
認識Redis Redis官網:https://redis.io/ Redis誕生於2009年全稱是Remote Dictionary Server 遠程詞典伺服器,是一個基於記憶體的鍵值型NoSQL資料庫 特征: 鍵值(key-value)型,value支持多種不同數據結構,功能豐富 單線程,每個命 ...
認識Redis
Redis官網:https://redis.io/
Redis誕生於2009年全稱是Remote Dictionary Server 遠程詞典伺服器,是一個基於記憶體的鍵值型NoSQL資料庫
特征:
- 鍵值(key-value)型,value支持多種不同數據結構,功能豐富
- 單線程,每個命令具備原子性
- 低延遲,速度快(基於記憶體.IO多路復用.良好的編碼)
- 支持數據持久化
- 支持主從集群、分片集群
NoSQL可以翻譯做Not Only SQL(不僅僅是SQL),或者是No SQL(非SQL的)資料庫。是相對於傳統關係型資料庫而言,有很大差異的一種特殊的資料庫,因此也稱之為非關係型資料庫
關係型數據是結構化的,即有嚴格要求,而NoSQL則對資料庫格式沒有嚴格約束,往往形式鬆散,自由
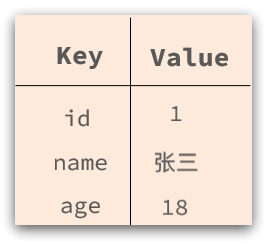
可以是鍵值型:
也可以是文檔型:

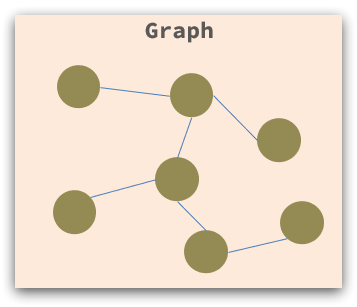
甚至可以是圖格式:
在事務方面:
- 傳統關係型資料庫能滿足事務ACID的原則
- 非關係型資料庫往往不支持事務,或者不能嚴格保證ACID的特性,只能實現基本的一致性
除了上面說的,在存儲方式.擴展性.查詢性能上關係型與非關係型也都有著顯著差異,總結如下:

- 存儲方式
- 關係型資料庫基於磁碟進行存儲,會有大量的磁碟IO,對性能有一定影響
- 非關係型資料庫,他們的操作更多的是依賴於記憶體來操作,記憶體的讀寫速度會非常快,性能自然會好一些
- 擴展性
- 關係型資料庫集群模式一般是主從,主從數據一致,起到數據備份的作用,稱為垂直擴展。
- 非關係型資料庫可以將數據拆分,存儲在不同機器上,可以保存海量數據,解決記憶體大小有限的問題。稱為水平擴展。
- 關係型資料庫因為表之間存在關聯關係,如果做水平擴展會給數據查詢帶來很多麻煩
安裝Redis
企業都是基於Linux伺服器來部署項目,而且Redis官方也沒有提供Windows版本的安裝包
本文選擇的Linux版本為CentOS 7
單機安裝
- 安裝需要的依賴
yum install -y gcc tcl
- 上傳壓縮包並解壓
tar -zxf redis-7.0.12.tar.gz
- 進入解壓的redis目錄
cd redis-7.0.12
- 編譯並安裝
make && make install
預設的安裝路徑是在 /usr/local/bin目錄下
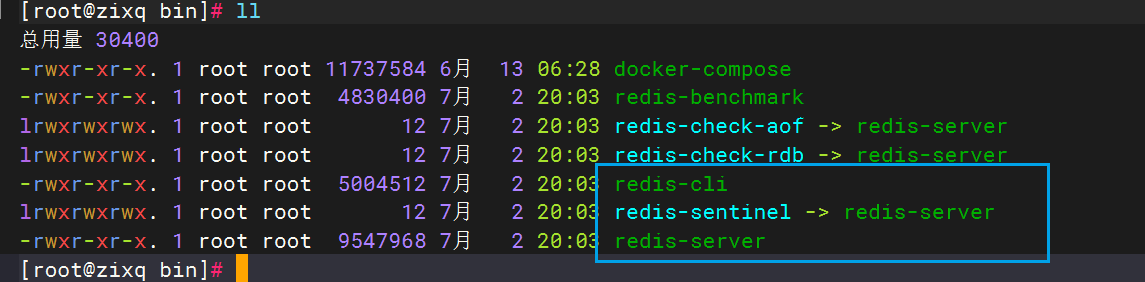
該目錄已經預設配置到環境變數,因此可以在任意目錄下運行這些命令。其中:
- redis-cli:是redis提供的命令行客戶端
- redis-server:是redis的服務端啟動腳本
- redis-sentinel:是redis的哨兵啟動腳本
啟動Redis
redis的啟動方式有很多種,例如:
- 預設啟動
- 指定配置啟動
- 開機自啟
預設啟動
安裝完成後,在任意目錄輸入redis-server命令即可啟動Redis:
redis-server
這種啟動屬於“前臺啟動”,會阻塞整個會話視窗,視窗關閉或者按下CTRL + C則Redis停止
指定配置啟動
如果要讓Redis以“後臺”方式啟動,則必須修改Redis配置文件,就在之前解壓的redis安裝包下(/usr/local/src/redis-6.2.6),名字叫redis.conf
修改redis.conf文件中的一些配置:可以先拷貝一份再修改
# 允許訪問的地址,預設是127.0.0.1,會導致只能在本地訪問。修改為0.0.0.0則可以在任意IP訪問,生產環境不要設置為0.0.0.0
bind 0.0.0.0
# 守護進程,修改為yes後即可後臺運行
daemonize yes
# 密碼,設置後訪問Redis必須輸入密碼
requirepass 072413
Redis的其它常見配置:
# 監聽的埠
port 6379
# 工作目錄,預設是當前目錄,也就是運行redis-server時的命令,日誌、持久化等文件會保存在這個目錄
dir .
# 資料庫數量,設置為1,代表只使用1個庫,預設有16個庫,編號0~15
databases 1
# 設置redis能夠使用的最大記憶體
maxmemory 512mb
# 日誌文件,預設為空,不記錄日誌,可以指定日誌文件名
logfile "redis.log"
啟動Redis:
# 進入redis安裝目錄
cd /opt/redis-6.2.13
# 啟動
redis-server redis.conf
停止服務:
# 利用redis-cli來執行 shutdown 命令,即可停止 Redis 服務,
# 因為之前配置了密碼,因此需要通過 -u 來指定密碼
redis-cli -u password shutdown
開機自啟
可以通過配置來實現開機自啟。
首先,新建一個系統服務文件:
vim /etc/systemd/system/redis.service
內容如下:
[Unit]
Description=redis-server
After=network.target
[Service]
Type=forking
ExecStart=/usr/local/bin/redis-server /opt/redis-7.0.12/redis.conf
PrivateTmp=true
[Install]
WantedBy=multi-user.target
然後重載系統服務:
systemctl daemon-reload
現在,我們可以用下麵這組命令來操作redis了:
# 啟動
systemctl start redis
# 停止
systemctl stop redis
# 重啟
systemctl restart redis
# 查看狀態
systemctl status redis
執行下麵的命令,可以讓redis開機自啟:
systemctl enable redis
主從集群安裝
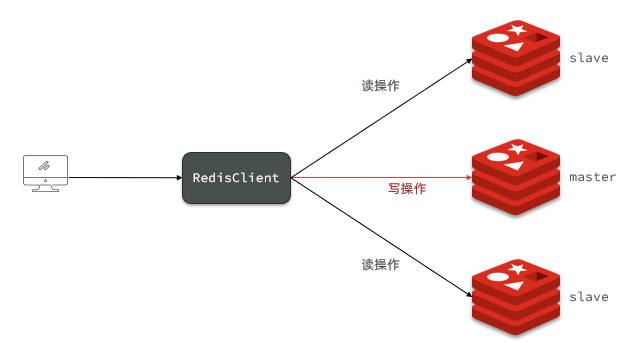
主:具有讀寫操作
從:只有讀操作
- 修改redis.conf文件
# 開啟RDB
# save ""
save 3600 1
save 300 100
save 60 10000
# 關閉AOF
appendonly no
- 將上面的redis.conf文件拷貝到不同地方
# 方式一:逐個拷貝
cp /usr/local/bin/redis-7.0.12/redis.conf /tmp/redis-7001
cp /usr/local/bin/redis-7.0.12/redis.conf /tmp/redis-7002
cp /usr/local/bin/redis-7.0.12/redis.conf /tmp/redis-7003
# 方式二:管道組合命令,一鍵拷貝
echo redis-7001 redis-7002 redis-7003 | xargs -t -n 1 cp /usr/local/bin/redis-7.0.12/redis.conf
- 修改各自的埠、rdb目錄改為自己的目錄
sed -i -e 's/6379/7001/g' -e 's/dir .\//dir \/tmp\/redis-7001\//g' redis-7001/redis.conf
sed -i -e 's/6379/7002/g' -e 's/dir .\//dir \/tmp\/redis-7002\//g' redis-7002/redis.conf
sed -i -e 's/6379/7003/g' -e 's/dir .\//dir \/tmp\/redis-7003\//g' redis-7003/redis.conf
- 修改每個redis節點的IP聲明。虛擬機本身有多個IP,為了避免將來混亂,需要在redis.conf文件中指定每一個實例的綁定ip信息,格式如下:
# redis實例的聲明 IP
replica-announce-ip IP地址
# 逐一執行
sed -i '1a replica-announce-ip 192.168.150.101' redis-7001/redis.conf
sed -i '1a replica-announce-ip 192.168.150.101' redis-7002/redis.conf
sed -i '1a replica-announce-ip 192.168.150.101' redis-7003/redis.conf
# 或者一鍵修改
printf '%s\n' redis-7001 redis-7002 redis-7003 | xargs -I{} -t sed -i '1a replica-announce-ip 192.168.150.101' {}/redis.conf
- 啟動
# 第1個
redis-server redis-7001/redis.conf
# 第2個
redis-server redis-7002/redis.conf
# 第3個
redis-server redis-7003/redis.conf
# 一鍵停止
printf '%s\n' redis-7001 redis-7002 redis-7003 | xargs -I{} -t redis-cli -p {} shutdown
- 開啟主從關係:配置主從可以使用replicaof 或者slaveof(5.0以前)命令
永久配置:在redis.conf中添加一行配置
slaveof <masterip> <masterport>
臨時配置:使用redis-cli客戶端連接到redis服務,執行slaveof命令(重啟後失效)
# 5.0以後新增命令replicaof,與salveof效果一致
slaveof <masterip> <masterport>
卸載Redis
- 查看redis是否啟動
ps aux | grep redis
- 若啟動,則殺死進程
kill -9 PID

- 停止服務
redis-cli shutdown
- 查看
/usr/local/lib目錄中是否有與Redis相關的文件
ll /usr/local/bin/redis-*
# 有的話就刪掉
rm -rf /usr/local/bin/redis-*
Redis客戶端工具
命令行客戶端
Redis安裝完成後就自帶了命令行客戶端:redis-cli,使用方式如下:
redis-cli [options] [commonds]
其中常見的options有:
-h 127.0.0.1:指定要連接的redis節點的IP地址,預設是127.0.0.1-p 6379:指定要連接的redis節點的埠,預設是6379-a 072413:指定redis的訪問密碼
其中的commonds就是Redis的操作命令,例如:
ping:與redis服務端做心跳測試,服務端正常會返回pong
不指定commond時,會進入redis-cli的交互控制台:

圖形化客戶端
地址:https://github.com/uglide/RedisDesktopManager
不過該倉庫提供的是RedisDesktopManager的源碼,並未提供windows安裝包。
在下麵這個倉庫可以找到安裝包:https://github.com/lework/RedisDesktopManager-Windows/releases
下載之後,解壓、安裝


Redis預設有16個倉庫,編號從0至15. 通過配置文件可以設置倉庫數量,但是不超過16,並且不能自定義倉庫名稱。
如果是基於redis-cli連接Redis服務,可以通過select命令來選擇資料庫
# 選擇 0號庫
select 0
Redis常見命令 / 對象
Redis是一個key-value的資料庫,key一般是String類型,不過value的類型多種多樣:

查命令的官網: https://redis.io/commands
在交互界面使用 help 命令查詢:
help [command]

通用命令
通用指令是部分數據類型都可以使用的指令,常見的有:
- KEYS:查看符合模板的所有key。在生產環境下,不推薦使用keys 命令,因為這個命令在key過多的情況下,效率不高
- DEL:刪除一個指定的key
- EXISTS:判斷key是否存在
- EXPIRE:給一個key設置有效期,有效期到期時該key會被自動刪除。記憶體非常寶貴,對於一些數據,我們應當給他一些過期時間,當過期時間到了之後,他就會自動被刪除
- 當使用EXPIRE給key設置的有效期過期了,那麼此時查詢出來的TTL結果就是-2
- 如果沒有設置過期時間,那麼TTL返回值就是-1
- TTL:查看一個KEY的剩餘有效期

String命令
使用場景:
- 驗證碼保存
- 不易變動的對象保存
- 簡單鎖的保存
String類型,也就是字元串類型,是Redis中最簡單的存儲類型
其value是字元串,不過根據字元串的格式不同,又可以分為3類:
- string:普通字元串
- int:整數類型,可以做自增.自減操作
- float:浮點類型,可以做自增.自減操作

String的常見命令有:
-
SET:添加或者修改已經存在的一個String類型的鍵值對,對於SET,若key不存在則為添加,存在則為修改
-
GET:根據key獲取String類型的value
-
MSET:批量添加多個String類型的鍵值對
-
MGET:根據多個key獲取多個String類型的value
-
INCR:讓一個整型的key自增1
-
INCRBY:讓一個整型的key自增並指定步長
- incrby num 2 讓num值自增2
- 也可以使用負數,是為減法,如:incrby num -2 讓num值-2。此種類似 DECR 命令,而DECR是每次-1
-
INCRBYFLOAT:讓一個浮點類型的數字自增並指定步長
-
SETNX:添加一個String類型的鍵值對(key不存在為添加,存在則不執行)
-
SETEX:添加一個String類型的鍵值對,並且指定有效期
註:以上命令除了INCRBYFLOAT 都是常用命令
key問題
key的設計
Redis沒有類似MySQL中的Table的概念,我們該如何區分不同類型的key?
可以通過給key添加首碼加以區分,不過這個首碼不是隨便加的,有一定的規範
Redis的key允許有多個單詞形成層級結構,多個單詞之間用:隔開,格式如下:

這個格式並非固定,也可以根據自己的需求來刪除或添加詞條
如項目名稱叫 automation,有user和product兩種不同類型的數據,我們可以這樣定義key:
-
user相關的key:automation:user:1
-
product相關的key:automation:product:1
同時還需要滿足:
- key的長度最好別超過44位元組(3.0版本是39位元組)
- key中別包含特殊字元
BigKey問題
BigKey通常“以Key的大小和Key中成員的數量來綜合判定”,例如:
- Key本身的數據量過大:一個String類型的Key,它的值為5 MB
- Key中的成員數過多:一個ZSET類型的Key,它的成員數量為10,000個
- Key中成員的數據量過大:一個Hash類型的Key,它的成員數量雖然只有1,000個但這些成員的Value(值)總大小為100 MB
判定元素大小的方式:
MEMORY USAGE key # 查看某個key的記憶體大小,不建議使用:因為此命令對CPU使用率較高
# 衡量值 或 值的個數
STRLEN key # string結構 某key的長度
LLEN key # list集合 某key的值的個數
.............
推薦值:
- 單個key的value小於10KB
- 對於集合類型的key,建議元素數量小於1000
BigKey的危害
- 網路阻塞:對BigKey執行讀請求時,少量的QPS就可能導致帶寬使用率被占滿,導致Redis實例,乃至所在物理機變慢
- 數據傾斜:BigKey所在的Redis實例記憶體使用率遠超其他實例,無法使數據分片的記憶體資源達到均衡
- Redis阻塞:對元素較多的hash、list、zset等做運算會耗時較舊,使主線程被阻塞
- CPU壓力:對BigKey的數據序列化和反序列化會導致CPU的使用率飆升,影響Redis實例和本機其它應用
如何發現BigKey
- redis-cli --bigkeys 命令:
redis-cli -a 密碼 --bigkeys
此命令可以遍歷分析所有key,並返回Key的整體統計信息與每個數據的Top1的key
不足:返回的是記憶體大小是TOP1的key,而此key不一定是BigKey,同時TOP2、3.......的key也不一定就不是BigKey
- scan命令掃描:]每次會返回2個元素,第一個是下一次迭代的游標(cursor),第一次游標會設置為0,當最後一次scan 返回的游標等於0時,表示整個scan遍歷結束了,第二個返回的是List,一個匹配的key的數組
127.0.0.1:7001> help SCAN
SCAN cursor [MATCH pattern] [COUNT count] [TYPE type]
summary: Incrementally iterate the keys space
since: 2.8.0
group: generic
自定義代碼來判定是否為BigKey
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.ScanResult;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class JedisTest {
private final static int STR_MAX_LEN = 10 * 1024;
private final static int HASH_MAX_LEN = 500;
private Jedis jedis;
@BeforeEach
void setUp() {
// 1.建立連接
jedis = new Jedis("192.168.146.100", 6379);
// 2.設置密碼
jedis.auth("072413");
// 3.選擇庫
jedis.select(0);
}
@Test
void testScan() {
int maxLen = 0;
long len = 0;
String cursor = "0";
do {
// 掃描並獲取一部分key
ScanResult<String> result = jedis.scan(cursor);
// 記錄cursor
cursor = result.getCursor();
List<String> list = result.getResult();
if (list == null || list.isEmpty()) {
break;
}
// 遍歷
for (String key : list) {
// 判斷key的類型
String type = jedis.type(key);
switch (type) {
case "string":
len = jedis.strlen(key);
maxLen = STR_MAX_LEN;
break;
case "hash":
len = jedis.hlen(key);
maxLen = HASH_MAX_LEN;
break;
case "list":
len = jedis.llen(key);
maxLen = HASH_MAX_LEN;
break;
case "set":
len = jedis.scard(key);
maxLen = HASH_MAX_LEN;
break;
case "zset":
len = jedis.zcard(key);
maxLen = HASH_MAX_LEN;
break;
default:
break;
}
if (len >= maxLen) {
System.out.printf("Found big key : %s, type: %s, length or size: %d %n", key, type, len);
}
}
} while (!cursor.equals("0"));
}
@AfterEach
void tearDown() {
if (jedis != null) {
jedis.close();
}
}
}
- 第三方工具
- 利用第三方工具,如 Redis-Rdb-Tools 分析RDB快照文件,全面分析記憶體使用情況
- 網路監控
- 自定義工具,監控進出Redis的網路數據,超出預警值時主動告警
- 一般阿裡雲搭建的雲伺服器就有相關監控頁面

如何刪除BigKey
BigKey記憶體占用較多,即便是刪除這樣的key也需要耗費很長時間,導致Redis主線程阻塞,引發一系列問題
- redis 3.0 及以下版本:如果是集合類型,則遍歷BigKey的元素,先逐個刪除子元素,最後刪除BigKey

- Redis 4.0以後:使用非同步刪除的命令 unlink
127.0.0.1:7001> help UNLINK
UNLINK key [key ...]
summary: Delete a key asynchronously in another thread. Otherwise it is just as DEL, but non blocking.
since: 4.0.0
group: generic
解決BigKey問題
上一節是刪除BigKey,但是數據最終還是未解決
要解決BigKey:
- 選擇合適的數據結構(String、Hash、List、Set、ZSet、Stream、GEO、HyperLogLog、BitMap)
- 將大數據拆為小數據,具體根據業務來
如:一個對象放在hash中,hash底層會使用ZipList壓縮,但entry數量超過500時(看具體redis版本),會使用哈希表而不是ZipList
# 查看redis的entry數量
[root@zixq ~]# redis-cli
127.0.0.1:7001> config get hash-max-ziplist-entries
# 修改redis的entry數量 別太離譜即可
config set hash-max-ziplist-entries
因此:一個hash的key中若是field-value約束在一定的entry以內即可,超出的就用另一個hash的key來存儲,具體實現以業務來做
Hash命令
使用場景:
- 易改變對象的保存
- 分散式鎖的保存(Redisson分散式鎖的實現原理)
這個在工作中使用頻率很高
Hash類型,也叫散列,其value是一個無序字典,類似於Java中的HashMap結構。
String結構是將對象序列化為JSON字元串後存儲,當需要修改對象某個欄位時很不方便:

Hash結構可以將對象中的每個欄位獨立存儲,可以針對單個欄位做CRUD:
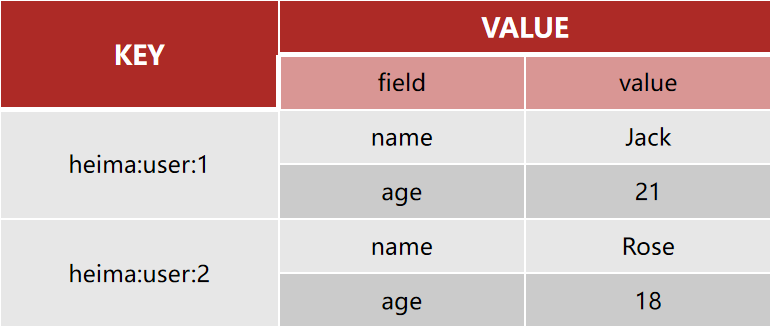
Hash類型的常見命令
-
HSET key field value:添加或者修改hash類型key的field的值。同理:操作不存在數據是為新增,存在則為修改
-
HGET key field:獲取一個hash類型key的field的值
-
HMSET:批量添加多個hash類型key的field的值
-
HMGET:批量獲取多個hash類型key的field的值
-
HGETALL:獲取一個hash類型的key中的所有的field和value
-
HKEYS:獲取一個hash類型的key中的所有的field
-
HINCRBY:讓一個hash類型key的field的value值自增並指定步長
-
HSETNX:添加一個hash類型的key的field值,前提是這個field不存在,否則不執行
List命令 - 命令規律開始變化
Redis中的List類型與Java中的LinkedList類似,可以看做是一個雙向鏈表結構。既可以支持正向檢索,也可以支持反向檢索。
特征也與LinkedList類似:
- 有序
- 元素可以重覆
- 插入和刪除快
- 查詢速度一般
使用場景:
- 朋友圈點贊列表
- 評論列表
List的常見命令有:
- LPUSH key element ... :向列表左側插入一個或多個元素
- LPOP key:移除並返回列表左側的第一個元素,沒有則返回nil
- RPUSH key element ... :向列表右側插入一個或多個元素
- RPOP key:移除並返回列表右側的第一個元素
- LRANGE key star end:返回一段角標範圍內的所有元素
- BLPOP和BRPOP:與LPOP和RPOP類似,只不過在沒有元素時等待指定時間,而不是直接返回nil

Set命令
Redis的Set結構與Java中的HashSet類似,可以看做是一個value為null的HashMap。因為也是一個hash表,因此具備與HashSet類似的特征:
- 無序
- 元素不可重覆
- 查找快
- 支持交集.並集.差集等功能
使用場景:
- 一人一次的業務。如:某商品一個用戶只能買一次
- 共同擁有的業務,如:關註、取關與共同關註
Set類型的常見命令
- SADD key member ... :向set中添加一個或多個元素
- SREM key member ... :移除set中的指定元素
- SCARD key:返回set中元素的個數
- SISMEMBER key member:判斷一個元素是否存在於set中
- SMEMBERS:獲取set中的所有元素
- SINTER key1 key2 ... :求key1與key2的交集
- SDIFF key1 key2 ... :求key1與key2的差集
- SUNION key1 key2 ..:求key1和key2的並集
SortedSet / ZSet 命令
Redis的SortedSet是一個可排序的set集合,與Java中的TreeSet有些類似,但底層數據結構卻差別很大。SortedSet中的每一個元素都帶有一個score屬性,可以基於score屬性對元素排序,底層的實現是一個跳錶(SkipList)加 hash表。
SortedSet具備下列特性:
- 可排序
- 元素不重覆
- 查詢速度快
使用場景:
- 排行榜
SortedSet的常見命令有:
- ZADD key score member:添加一個或多個元素到sorted set ,如果已經存在則更新其score值
- ZREM key member:刪除sorted set中的一個指定元素
- ZSCORE key member : 獲取sorted set中的指定元素的score值
- ZRANK key member:獲取sorted set 中的指定元素的排名
- ZCARD key:獲取sorted set中的元素個數
- ZCOUNT key min max:統計score值在給定範圍內的所有元素的個數
- ZINCRBY key increment member:讓sorted set中的指定元素自增,步長為指定的increment值
- ZRANGE key min max:按照score排序後,獲取指定排名範圍內的元素
- ZRANGEBYSCORE key min max:按照score排序後,獲取指定score範圍內的元素
- ZDIFF.ZINTER.ZUNION:求差集.交集.並集
註意:所有的排名預設都是升序,如果要降序則在命令的Z後面添加REV即可,例如:
- 升序獲取sorted set 中的指定元素的排名:ZRANK key member
- 降序獲取sorted set 中的指定元素的排名:ZREVRANK key memeber
Stream命令
基於Stream的消息隊列-消費者組
消費者組(Consumer Group):將多個消費者劃分到一個組中,監聽同一個隊列。具備下列特點:

- 創建消費者組
XGROUP CREATE key groupName ID [MKSTREAM]
- key:隊列名稱
- groupName:消費者組名稱
- ID:起始ID標示,$代表隊列中最後一個消息,0則代表隊列中第一個消息
- MKSTREAM:隊列不存在時自動創建隊列
- 刪除指定的消費者組
XGROUP DESTORY key groupName
- 給指定的消費者組添加消費者
XGROUP CREATECONSUMER key groupname consumername
- 刪除消費者組中的指定消費者
XGROUP DELCONSUMER key groupname consumername
- 從消費者組讀取消息
XREADGROUP GROUP group consumer [COUNT count] [BLOCK milliseconds] [NOACK] STREAMS key [key ...] ID [ID ...]
-
group:消費組名稱
-
consumer:消費者名稱,如果消費者不存在,會自動創建一個消費者
-
count:本次查詢的最大數量
-
BLOCK milliseconds:當沒有消息時最長等待時間
-
NOACK:無需手動ACK,獲取到消息後自動確認
-
STREAMS key:指定隊列名稱
-
ID:獲取消息的起始ID:
- ">":從下一個未消費的消息開始
- 其它:根據指定id從pending-list中獲取已消費但未確認的消息,例如0,是從pending-list中的第一個消息開始
STREAM類型消息隊列的XREADGROUP命令特點:
- 消息可回溯
- 可以多消費者爭搶消息,加快消費速度
- 可以阻塞讀取
- 沒有消息漏讀的風險
- 有消息確認機制,保證消息至少被消費一次
消費者監聽消息的基本思路:

GEO命令
GEO就是Geolocation的簡寫形式,代表地理坐標。Redis在3.2版本中加入了對GEO的支持,允許存儲地理坐標信息,幫助我們根據經緯度來檢索數據
常見的命令有:
- GEOADD:添加一個地理空間信息,包含:經度(longitude)、緯度(latitude)、值(member)
- GEODIST:計算指定的兩個點之間的距離並返回
- GEOHASH:將指定member的坐標轉為hash字元串形式並返回
- GEOPOS:返回指定member的坐標
- GEORADIUS:指定圓心、半徑,找到該圓內包含的所有member,並按照與圓心之間的距離排序後返回。6.以後已廢棄
- GEOSEARCH:在指定範圍內搜索member,並按照與指定點之間的距離排序後返回。範圍可以是圓形或矩形。6.2.新功能
- GEOSEARCHSTORE:與GEOSEARCH功能一致,不過可以把結果存儲到一個指定的key。 6.2.新功能
BitMap命令
bit:指的就是bite,二進位,裡面的內容就是非0即1咯
map:就是說將適合使用0或1的業務進行關聯。如:1為簽到、0為未簽到,這樣就直接使用某bite就可表示出一個用戶一個月的簽到情況,減少記憶體花銷了
BitMap底層是基於String實現的,因此:在Java中BitMap相關的操作封裝到了redis的String操作中
BitMap的操作命令有:
- SETBIT:向指定位置(offset)存入一個0或1
- GETBIT :獲取指定位置(offset)的bit值
- BITCOUNT :統計BitMap中值為1的bit位的數量
- BITFIELD :操作(查詢、修改、自增)BitMap中bit數組中的指定位置(offset)的值
- BITFIELD_RO :獲取BitMap中bit數組,並以十進位形式返回
- BITOP :將多個BitMap的結果做位運算(與 、或、異或)
- BITPOS :查找bit數組中指定範圍內第一個0或1出現的位置
HyperLogLog 命令
UV:全稱Unique Visitor,也叫獨立訪客量,是指通過互聯網訪問、瀏覽這個網頁的自然人。1天內同一個用戶多次訪問該網站,只記錄1次
PV:全稱Page View,也叫頁面訪問量或點擊量,用戶每訪問網站的一個頁面,記錄1次PV,用戶多次打開頁面,則記錄多次PV。往往用來衡量網站的流量
Hyperloglog(HLL)是從Loglog演算法派生的概率演算法,用於確定非常大的集合的基數,而不需要存儲其所有值
相關演算法原理大家可以參考:https://juejin.cn/post/6844903785744056333#heading-0
Redis中的HLL是基於string結構實現的,單個HLL的記憶體永遠小於16kb。作為代價,其測量結果是概率性的,有小於0.81%的誤差,同時此結構自帶去重
常用命令如下:目前也只有這些命令

PubSub 發佈訂閱
PubSub(發佈訂閱)是Redis2.0版本引入的消息傳遞模型。顧名思義,消費者可以訂閱一個或多個channel,生產者向對應channel發送消息後,所有訂閱者都能收到相關消息
- SUBSCRIBE channel [channel] :訂閱一個或多個頻道
- PUBLISH channel msg :向一個頻道發送消息
- PSUBSCRIBE pattern[pattern] :訂閱與pattern格式匹配的所有頻道。pattern支持的通配符如下:
? 表示 一個 字元 如:h?llo 則可以為 hallo、hxllo
* 表示 0個或N個 字元 如:h*llo 則可以為 hllo、heeeello.........
[ae] 表示 是a或e都行 如:h[ae]llo 則可以為 hello、hallo
優點:
- 採用發佈訂閱模型,支持多生產、多消費
缺點:
- 不支持數據持久化
- 無法避免消息丟失
- 消息堆積有上限,超出時數據丟失
Java操作:Jedis
官網:https://redis.io/docs/clients/
其中Java客戶端也包含很多:

標記為❤的就是推薦使用的Java客戶端,包括:
- Jedis和Lettuce:這兩個主要是提供了“Redis命令對應的API”,方便我們操作Redis,而SpringDataRedis又對這兩種做了抽象和封裝
- Redisson:是在Redis基礎上實現了分散式的可伸縮的Java數據結構,例如Map.Queue等,而且支持跨進程的同步機制:Lock.Semaphore等待,比較適合用來實現特殊的功能需求
入門Jedis
創建Maven項目
- 依賴
<!--jedis-->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.7.0</version>
</dependency>
- 測試:其他類型如Hash、Set、List、SortedSet和下麵String是一樣的用法
package com.zixieqing.redis;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import redis.clients.jedis.Jedis;
/**
* jedis操作redis:redis的命令就是jedis對應的API
*
* @author : ZiXieqing
*/
public class QuickStartTest {
private Jedis jedis;
@Before
public void setUp() throws Exception {
jedis = new Jedis("host", 6379);
// 設置密碼
jedis.auth("072413");
// 設置庫
jedis.select(0);
}
@After
public void tearDown() throws Exception {
if (null != jedis) jedis.close();
}
/**
* String類型
*/
@Test
public void stringTest() {
// 添加key-value
String result = jedis.set("name", "zixieqing");
System.out.println("result = " + result);
// 通過key獲取value
String value = jedis.get("name");
System.out.println("value = " + value);
// 批量添加或修改
String mset = jedis.mset("age", "18", "sex", "girl");
System.out.println("mset = " + mset);
System.out.println("jedis.keys() = " + jedis.keys("*"));
// 給key自增並指定步長
long incrBy = jedis.incrBy("age", 5L);
System.out.println("incrBy = " + incrBy);
// 若key不存在,則添加,存在則不執行
long setnx = jedis.setnx("city", "hangzhou");
System.out.println("setnx = " + setnx);
// 添加key-value,並指定有效期
String setex = jedis.setex("job", 10L, "Java");
System.out.println("setex = " + setex);
// 獲取key的有效期
long ttl = jedis.ttl("job");
System.out.println("ttl = " + ttl);
}
}
連接池
Jedis本身是線程不安全的,並且頻繁的創建和銷毀連接會有性能損耗,推薦使用Jedis連接池代替Jedis的直連方式
package com.zixieqing.redis.util;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
import java.time.Duration;
/**
* Jedis連接池
*
* @author : ZiXieqing
*/
public class JedisConnectionFactory {
private static JedisPool jedisPool;
static {
// 設置連接池
JedisPoolConfig PoolConfig = new JedisPoolConfig();
PoolConfig.setMaxTotal(30);
PoolConfig.setMaxIdle(30);
PoolConfig.setMinIdle(0);
PoolConfig.setMaxWait(Duration.ofSeconds(1));
/*
設置鏈接對象
JedisPool(GenericObjectPoolConfig<Jedis> poolConfig, String host, int port, int timeout, String password)
*/
jedisPool = new JedisPool(PoolConfig, "192.168.46.128", 6379, 1000, "072413");
}
public static Jedis getJedis() {
return jedisPool.getResource();
}
}
Java操作:SpringDataRedis
SpringData是Spring中數據操作的模塊,包含對各種資料庫的集成,其中對Redis的集成模塊就叫做SpringDataRedis
官網:https://spring.io/projects/spring-data-redis
- 提供了對不同Redis客戶端的整合(Lettuce和Jedis)
- 提供了RedisTemplate統一API來操作Redis
- 支持Redis的發佈訂閱模型
- 支持Redis哨兵和Redis集群
- 支持基於JDK.JSON、字元串、Spring對象的數據序列化及反序列化
- 支持基於Redis的JDKCollection實現
SpringDataRedis中提供了RedisTemplate工具類,其中封裝了各種對Redis的操作。並且將不同數據類型的操作API封裝到了不同的類型中:

入門SpringDataRedis
創建SpringBoot項目
- pom.xml配置
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.3.9.RELEASE</version>
<relativePath/>
</parent>
<groupId>com.zixieqing</groupId>
<artifactId>02-spring-data-redis</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>02-spring-data-redis</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>8</java.version>
</properties>
<dependencies>
<!--redis依賴-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!--common-pool-->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>
<!--Jackson依賴-->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
</project>
- YAML文件配置
spring:
redis:
host: 192.168.46.128
port: 6379
password: "072413"
jedis:
pool:
max-active: 100 # 最大連接數
max-idle: 100 # 最大空閑數
min-idle: 0 # 最小空閑數
max-wait: 5 # 最大鏈接等待時間 單位:ms
- 測試:其他如Hash、List、Set、SortedSet的方法和下麵String差不多
package com.zixieqing.springdataredis;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.redis.core.RedisTemplate;
import javax.annotation.Resource;
import java.util.ArrayList;
import java.util.Objects;
import java.util.concurrent.TimeUnit;
@SpringBootTest(classes = App.class)
class ApplicationTests {
@Resource
private RedisTemplate<String, Object> redisTemplate;
/**
* SpringDataRedis操作redis:String類型 其他類型都是同理操作
*
* String:opsForValue
* Hash:opsForHash
* List:opsForList
* Set:opsForSet
* SortedSet:opsForZSet
*/
@Test
void stringTest() {
// 添加key-value
redisTemplate.opsForValue().set("name", "紫邪情");
// 根據key獲取value
String getName = Objects.requireNonNull(redisTemplate.opsForValue().get("name")).toString();
System.out.println("getName = " + getName);
// 添加key-value 並 指定有效期
redisTemplate.opsForValue().set("job", "Java", 10L, TimeUnit.SECONDS);
String getJob = Objects.requireNonNull(redisTemplate.opsForValue().get("job")).toString();
System.out.println("getJob = " + getJob);
// 就是 setnx 命令,key不存在則添加,存在則不執行
redisTemplate.opsForValue().setIfAbsent("city", "杭州");
redisTemplate.opsForValue().setIfAbsent("info", "臉皮厚,欠揍", 10L, TimeUnit.SECONDS);
ArrayList<String> keys = new ArrayList<>();
keys.add("name");
keys.add("job");
keys.add("city");
keys.add("info");
redisTemplate.delete(keys);
}
}
數據序列化
RedisTemplate可以接收Object類型作為值寫入Redis:

只不過寫入前會把Object序列化為位元組形式,預設是採用JDK序列化,得到的結果是這樣的:

缺點:
- 可讀性差
- 記憶體占用較大
Jackson序列化
我們可以自定義RedisTemplate的序列化方式,代碼如下:
package com.zixieqing.springdataredis.config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.GenericJackson2JsonRedisSerializer;
import org.springframework.data.redis.serializer.RedisSerializer;
/**
* redis自定義序列化方式
*
* @author : ZiXieqing
*/
@Configuration
public class RedisSerializeConfig {
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory connectionFactory){
// 創建RedisTemplate對象
RedisTemplate<String, Object> template = new RedisTemplate<>();
// 設置連接工廠
template.setConnectionFactory(connectionFactory);
// 創建JSON序列化工具
GenericJackson2JsonRedisSerializer jsonRedisSerializer = new GenericJackson2JsonRedisSerializer();
// 設置Key的序列化
template.setKeySerializer(RedisSerializer.string());
template.setHashKeySerializer(RedisSerializer.string());
// 設置Value的序列化
template.setValueSerializer(jsonRedisSerializer);
template.setHashValueSerializer(jsonRedisSerializer);
// 返回
return template;
}
}
這裡採用了JSON序列化來代替預設的JDK序列化方式。最終結果如圖:

整體可讀性有了很大提升,並且能將Java對象自動的序列化為JSON字元串,並且查詢時能自動把JSON反序列化為Java對象
不過,其中記錄了序列化時對應的class名稱,目的是為了查詢時實現自動反序列化。這會帶來額外的記憶體開銷。
StringRedisTemplate
儘管JSON的序列化方式可以滿足我們的需求,但依然存在一些問題

為了在反序列化時知道對象的類型,JSON序列化器會將類的class類型寫入json結果中,存入Redis,會帶來額外的記憶體開銷。
為了減少記憶體的消耗,我們可以採用手動序列化的方式,換句話說,就是不藉助預設的序列化器,而是我們自己來控制序列化的動作,同時,我們只採用String的序列化器,這樣,在存儲value時,我們就不需要在記憶體中多存儲數據,從而節約我們的記憶體空間

這種用法比較普遍,因此SpringDataRedis就提供了RedisTemplate的子類:StringRedisTemplate,它的key和value的序列化方式預設就是String方式


使用示例:
package com.zixieqing.springdataredis;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.zixieqing.springdataredis.entity.User;
import lombok.extern.slf4j.Slf4j;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.redis.core.StringRedisTemplate;
import javax.annotation.Resource;
import java.util.ArrayList;
import java.util.Objects;
import java.util.concurrent.TimeUnit;
@Slf4j
@SpringBootTest(classes = App.class)
class ApplicationTests {
@Autowired
private StringRedisTemplate stringRedisTemplate;
// 是jackson中的
private final ObjectMapper mapper = new ObjectMapper();
/**
* 使用StringRedisTemplate操作Redis 和 序列化與反序列化
*
* 操作redis和String類型一樣的
*/
@Test
void serializeTest() throws JsonProcessingException {
User user = new User();
user.setName("zixieqing")
.setJob("Java");
// 序列化
String userStr = mapper.writeValueAsString(user);
stringRedisTemplate.opsForValue().set("com:zixieqing:springdataredis:user", userStr);
// 反序列化
String userStr2 = stringRedisTemplate.opsForValue().get("com:zixieqing:springdataredis:user");
User user2 = mapper.readValue(userStr2, User.class);
log.info("反序列化結果:{}", user2);
}
}

緩存更新策略
緩存更新是redis為了節約記憶體而設計出來的一個東西,主要是因為記憶體數據寶貴,當我們向redis插入太多數據,此時就可能會導致緩存中的數據過多,所以redis會對部分數據進行淘汰

記憶體淘汰:redis自動進行,當redis記憶體達到咱們設定的max-memery的時候,會自動觸發淘汰機制,淘汰掉一些不重要的數據(可以自己設置策略方式)
超時剔除:當我們給redis設置了過期時間ttl之後,redis會將超時的數據進行刪除,方便咱們繼續使用緩存
主動更新:我們可以手動調用方法把緩存刪掉,通常用於解決緩存和資料庫不一致問題
業務場景:先說結論,後面分析這些結論是怎麼來的
- 低一致性需求:使用Redis自帶的記憶體淘汰機制
- 高一致性需求:主動更新,並以超時剔除作為兜底方案
- 讀操作:
- 緩存命中則直接返回
- 緩存未命中則查詢資料庫,並寫入緩存,設定超時時間
- 寫操作:
- 先寫資料庫,然後再刪除緩存
- 要確保資料庫與緩存操作的原子性(單體系統寫庫操作和刪除緩存操作放入一個事務;分散式系統使用分散式事務管理這二者)
- 讀操作:
主動更新策略:資料庫與緩存不一致問題
由於我們的緩存的數據源來自於資料庫,而資料庫的數據是會發生變化的。因此,如果當資料庫中數據發生變化,而緩存卻沒有同步,此時就會有一致性問題存在,其後果是:
用戶使用緩存中的過時數據,就會產生類似多線程數據安全問題,從而影響業務,產品口碑等;怎麼解決呢?有如下幾種方案

Cache Aside Pattern 人工編碼方式:緩存調用者在更新完資料庫後再去更新緩存,也稱之為雙寫方案。這種由我們自己編寫,所以可控,因此此種方式勝出
Read/Write Through Pattern : 由系統本身完成,資料庫與緩存的問題交由系統本身去處理
Write Behind Caching Pattern :調用者只操作緩存,其他線程去非同步處理資料庫,實現最終一致
Cache Aside 人工編碼 解決資料庫與緩存不一致
由上一節知道資料庫與緩存不一致的解決方案是 Cache Aside 人工編碼,但是這個玩意兒需要考慮幾個問題:
-
刪除緩存還是更新緩存?
-
更新緩存:每次更新資料庫都更新緩存,無效寫操作較多
-
刪除緩存:更新資料庫時讓緩存失效,查詢時再更新緩存(勝出)
-
-
如何保證緩存與資料庫的操作的同時成功或失敗?
- 單體系統,將緩存與資料庫操作放在一個事務
- 分散式系統,利用TCC等分散式事務方案
-
先操作緩存還是先操作資料庫?
-
先刪除緩存,再操作資料庫
-
先操作資料庫,再刪除緩存(勝出)
-
為什麼是先操作資料庫,再刪除緩存?
操作資料庫和操作緩存在“串列”情況下沒什麼太大區別,問題不大,但是:在“併發”情況下,二者就有區別,就會產生資料庫與緩存數據不一致的問題
先看“先刪除緩存,再操作資料庫”:

再看“先操作資料庫,再刪除緩存”:redis操作幾乎是微秒級,所以下圖線程1會很快完成,然後線程2業務一般都慢一點,所以緩存中能極快地更新成資料庫中的最新數據,因此這種方式雖也會發生數據不一致,但幾率很小(資料庫操作一般不會在微秒級別內完成)

因此:勝出的是“先操作資料庫,再刪除緩存”

緩存穿透及解決方式
緩存穿透:指客戶端請求的數據在緩存中和資料庫中都不存在。這樣緩存永遠不會生效,這些請求都會打到資料庫
場景:如別人模仿id,然後發起大量請求,而這些id對應的數據redis中沒有,然後全跑去查庫,資料庫壓力就會增大,導致資料庫扛不住而崩掉
解決方式:
-
緩存空對象:就是緩存和資料庫中都沒有時,直接放個空對象到緩存中,並設置有效期即可
-
優點:實現簡單,維護方便
-
缺點:
- 額外的記憶體消耗
- 可能造成短期的不一致。一開始redis和資料庫都沒有,後面新增了數據,而此數據的id可能恰好對上,這樣redis中存的這id的數據還是空對象
-
-
布隆過濾:採用的是哈希思想來解決這個問題,通過一個龐大的二進位數組,用哈希思想去判斷當前這個要查詢的數據是否存在,如果布隆過濾器判斷存在,則放行,這個請求會去訪問redis,哪怕此時redis中的數據過期了,但是資料庫中一定存在這個數據,在資料庫中查詢出來這個數據後,再將其放入到redis中,假設布隆過濾器判斷這個數據不存在,則直接返回
-
優點:記憶體占用較少,沒有多餘key
-
缺點:
-
實現複雜
-
存在誤判可能。布隆過濾器判斷存在,可資料庫中不一定真存在,因它採用的是哈希演算法,就會產生哈希衝突
-
-
-
增加主鍵id的複雜度,從而提前做好基礎數據校驗
-
做用戶許可權認證
-
做熱點參數限流
空對象和布隆過濾的架構如下:左為空對象,右為布隆過濾

緩存空對象示例:
@Service
public class ShopServiceImpl extends ServiceImpl<ShopMapper, Shop> implements IShopService {
@Resource
private StringRedisTemplate stringRedisTemplate;
@Override
public Result findShopById(Long id) {
String cacheKey = CACHE_SHOP_KEY + id;
// 查 redis
Map<Object, Object> shopMap = stringRedisTemplate.opsForHash().entries(cacheKey);
// 有則返回 同時需要看是否命中的是:空對象
if (!shopMap.isEmpty()) {
return Result.ok(JSONUtil.toJsonStr(shopMap));
}
// 無則查庫
Shop shop = getById(id);
// 庫中無
if (null == shop) {
// 向 redis 中放入 空對象,且設置有效期
Map<String, String> hashMap = new HashMap<>(16);
hashMap.put("", "");
stringRedisTemplate.opsForHash().putAll(cacheKey, hashMap);
// CACHE_NULL_TTL = 2L
stringRedisTemplate.expire(cacheKey, CACHE_NULL_TTL, TimeUnit.MINUTES);
return Result.fail("商鋪不存在");
}
// 庫中有 BeanUtil 使用的是hutool工具
// 這步意思:因為Shop實例類中欄位類型不是均為String,因此需要將欄位值轉成String,否則存入Redis時會發生 造型異常
Map<String, Object> shopMapData = BeanUtil.beanToMap(shop, new HashMap<>(16),
CopyOptions.create()
.ignoreNullValue()
.setIgnoreError(false)
.setFieldValueEditor((filedKey, filedValue) -> filedValue = filedValue + "")
);
// 寫入 redis
stringRedisTemplate.opsForHash().putAll(cacheKey, shopMapData);
// 設置有效期 CACHE_SHOP_TTL = 30L
stringRedisTemplate.expire(cacheKey, CACHE_SHOP_TTL, TimeUnit.MINUTES);
// 返回客戶端
return Result.ok(JSONUtil.toJsonStr(shop));
}
}
緩存雪崩及解決方式
緩存雪崩:指在同一時段大量的緩存key同時失效 或 Redis服務宕機,導致大量請求到達資料庫,帶來巨大壓力

解決方案:
- 給不同的Key的TTL添加隨機值
- 利用Redis集群提高服務的可用性
- 給緩存業務添加降級限流策略
- 給業務添加多級緩存
緩存擊穿及解決方式
緩存擊穿問題也叫熱點Key問題,就是一個被高併發訪問並且緩存重建業務較複雜的key突然失效了,無數的請求訪問會在瞬間給資料庫帶來巨大的衝擊

常見的解決方案有兩種:
- 互斥鎖
- 邏輯過期

互斥鎖 - 保一致
互斥鎖:保一致性,會讓線程阻塞,有死鎖風險
本質:利用了String的setnx指令;key不存在則添加,存在則不操作
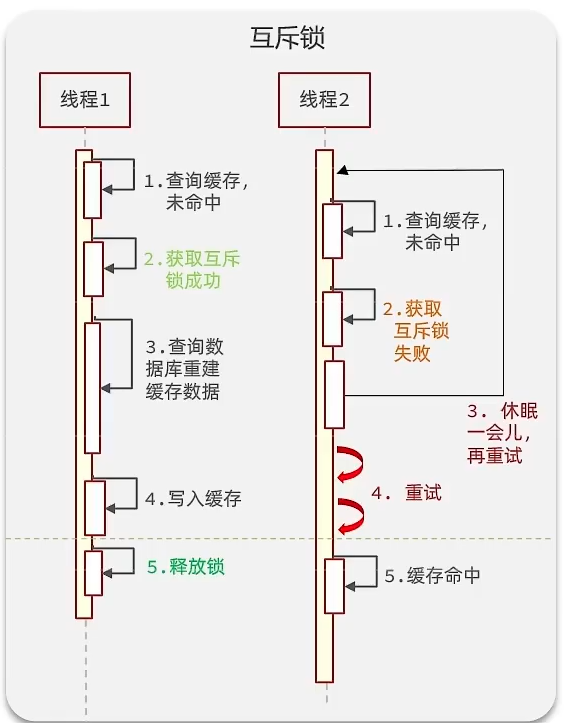
示例:下列邏輯該封裝則封裝即可
public class ShopServiceImpl extends ServiceImpl<ShopMapper, Shop> implements IShopService {
@Resource
private StringRedisTemplate stringRedisTemplate;
@Override
public Result queryShopById(Long id) {
String cacheKey = CACHE_SHOP_KEY + id;
// 查 redis
Map<Object, Object> shopMap = stringRedisTemplate.opsForHash().entries(cacheK


