
本文旨在探討火山引擎 DataLeap 在處理計算治理過程中所面臨的問題及其解決方案,並展示這些解決方案帶來的實際收益。主要內容包括:探討面臨的痛點和挑戰、提供自動化的解決方案、分析實踐效果和收益、提出結論和未來展望。 ...
更多技術交流、求職機會,歡迎關註位元組跳動數據平臺微信公眾號,回覆【1】進入官方交流群
【導讀】本文旨在探討火山引擎 DataLeap 在處理計算治理過程中所面臨的問題及其解決方案,並展示這些解決方案帶來的實際收益。主要內容包括:
-
探討面臨的痛點和挑戰
-
提供自動化的解決方案
-
分析實踐效果和收益
-
提出結論和未來展望
▌痛點 & 挑戰
在分析業務痛點和挑戰之前,先要清楚業務現狀。
-
現狀概覽
位元組跳動數據平臺目前使用了 1 萬多個任務執行隊列,支持 DTS、HSQL、Spark、Python、Flink、Shell 等 50 多種類型的任務。
自動計算治理框架目前已經完成了離線任務的接入,包括 HSQL、Hive to X 的 DTS 任務、AB test 和底層通過 Spark 引擎執行的任務,涉及到上千個隊列,國內 可優化任務 170 萬+ 的任務優化覆蓋率達到 60%+。另外實時任務的優化也在同步推進。
-
痛點:手動調參常⻅問題
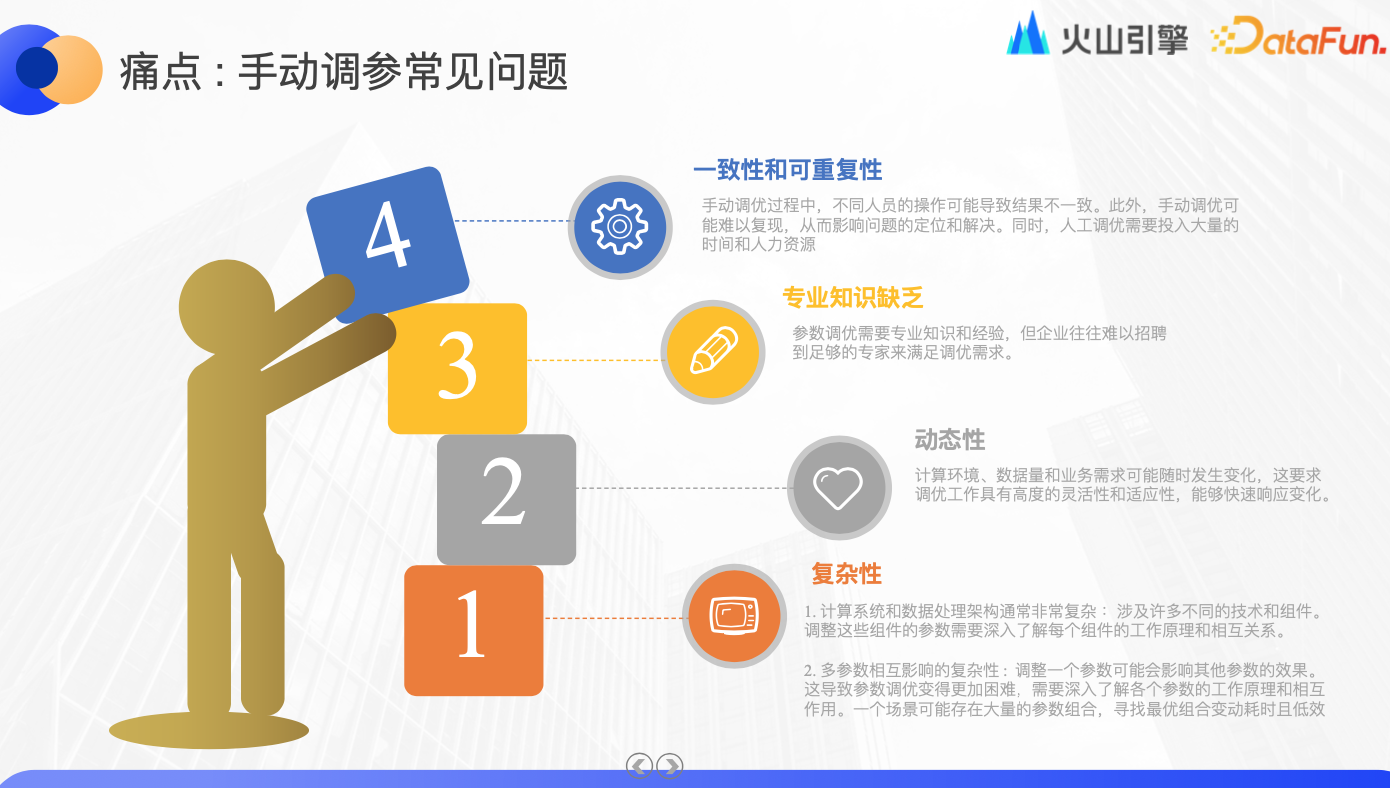
在手動調參的過程中,我們常常面臨以下困境:
-
系統複雜度:
大數據計算系統與數據處理架構涵蓋多種技術和組件,對其參數的調整需深刻理解各組件的運作機制及其相互依賴。以 Spark 為例,其擁有上百個適用於不同場景的參數,而這些參數可能互相影響,增加了調優的難度。過去,我們通常依賴單一任務模板進行少量參數調整,雖然此法能讓單項任務搶占資源,卻難以保證整體業務的及時性和穩定性。
-
動態變化:
計算環境、數據量和業務需求可能隨時變動,這要求調優工作需具備高度的靈活性和適應性,以迅速應對各種變化。
-
專業知識缺乏:
通常由數據分析師來執行優化任務,但他們更側重於業務場景而非底層邏輯。因此,我們希望通過自動化方案沉澱專業知識,提供一站式解決方案。
-
一致性與可重覆性缺失:
不同人員操作可能導致不一致的結果,手動調優往往難以復現。例如,昨天的分區調優效果良好,但明天可能因數據量增加而導致記憶體溢出(OOM),後續運維包括復盤將需要投入大量時間成本。
-
挑戰:複雜的優化場景和目標
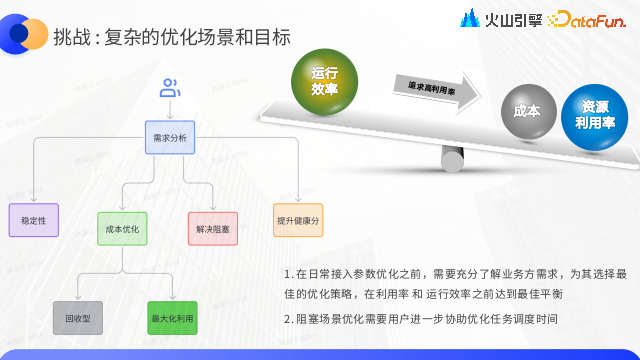
針對業務方的優化需求,通常包括提高系統穩定性、降低運營成本、解決任務阻塞及提升系統健康度等多個方面。為選擇最適合的優化策略,需深入理解以下幾個常見場景:
-
穩定性與健康度:提高穩定性通常意味著需要犧牲一些資源利用率以保障運行效率;而提升健康度則旨在追求較高的資源利用率,儘管可能會對運行效率產生一些影響。
-
成本優化:主要包括回收無效成本和最大化資源利用率兩個方向。由於業務方常存在大量未被充分利用的資源,我們需要協助他們提升任務的運行效率和縮短產出時間。
-
解決阻塞:通過調整算力和記憶體等參數來緩解阻塞。若參數調優無法完全解決阻塞問題,就需要與用戶協作,優化任務的調度時間。
-
業務優化場景需求分析

針對之前提及的優化場景,以下是一些具體的解決策略:
-
穩定性優化:
推薦資源配額應基於任務的實際使用量,同時為保障穩定性,將近 7 天的波動和失敗指標納入權重計算,確保推薦參數能適應業務的波動和增長。
-
隊列阻塞解決:
在 CPU 阻塞而記憶體正常時,維持總算力不變,減少物理核、增加虛擬核,並相應調整記憶體配額。
在 CPU 正常而記憶體阻塞時,降低總算力,從而降低任務申請的物理記憶體總量。
當 CPU 和記憶體同時阻塞時,適度降低算力或減少虛擬核,以保任務運行性能在預期範圍內。
註意:如參數調優未能解決阻塞問題,需與調度系統協同,將任務調度至合適時段,以徹底解決阻塞問題。
-
計算健康分提升:
CPU 利用率:對於小任務,可減少物理核、增加虛擬核。對普通和大任務,需評估是否調整算力,進而確定調優方向。
記憶體利用率:通常不宜將記憶體利用率設置過高以避免 OOM,首先按需分配資源,然後根據記憶體利用率調整虛擬核。例如,當利用率低於 50%時,提升虛擬核。後期將支持 1/1000 核的微調以逼近理想的記憶體利用率閾值。記憶體調優涵蓋多個階段如 map、shuffle 和 reduce 等,每階段的處理性能和參數配置有所差異。遇到記憶體調優瓶頸時,可考慮進行 shuffle 優化。
-
成本優化:
Quota 回收型:實際使用量應低於申請量,如需回收 20%,則需確保空閑量超過 30%的時間占比維持在 95%以上,同時保有 10%的可用餘量。
Quota 充分利用型:
CPU 型優化:可增加虛擬核或物理核,但由於增加虛擬核可能導致超發,為保障隊列穩定性,建議增加物理核。
記憶體型優化:增加算力、減少物理核、增加虛擬核,以釋放更多記憶體資源,確保記憶體得到充分利用。
▌自動化解決方案
接下來講解針對上述場景的自動化解決方案。
-
解決方案:實時規則引擎
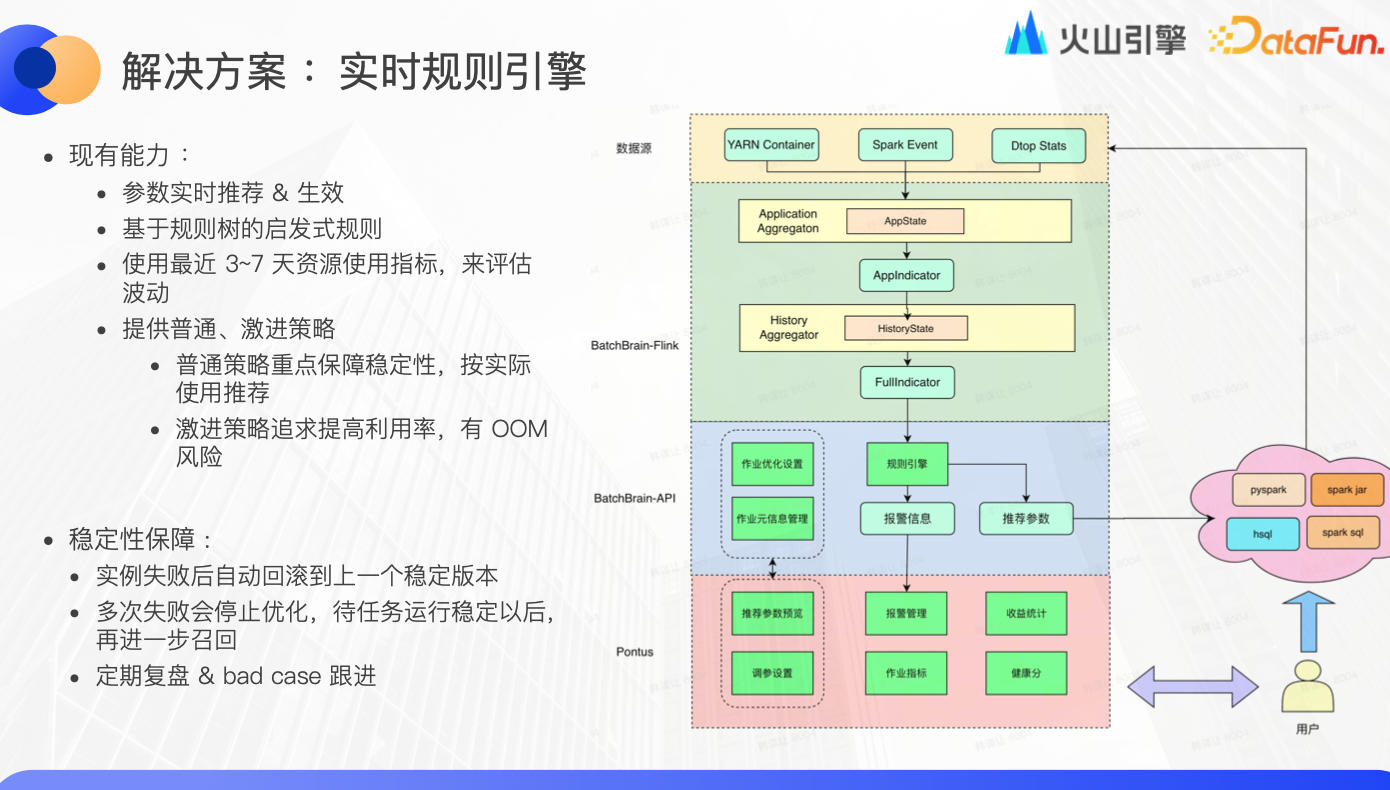
首先,我們介紹實時規則引擎及其功能:
-
參數實時推薦與應用:該引擎能夠實時收集 Yarn container、Spark event 和 Dtop status 等數據,通過基於 app ID 的聚合,統計所有核心與觀測指標,並將數據記錄至歷史資料庫中。在連續的 3-7 天觀測期內,引擎會根據收集到的數據進一步優化參數推薦,最終將推薦參數推送到 Spark 等執行引擎,並實時監控任務的執行情況。
-
啟髮式規則的應用:利用基於規則樹的啟髮式規則,針對不同的場景,我們可以設定不同的優化目標和閾值,為優化過程提供指導。
-
資源使用評估:通過分析最近 3-7 天的資源使用累積指標,實時規則引擎可以評估整體的資源波動情況,為進一步的優化提供數據支持。
-
穩定性與健康分策略:
普通策略:旨在保障系統的穩定性,通過分析實際的資源使用量來提供參數推薦。
激進策略:著眼於提高資源利用率,不斷探索任務的性能邊界,同時能自適應地應對 OOM 風險,保障系統的運行效率。
為確保系統的穩定運行,一旦任務實例失敗,實時規則引擎會自動將參數回滾至上一個穩定版本。若連續失敗多次,則暫停該任務的優化過程,直至任務恢復穩定運行。我們每周會對失敗案例進行復盤分析,以持續優化和改進實時規則引擎的性能和準確性。
-
解決方案:實時監控 & 自適應調整

我們還實施了一系列實時監控和自適應調整方案,以增強 Spark 等底層引擎的性能和穩定性:
-
OOM 自適應處理:針對易發生 OOM 的任務,我們將其調度至獨立的 executor,讓其獨享 container 資源,從而在不增加總資源的前提下,減緩 OOM 的發生,保障任務的穩定運行。
-
Shuffle 溢寫分裂管理:我們設定了每個容器的 Shuffle 磁碟寫入量閾值。一旦寫入量超過閾值,系統會自動分裂出新的容器,避免單個容器的溢寫,同時減輕 ESS 的壓力。
-
Shuffle 分級限流機制:根據任務的優先順序,分配不同的查詢處理速率(QPS)。高優先順序任務將獲得更多的 QPS,而低優先順序任務的 QPS 會相應限制,以防止 ESS 服務過載,確保高優先順序任務的順利執行。
-
節點黑名單優化:為了降低任務失敗率,我們實現了節點黑名單機制。當節點因特定失敗原因被標記時,任務會儘量避免在該節點上執行。我們還提供了設置黑名單節點數量上限的功能,防止過多節點被拉黑,影響整個集群的可用性。
-
失敗回滾與參數管理:當任務實例失敗時,系統會自動將參數回滾至上一個穩定版本。若連續失敗兩次,系統會自動抹除推薦參數並暫停優化,以避免對任務造成進一步的干擾。這種機制有助於降低業務波動對執行的風險,同時減少人工干預的成本。
-
Dataleap 一站式的治理解決方案
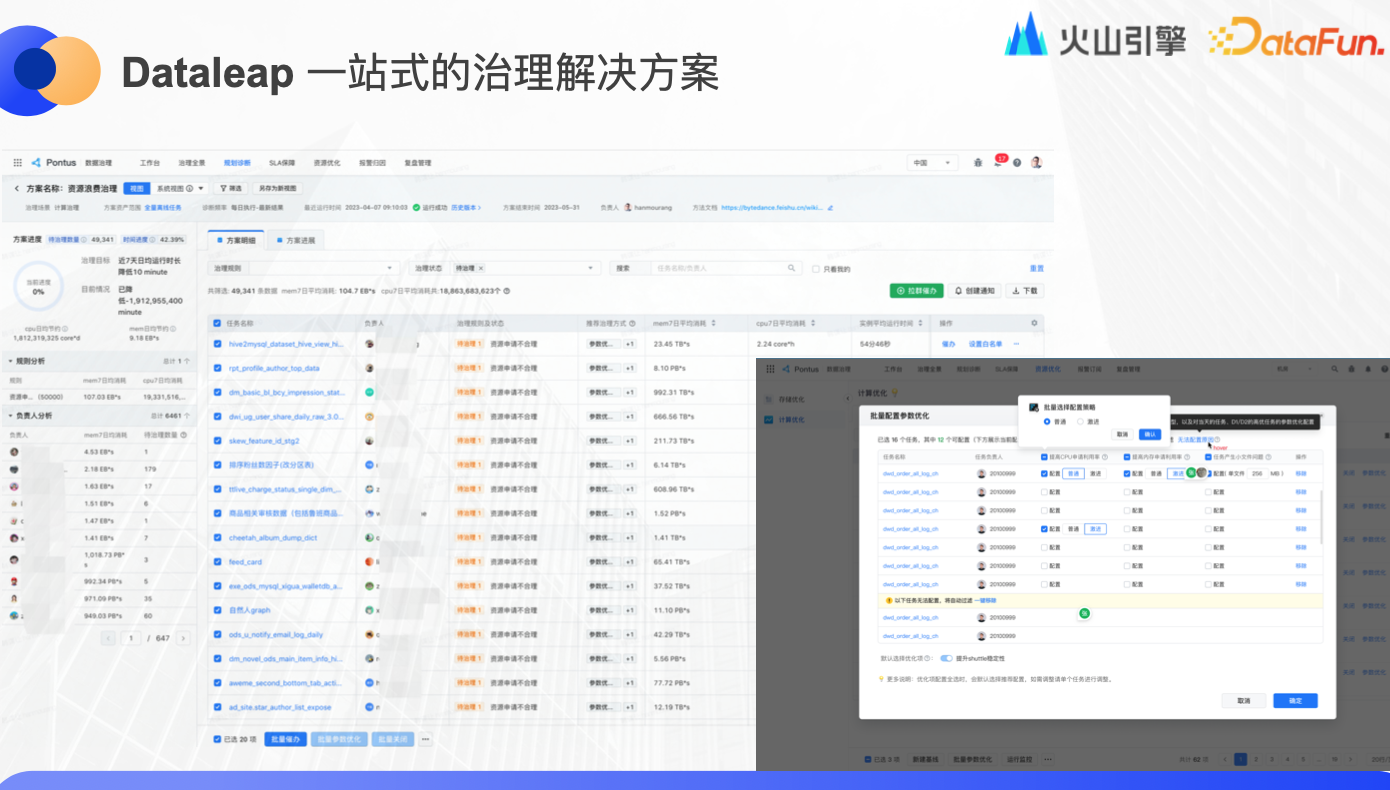
最後還有產品側的一站式解決方案,用戶可以快速發起治理。系統界面可以看到每個用戶當前可治理的資源量等信息,可以批量或者單個開啟優化,可以選擇激進或普通策略,支持小文件優化,系統會根據業務場景自動適配。在做優化方案的同時,系統就會預估出成本和收益。
▌實踐 & 收益
接下來複盤一個具體的優化案例。
-
優化實踐:隊列優化前後效果
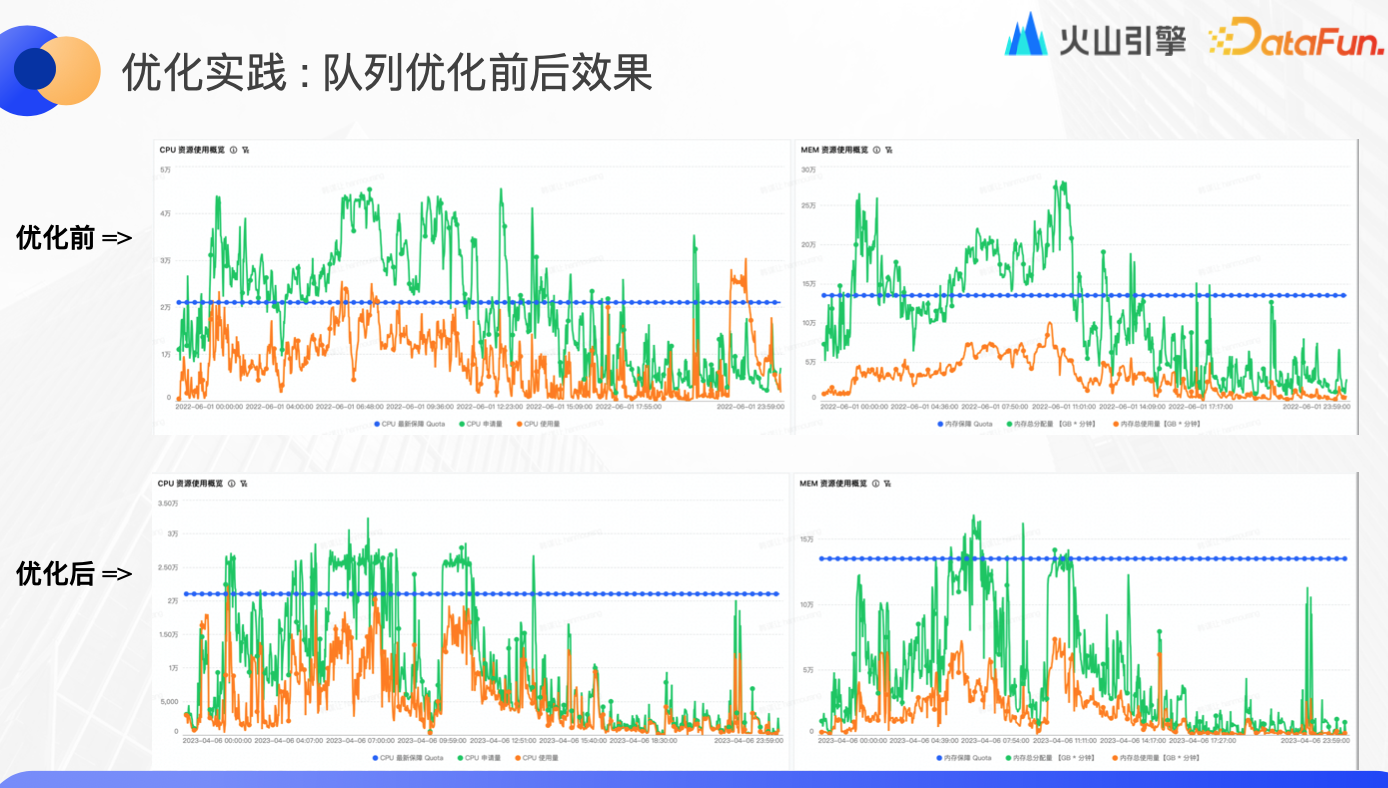
本例的隊列在優化前的每天 10 點前都處於超髮狀態,導致任務阻塞非常嚴重,很多任務長期處於等待狀態。優化後的資源申請量明顯降低,申請量和使用量之間的 gap 趨向理想範圍,由於減輕了記憶體超發,使 OOM 問題得到改善,讓平臺使用更少的成本和資源做了更多的事情。
-
收益分析:隊列優化收益指標
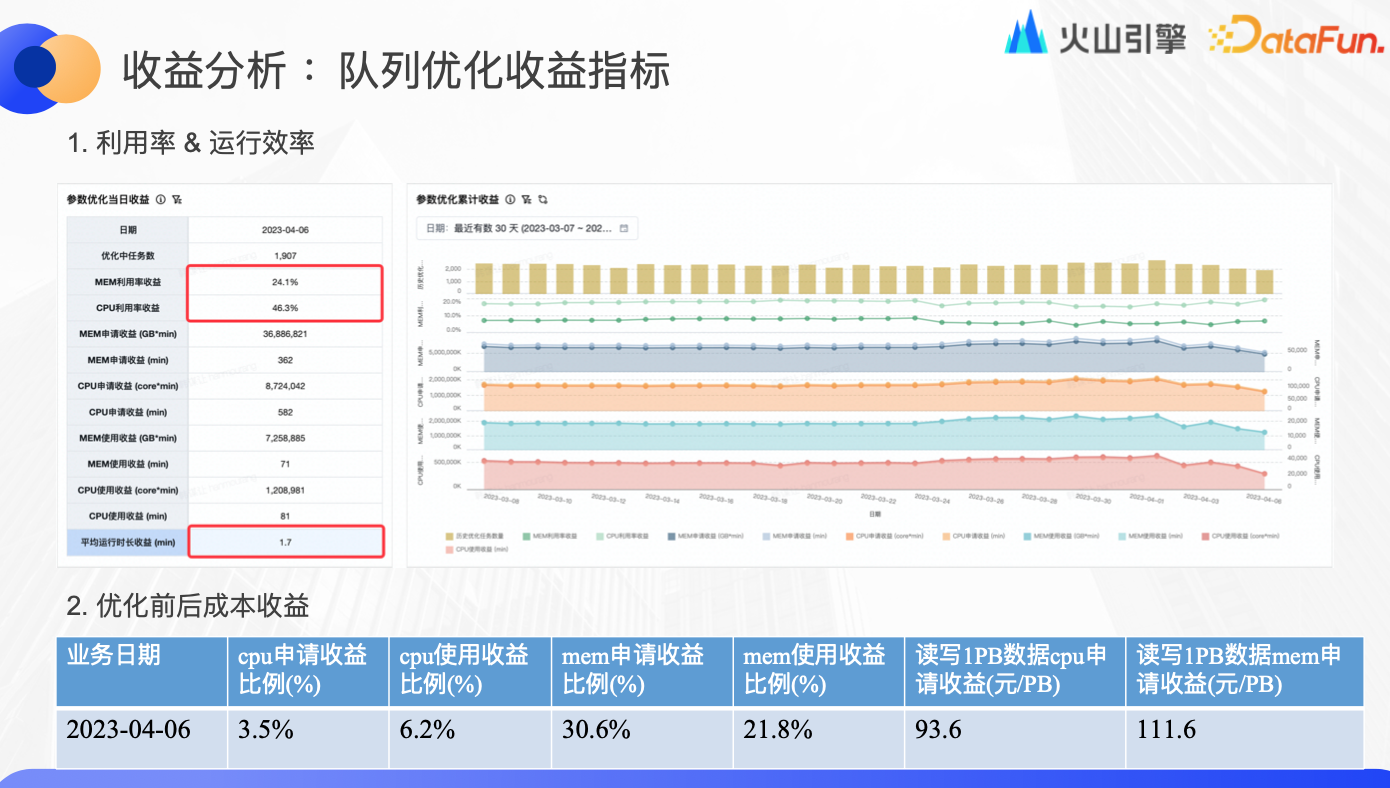
由於每個用戶對於底層的理解程度不同,如果按單個任務、單個用戶去優化,很難保障人力成本和時間成本。而通過平臺的自動化解決方案,就可以保證所有業務、隊列都可以達到一個非常好的預期效果。
如上圖所示,該隊列一共有 1900 多個任務,優化完成後,CPU 申請量減少 3.5%、使用量減少 6.2%、利用率提升 46.3%,記憶體申請量減少 30.6%、使用量減少 21.8%、利率提升 24%,所有任務的平均運行時長減少了 1.7 分鐘,每 PB 數據 CPU 節約近百元、記憶體節約百元以上。
-
收益概覽:業務隊列普通策略優化效果
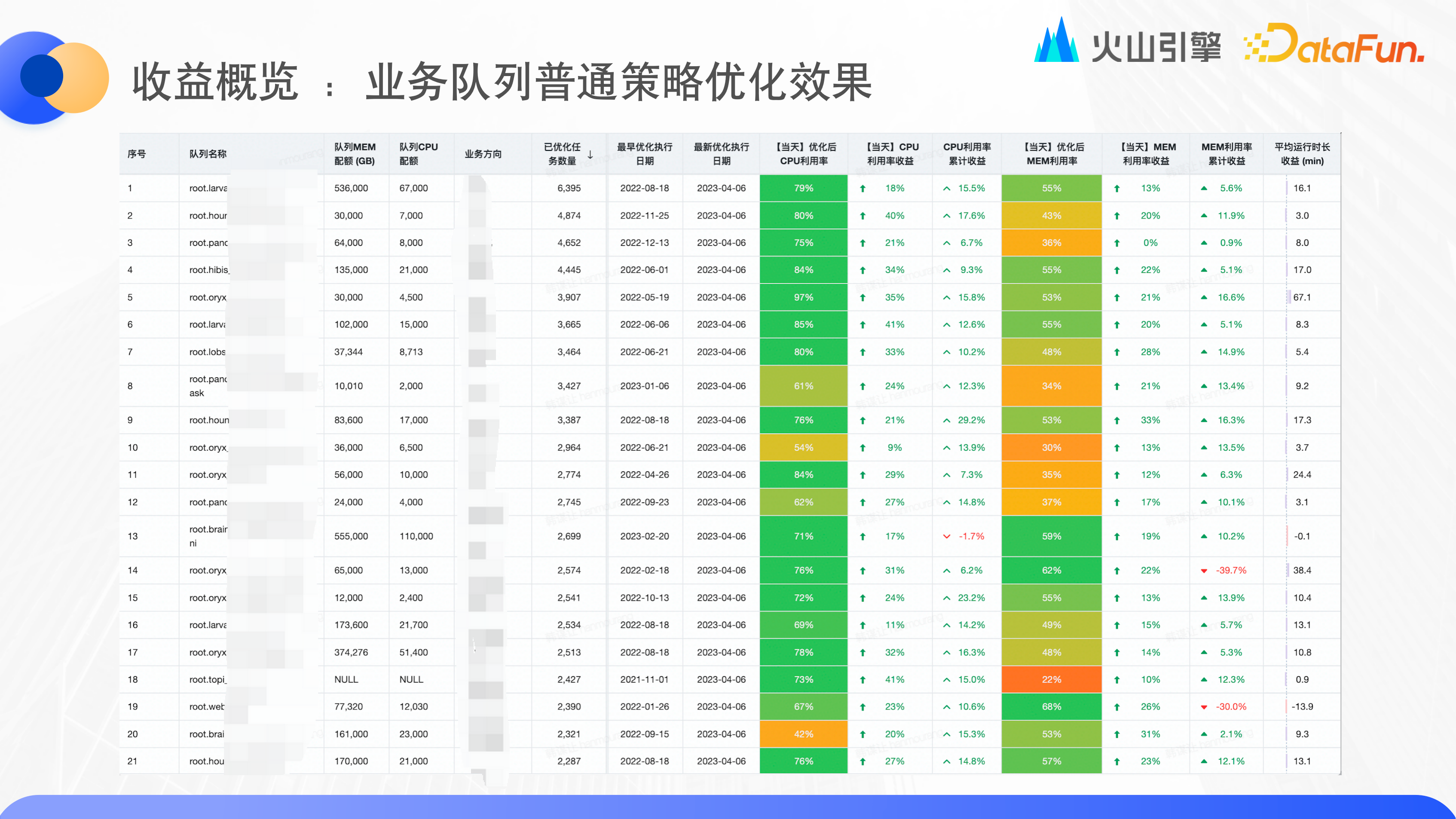
穩定策略對於記憶體使用率的目標是 75%-80%,已完成優化的 TOP20 隊列普遍提升了 20%,CPU 使用率普遍達到了 70%-80%,整體運行時長也有提升。
另外還有一些激進策略、深度優化和成本優化策略,可以幫助大部分業務在資源利用率和運行效率之間尋求平衡。
-
收益概覽:增量小文件合併

增量小文件合併是在 reduce 階段,會把產出不合理的文件進一步合併,這個操作導致線上 2000 多個任務的平均運行時間增加了 18%,對當前任務來說是負向收益。但是合併完成後下游任務讀取數據性能比之前提高很多,對整個隊列、集群來說是長期正向收益。後續我們會爭取把小文件合併的性能損耗從 18%降到 10%以內。
▌結論 & 展望
-
自動化方案優勢 & 局限性

自動化方案的優勢包括:
-
效率提升:通過運用先進的演算法和實時監控機制,自動化方案能夠迅速鎖定最優參數組合,從而提升調優效率。
-
準確性增強:能夠妥善處理參數間複雜的相互影響,為複雜系統呈現更為精準的調優結果,進一步提高調優的準確性。
-
人力成本節省:自動化方案減少了人力的投入,有助於降低企業及組織的運營成本。
-
實時監控與自適應調整:實時監控系統的狀態和性能,根據數據的變化自動做出調整,確保系統始終運行在最佳狀態。
然而,自動化方案也存在一些局限性:
-
演算法依賴:方案的效果高度依賴於所選用的演算法,選取合適的演算法和優化策略成為關鍵。
-
可解釋性與可控性的局限:自動化方案可能會在可解釋性和可控性方面顯示出一些限制,增加了在特定情況下對系統理解和調整的難度。
-
特定場景的應對困難:在某些特定的場景下,自動化方案無法完全取代人工調優,仍需專業人員的參與和經驗。
-
未來發展與挑戰

最後來看一下未來的發展規劃和可能面對的挑戰。
發展重點:
-
元數據閉環多產品化:
分級保障:實現 Pontus 和 Dorado 之間的元數據通信,針對服務等級協議(SLA)和核心鏈路節點,確保高優先順序的穩定性和及時性。
隊列管理:明確在 Megatron 側為各業務配置的資源使用規則:
回溯管理:設定指定時段內回溯任務所能使用的資源上限。
用戶資源管理:通過設定單個用戶可使用的資源比例上限,以控制該用戶名下任務的可用計算力。
Ad-hoc 資源控制:在系統高負載時段,自動調整 adhoc 查詢的資源使用管控。
-
用戶干預參數推薦:
提供固定值、最大/最小閾值、參數屏蔽等選項,允許用戶根據實際需求調整參數。
-
結合規則引擎與演算法優化:
通過集成規則引擎和演算法優化,實現更為高效且準確的參數調優。
預見挑戰:
-
適應變化的數據環境:
面對大數據領域的快速進展,持續優化自動化解決方案以適應不斷變化的數據環境。
-
提升演算法性能:
為實現更高效的自動化解決方案,持續研究和提升演算法性能。
-
保障系統的可解釋性和可控性:
在推進自動化的過程中,確保系統的可解釋性和可控性,以便用戶能夠理解併進行調整。
點擊跳轉DataLeap瞭解更多


