
本篇文章來源於 ByteHouse 產品專家在火山引擎數智平臺(VeDI)主辦的“數智化轉型背景下的火山引擎大數據技術揭秘”線下 Meeup 的演講,將從 ByteHouse 資料庫架構演進、增強 HaKafka 引擎實現方案、增強 Materialzed MySQL 實現方案、案例實踐和未來展望四... ...
更多技術交流、求職機會,歡迎關註位元組跳動數據平臺微信公眾號,回覆【1】進入官方交流群
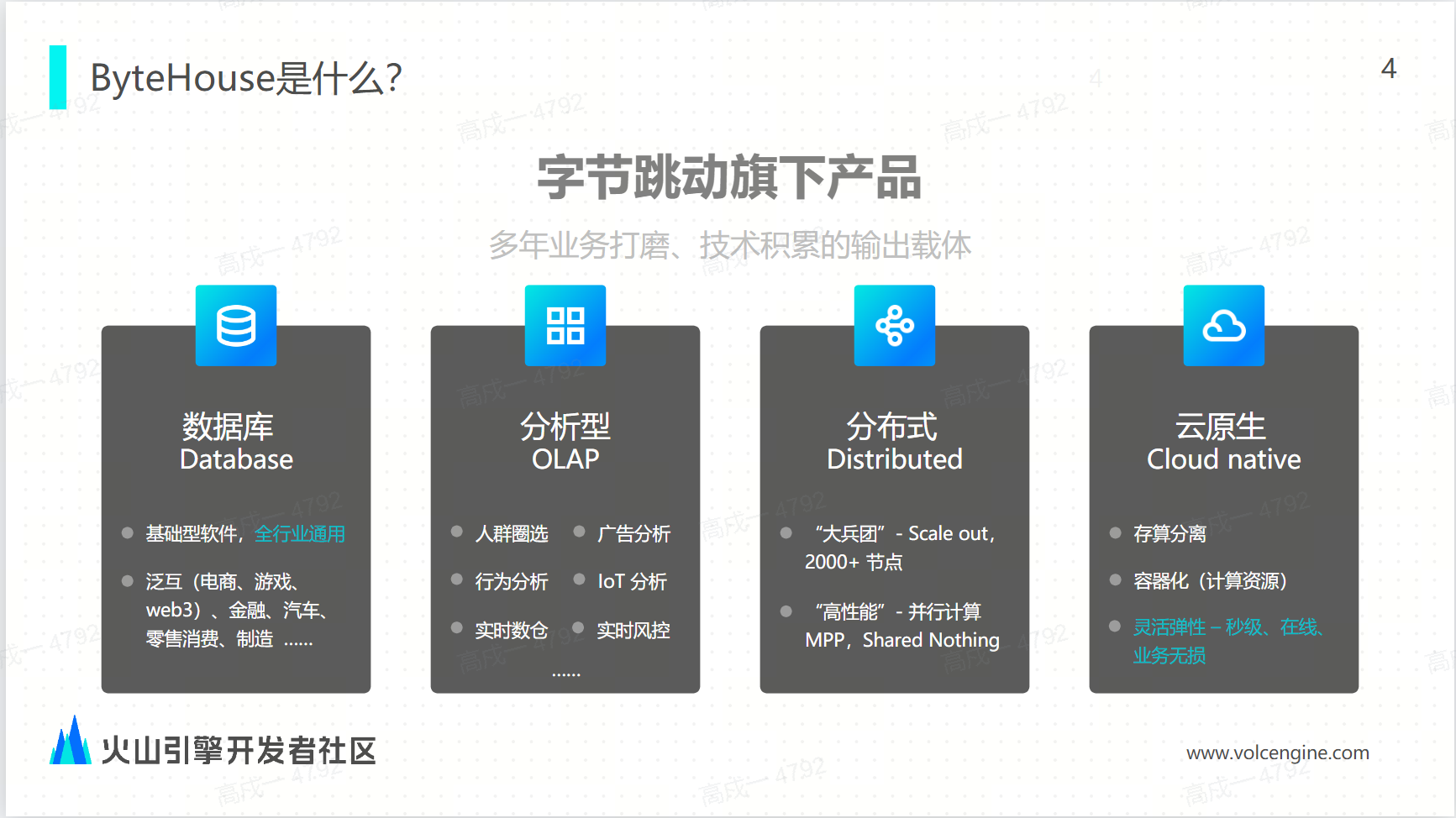
作為企業數字化建設的必備要素,易用的數據引擎能幫助企業提升數據使用效率,更好提升數據應用價值,夯實數字化建設基礎。
數據導入是衡量 OLAP 引擎性能及易用性的重要標準之一,高效的數據導入能力能夠加速數據實時處理和分析的效率。作為一款 OLAP 引擎,火山引擎雲原生數據倉庫 ByteHouse 源於開源 ClickHouse,在位元組跳動多年打磨下,提供更豐富的能力和更強性能,能為用戶帶來極速分析體驗,支撐實時數據分析和海量離線數據分析,具備便捷的彈性擴縮容能力,極致的分析性能和豐富的企業級特性。
隨著 ByteHouse 內外部用戶規模不斷擴大, 越來越多用戶對數據導入提出更高的要求,這也為 ByteHouse 的數據導入能力帶來了更大的挑戰。
本篇文章來源於 ByteHouse 產品專家在火山引擎數智平臺(VeDI)主辦的“數智化轉型背景下的火山引擎大數據技術揭秘”線下 Meeup 的演講,將從 ByteHouse 資料庫架構演進、增強 HaKafka 引擎實現方案、增強 Materialzed MySQL 實現方案、案例實踐和未來展望四個部分展開分享。
ByteHouse 資料庫的架構演進
作為一款分析型資料庫,ByteHouse 已經應用在互聯網、金融、汽車領域,幫助企業實現人群洞察、行為分析、 IOT 風控等場景的實時分析。
ByteHouse 的演進
-
從 2017 年開始,位元組內部的整體數據量不斷上漲,為了支撐實時分析的業務,位元組內部開始了對各種資料庫的選型。經過多次實驗,在實時分析版塊,位元組內部決定開始試水 ClickHouse。
-
2018 年到 2019 年,位元組內部的 ClickHouse 業務從單一業務,逐步發展到了多個不同業務,適用到更多的場景,包括 BI 分析、A/B 測試、模型預估等。
-
在上述這些業務場景的不斷實踐之下,研發團隊基於原生 ClickHouse 做了大量的優化,同時又開發了非常多的特性。
-
2020 年, ByteHouse 正式在位元組跳動內部立項,2021 年通過火山引擎對外服務。
-
截止 2022 年 3 月,ByteHouse 在位元組內部總節點數達到 18000 個,而單一集群的最大規模是 2400 個節點。
ByteHouse 的架構
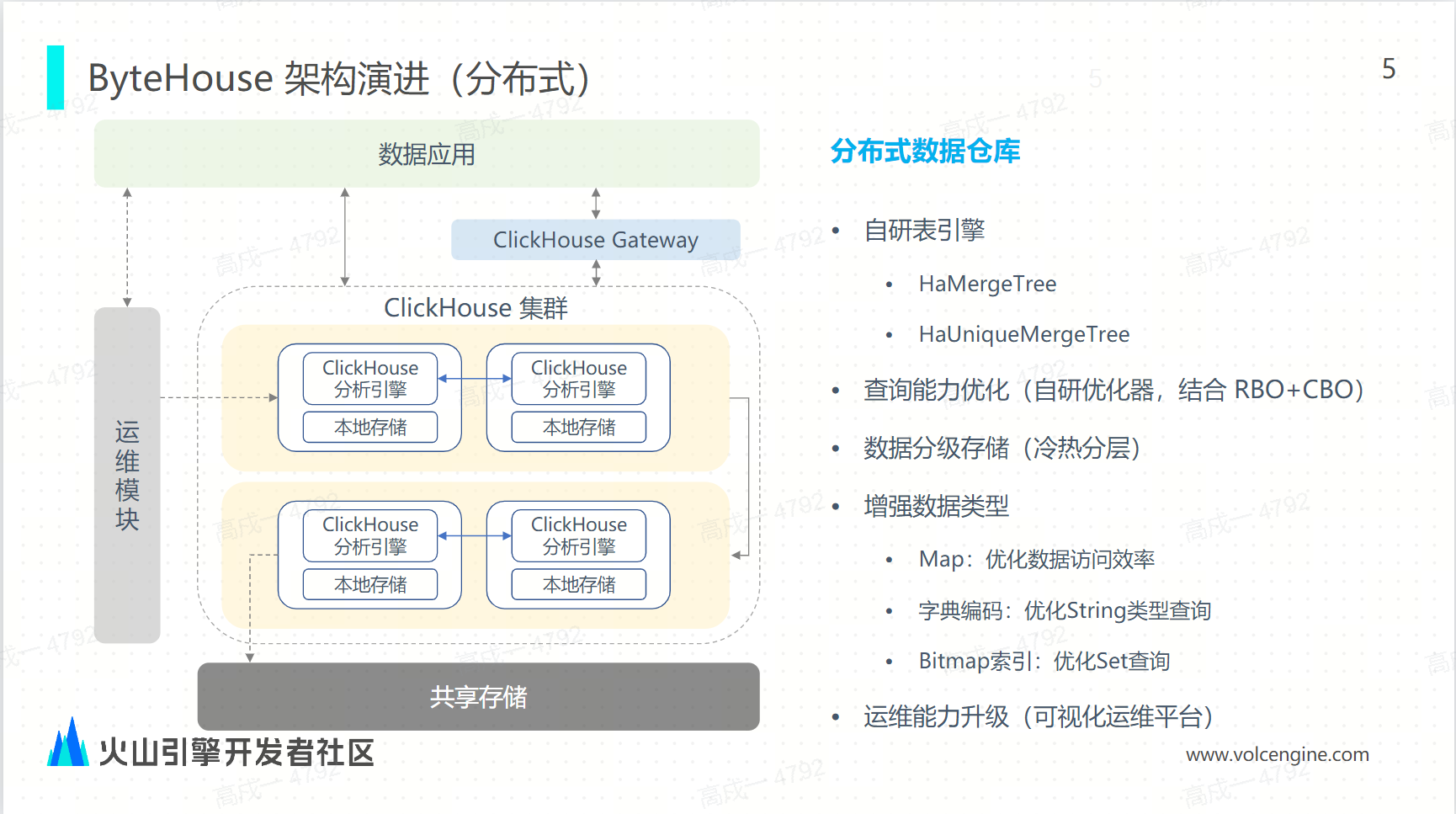
ByteHouse 架構分為分散式架構和雲原生架構兩種。分散式架構的主要特點就是單集群可以支持 2000 多個節點的“大兵團”;通過分散式的並行計算體現的高性能,能夠充分利用每個節點的計算和存儲資源;雲原生實現了存算分離,計算資源通過容器化進行彈性和秒級的擴容,這對業務是無感知的。
從分散式架構來看,ByteHouse 具備 MPP 1.0 特點:
-
存算一體:通過本地存儲能夠保證它極致的這種查詢性能。
-
自研的表引擎:包含 HaMergeTree 和 HaUniqueMergeTree。
-
在社區 RBO 優化器的基礎上增強 RBO 加 CBO 的結合的查詢優化,並基於 CBO 的分散式計劃能夠在集群模式下計算全局最優的查詢計劃。
-
支持數據的冷熱分存,同時兼顧性能和成本。
-
增強關鍵的數據類型,從而優化查詢性能。
-
通過統一的管控面提供可視化的管理查詢和運維,從內到外給用戶提供優質的使用體驗。
但 MPP 1.0 存在資源隔離、擴容等痛點,由此演進到雲原生架構,即 MPP 2.0:其中存算分離通過結合 shared-everything 存儲和 shared-nothing 計算層,避免了傳統 MPP 架構中數據重新分配 (re-sharding) 的問題。
好處在於:
-
更好地實現資源隔離。每個用戶不同的計算都提交到不同的計算組,併進行計算資源和存儲資源的擴容,再結合按量計費的計費策略可以降低用戶使用成本。
-
底層存儲既支持 HDFS,也支持 S3 對象存儲,能夠讓 ByteHouse 實現真正的雲原生。

ByteHouse 技術優勢
在增強型數據導入場景中,ByteHouse 核心優勢體現在自研表引擎:
-
在社區版的基礎上,ByteHouse 對錶引擎做了進一步增強,使其能夠實現開源的 ClickHouse 所做不到的場景。
-
高可用引擎,相比社區高可用引擎,可以支持表的數量更多,集群的規模更大,穩定性會更高。
-
實時數據引擎,相比社區實時數據引擎,消費能力更強,支持 at least once 的語義,排除單點寫入的性能故障。
-
Unique 引擎,相比社區 Unique 引擎,ByteHouse 沒有更新延遲問題,能夠實現真正實時的 upsert。
-
Bitmap 引擎,在特定的場景比如用戶圈選圈群的場景中支持大量的交並補操作,能夠使整體的性能提升 10 - 50 倍以上。

這裡具體再介紹一下 ByteHouse 自研引擎的優勢——與導入密切相關的表引擎。
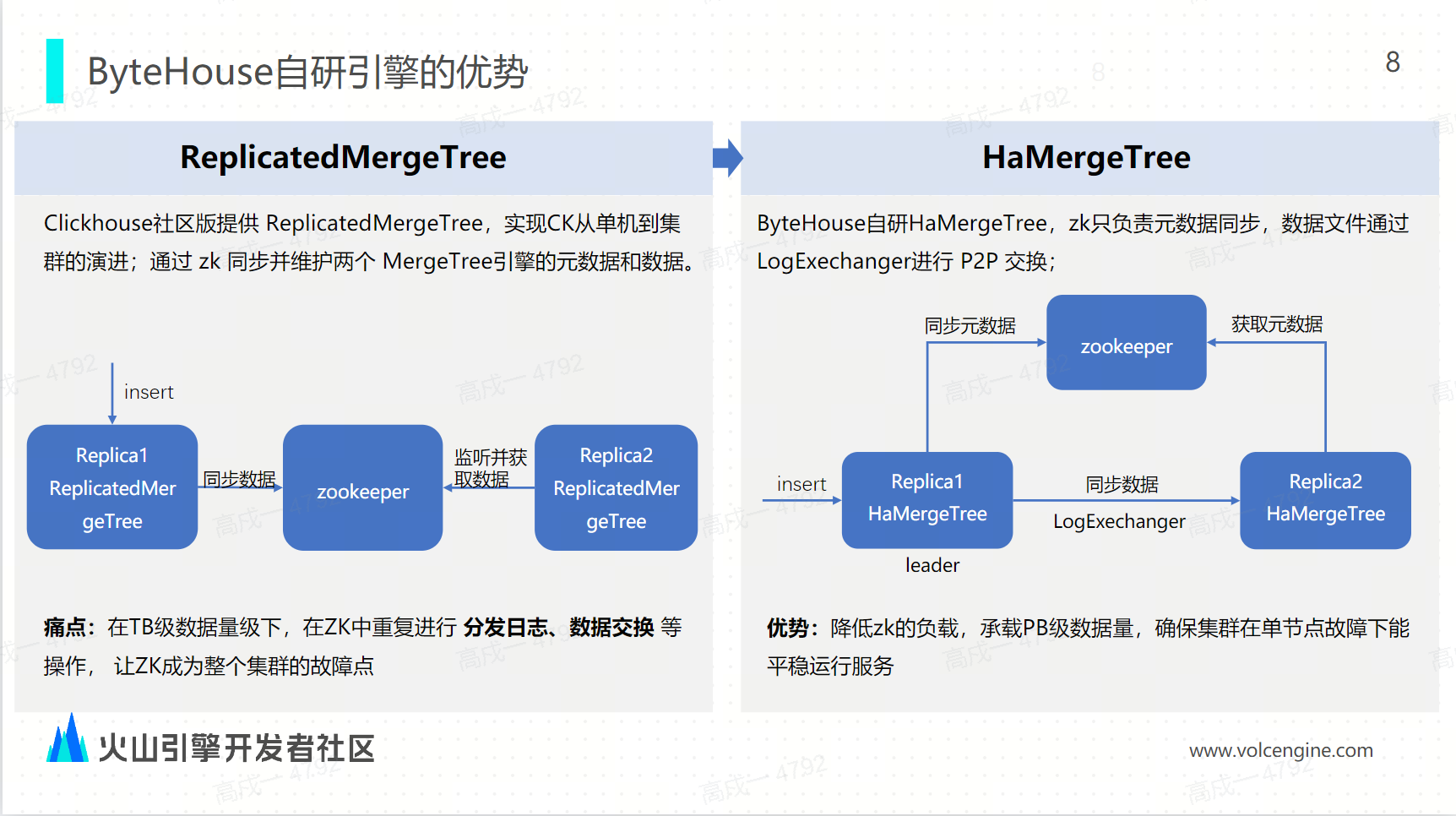
首先,ByteHouse 提供的 HaMergeTree 方案能夠降低 ZK 負載,提升可承載的數據量級。
-
ClickHouse 社區版本:社區提供的 ReplicatedMergeTree 表引擎讓 ClickHouse 實現了從單機到集群的演進,通過 ZK 節點來同步並維護兩個 MergeTree 之間的元數據和數據。痛點在於,在 TB 級的數據量級之下, ZK 重覆地進行分發日誌和數據交換等操作,極大地增加了 ZK 的壓力,使 ZK 成為整個集群的故障點。
-
ByteHouse 自研 HaMergeTree: 將元數據的同步和數據的同步解耦,ZK 只負責元數據的同步,而數據的同步是通過 LogExchange 來實現,在兩個 MergeTree 之間進行對等拷貝。優勢在於,降低了 ZK 的負載,即使是承載 PB 級的數據量,集群也能夠平穩地運行。
其次,ByteHouse 提供的 HaMergeTree 方案能平衡讀寫性能。
-
ClickHouse 社區版本:提供 ReplacingMerge Tree 實現了對唯一鍵的支持;使用 Merge-on-read 的實現邏輯,在不同批次的數據中包含著相同的 key ,需要在讀時做合併,讓相同的 key 返回最新的版本。痛點在於,數據存在延遲、滯後,降低讀的性能。
-
ByteHouse 自研的 HaUniqueMergeTree:引入了 delete bitmap 的組件在數據插入時即標記刪除,然後在數據查詢時過濾掉標記刪除的數據。優勢在於,整體上平衡了讀和寫的性能,保障了讀取時性能一致性。

增強 HaKafka 引擎實現方案
HaKafka 引擎架構介紹
社區版 Kafka 優勢:由於社區版 ClickHouse 是一個分散式結構,其數據分佈在多個 Shard 上,Kafka 引擎可以在多個 Shard 上去做併發的寫入,而在同一個 Shard 內可以啟動多線程做併發寫入,並具備本地盤的極致的性能讀寫。
社區版 Kafka 不足:
-
在內外部業務的場景中,會經常遇到唯一鍵場景,由於社區版本的 Kafka 的 high level 的消費模式(這種模式就決定無法預知數據被寫入到哪一個 Shard 上),所以很難滿足這一類場景。
-
社區版的 Kafka 引擎沒有高可用,即使 ClickHouse 是多副本的,在當一個節點發生宕機時,無法保證另一個節點繼續消費。

HaKafka 引擎架構(分散式架構)
保持社區版本兩級併發兩大的優化點:
-
引入高可用,讓備節點處於 stand-by 的狀態,一旦主節點發生宕機,備節點立刻繼續進行消費。
-
升級為 low-level 的消費模式,當數據寫入的時候,相同的 key 會寫到相同的 partition 裡面,保證在同一個 Shard 下支持的唯一鍵場景。

ByteHouse 增強 HaKafka 引擎核心功能實現
-
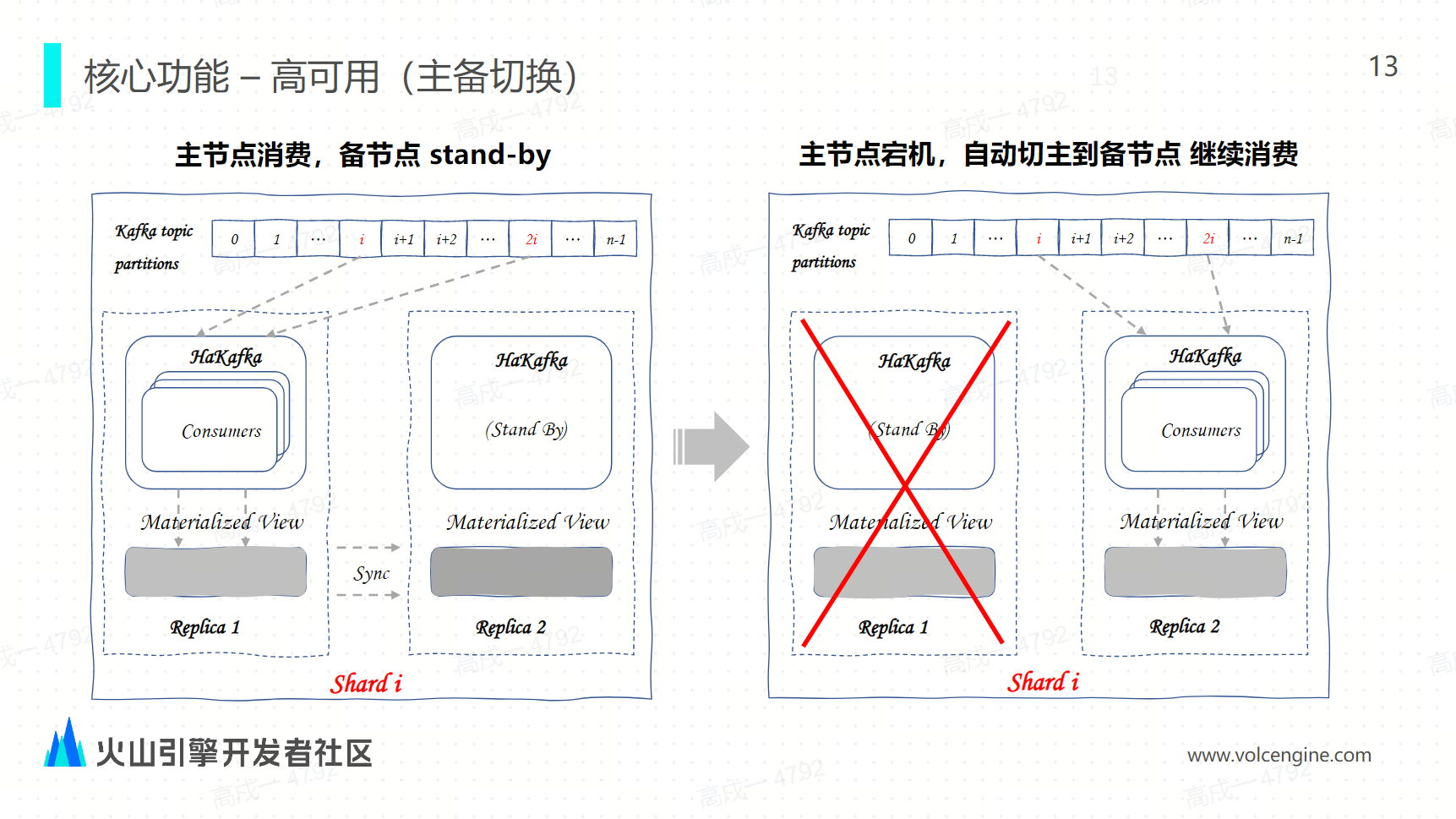
高可用(主備切換)
在備節點上起一個 stand by 的 consumer ,通過 ZK 來進行選組,選到的主節點進行消費,當主節點發生宕機或者無法進行服務時,在秒級之內切換到備節點上,讓備節點繼續消費。
假設現在 replica 1 因為故障宕機了,無法繼續進行消費,那麼 Z K 能在秒級內把 replica 2 選為 leader。 replica 2 隨即會立即啟動相同數量的消費者,啟動之後會繼續從 replica 1 的消費位置開始繼續進行消費。
-
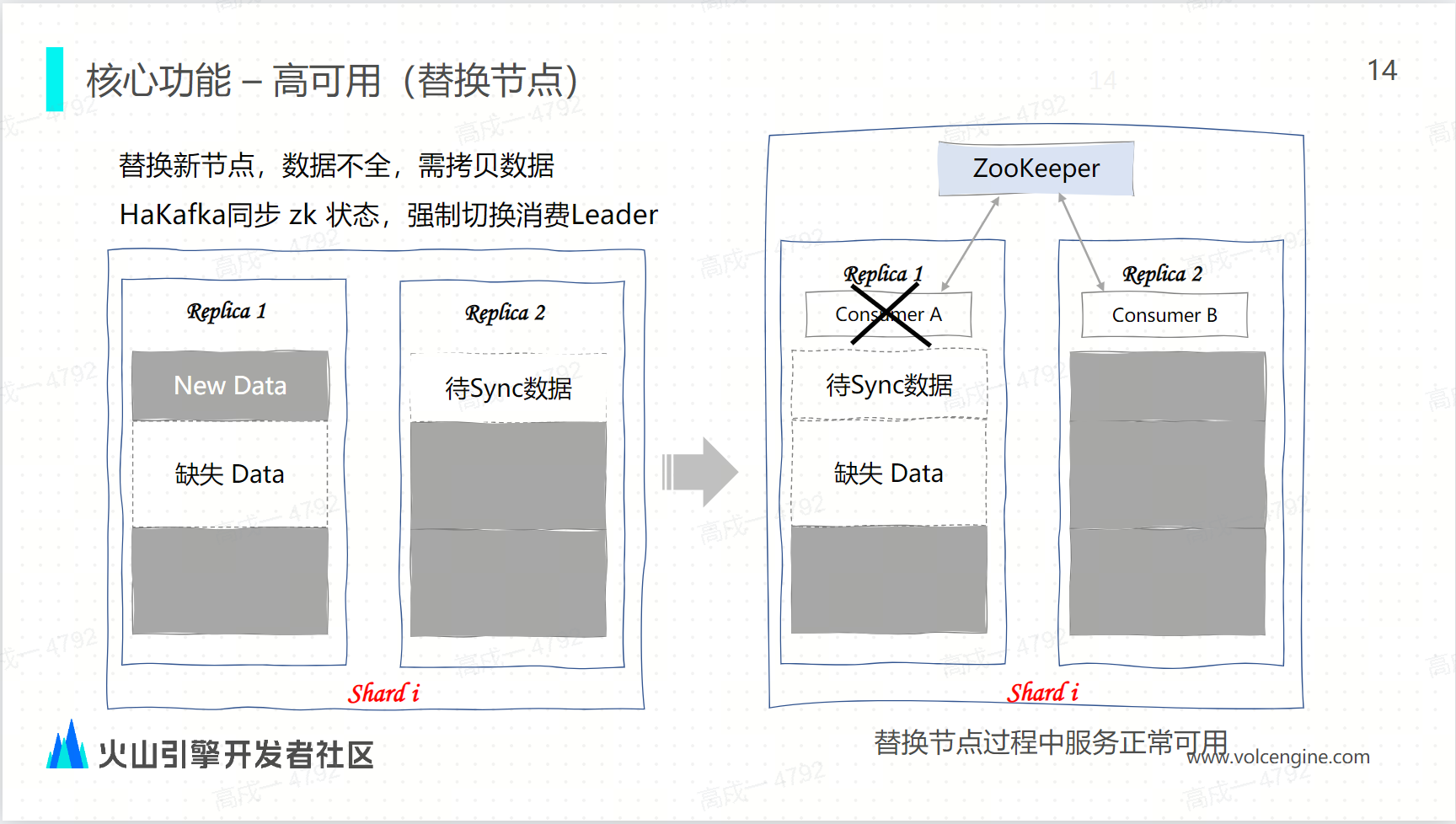
替換節點
隨著集群規模的增大,節點數越來越多的情況下,不可避免地遇到節點故障,這個時候就需要替換節點。
對於分散式架構,替換節點一個重要的操作就是拷貝數據,在拷貝數據的時候意味著新的節點的數據是不全的,如圖示,示意圖 replica 1 為新替換的節點,還處於數據拷貝的狀態,即數據是不全,如果此時實施消費的 leader 起在了 replica 1,就意味著 最新的消費數據會寫進 replica 1,但是它缺失一部分舊的數據。
而 replica 2 有舊的數據,它的最新數據還需要從 replica 1 進行拷貝,那這個時候下載之內沒有一個副本上面的數據是完整的,所有的節點就不可能對外提供服務。
這時 HaKafka 會做強制限制,如果 replica 1 是一個新節點,且還在拷貝數據的狀態,那麼就會強制把 leader 切換成 replica 2,由 replica 2 繼續去消費最新的數據,replica 1 保持繼續拷貝數據,這樣可以保證在節點替換的過程中至少有一個副本是能夠正常提供服務。
-
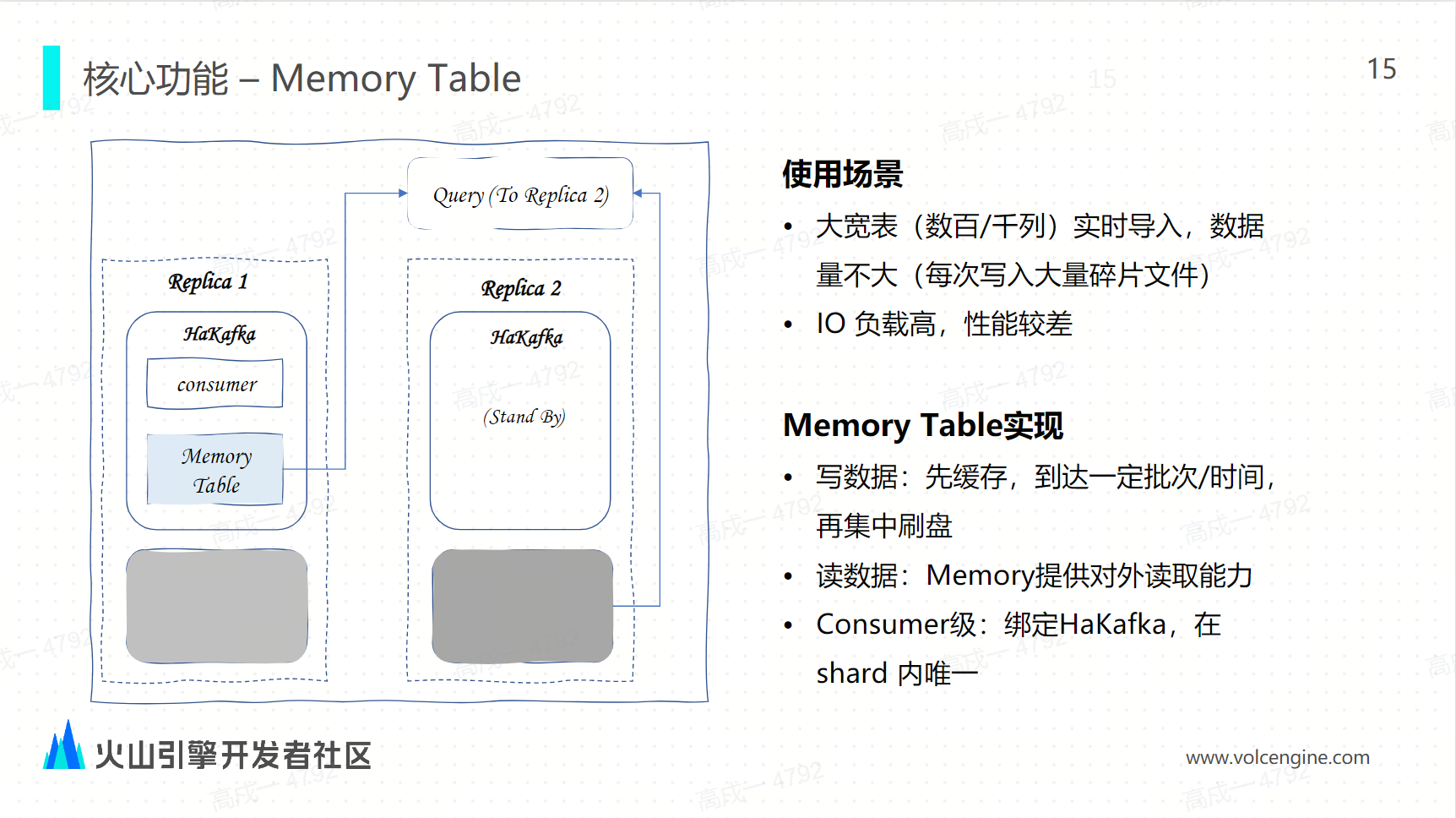
Memory table
不同於社區的 Memory Table 和底層存儲綁定,ByteHouse 的 Memory Table 是和 Hakafka 綁定的,主要使用在有百列或者千列的大寬表的場景。
對於 ClickHouse 來說,每一次導入的寫的文件的數量和列數是成正比的。如果列很多,但是每批次寫入的數據量不大,這時每一次寫入就會造成很多的碎片,這對於 IO 的消耗會比較高,寫入的性能其實也會比較差。
針對這種情況,考慮使用 Memory Table,讓寫不直接落盤,每一次寫先寫到 Memory Table 中,攢到一定的批次或者到達一定的時間之後再一次性刷盤。
當數據寫入 Memory Table 之後,就可以對外提供查詢服務了,因為 memory table 是跟 Kafka 綁定的,在同一個下的內是唯一的。當查詢來了之後,只需要路由到對應的消費節點下 the Memory Table,就能保證了數據查詢的一致性。
-
雲原生架構增強
分散式架構的痛點在於:
1.節點故障:位元組的集群規模較大,每周/每天會遇到節點故障的問題,需要進行節點替換,是一個比較大的負擔。
2.讀寫衝突問題:隨著集群的接入的業務越來越多,數據量越來越大的情況下,每一個節點同時承擔著查詢和寫入的操作,之間會有衝突。
3.擴容成本:唯一鍵的場景對數據分佈要求非常嚴格,擴容在這種場景下很難支持,因為擴容之後 partition 的映射關係發生了變化。
雲原生架構優點在於,存算分離、自動擴容、自動容錯輕量級的擴縮容等,因為雲原生支持事物,讓我們可以將消費語義增強到 exactly once。

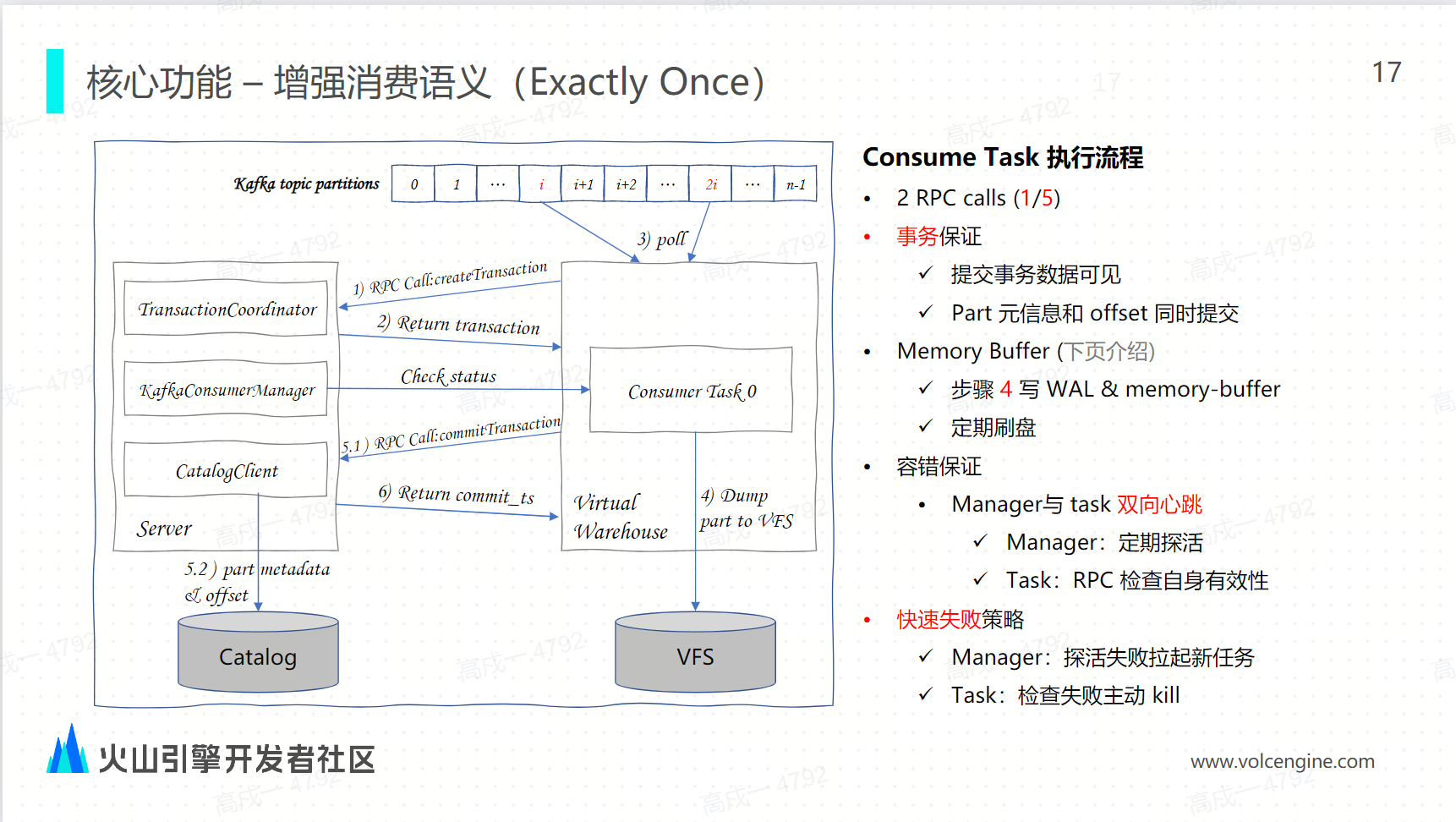
在雲原生架構下的 Kafka 引擎是如何通過事務來實現 exactly once:
-
事務保證:因為雲原生架構有事務的支持,所以每一輪的消費都需要有事物來保證。因為 Catalog 的元信息和 Catalog 元信息的交互是在 Server 端進行的,所以第一步會通過 RPC 的請求向 Server 端請求創建消費事務,然後客戶端創建正常,創建消費事務之後會把 transaction ID 給 consumer, consumer 拿到這種全聲音 ID 之後就可以開始正常地消費了。之後它就會從分配到的 partition 裡面不停地消費數據,當消費到足夠的數據量或者消費滿足一定的時間時,它就會把消費的這數據轉換為對應的 part 文件並 dump 到存儲層。在 dump 之後,數據是不可見的,因為這個時候的 transaction 還沒有提交,所以在第五步的時候,還是會通過一個 RPC 的 call 把剛纔 dump 的元信息消費的 offseed 提交到 catalog 中。這一步是一個原子性的提交,也是我們的消費語義升級從 at least once 到 exactly once 的一個核心關鍵點
容錯保證:因為 manager 和它具體之間的任務是在不同的節點上的,所以需要有一定的這種容錯機制。當前是讓 manager 和 task 之間保持一種一個雙向的心跳機制來保證,比如說 manager 每隔 10 秒鐘會去探活一次,看看當前任務是否正常運行,如果沒有在正常運行,它就會重新拉起一個新的 task。而對於 task 來說,它每一次的消費都會有兩次的 RPC call 和 Server 端做交互,這兩次的 RPC 交互都會向 manager 去校驗自身的有效性,如果校驗到自己當前是一個失效的狀態,它就會把自己 kill 掉,從而保證整個全局的唯一任務的運行。
-
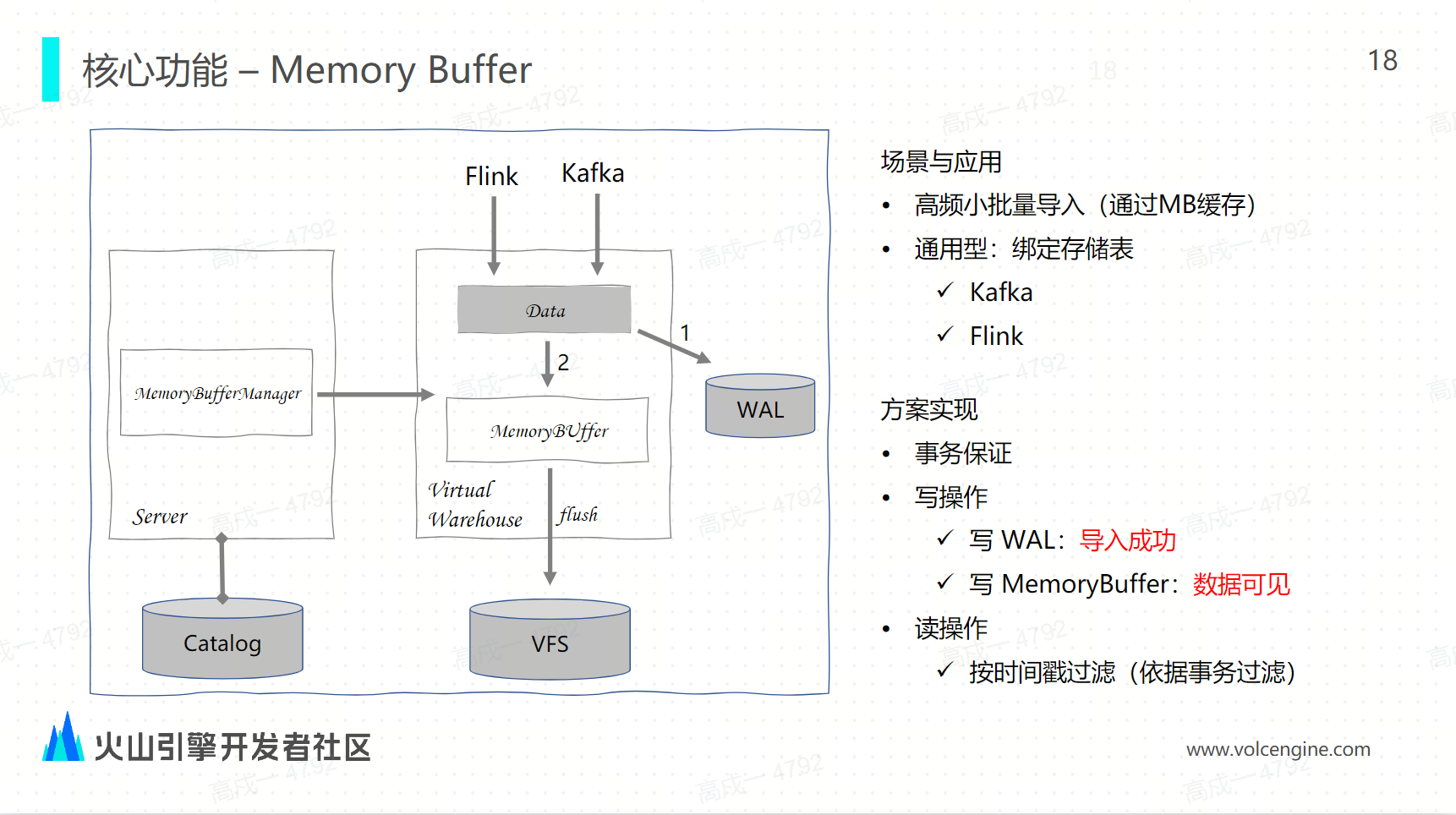
Memory Buffer:與社區相似,Memory Buffer 和底層的存儲表綁定。因為都是寫入底表的,不僅 Kafka 的導入可以用,Flink 的導入也可以用。memory buffer 的使用場景是高頻的小批量的導入場景,因為每一次導入都會寫一個 part,不停地寫 part 會對集群產生壓力。而 ClickHouse 的話,對 ClickHouse 來說 part 越多性能越差,所以使用 memory buffer 來緩存小批量的數據,到達一定批次之後再進行導入。首先需要有一個事務的保證,才能保證導入的完整性和一致性。另外它需要有 WAL,因為首先把數據要先寫到 WAL 中,數據寫入到 WAL 中之後,就認為導入成功了,因為 WAL 本身也是一個持久化的存儲,數據寫入 WAL 之後,再將數據寫入到 memory buffer。當數據寫入了 memory buffer 之後就可以對外提供查詢服務。
增強 Materialzed MySQL 實現方案
社區版 Materialzed MySQL 介紹
物化 MySQL 將 MySQL 的表映射到 ClickHouse 中, ClickHouse 服務會讀取 binlog,並執行 DDL 和 DML 的請求,實現了這種基於實現了基於 MySQL binlog 的實時 CDC 同步。它的架構很簡單,不依賴於數據同步工具,使用自身的資源就能將整個 MySQL 的資料庫同步到 ClickHouse 中,並且時效性很好,因為實時同步的延時一般在秒級、毫秒級到秒級之間。
社區版本的這種物化 MySQL 在很大程度上去解決了 MySQL 資料庫到 ClickHouse 之間的這種實時同步。在實際業務、實際場景中,遇到不少問題:
1.社區版本的物化 MySQL,它是不支持同步到分散式表,也不支持跳過 DDL,缺乏這些功能就很難將資料庫的引擎應用到實際生產中。
2.社區版本的物化 MySQL 不支持在數據同步發生異常時進行輔助,發生異常的時候發起重新同步的命令,它沒有同步的日誌信息和沒有同步的狀態信息,缺少了這些信息會導致同步發生異常的時候,很難在短期內把這些任務重新啟動。
基於這些問題和痛點, ByteHouse 在社區版本的物化 MySQL 的基礎之上做了一些功能增強易用性,降低了運維成本,讓數據的同步更加穩定。

ByteHouse 的物化 MySQL 結合了 HaUniqueMergeTree 表引擎:結合這樣的表引擎之後,它就能夠實現數據的實時去重能力,同時它能夠支持分散式的能力,我們通過底層的中間的參數優化,比如 include tables、 exclude tables、 SKIP DDL 等等能夠允許用戶自定義同步的表的同步範圍。
通過下 model 這樣的一個參數,能夠支持分散式表的同步,然後通過 Rethink 參數的設置支持將額外增加的表啟動獨立的數據同步任務去進行 CDC 同步,在出現異常的時候,我們也支持跳過這種不支持的 DDL 語句。另外,可以通過系統日誌的抓取和展示進行可視化的運維。
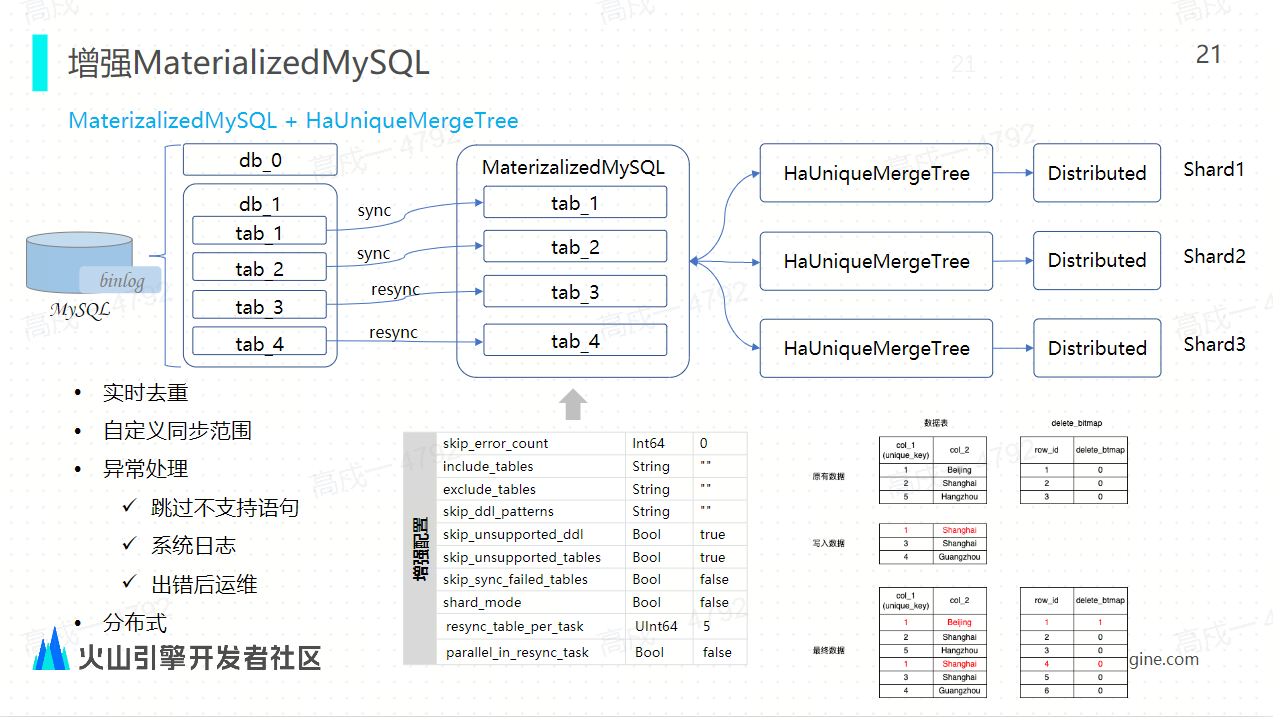
ByteHouse 增強 Materialzed MySQL 核心功能實現
-
實時去重/分散式
社區版的物化 MySQL 使用的是 ReplacingMergeTree,每一個同步任務都會將源端的 MySQL 資料庫同步到 ClickHouse 的某一個節點上面,它不支持按照分片邏輯將數據分佈到所有的節點,也無法利用 ClickHouse 整個集群的分散式計算和存儲能力,所 ByteHouse 的物化 MySQL 支持分散式地同步利用。我們利用 HaUniqueMergeTree 表引擎,將每張表同步到對應的分散式節點上,充分利用集群的這種分散式計算能力,同時通過表引擎的實時 upsert 能力來實現快速地去重。
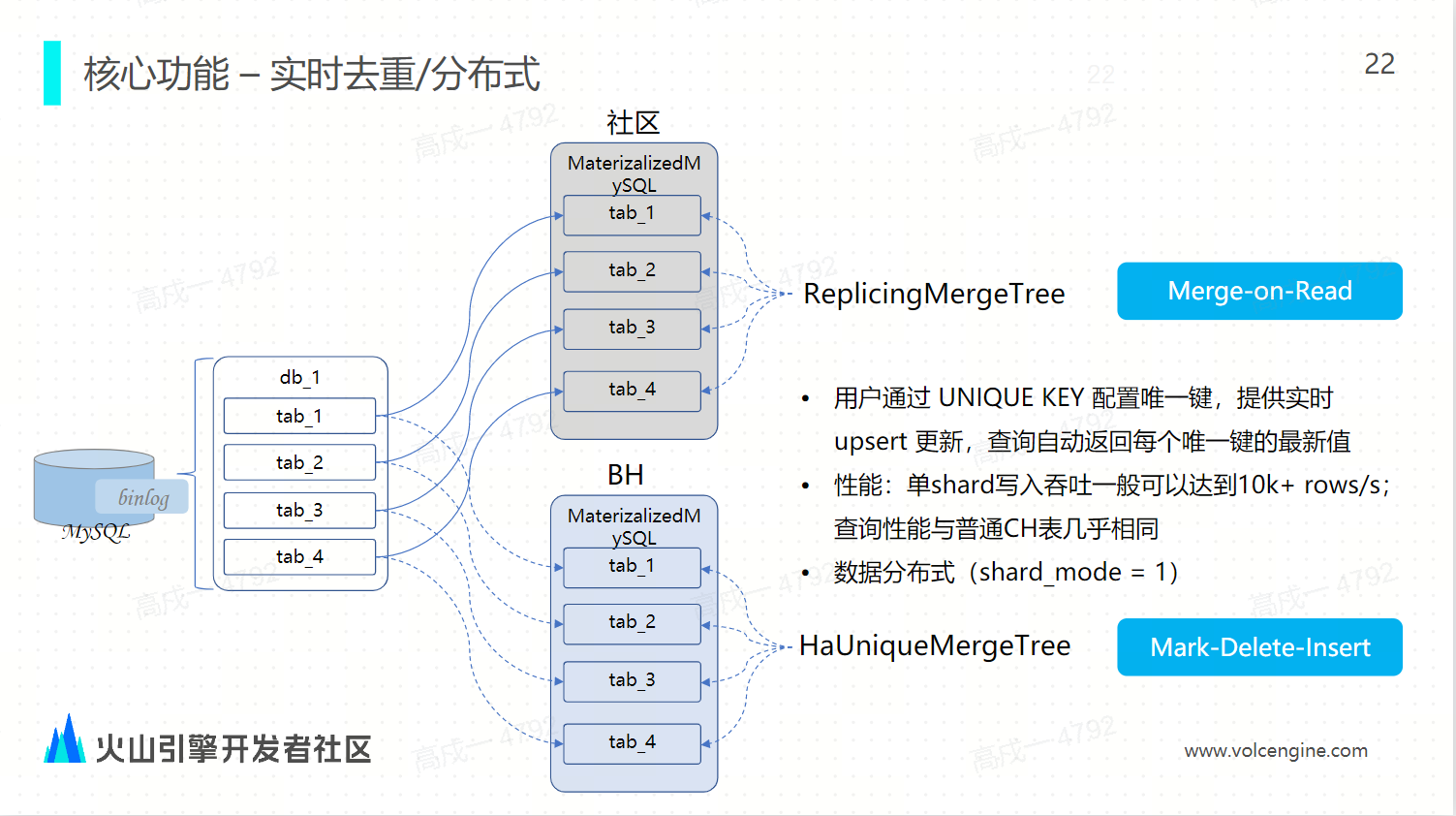
-
非同步 Resync
這裡有三個對象, SYNC manager 是用來管理主 SYNC 線程和 Resync 線程,然後 SYNC task 和 resync task 各自管理各自的任務。比如說一個 MySQL 的庫有 100 張表,我們選了 50 張表進行同步,所以在同步進行過程中,當 think task 同步到 binlog 的 position 位置,比如到 1000 的時候,用戶修改了配置之後,它增加了 30 張表。增加 30 張表的時候, SYNC manager 就會啟動 Resync task 去同步另外 30 張表,那這個時候 SYNC task 是繼續執行的;RESYNC task 會從 position 0 開始,它先做全量的同步,然後再做增量的同步。所以當到達某一個階段,比如說 sync task 跑到了 position 1500 的時候, resync task 跑到了 position 1490 的時候,這時 SYNC manager 就會去判斷兩者的誤差,這個 position 的誤差在一定的閾值之內,在一定閾值之內之後,它會將 SYNC task 停止 1 秒鐘,將 RESYNC task 合併到 SYNC task 中。合併成功之後,這 80 張表就都會通過 SYNC task 繼續同步,而 RESYNC task 這個任務就會被停止掉。這就是現在 RESYNC task 做了一個能力實現。
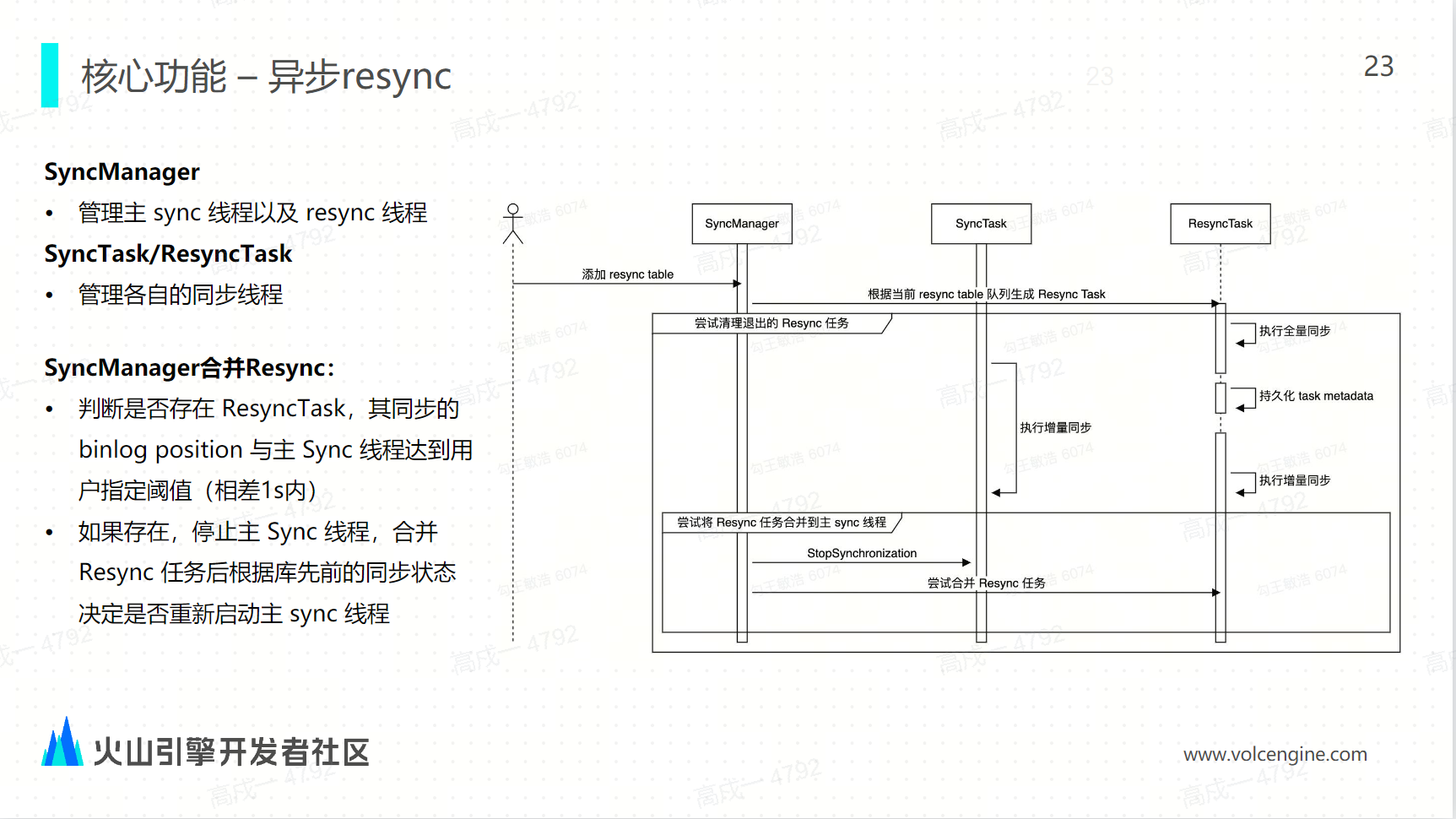
-
可視化運維
通過可視化的任務監控和任務啟停異常的重啟任務告警這些方式實現了物化 MySQL 的可視化易用性的極大提升。
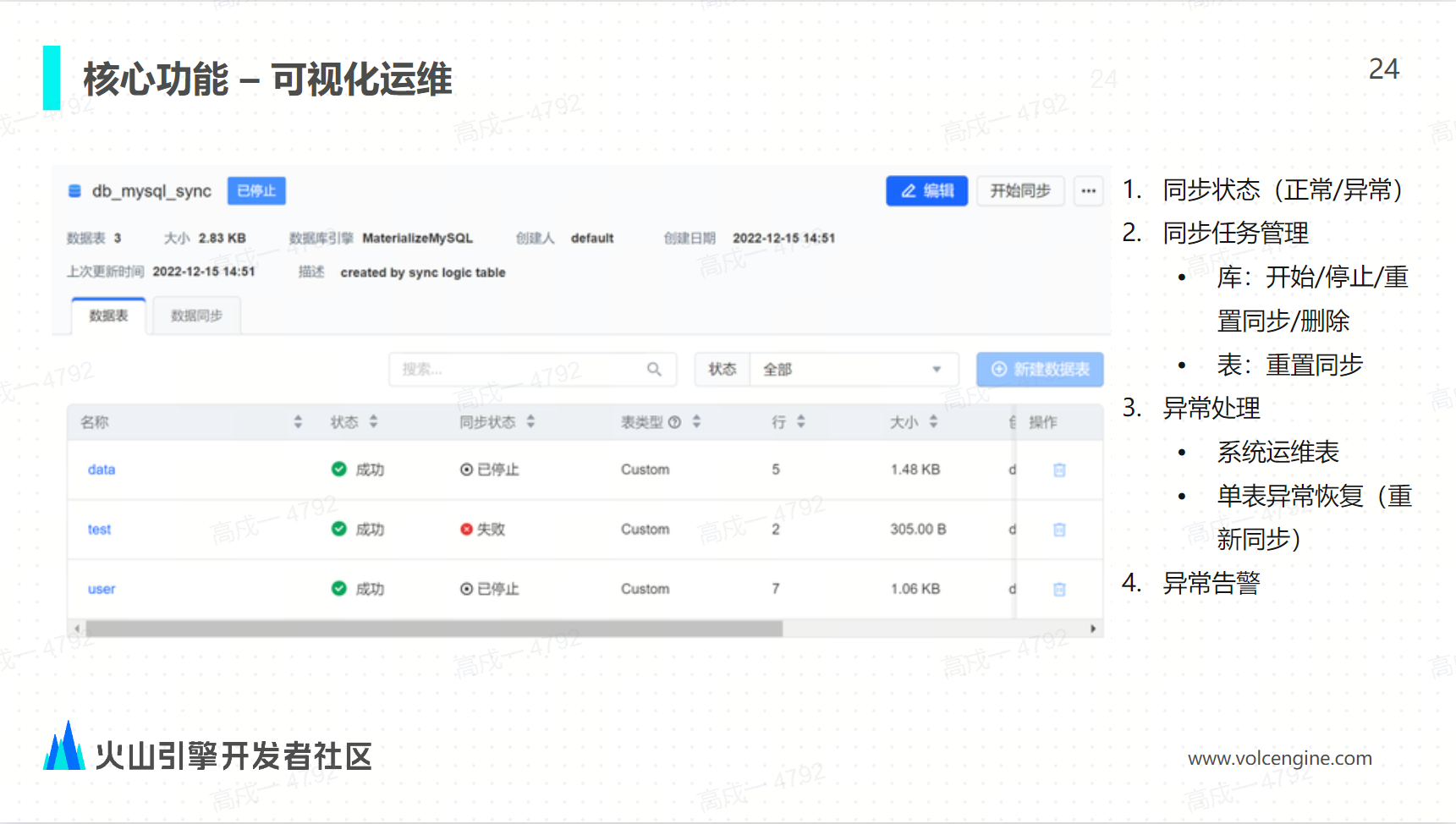
案例實踐與未來展望
案例一:短視頻直播
該場景下的數據是批流一體寫入,為了維護和管理抖音創作者的數據,並且面向這種業務運營和達人經營提供數據查詢服務,需要將短視頻和直播的實時數據和離線數據做融合,來構建 B 端的數據分析。
-
問題:首先,創作者是唯一的,需要我們進行數據去重。第二,數據源是比較多樣化的,所以它整個欄位超過 4000 +,是典型的大寬表場景。第三,T+1 的數據,T+1 數據離線同步後,T+0 數據要對它進行更新。第四,是對任何指標的實時查詢需要秒級出結果,這是業務面臨的問題。
-
解決方案:第一,我們採用了自研的 Unique 表引擎來做實時的去重,並且能夠讓數據在寫入時就可以實時去重、實時查詢。第二,通過 Kafka 引擎的 memory table 來實現大寬表數據先緩存,到達了一定的批次之後再集中刷盤。通過對 Byte house 的優化方案有效地解決了碎片化、IO 負載高的問題,能夠支持 10 億+創作數據實時寫入和實時查詢。

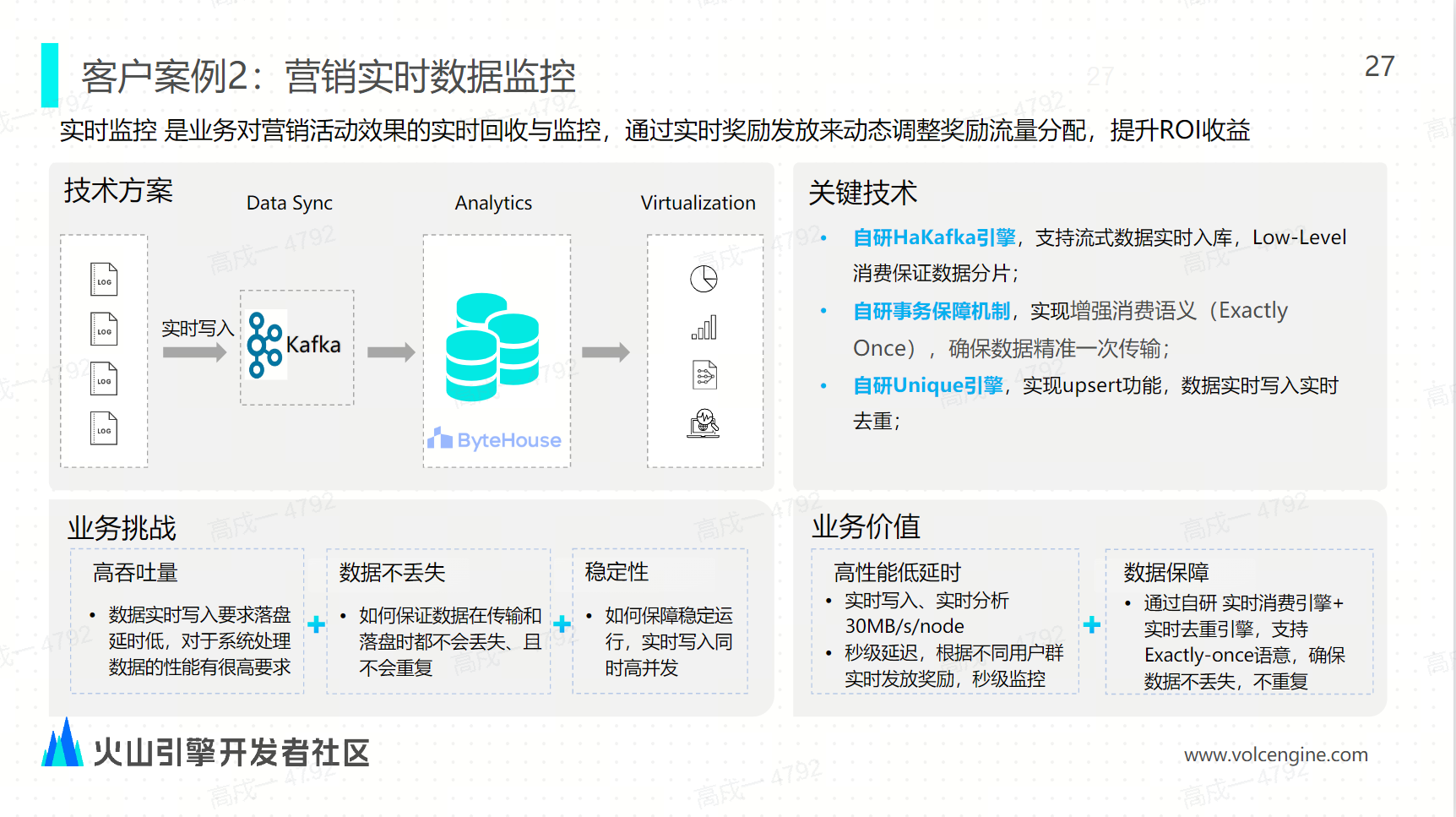
案例二:營銷實時數據的監控
營銷實時監控是對業務營銷活動效果的實時查詢和實時回收,希望通過這種實時回收來動態調整獎品的實時發放策略來做到最終的 IOR、ROI 的提升。這就要求數據實時寫入、落盤延時要非常低,對數據處理的性能也有很高的要求。在數據傳送上面需要保證數據傳輸的唯一性,以保證獎品不會重覆發放,也不會丟失。
-
解決方案:我們在方案上首先採用自研的 Kafka 引擎來支持流式數據的實時寫入,實時寫入便實時入庫。通過 low-level 的這種消費來保證數據的有序分片,再通過增強的消費語義 exactly once 保證數據的精準一次傳輸。最後我們通過自研的 Unique 引擎來實現實時的這種 upsert 的語義,讓數據實時寫入、實時去重。通過 ByteHouse 方案的優化,營銷業務的每一個節點的實時性能達到了 30 MB/s/node,分析性能也是在秒級的延時,讓運營人員能根據不同用戶群,實時發放獎勵,並秒級地監控獎品發放的進展,從而調整獎品的發放策略。
案例三:游戲廣告的數據分析
游戲廣告數據分析是在廣告業務中會做一些人群圈選、廣告投放、效果反饋等投放策略,用戶行為預測這些全流程的統計和監控來實現廣告營銷過程的數字化,提升整個廣告游戲投放的 ROI 。
-
問題:業務數據和日誌數據要求實時寫入、實時去重,由於體量比較大,所以寫入壓力和查詢壓力都比較大。
-
解決方案:首先使用 Kafka 引擎來支持流式數據寫入,通過 low level 消費模式保障數據的有序分片,再通過 Unique 引擎來實現數據的唯一性,並且實時地去重。在業務數據方面,我們使用物化 MySQL 來保障業務數據從 MySQL 到 ByteHouse 之間能夠實時同步。最後使用自研的查詢優化器來優化查詢性能,通過 ByteHouse 的優化之後,廣告效果分析從原來的小時級提升到了現在的秒級延時數據查詢的性能,單線程同步 20+MB/s ,並且整個查詢性能提升了 3 倍,用戶的收益和體驗得到了明顯的改善。

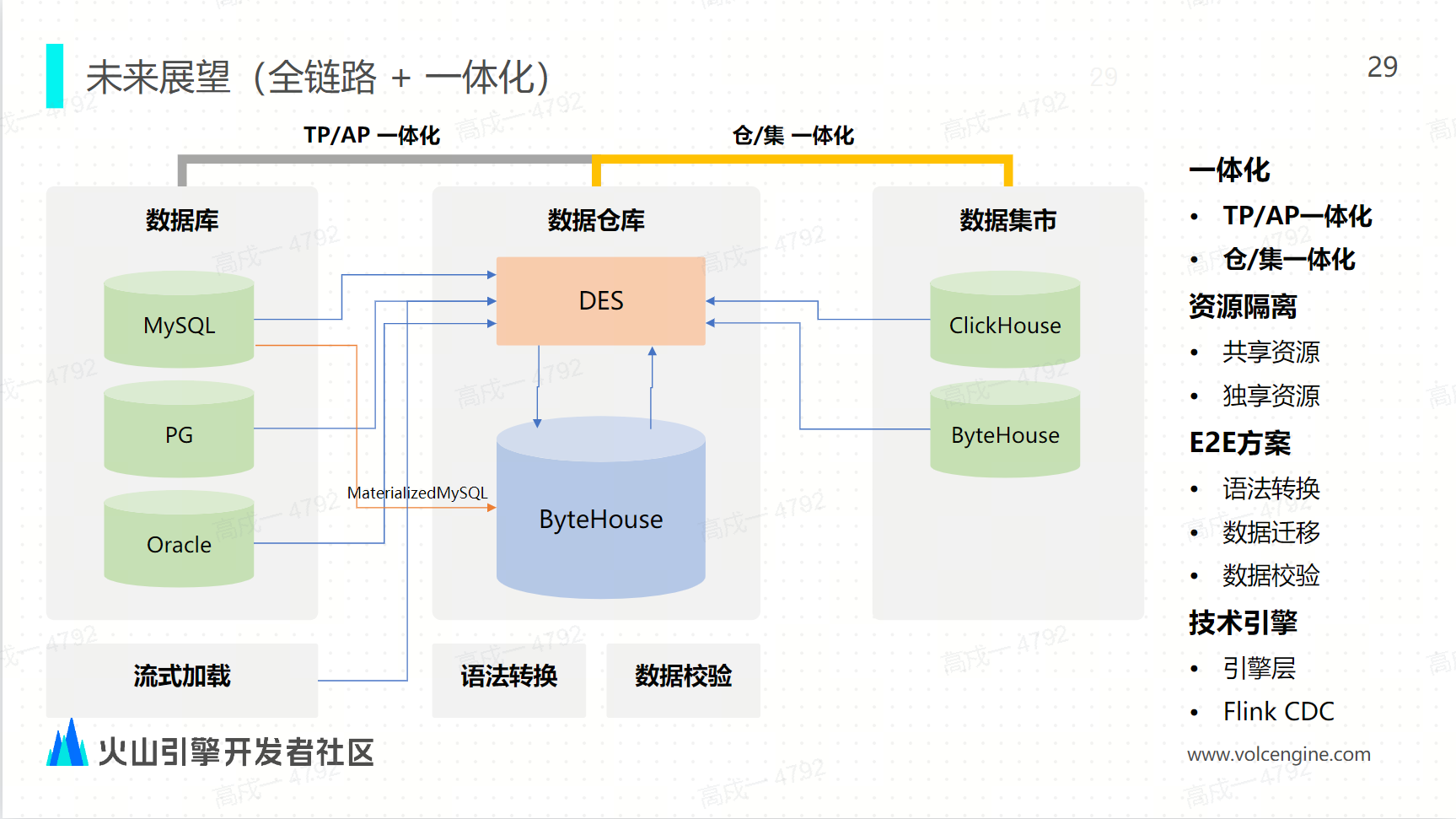
未來戰略:全鏈路和一體化
-
端到端。從語法轉換、數據遷移,到數據校驗,形成完整的全鏈路方案。
-
一體化。通過 DES 的邏輯複製能力實現 TP / AP 的一體化,同時實現數據倉庫和數據集市的一體化。
-
資源隔離。支持用戶使用共用資源池或者資料庫引擎來進行數據的同步,也支持用戶通過獨享的資源池來進行高效數據同步。
-
多引擎方案。除了基於 ClickHouse 引擎的基礎能力,我們也會去探索更多的底層引擎能力來增強 ByteHouse 的數據同步。
點擊跳轉 雲原生數據倉庫ByteHouse 瞭解更多


