
1. 基本信息 高性能MySQL:經過大規模運維驗證的策略(第4版) High Performance MySQL, Fourth Edition [美] Silvia Botros(西爾維亞·博特羅斯);Jeremy Tinley(傑里米·廷利) 電子工業出版社,2022年10月出版 1.1. 讀 ...
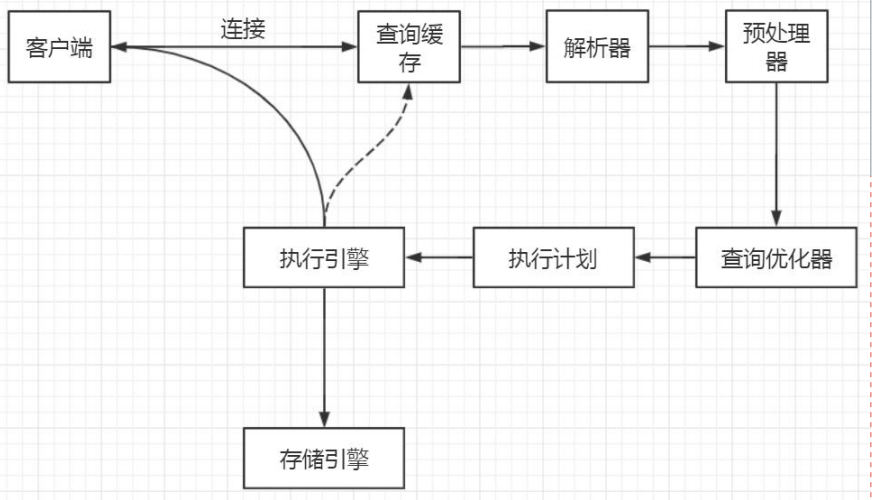
我們的程式或者工具要操作資料庫,第一步要做什麼事情? 跟資料庫建立連接。
首先,MySQL必須要運行一個服務,監聽預設的3306埠。在我們開發系統跟第三方對接的時候,必須要弄清楚的有兩件事。
-
第一個就是通信協議,比如我們是用HTTP還是WebService還是TCP?
-
第二個是消息格式,比如我們用XML格式,還是JSON格式,還是定長格式?報文頭長度多少,包含什麼內容,每個欄位的詳細含義。
MySQL是支持多種通信協議的,可以使用同步/非同步的方式,支持長連接/短連接。我們分別來看:
同步通信
同步通信依: 賴於被調用方,受限於被調用方的性能。也就是說,應用操作資料庫,線程會阻塞,等待資料庫的返回。一般只能做到一對一,很難做到一對多的通信。
非同步通信
非同步可以避免應用阻塞等待,但是不能節省SQL執行的時間。
如果非同步存在併發,每一個SQL的執行都要單獨建立一個連接,避免數據混亂。但是這樣會給服務端帶來巨大的壓力(一個連接就會創建一個線程,線程間切換會占用大量CPU資源)。另外非同步通信還帶來了編碼的複雜度,所以一般不建議使用。如果要非同步,必須使用連接池,排隊從連接池獲取連接而不是創建新連接。
長連接與短連接
MySQL既支持短連接,也支持長連接。短連接就是操作完畢以後,馬上close掉。長連接可以保持打開,減少服務端創建和釋放連接的消耗,後面的程式訪問的時候還可以使用這個連接。一般我們會在連接池中使用長連接。
保持長連接會消耗記憶體。長時間不活動的連接,MySQL伺服器會斷開。
showglobalvariableslike'wait_timeout';--非互動式超時時間,如JDBC程式
showglobalvariableslike'interactive_timeout';--互動式超時時間,如資料庫工具
預設都是28800秒,8小時。
可以用showstatus命令:showglobalstatuslike'Thread%';
Threads_cached:緩存中的線程連接數。
Threads_connected:當前打開的連接數。
Threads_created:為處理連接創建的線程數。
Threads_running:非睡眠狀態的連接數,通常指併發連接數。
MySQL支持哪些通信協議呢?
UnixSocket
比如我們在Linux伺服器上,如果沒有指定-h參數,它就用socket方式登錄(省略了-S/var/lib/mysql/mysql.sock)。
它不用通過網路協議,也可以連接到MySQL的伺服器,它需要用到伺服器上的一個物理文件(/var/lib/mysql/mysql.sock)。
select @@socket;
TCP/IP 協議
我們的編程語言的連接模塊都是用 TCP 協議連接到 MySQL 伺服器的,比如 mysql-connector-java-x.x.xx.jar

2. 語法解析和預處理
為什麼一條 SQL 語句能夠被識別呢?假如我隨便執行一個字元串 penyuyan,伺服器報了一個 1064 的錯, 它是怎麼知道我輸入的內容是錯誤的?
[Err] 1064 - You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the
right syntax to use near 'penyuyan' at line 1
這個就是 MySQL 的 Parser 解析器和 Preprocessor 預處理模塊。 這一步主要做的事情是對語句基於 SQL 語法進行詞法和語法分析和語義的解析。
詞法解析
詞法分析就是把一個完整的 SQL 語句打碎成一個個的單詞。 比如一個簡單的 SQL 語句:
select name from user where id = 1;
它會打碎成 8 個符號,每個符號是什麼類型,從哪裡開始到哪裡結束。
語法解析
語法分析會對 SQL 做一些語法檢查,比如單引號有沒有閉合,然後根據 MySQL 定義的語法規則,根據 SQL 語句生成一個數據結構。這個數據結構我 們把它叫做解析樹(select_lex)。
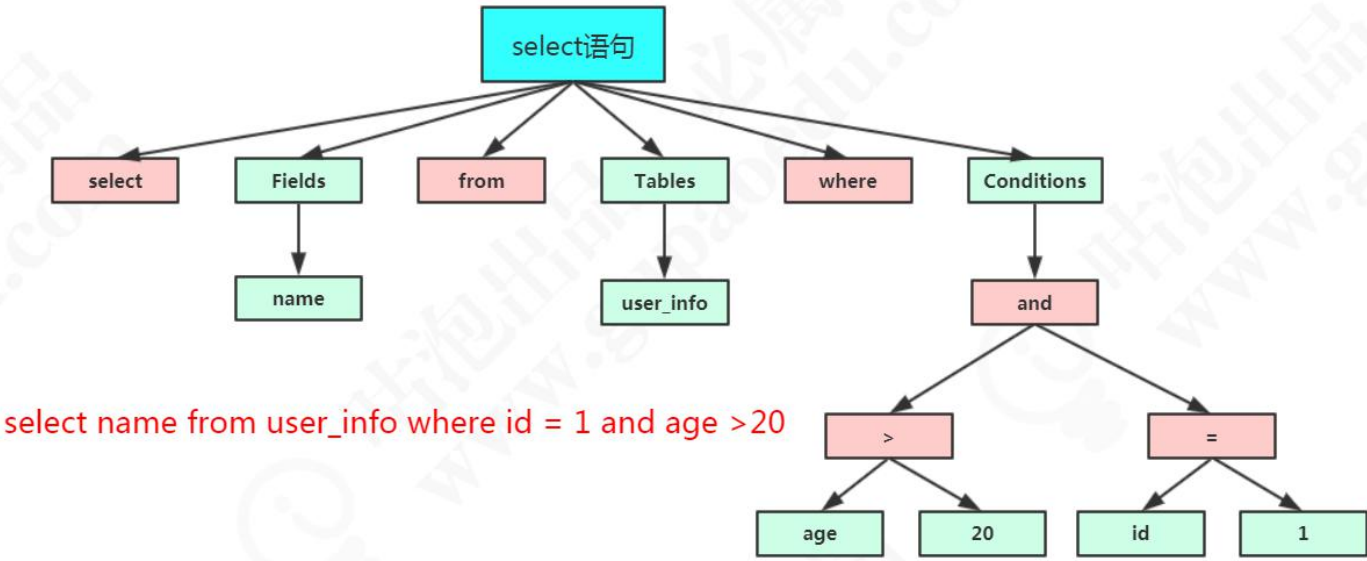 任何資料庫的中間件,比如Mycat,Sharding-JDBC(用到了DruidParser),都必須要有詞法和語法分析功能,在市面上也有很多的開源的詞法解析的工具(比如LEX,Yacc).
任何資料庫的中間件,比如Mycat,Sharding-JDBC(用到了DruidParser),都必須要有詞法和語法分析功能,在市面上也有很多的開源的詞法解析的工具(比如LEX,Yacc).
預處理器
如果我寫了一個詞法和語法都正確的SQL,但是表名或者欄位不存在,會在哪裡報錯?是在資料庫的執行層還是解析器?比如:
select * from xxx;
解析器可以分析語法,但是它怎麼知道資料庫裡面有什麼表,表裡面有什麼欄位呢?實際上還是在解析的時候報錯,解析SQL的環節裡面有個預處理器。 它會檢查生成的解析樹,解決解析器無法解析的語義。比如,它會檢查表和列名是否存在,檢查名字和別名,保證沒有歧義。預處理之後得到一個新的解析樹。
3.查詢優化(QueryOptimizer)與查詢執行計劃
得到解析樹之後,是不是執行SQL語句了呢?這裡我們有一個問題,一條SQL語句是不是只有一種執行方式?或者說資料庫最終執行的SQL是不是就是我們發送的SQL?
這個答案是否定的。一條SQL語句是可以有很多種執行方式的,最終返回相同的結果,他們是等價的。但是如果有這麼多種執行方式,這些執行方式怎麼得到的?最終選擇哪一種去執行?根據什麼判斷標準去選擇?
這個就是MySQL的查詢優化器的模塊(Optimizer)。 查詢優化器的目的就是根據解析樹生成不同的執行計劃(ExecutionPlan),然後選擇一種最優的執行計劃,MySQL裡面使用的是基於開銷(cost)的優化器,那種執行計劃開銷最小,就用哪種。
可以使用這個命令查看查詢的開銷:
showstatus like 'Last_query_cost';
優化器可以做什麼?
舉兩個簡單的例子:
1、當我們對多張表進行關聯查詢的時候,以哪個表的數據作為基準表。 2、有多個索引可以使用的時候,選擇哪個索引。
實際上,對於每一種資料庫來說,優化器的模塊都是必不可少的,他們通過複雜的演算法實現儘可能優化查詢效率的目標。 如果對於優化器的細節感興趣,可以看看《資料庫查詢優化器的藝術-原理解析與SQL 性能優化》。
 但是優化器也不是萬能的,並不是再垃圾的SQL語句都能自動優化,也不是每次都能選擇到最優的執行計劃,大家在編寫SQL語句的時候還是要註意。
但是優化器也不是萬能的,並不是再垃圾的SQL語句都能自動優化,也不是每次都能選擇到最優的執行計劃,大家在編寫SQL語句的時候還是要註意。
優化器是怎麼得到執行計劃的?
首先我們要啟用優化器的追蹤(預設是關閉的):
SHOWVARIABLES LIKE 'optimizer_trace';
set optimizer_trace ='enabled=on';
註意開啟這開關是會消耗性能的,因為它要把優化分析的結果寫到表裡面,所以不要輕易開啟,或者查看完之後關閉它(改成off
接著我們執行一個SQL語句,優化器會生成執行計劃:
select t.tcid from teacher t, teacher_contact tc wheret.tcid=tc.tcid;
這個時候優化器分析的過程已經記錄到系統表裡面了,我們可以查詢:
select * from information_schema.optimizer_trace\G
它是一個JSON類型的數據,主要分成三部分,準備階段、優化階段和執行階段。

expanded_query是優化後的SQL語句。
considered_execution_plans裡面列出了所有的執行計劃。
優化器得到的結果
優化器最終會把解析樹變成一個查詢執行計劃,查詢執行計劃是一個數據結構。當然,這個執行計劃是不是一定是最優的執行計劃呢?不一定,因為MySQL也有可能覆蓋不到所有的執行計劃。
我們怎麼查看MySQL的執行計劃呢?比如多張表關聯查詢,先查詢哪張表?在執行查詢的時候可能用到哪些索引,實際上用到了什麼索引?
MySQL提供了一個執行計劃的工具。我們在SQL語句前面加上EXPLAIN,就可以看到執行計劃的信息。
EXPLAIN select name from user where id=1;
*註意Explain的結果也不一定最終執行的方式。
4.存儲引擎
得到執行計劃以後,SQL語句是不是終於可以執行了? 問題又來了:
1、從邏輯的角度來說,我們的數據是放在哪裡的,或者說放在一個什麼結構裡面?
2、執行計劃在哪裡執行?是誰去執行?
存儲引擎基本介紹
我們先回答第一個問題:在關係型資料庫裡面,數據是放在什麼結構裡面的?
放在表Table裡面的 我們可以把這個表理解成Excel電子錶格的形式。所以我們的表在存儲數據的同時,還要組織數據的存儲結構,這個存儲結構就是由我們的存儲引擎決定的,所以我們也可以把存儲引擎叫做表類型。
查看存儲引擎
比如我們資料庫裡面已經存在的表,我們怎麼查看它們的存儲引擎呢?
show table status from `xxx`;
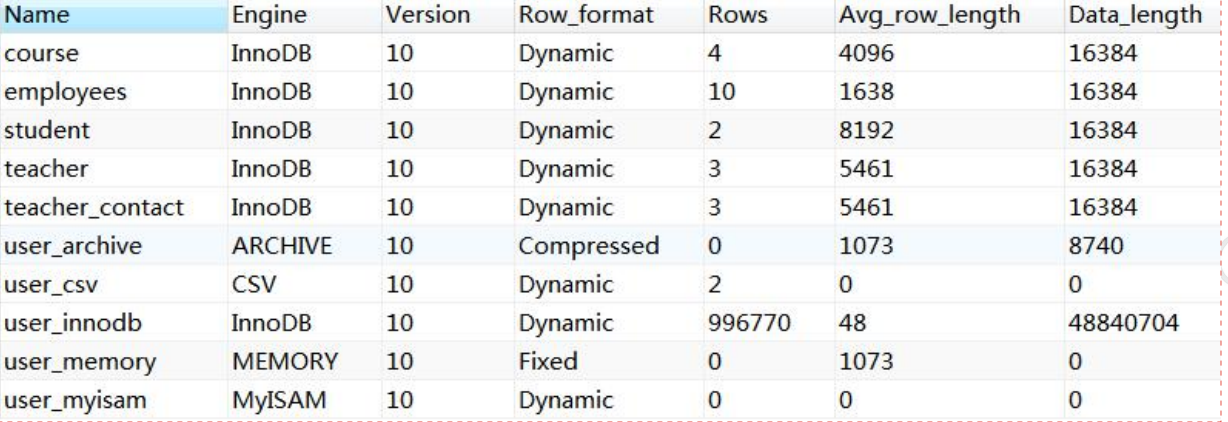
在MySQL裡面,我們創建的每一張表都可以指定它的存儲引擎,而不是一個資料庫只能使用一個存儲引擎。存儲引擎的使用是以表為單位的。而且,創建表之後還可以修改存儲引擎。
我們說一張表使用的存儲引擎決定我們存儲數據的結構,那在伺服器上它們是怎麼存儲的呢?我們先要找到資料庫存放數據的路徑:
showvariableslike'datadir';
預設情況下,每個資料庫有一個自己文件夾,任何一個存儲引擎都有一個frm文件,這個是表結構定義文件。  不同的存儲引擎存放數據的方式不一樣,產生的文件也不一樣,innodb是1個,memory沒有,myisam是兩個。
不同的存儲引擎存放數據的方式不一樣,產生的文件也不一樣,innodb是1個,memory沒有,myisam是兩個。
這些存儲引擎的差別在哪呢?
存儲引擎比較
MyISAM和InnoDB是我們用得最多的兩個存儲引擎,在MySQL5.5版本之前,預設的存儲引擎是MyISAM,它是MySQL自帶的。我們創建表的時候不指定存儲引擎,它就會使用MyISAM作為存儲引擎.
MyISAM的前身是ISAM(IndexedSequentialAccessMethod:利用索引,順序存取數據的方法).
5.5版本之後預設的存儲引擎改成了InnoDB,它是第三方公司為MySQL開發的。為什麼要改呢?最主要的原因還是InnoDB支持事務,支持行級別的鎖,對於業務一致性要求高的場景來說更適合。
MyISAM
應用範圍比較小。表級鎖定限制了讀/寫的性能,因此在Web和數據倉庫配置中,它通常用於只讀或以讀為主的工作。 特點:
-
支持表級別的鎖(插入和更新會鎖表)。不支持事務。
-
擁有較高的插入(insert)和查詢(select)速度。
-
存儲了表的行數(count速度更快)。
InnoDB
mysql5.7中的預設存儲引擎。InnoDB是一個事務安全(與ACID相容)的MySQL 存儲引擎,它具有提交、回滾和崩潰恢復功能來保護用戶數據。InnoDB行級鎖(不升級為更粗粒度的鎖)和Oracle風格的一致非鎖讀提高了多用戶併發性和性能。InnoDB將用戶數據存儲在聚集索引中,以減少基於主鍵的常見查詢的I/O。為了保持數據完整性, InnoDB還支持外鍵引用完整性約束。 特點:
-
支持事務,支持外鍵,因此數據的完整性、一致性更高。
-
支持行級別的鎖和表級別的鎖。
-
支持讀寫併發,寫不阻塞讀(MVCC)。
-
特殊的索引存放方式,可以減少IO,提升查詢效率。
-
適合:經常更新的表,存在併發讀寫或者有事務處理的業務系統.
Memory
將所有數據存儲在RAM中,以便在需要快速查找非關鍵數據的環境中快速訪問。這個引擎以前被稱為堆引擎。其使用案例正在減少;InnoDB及其緩衝池記憶體區域提供了一種通用、持久的方法來將大部分或所有數據保存在記憶體中,而ndbcluster為大型分散式數據集提供了快速的鍵值查找。 特點:
-
把數據放在記憶體裡面,讀寫的速度很快,但是資料庫重啟或者崩潰,數據會全部消失。只適合做臨時表。
CSV
它的表實際上是帶有逗號分隔值的文本文件。csv表允許以csv格式導入或轉儲數據,以便與讀寫相同格式的腳本和應用程式交換數據。因為csv表沒有索引,所以通常在正常操作期間將數據保存在innodb表中,並且只在導入或導出階段使用csv表。 特點: 特點:不允許空行,不支持索引。格式通用,可以直接編輯,適合在不同資料庫之間導入導出。
Archive
這些緊湊的未索引的表用於存儲和檢索大量很少引用的歷史、存檔或安全審計信息。 特點:
-
不支持索引,不支持updatedelete。
如何選擇存儲引擎?
-
如果對數據一致性要求比較高,需要事務支持,可以選擇InnoDB。
-
如果數據查詢多更新少,對查詢性能要求比較高,可以選擇MyISAM。
-
如果需要一個用於查詢的臨時表,可以選擇Memory。
5. 執行引擎
存儲引擎分析完了,它是我們存儲數據的形式,繼續第二個問題,是誰使用執行計划去操作存儲引擎呢?
這就是我們的執行引擎,它利用存儲引擎提供的相應的API來完成操作。
為什麼我們修改了表的存儲引擎,操作方式不需要做任何改變?因為不同功能的存儲引擎實現的API是相同的。


