
事務的底層原理 在事務的實現機制上,MySQL 採用的是 WAL:Write-ahead logging,預寫式日誌,機制來實現的。 在使用 WAL 的系統中,所有的修改都先被寫入到日誌中,然後再被應用到系統中。通常包含 redo 和 undo 兩部分信息。 為什麼需要使用 WAL,然後包含 red ...
事務的底層原理
在事務的實現機制上,MySQL 採用的是 WAL:Write-ahead logging,預寫式日誌,機制來實現的。
在使用 WAL 的系統中,所有的修改都先被寫入到日誌中,然後再被應用到系統中。通常包含 redo 和 undo 兩部分信息。
為什麼需要使用 WAL,然後包含 redo 和 undo 信息呢?舉個例子,如果一個系統直接將變更應用到系統狀態中,那麼在機器掉電重啟之後系統需要知道操作是成功了,還是只有部分成功或者是失敗了。如果使用了 WAL,那麼在重啟之後系統可以通過比較日誌和系統狀態來決定是繼續完成操作還是撤銷操作。
redo log 稱為重做日誌,每當有操作時,在數據變更之前將操作寫入 redo log,這樣當發生掉電之類的情況時系統可以在重啟後繼續操作。
undo log 稱為撤銷日誌,當一些變更執行到一半無法完成時,可以根據撤銷日誌恢復到變更之間的狀態。
MySQL 中用 redo log 來在系統 Crash 重啟之類的情況時修複數據,而 undo log 來保證事務的原子性。
事務 id
一個事務可以是一個只讀事務,或者是一個讀寫事務:可以通過 START TRANSACTION READ ONLY 語句開啟一個只讀事務。
在只讀事務中不可以對普通的表進行增、刪、改操作,但可以對用戶臨時表做增、刪、改操作。
可以通過 START TRANSACTION READ WRITE 語句開啟一個讀寫事務,或者使用 BEGIN、START TRANSACTION 語句開啟的事務預設也算是讀寫事務。
在讀寫事務中可以對錶執行增刪改查操作。
如果某個事務執行過程中對某個表執行了增、刪、改操作,那麼 InnoDB 存儲引擎就會給它分配一個獨一無二的事務 id,針對 MySQL 5.7 分配方式如下:
- 對於只讀事務來說,只有在它第一次對某個用戶創建的臨時表執行增、刪、改操作時才會為這個事務分配一個事務 id,否則的話是不分配事務 id 的。
- 對於讀寫事務來說,只有在它第一次對某個表執行增、刪、改操作時才會為這個事務分配一個事務 id,否則的話也是不分配事務 id 的。
- 有的時候雖然開啟了一個讀寫事務,但是在這個事務中全是查詢語句,並沒有執行增、刪、改的語句,那也就意味著這個事務並不會被分配一個事務 id。
這個事務 id 本質上就是一個數字,它的分配策略和隱藏列 row_id 的分配策略大抵相同,具體策略如下:
- 伺服器會在記憶體中維護一個全局變數,每當需要為某個事務分配一個事務 id 時,就會把該變數的值當作事務 id 分配給該事務,並且把該變數自增 1。
- 每當這個變數的值為 256 的倍數時,就會將該變數的值刷新到系統表空間的頁號為 5 的頁面中一個稱之為 Max Trx ID 的屬性處,這個屬性占用 8 個位元組的存 儲空間。
- 當系統下一次重新啟動時,會將上邊提到的 Max Trx ID 屬性載入到記憶體中,將該值加上 256 之後賦值給全局變數,因為在上次關機時該全局變數的值可能大於Max Trx ID 屬性值。
- 這樣就可以保證整個系統中分配的事務 id 值是一個遞增的數字。先被分配 id 的事務得到的是較小的事務 id,後被分配 id 的事務得到的是較大的事務 id。
mvcc
全稱 Multi-Version Concurrency Control,即多版本併發控制,主要是為了提高資料庫的併發性能。
同一行數據平時發生讀寫請求時,會上鎖阻塞住。但 MVCC 用更好的方式去處理讀寫請求,做到在發生讀寫請求衝突時不用加鎖。
這個讀是指的快照讀,而不是當前讀,當前讀是一種加鎖操作,是悲觀鎖。
MVCC 原理
在事務併發執行遇到的問題如下:
- 臟讀:如果一個事務讀到了另一個未提交事務修改過的數據,那就意味著發生了臟讀;
- 不可重覆讀:如果一個事務只能讀到另一個已經提交的事務修改過的數據,並且其他事務每對該數據進行一次修改並提交後,該事務都能查詢得到最新值,那就意味著發生了不可重覆讀;
- 幻讀:如果一個事務先根據某些條件查詢出一些記錄,之後另一個事務又向表中插入了符合這些條件的記錄,原先的事務再次按照該條件查詢時,能把另一個事務插入的記錄也讀出來,那就意味著發生了幻讀,幻讀強調的是一個事務按照某個相同條件多次讀取記錄時,後讀取時讀到了之前沒有讀到的記錄,幻讀只是重點強調了讀取到了之前讀取沒有獲取到的記錄。
MySQL 在 REPEATABLE READ 隔離級別下,是可以很大程度避免幻讀問題的發生的。
版本鏈
對於使用 InnoDB 存儲引擎的表來說,它的聚簇索引記錄中都包含兩個必要的隱藏列:
- trx_id:每次一個事務對某條聚簇索引記錄進行改動時,都會把該事務的事務 id 賦值給 trx_id 隱藏列;
- roll_pointer:每次對某條聚簇索引記錄進行改動時,都會把舊的版本寫入到 undo 日誌中,然後這個隱藏列就相當於一個指針,可以通過它來找到該記錄修 改前的信息;
演示
-- 創建表
CREATE TABLE mvcc_test (
id INT,
name VARCHAR(100),
domain varchar(100),
PRIMARY KEY (id)
) Engine=InnoDB CHARSET=utf8;
-- 添加數據
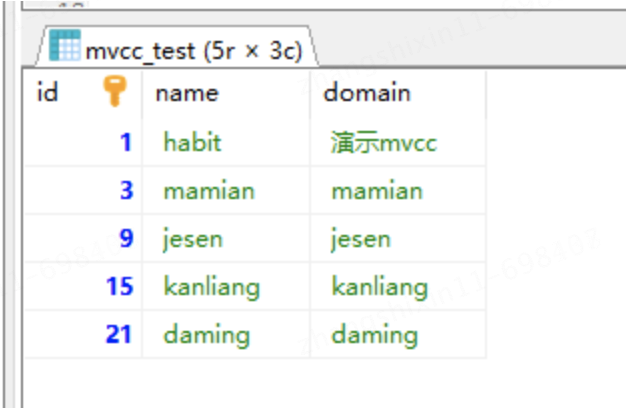
INSERT INTO mvcc_test VALUES(1, 'habit', '演示mvcc');
假設插入該記錄的事務 id=50,那麼該條記錄的展示如圖:
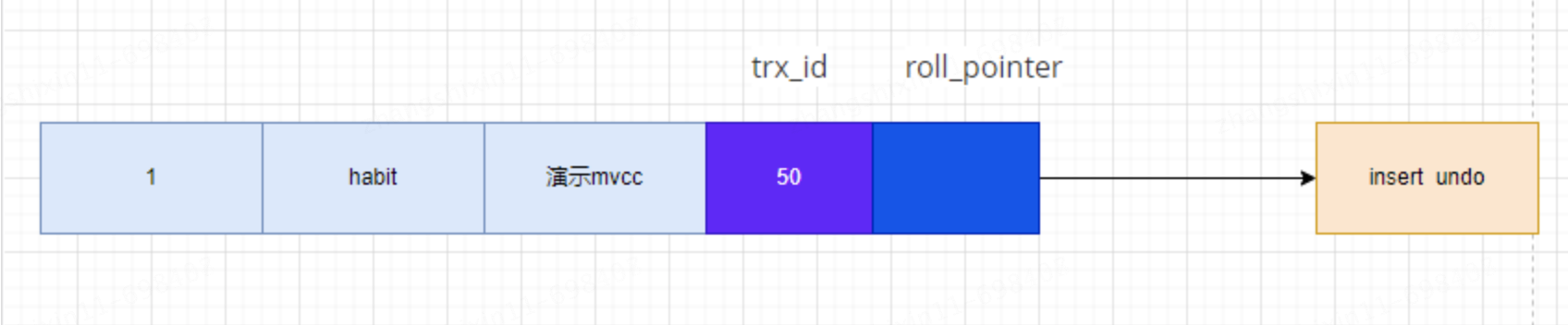
假設之後兩個事務 id 分別為 70、90 的事務對這條記錄進行 UPDATE 操作。
| trx_id=70 | trx_id=90 |
|---|---|
| begin | |
| begin | |
| update mvcc_test set name='habit_trx_id_70_01' where id=1 | |
| update mvcc_test set name='habit_trx_id_70_02' where id=1 | |
| commit | |
| update mvcc_test set name='habit_trx_id_90_01' where id=1 | |
| update mvcc_test set name='habit_trx_id_90_02' where id=1 | |
| commit |
每次對記錄進行改動,都會記錄一條 undo 日誌,每條 undo 日誌也都有一個 roll_pointer 屬性,可以將這些 undo 日誌都連起來,串成一個鏈表。
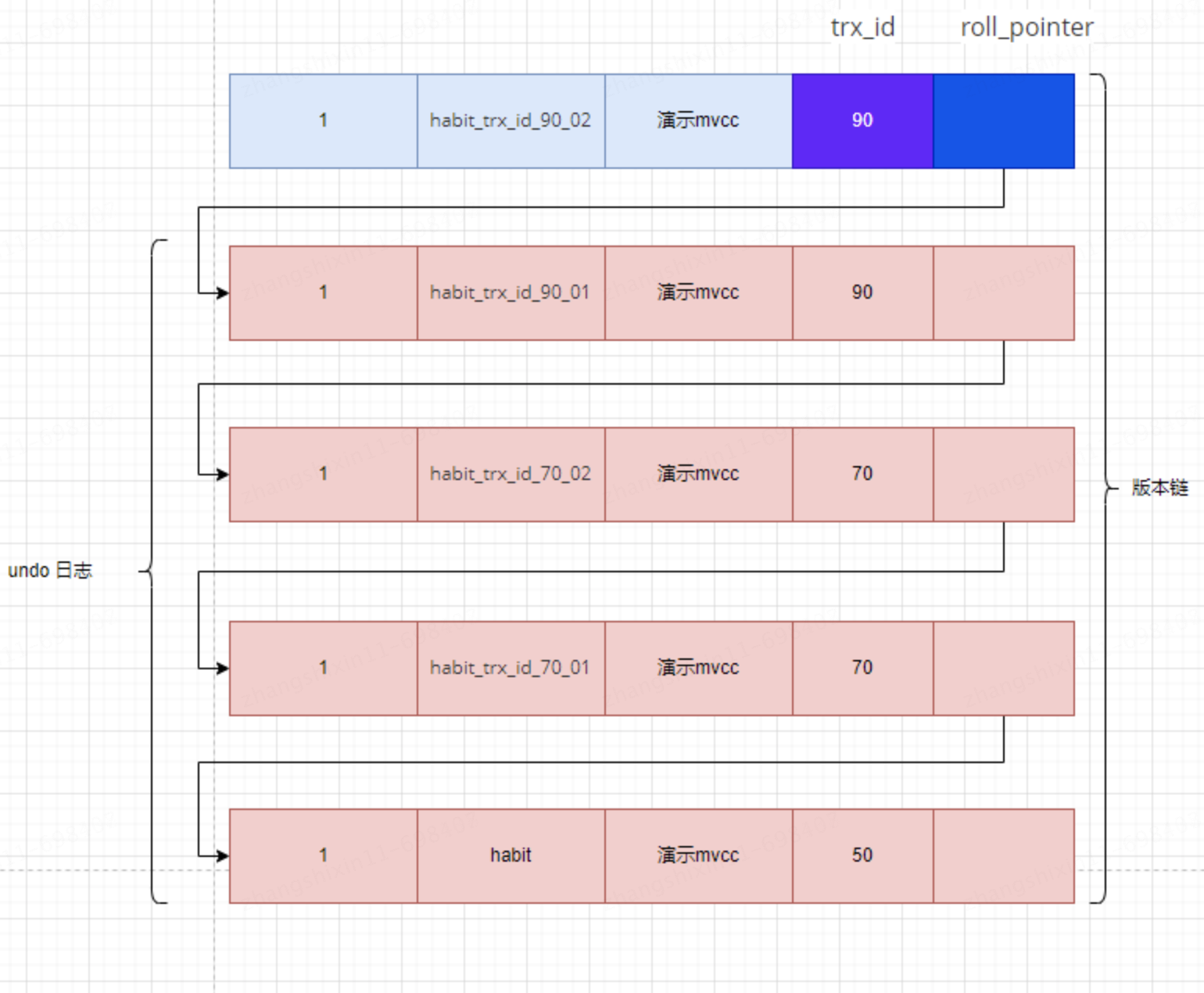
對該記錄每次更新後,都會將舊值放到一條 undo 日誌中,就算是該記錄的一個舊版本,隨著更新次數的增多,所有的版本都會被 roll_pointer 屬性連接成一個鏈表,把這個鏈表稱之為版本鏈,版本鏈的頭節點就是當前記錄最新的值。另外,每個版本中還包含生成該版本時對應的事務 id。於是可以利用這個記錄的版本鏈來控制併發事務訪問相同記錄的行為,那麼這種機制就被稱之為:多版本併發控制,即 MVCC。
ReadView
對於使用 READ UNCOMMITTED 隔離級別的事務來說,由於可以讀到未提交事務修改過的記錄,所以直接讀取記錄的最新版本就好了。
對於使用 SERIALIZABLE 隔離級別的事務來說,InnoDB 使用加鎖的方式來訪問記錄。
對於使用 READ COMMITTED 和 REPEATABLE READ 隔離級別的事務來說,都必須保證讀到已經提交了的事務修改過的記錄,也就是說假如另一個事務已經修改了記錄但是尚未提交,是不能直接讀取最新版本的記錄的,核心問題就是:READ COMMITTED 和 REPEATABLE READ 隔離級別在不可重覆讀和幻讀上的區別是從哪裡來的,其實結合前面的知識,這兩種隔離級別關鍵是需要判斷一下版本鏈中的哪個版本是當前事務可見的。
為此,InnoDB 提出了一個 ReadView 的概念,這個 ReadView 中主要包含 4 個比較重要的內容:
- m_ids:表示在生成 ReadView 時當前系統中活躍的讀寫事務的事務id 列表;
- min_trx_id:表示在生成 ReadView 時當前系統中活躍的讀寫事務中最小的事務 id,也就是 m_ids 中的最小值;
- max_trx_id:表示在生成 ReadView 時系統中應該分配給下一個事務的 id 值,註:max_trx_id 並不是 m_ids 中的最大值,事務 id 是遞增分配的。比方說現在有 id 為 1,2,3 這三個事務,之後 id 為 3 的事務提交了。那麼一個新的讀事務在生成 ReadView 時,m_ids 就包括 1 和 2,min_trx_id 的值就是 1,max_trx_id 的值就是 4;
- creator_trx_id:表示生成該 ReadView 的事務的事務 id;
有了這個 ReadView,這樣在訪問某條記錄時,只需要按照下邊的步驟判斷記錄的某個版本是否可見:
- 如果被訪問版本的 trx_id 屬性值與 ReadView 中的 creator_trx_id 值相同,意味著當前事務在訪問它自己修改過的記錄,所以該版本可以被當前事務訪問;
- 如果被訪問版本的 trx_id 屬性值小於 ReadView 中的 min_trx_id 值,表明生成該版本的事務在當前事務生成 ReadView 前已經提交,所以該版本可以被當前事務訪問;
- 如果被訪問版本的 trx_id 屬性值大於或等於 ReadView 中的 max_trx_id 值,表明生成該版本的事務在當前事務生成 ReadView 後才開啟,所以該版本不可以被當前事務訪問;
- 如果被訪問版本的 trx_id 屬性值在 ReadView 的 min_trx_id 和 max_trx_id之間 min_trx_id < trx_id < max_trx_id,那就需要判斷一下 trx_id 屬性值是不是在 m_ids 列表中,如果在,說明創建 ReadView 時生成該版本的事務還是活躍的,該版本不可以被訪問;如果不在,說明創建 ReadView 時生成該版本的事務已經被提交,該版本可以被訪問;
- 如果某個版本的數據對當前事務不可見的話,那就順著版本鏈找到下一個版本的數據,繼續按照上邊的步驟判斷可見性,依此類推,直到版本鏈中的最後一個版本。如果最後一個版本也不可見的話,那麼就意味著該條記錄對該事務完全不可見,查詢結果就不包含該記錄;
在 MySQL 中,READ COMMITTED 和 REPEATABLE READ 隔離級別的一個非常大的區別就是它們生成 ReadView 的時機不同。
還是以表 mvcc_test 為例,假設現在表 mvcc_test 中只有一條由事務 id 為 50 的事務插入的一條記錄,接下來看一下 READ COMMITTED 和 REPEATABLE READ 所謂的生成 ReadView 的時機不同到底不同在哪裡。
READ COMMITTED: 每次讀取數據前都生成一個 ReadView;
比方說現在系統里有兩個事務id 分別為 70、90 的事務在執行:
-- T 70
UPDATE mvcc_test SET name = 'habit_trx_id_70_01' WHERE id = 1;
UPDATE mvcc_test SET name = 'habit_trx_id_70_02' WHERE id = 1;
此時表 mvcc_test 中 id 為 1 的記錄得到的版本鏈表如下所示:

假設現在有一個使用 READ COMMITTED 隔離級別的事務開始執行:
-- 使用 READ COMMITTED 隔離級別的事務
BEGIN;
-- SELECE1:Transaction 70、90 未提交
SELECT * FROM mvcc_test WHERE id = 1;
-- 得到的列 name 的值為'habit'
這個 SELECE1 的執行過程如下:
在執行 SELECT 語句時會先生成一個 ReadView,ReadView 的 m_ids 列表的內容就是[70, 90],min_trx_id 為 70,max_trx_id 為 91,creator_trx_id 為 0。
然後從版本鏈中挑選可見的記錄,從圖中可以看出,最新版本的列 name 的內容是 habit_trx_id_70_02,該版本的 trx_id 值為 70,在 m_ids 列表內,所以不符合可見性要求第 4 條:**如果被訪問版本的 trx_id 屬性值在 ReadView 的 min_trx_id 和 max_trx_id之間 min_trx_id < trx_id < max_trx_id,那就需要判斷一下trx_id 屬性值是不是在 m_ids 列表中,如果在,說明創建 ReadView 時生成該版本的事務還是活躍的,該版本不可以被訪問;如果不在,說明創建 ReadView 時生成該版本的事務已經被提交,該版本可以被訪問。**根據 roll_pointer 跳到下一個版本。
下一個版本的列 name 的內容是 habit_trx_id_70_01,該版本的 trx_id 值也為 70,也在 m_ids 列表內,所以也不符合要求,繼續跳到下一個版本。
下一個版本的列 name 的內容是 habit,該版本的 trx_id 值為 50,小於 ReadView 中的 min_trx_id 值,所以這個版本是符合要求的第 2 條:如果被訪問版本的 trx_id 屬性值小於 ReadView 中的 min_trx_id 值,表明生成該版本的事務在當前事務生成 ReadView 前已經提交,所以該版本可以被當前事務訪問。最後返回的版本就是這條列 name 為 habit 的記錄。
之後,把事務 id 為 70 的事務提交一下,然後再到事務 id 為 90 的事務中更新一下表 mvcc_test 中 id 為 1 的記錄:
-- T 90
UPDATE mvcc_test SET name = 'habit_trx_id_90_01' WHERE id = 1;
UPDATE mvcc_test SET name = 'habit_trx_id_90_02' WHERE id = 1;
此時表 mvcc 中 id 為 1 的記錄的版本鏈就長這樣:
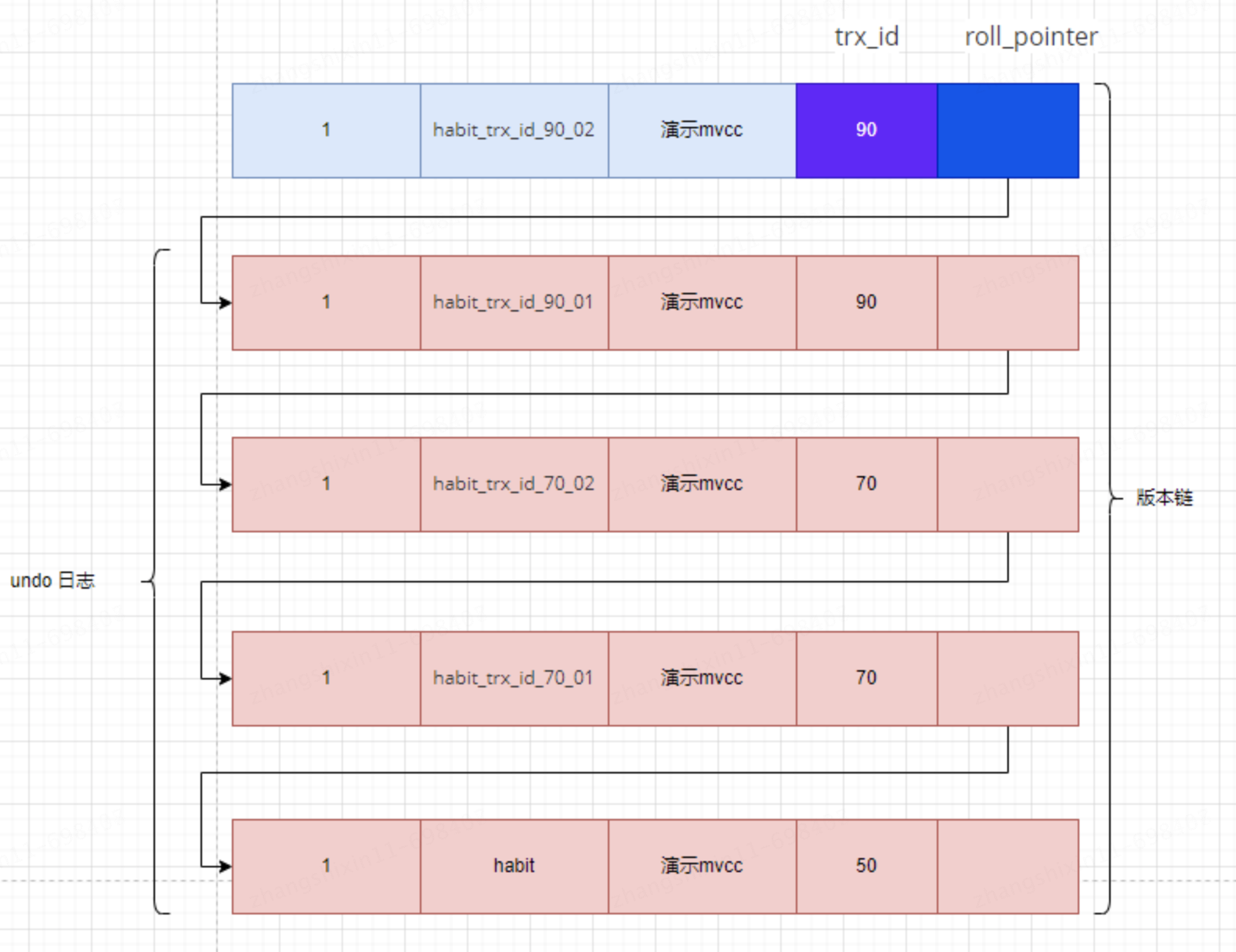
然後再到剛纔使用 READ COMMITTED 隔離級別的事務中繼續查找這個 id 為 1 的記錄,如下:
-- 使用 READ COMMITTED 隔離級別的事務
BEGIN;
-- SELECE1:Transaction 70、90 均未提交
SELECT * FROM mvcc_test WHERE id = 1; -- 得到的列 name 的值為'habit'
-- SELECE2:Transaction 70 提交,Transaction 90 未提交
SELECT * FROM mvcc_test WHERE id = 1; -- 得到的列 name 的值為'habit_trx_id_70_02'
這個SELECE2 的執行過程如下:
在執行 SELECT 語句時又會單獨生成一個 ReadView,該 ReadView 的 m_ids 列表的內容就是[90],min_trx_id 為90,max_trx_id 為 91,creator_trx_id 為 0。
然後從版本鏈中挑選可見的記錄,從圖中可以看出,最新版本的列 name 的內容是 habit_trx_id_90_02,該版本的 trx_id 值為 90,在 m_ids 列表內,所以不符合可見性要求,根據 roll_pointer 跳到下一個版本。
下一個版本的列 name 的內容是 habit_trx_id_90_01,該版本的 trx_id 值為 90,也在 m_ids 列表內,所以也不符合要求,繼續跳到下一個版本。
下一個版本的列 name 的內容是 habit_trx_id_70_02,該版本的 trx_id 值為 70,小於 ReadView 中的 min_trx_id 值 90,所以這個版本是符合要求的,最後返回這個版本中列 name 為 habit_trx_id_70_02 的記錄。
以此類推,如果之後事務 id 為 90 的記錄也提交了,再次在使用 READ COMMITTED 隔離級別的事務中查詢表 mvcc_test 中 id 值為 1 的記錄時,得到的結果就是 habit_trx_id_90_02 了。
總結:使用 READ COMMITTED 隔離級別的事務在每次查詢開始時都會生成一個獨立的 ReadView。
**REPEATABLE READ:**在第一次讀取數據時生成一個 ReadView;
對於使用 REPEATABLE READ 隔離級別的事務來說,只會在第一次執行查詢語句時生成一個 ReadView,之後的查詢就不會重覆生成了。
比方說現在系統里有兩個事務id 分別為 70、90 的事務在執行:
-- T 70
UPDATE mvcc_test SET name = 'habit_trx_id_70_01' WHERE id = 1;
UPDATE mvcc_test SET name = 'habit_trx_id_70_02' WHERE id = 1;
此時表 mvcc_test 中 id 為 1 的記錄得到的版本鏈表如下所示:
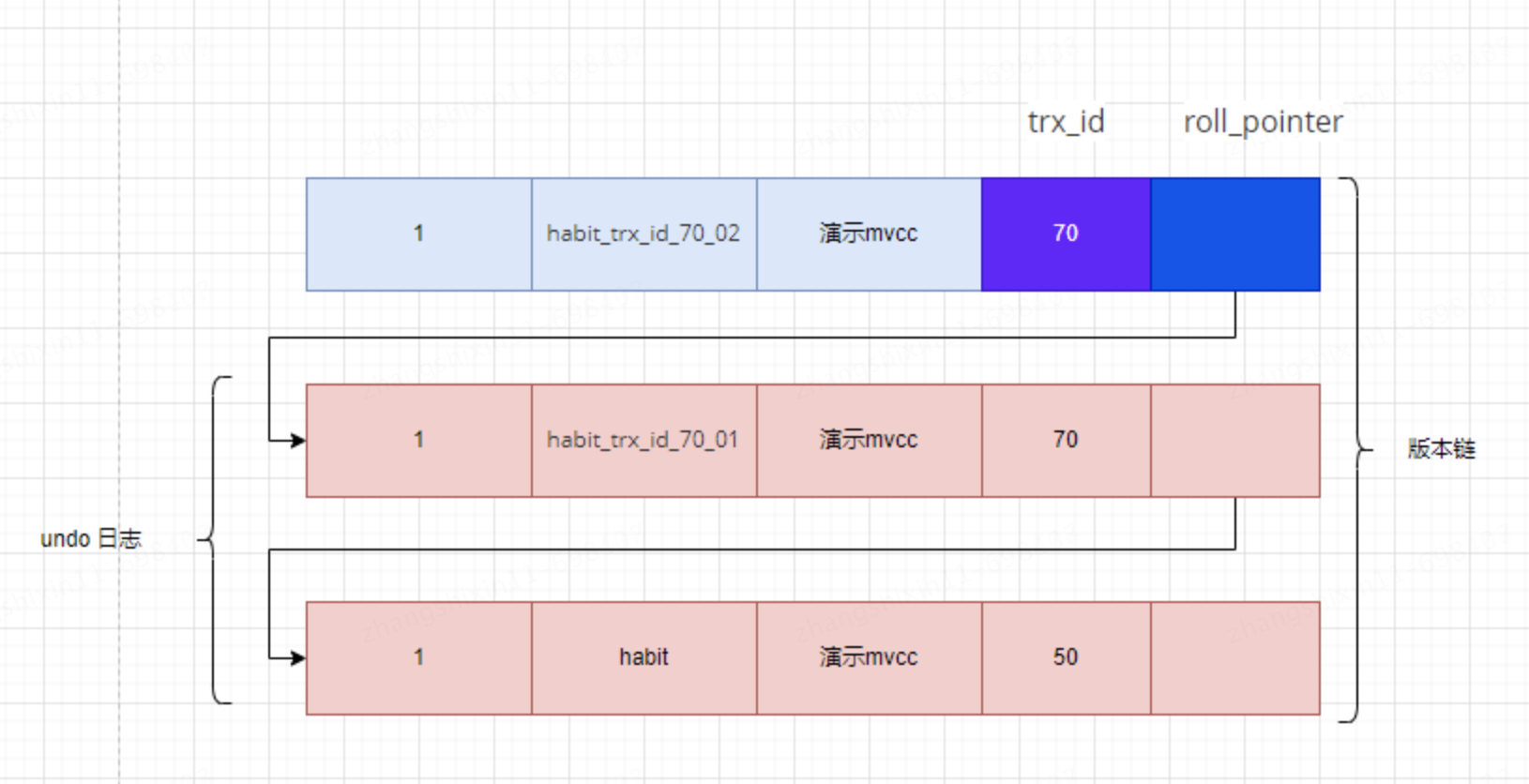
假設現在有一個使用 REPEATABLE READ 隔離級別的事務開始執行:
-- 使用 REPEATABLE READ 隔離級別的事務
BEGIN;
-- SELECE1:Transaction 70、90 未提交
SELECT * FROM mvcc_test WHERE id = 1; -- 得到的列name 的值為'habit'
這個 SELECE1 的執行過程如下:
在執行 SELECT 語句時會先生成一個 ReadView,ReadView 的 m_ids 列表的內容就是[70, 90],min_trx_id 為 70,max_trx_id 為 91,creator_trx_id 為 0。
然後從版本鏈中挑選可見的記錄,從圖中可以看出,最新版本的列 name 的內容是 habit_trx_id_70_02,該版本的 trx_id 值為 70,在 m_ids 列表內,所以不符合可見性要求,根據 roll_pointer 跳到下一個版本。
下一個版本的列 name 的內容是 habit_trx_id_70_01,該版本的 trx_id 值也為 70,也在 m_ids 列表內,所以也不符合要求,繼續跳到下一個版本。
下一個版本的列 name 的內容是 habit,該版本的 trx_id 值為 50,小於 ReadView 中的 min_trx_id 值,所以這個版本是符合要求的,最後返回的就是這條列name 為 habit 的記錄。
之後,把事務 id 為 70 的事務提交一下,然後再到事務 id 為 90 的事務中更新一下表 mvcc_test 中 id 為 1 的記錄:
-- 使用 REPEATABLE READ 隔離級別的事務
BEGIN;
UPDATE mvcc_test SET name = 'habit_trx_id_90_01' WHERE id = 1;
UPDATE mvcc_test SET name = 'habit_trx_id_90_02' WHERE id = 1;
此刻,表 mvcc_test 中 id 為 1 的記錄的版本鏈就長這樣:
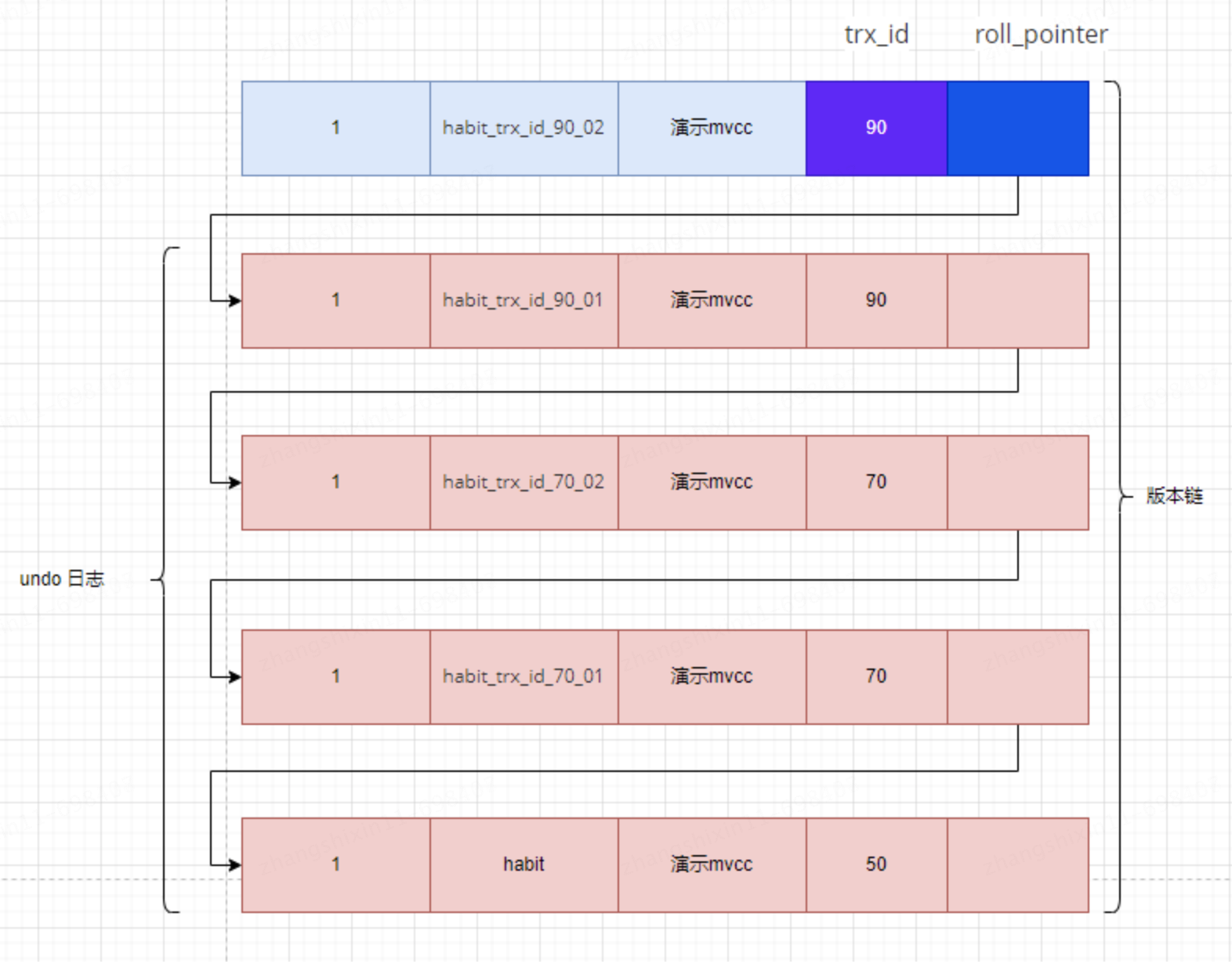
然後再到剛纔使用 REPEATABLE READ 隔離級別的事務中繼續查找這個 id 為 1 的記錄,如下:
-- 使用 REPEATABLE READ 隔離級別的事務
BEGIN;
-- SELECE1:Transaction 70、90 均未提交
SELECT * FROM mvcc_test WHERE id = 1; -- 得到的列 name 的值為'habit'
-- SELECE2:Transaction 70 提交,Transaction 90 未提交
SELECT * FROM mvcc_test WHERE id = 1; -- 得到的列 name 的值為'habit'
這個 SELECE2 的執行過程如下:
因為當前事務的隔離級別為 REPEATABLE READ,而之前在執行 SELECE1 時已經生成過 ReadView 了,所以此時直接復用之前的 ReadView,之前的 ReadView的 m_ids 列表的內容就是[70, 90],min_trx_id 為 70,max_trx_id 為 91, creator_trx_id 為 0。
然後從版本鏈中挑選可見的記錄,從圖中可以看出,最新版本的列 name 的內容是 habit_trx_id_90_02,該版本的 trx_id 值為 90,在 m_ids 列表內,所以不符合可見性要求,根據 roll_pointer 跳到下一個版本。
下一個版本的列 name 的內容是 habit_trx_id_90_01,該版本的 trx_id 值為 90,也在 m_ids 列表內,所以也不符合要求,繼續跳到下一個版本。
下一個版本的列 name 的內容是 habit_trx_id_70_02,該版本的 trx_id 值為 70,而 m_ids 列表中是包含值為 70 的事務 id 的,所以該版本也不符合要求,同理下一個列 name 的內容是 habit_trx_id_70_01 的版本也不符合要求。繼續跳到下一個版本。
下一個版本的列 name 的內容是 habit,該版本的 trx_id 值為 50,小於 ReadView 中的 min_trx_id 值 70,所以這個版本是符合要求的,最後返回給用戶的版本就是這條列 name 為 habit 的記錄。
也就是說兩次 SELECT 查詢得到的結果是重覆的,記錄的列 name 值都是 habit,這就是可重覆讀的含義。如果之後再把事務 id 為 90 的記錄提交了,然後再到剛纔使用 REPEATABLE READ 隔離級別的事務中繼續查找這個 id 為 1 的記錄,得到的結果還是 habit。
MVCC 下的幻讀解決和幻讀現象
REPEATABLE READ 隔離級別下 MVCC 可以解決不可重覆讀問題,那麼幻讀呢?MVCC 是怎麼解決的?幻讀是一個事務按照某個相同條件多次讀取記錄時,後讀取時讀到了之前沒有讀到的記錄,而這個記錄來自另一個事務添加的新記錄。
可以想想,在 REPEATABLE READ 隔離級別下的事務 T1 先根據某個搜索條件讀取到多條記錄,然後事務 T2 插入一條符合相應搜索條件的記錄並提交,然後事務 T1 再根據相同搜索條件執行查詢。結果會是什麼?按照 ReadView 中的比較規則中的第 3 條和第 4 條不管事務 T2 比事務 T1 是否先開啟,事務 T1 都是看不到 T2 的提交的。
但是,在 REPEATABLE READ 隔離級別下 InnoDB 中的 MVCC 可以很大程度地避免幻讀現象,而不是完全禁止幻讀。怎麼回事呢?來看下麵的情況:
首先在事務 T1 中執行:select * from mvcc_test where id = 30; 這個時候是找不到 id = 30 的記錄的。
在事務 T2 中,執行插入語句:insert into mvcc_test values(30,'luxi','luxi');
此時回到事務 T1,執行:
update mvcc_test set domain='luxi_t1' where id=30;
select * from mvcc_test where id = 30;
事務T1 很明顯出現了幻讀現象。
在 REPEATABLE READ 隔離級別下,T1 第一次執行普通的 SELECT 語句時生成了一個 ReadView,之後 T2 向 mvcc_test 表中新插入一條記錄並提交。
ReadView 並不能阻止 T1 執行 UPDATE 或者 DELETE 語句來改動這個新插入的記錄,由於 T2 已經提交,因此改動該記錄並不會造成阻塞,但是這樣一來,這條新記錄的 trx_id 隱藏列的值就變成了 T1 的事務 id。之後 T1 再使用普通的 SELECT 語句去查詢這條記錄時就可以看到這條記錄了,也就可以把這條記錄返回給客戶端。因為這個特殊現象的存在,可以認為 MVCC 並不能完全禁止幻讀。
mvcc 總結
從上邊的描述中可以看出來,所謂的 MVCC(Multi-Version Concurrency Control ,多版本併發控制)指的就是在使用 READ COMMITTD、REPEATABLE READ 這兩種隔離級別的事務在執行普通的 SELECT 操作時訪問記錄的版本鏈的過程,這樣子可以使不同事務的讀寫、寫讀操作併發執行,從而提升系統性能。
READ COMMITTD、REPEATABLE READ 這兩個隔離級別的一個很大不同就是:生成 ReadView 的時機不同,READ COMMITTD 在每一次進行普通 SELECT 操作前都會生成一個 ReadView,而 REPEATABLE READ 只在第一次進行普通 SELECT 操作前生成一個 ReadView,之後的查詢操作都重覆使用這個 ReadView 就好了,從而基本上可以避免幻讀現象。
InnoDB 的 Buffer Pool
對於使用 InnoDB 作為存儲引擎的表來說,不管是用於存儲用戶數據的索引,包括:聚簇索引和二級索引,還是各種系統數據,都是以頁的形式存放在表空間中的,而所謂的表空間只不過是 InnoDB 對文件系統上一個或幾個實際文件的抽象,也就是說數據還是存儲在磁碟上的。
但是磁碟的速度慢,所以 InnoDB 存儲引擎在處理客戶端的請求時,當需要訪問某個頁的數據時,就會把完整的頁的數據全部載入到記憶體中,即使只需要訪問一個頁的一條記錄,那也需要先把整個頁的數據載入到記憶體中。將整個頁載入到記憶體中後就可以進行讀寫訪問了,在進行完讀寫訪問之後並不著急把該頁對應的記憶體空間釋放掉,而是將其緩存起來,這樣將來有請求再次訪問該頁面時,就可以省去磁碟 IO 的開銷了。
Buffer Pool
InnoDB 為了緩存磁碟中的頁,在 MySQL 伺服器啟動的時候就向操作系統申請了一片連續的記憶體,這塊連續記憶體叫做:Buffer Pool,中文名:緩衝池。
預設情況下 Buffer Pool 只有 128M 大小。
查看該值:show variables like 'innodb_buffer_pool_size';
可以在啟動伺服器的時候配置 innodb_buffer_pool_size 參數的值,它表示 Buffer Pool 的大小,配置如下:
[server]
innodb_buffer_pool_size = 268435456
其中,268435456 的單位是位元組,也就是指定 Buffer Pool 的大小為 256M,Buffer Pool 也不能太小,最小值為 5M,當小於該值時會自動設置成 5M。
啟動 MySQL 伺服器的時候,需要完成對 Buffer Pool 的初始化過程,就是先向操作系統申請 Buffer Pool 的記憶體空間,然後把它劃分成若幹對控制塊和緩 存頁。但是此時並沒有真實的磁碟頁被緩存到 Buffer Pool 中,之後隨著程式的運行,會不斷的有磁碟上的頁被緩存到 Buffer Pool 中。
在 Buffer Pool 中會創建多個緩存頁,預設的緩存頁大小和在磁碟上預設的頁大小是一樣的,都是 16KB。
那麼怎麼知道該頁在不在 Buffer Pool 中呢?
在查找數據的時候,先通過哈希表中查找 key 是否在哈希表中,如果在證明 Buffer Pool 中存在該緩存也信息,如果不存在證明不存該緩存也信息,則通過讀取磁碟載入該頁信息放到 Buffer Pool 中,哈希表中的 key 是通過表空間號+ 頁號作組成的,value 是 Buffer Pool 的緩存頁。
flush 鏈表的管理
如果修改了 Buffer Pool 中某個緩存頁的數據,那它就和磁碟上的頁不一致了,這樣的緩存頁也被稱為:臟頁。最簡單的做法就是每發生一次修改就立即同步到磁碟上對應的頁上,但是頻繁的往磁碟中寫數據會嚴重的影響程式的性能。所以每次修改緩存頁後,並不著急把修改同步到磁碟上,而是在未來的某個時間進行同步。 但是如果不立即同步到磁碟的話,那之後再同步的時候怎麼知道 Buffer Pool 中哪些頁是臟頁,哪些頁從來沒被修改過呢?總不能把所有的緩存頁都同步到磁碟上吧,如果 Buffer Pool 被設置的很大,那一次性同步會非常慢。
所以,需要再創建一個存儲臟頁的鏈表,凡是修改過的緩存頁對應的控制塊都會作為一個節點加入到一個鏈表中,因為這個鏈表節點對應的緩存頁都是需要被刷新到磁碟上的,所以也叫 flush 鏈表。
刷新臟頁到磁碟
後臺有專門的線程每隔一段時間負責把臟頁刷新到磁碟,這樣可以不影響用戶線程處理正常的請求。
從 flush 鏈表中刷新一部分頁面到磁碟,後臺線程也會定時從 flush 鏈表中刷新一部分頁面到磁碟,刷新的速率取決於當時系統是不是很繁忙。這種刷新頁面的方式被稱之為:BUF_FLUSH_LIST。
redo 日誌
redo 日誌的作用
InnoDB 存儲引擎是以頁為單位來管理存儲空間的,增刪改查操作其實本質上都是在訪問頁面,包括:讀頁面、寫頁面、創建新頁面等操作。在真正訪問頁面之前,需要把在磁碟上的頁緩存到記憶體中的 Buffer Pool 之後才可以訪問。但是在事務的時候又強調過一個稱之為持久性的特性,就是說對於一個已經提交的事務,在事務提交後即使系統發生了崩潰,這個事務對資料庫中所做的更改也不能丟失。
如果只在記憶體的 Buffer Pool 中修改了頁面,假設在事務提交後突然發生了某個故障,導致記憶體中的數據都失效了,那麼這個已經提交了的事務對資料庫中所做的更改也就跟著丟失了,這是所不能忍受的。那麼如何保證這個持久性呢?一個很簡單的做法就是在事務提交完成之前把該事務所修改的所有頁面都刷新到磁碟,但是這個簡單粗暴的做法有些問題:
- 刷新一個完整的數據頁太浪費了;有時候僅僅修改了某個頁面中的一個位元組,但是在 InnoDB 中是以頁為單位來進行磁碟 IO 的,也就是說在該事務提交時不得不將一個完整的頁面從記憶體中刷新到磁碟,一個頁面預設是16KB 大小,只修改一個位元組就要刷新 16KB 的數據到磁碟上顯然是太浪費了。
- 隨機 IO 刷起來比較慢;一個事務可能包含很多語句,即使是一條語句也可能修改許多頁面,該事務修改的這些頁面可能並不相鄰,這就意味著在將某個事務修改的 Buffer Pool 中的頁面刷新到磁碟時,需要進行很多的隨機 IO,隨機 IO 比順序 IO 要慢,尤其對於傳統的機械硬碟來說。
只是想讓已經提交了的事務對資料庫中數據所做的修改永久生效,即使後來系統崩潰,在重啟後也能把這種修改恢復出來。其實沒有必要在每次事務提交時就把該事務在記憶體中修改過的全部頁面刷新到磁碟,只需要把修改了哪些東西記錄一下就好,比方說:某個事務將系統表空間中的第 5 號頁面中偏移量為 5000 處的那個位元組的值 0 改成 5 只需要記錄一下:將第 5 號表空間的 5 號頁面的偏移量為 5000 處的值更新為:5。
這樣在事務提交時,把上述內容刷新到磁碟中,即使之後系統崩潰了,重啟之後只要按照上述內容所記錄的步驟重新更新一下數據頁,那麼該事務對資料庫中所做的修改又可以被恢復出來,也就意味著滿足持久性的要求。因為在系統崩潰重啟時需要按照上述內容所記錄的步驟重新更新數據頁,所以上述內容也被稱之為:重做日誌,即:redo log。與在事務提交時將所有修改過的記憶體中的頁面刷新到磁碟中相比,只將該事務執行過程中產生的 redo log 刷新到磁碟的好處如下:
- redo log 占用的空間非常小存儲表空間 ID、頁號、偏移量以及需要更新的值所需的存儲空間是很小的;
- redo log 是順序寫入磁碟的在執行事務的過程中,每執行一條語句,就可能產生若幹條 redo log,這些日誌是按照產生的順序寫入磁碟的,也就是使用順序 IO;
redo log 的寫入過程
InnoDB 為了更好的進行系統崩潰恢復,把一次原子操作生成的 redo log 都放在了大小為 512 位元組的塊(block)中。
為瞭解決磁碟速度過慢的問題而引入了 Buffer Pool。同理,寫入 redo log 時也不能直接寫到磁碟上,實際上在伺服器啟動時就向操作系統申請了一大片稱之為 redo log buffer 的連續記憶體空間,即:redo log 緩衝區,也可以簡稱:log buffer。這片記憶體空間被劃分成若幹個連續的 redo log block,可以通過啟動參數innodb_log_buffer_size 來指定 log buffer 的大小,該啟動參數的預設值為:16MB。
向 log buffer 中寫入 redo log 的過程是順序的,也就是先往前邊的 block 中寫,當該 block 的空閑空間用完之後再往下一個 block 中寫。
redo log 刷盤時機
log buffer 什麼時候會寫入到磁碟呢?
- log buffer 空間不足時,如果不停的往這個有限大小的 log buffer 里塞入日誌,很快它就會被填滿。InnoDB 認為如果當前寫入 log buffer 的 redo log 量已 經占滿了 log buffer 總容量的大約一半左右,就需要把這些日誌刷新到磁碟上。
- 事務提交時,必須要把修改這些頁面對應的 redo log 刷新到磁碟。
- 後臺有一個線程,大約每秒都會刷新一次 log buffer 中的 redo log 到磁碟。
- 正常關閉伺服器時等等。
undo 日誌
事務需要保證原子性,也就是事務中的操作要麼全部完成,要麼什麼也不做。但是偏偏有時候事務執行到一半會出現一些情況,比如:
- 情況一:事務執行過程中可能遇到各種錯誤,比如伺服器本身的錯誤,操作系統錯誤,甚至是突然斷電導致的錯誤。
- 情況二:程式員可以在事務執行過程中手動輸入 ROLLBACK 語句結束當前的事務的執行。
這兩種情況都會導致事務執行到一半就結束,但是事務執行過程中可能已經修改了很多東西,為了保證事務的原子性,需要把東西改回原先的樣子,這個過程就稱之為回滾,即:rollback,這樣就可以造成這個事務看起來什麼都沒做,所以符合原子性要求。
每當要對一條記錄做改動時,都需要把回滾時所需的東西都給記下來。
比方說:
- 插入一條記錄時,至少要把這條記錄的主鍵值記下來,之後回滾的時候只需要把這個主鍵值對應的記錄刪掉。
- 刪除了一條記錄,至少要把這條記錄中的內容都記下來,這樣之後回滾時再把由這些內容組成的記錄插入到表中。
- 修改了一條記錄,至少要把修改這條記錄前的舊值都記錄下來,這樣之後回滾時再把這條記錄更新為舊值。
這些為了回滾而記錄的這些東西稱之為撤銷日誌,即:undo log。這裡需要註意的一點是,由於查詢操作並不會修改任何用戶記錄,所以在查詢操作執行時,並不需要記錄相應的 undo log。
undo 日誌的格式
為了實現事務的原子性,InnoDB 存儲引擎在實際進行增、刪、改一條記錄時,都需要先把對應的 undo 日誌記下來。一般每對一條記錄做一次改動,就對應著一條 undo 日誌,但在某些更新記錄的操作中,也可能會對應著 2 條 undo 日誌。
一個事務在執行過程中可能新增、刪除、更新若幹條記錄,也就是說需要記錄很多條對應的 undo 日誌,這些 undo 日誌會被從 0 開始編號,也就是說根據生成的順序分別被稱為第 0 號 undo 日誌、第 1 號 undo 日誌、...、第 n 號 undo 日誌等,這個編號也被稱之為 undo no。
這些 undo 日誌是被記錄到類型為 FIL_PAGE_UNDO_LOG 的頁面中。這些頁面可以從系統表空間中分配,也可以從一種專門存放 undo 日誌的表空間,也就是所謂的 undo tablespace 中分配。
作者:京東物流 張士欣
來源:京東雲開發者社區 自圓其說Tech 轉載請註明來源


