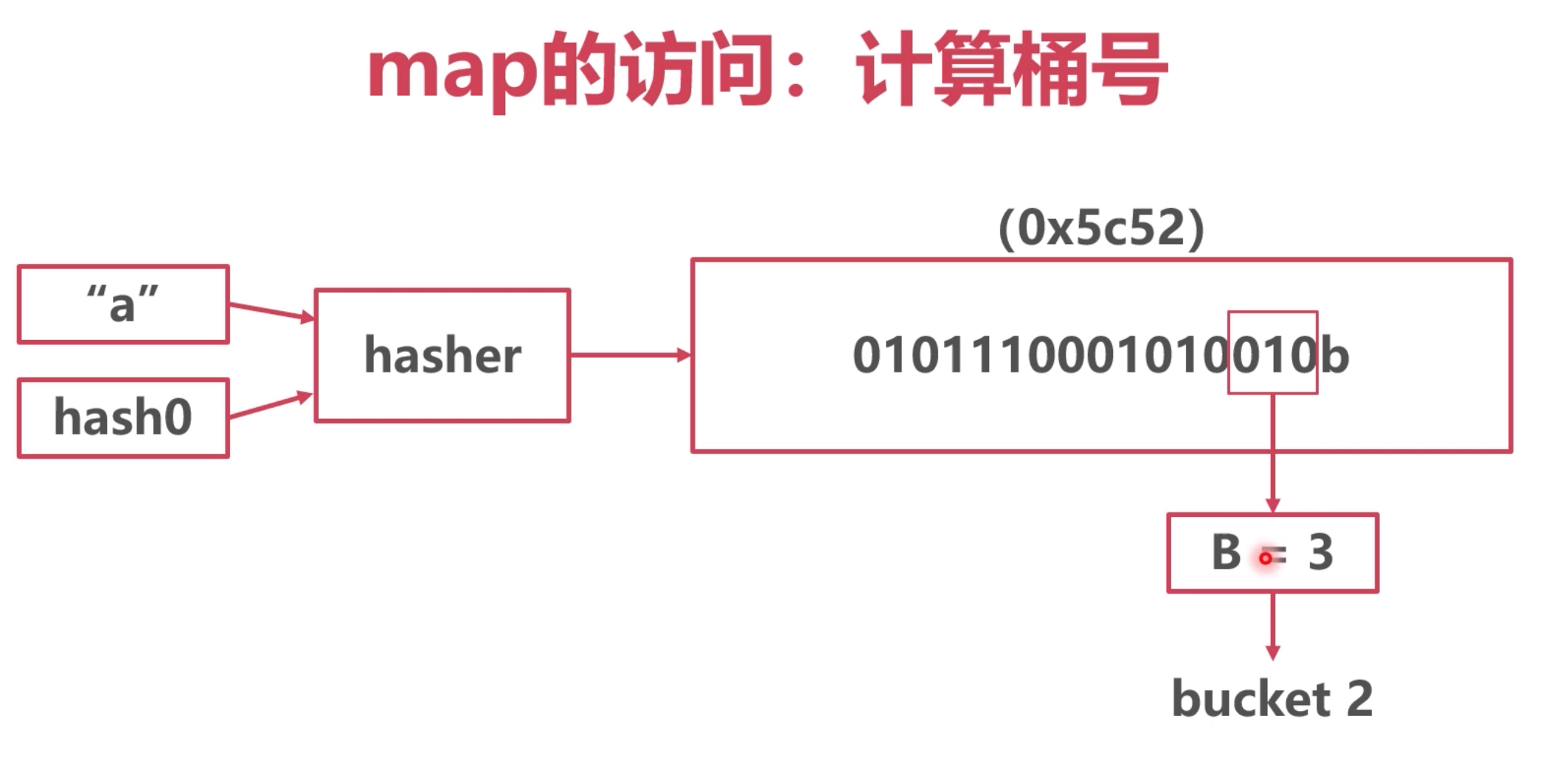
- 通過
key + hash0種子 通過hash演算法,等到一串32位的字元串。具體多少位與操作系統有關。
- 取哈希值的後B位。圖中B為3,得到了 010 就是 2號桶。
- 得到的值 就是 桶的位置。
2. 訪問進行匹配

這裡有個 tophash,只存儲了hash值的前8位。map裡面挺多8的。
開始對比key為a的哈希值的前8位,如果找到了,則需要對比下key,因為前8位可能會有一樣的
如果不匹配,則繼續往後找,溢出桶,找到則返回值。
如果都找不到,則沒有這個key。
map寫入

基本和查找類似。
map擴容
當map 溢出桶太多時會導致嚴重的性能下降,就需要對map的桶進行擴容。
可能會觸發擴容的情況: 後面會具體解釋
裝載因數超過 6.5(平均每個槽6.5個key)
使用了太多溢出桶(溢出桶超過了普通桶)
具體實現在 runtime.mapassign()中:
//截取其中的關鍵代碼:
// If we hit the max load factor or we have too many overflow buckets,
// and we're not already in the middle of growing, start growing.
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
goto again // Growing the table invalidates everything, so try again
}
// overLoadFactor reports whether count items placed in 1<<B buckets is over loadFactor.
func overLoadFactor(count int, B uint8) bool {
return count > bucketCnt && uintptr(count) > loadFactorNum*(bucketShift(B)/loadFactorDen)
}
loadFactor:=count / (2^B) 即 裝載因數 = map中元素的個數 / map中當前桶的個數
通過計算公式我們可以得知,裝載因數是指當前map中,每個桶中的平均元素個數。
如果沒有溢出桶,那麼一個桶中最多有8個元素,當平均每個桶中的數據超過了6.5個,那就意味著當前容量要不足了,發生擴容。
func tooManyOverflowBuckets(noverflow uint16, B uint8) bool {
// If the threshold is too low, we do extraneous work.
// If the threshold is too high, maps that grow and shrink can hold on to lots of unused memory.
// "too many" means (approximately) as many overflow buckets as regular buckets.
// See incrnoverflow for more details.
if B > 15 {
B = 15
}
// The compiler doesn't see here that B < 16; mask B to generate shorter shift code.
return noverflow >= uint16(1)<<(B&15)
}
當 B < 15 時,如果overflow的bucket數量超過 2^B。
當 B >= 15 時,overflow的bucket數量超過 2^15。
map的擴容的類型
- 等量擴容:數據不多但是溢出桶太多了 (整理)
- 翻倍擴容:數據太多了
第一步:
創建一組新桶
oldbuckets 指向原有的桶數組
buckets 指向新的桶數組
map標記為擴容狀態
實現源碼:
func hashGrow(t *maptype, h *hmap) {
bigger := uint8(1)
if !overLoadFactor(h.count+1, h.B) {
bigger = 0
h.flags |= sameSizeGrow
}
oldbuckets := h.buckets
// 新建桶
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)
flags := h.flags &^ (iterator | oldIterator)
if h.flags&iterator != 0 {
flags |= oldIterator
}
//更改B的值
h.B += bigger
// 更改map狀態
h.flags = flags
// oldbuckets 指向原來的
h.oldbuckets = oldbuckets
// buckets 指向新桶
h.buckets = newbuckets
h.nevacuate = 0
h.noverflow = 0
// 賦值新的溢出桶
if h.extra != nil && h.extra.overflow != nil {
if h.extra.oldoverflow != nil {
throw("oldoverflow is not nil")
}
h.extra.oldoverflow = h.extra.overflow
h.extra.overflow = nil
}
if nextOverflow != nil {
if h.extra == nil {
h.extra = new(mapextra)
}
h.extra.nextOverflow = nextOverflow
}
}
步驟2
將所有的數據從!日桶驅逐到新桶
採用漸進式驅逐
每次操作一個日桶時,將1日桶數據驅逐到新桶
讀取時不進行驅逐,只判斷讀取新桶還是舊桶
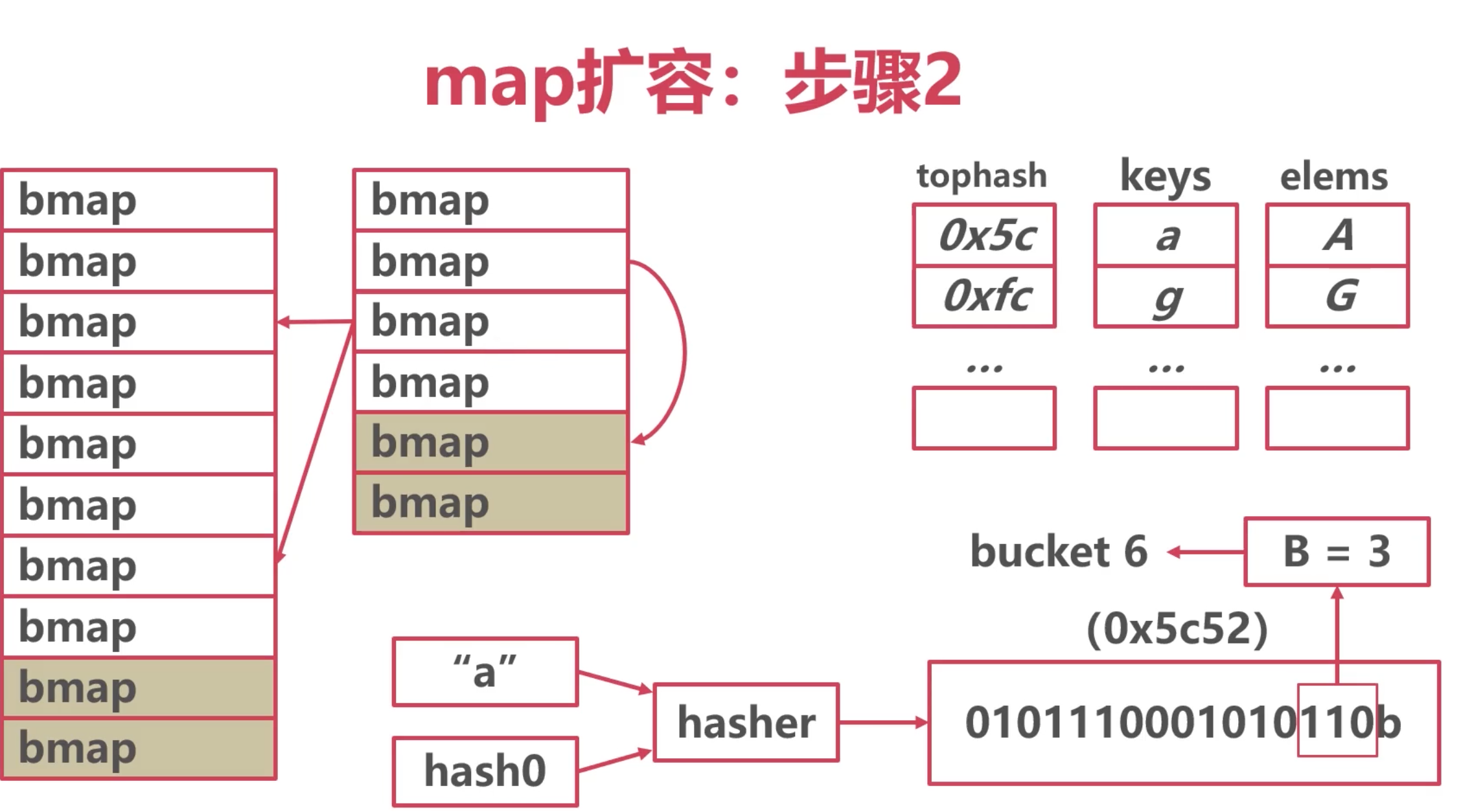
例如圖中:原本的2號桶中的數據,要麼去新的2號010,要麼去新的6號桶。110
這部分的代碼也在map.go中
在 mapassign中有這個邏輯:
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
if h.growing() {
growWork(t, h, bucket)
}
}
func growWork(t *maptype, h *hmap, bucket uintptr) {
// 具體的邏輯就在這個 evacuate中實現的。
evacuate(t, h, bucket&h.oldbucketmask())
// evacuate one more oldbucket to make progress on growing
if h.growing() {
evacuate(t, h, h.nevacuate)
}
}
步驟3
所有的日桶驅逐完成後
oldbuckets回收


