
如何保持數據一致性 資料庫和緩存(比如:redis)雙寫數據一致性問題,是一個跟開發語言無關的公共問題。尤其在高併發的場景下,這個問題變得更加嚴重。 以下是我無意間瞭解很好的文章,分享給大家。 1. 常見方案 通常情況下,我們使用緩存的主要目的是為了提升查詢的性能。大多數情況下,我們是這樣使用緩存的 ...
如何保持數據一致性
資料庫和緩存(比如:redis)雙寫數據一致性問題,是一個跟開發語言無關的公共問題。尤其在高併發的場景下,這個問題變得更加嚴重。
以下是我無意間瞭解很好的文章,分享給大家。
1. 常見方案
通常情況下,我們使用緩存的主要目的是為了提升查詢的性能。大多數情況下,我們是這樣使用緩存的:
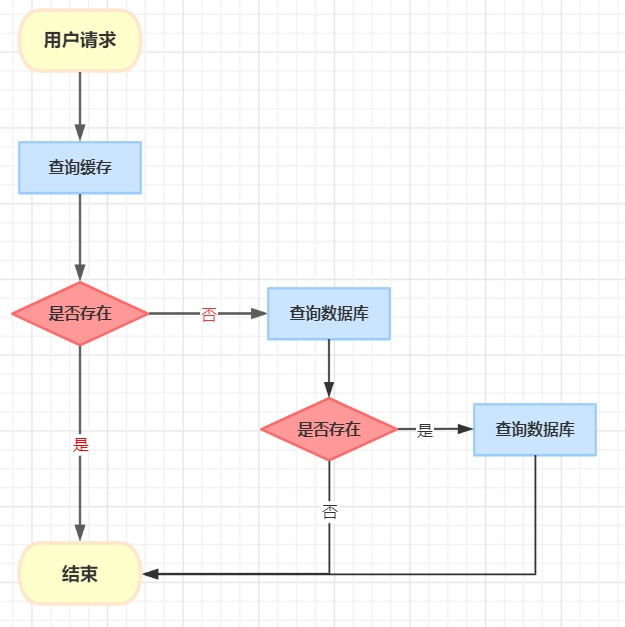
-
用戶請求過來之後,先查緩存有沒有數據,如果有則直接返回。
-
如果緩存沒數據,再繼續查資料庫。
-
如果資料庫有數據,則將查詢出來的數據,放入緩存中,然後返回該數據。
-
如果資料庫也沒數據,則直接返回空。
這是緩存非常常見的用法。一眼看上去,好像沒有啥問題。
但你忽略了一個非常重要的細節:如果資料庫中的某條數據,放入緩存之後,又立馬被更新了,那麼該如何更新緩存呢?
不更新緩存行不行?
答:當然不行,如果不更新緩存,在很長的一段時間內(決定於緩存的過期時間),用戶請求從緩存中獲取到的都可能是舊值,而非資料庫的最新值。這不是有數據不一致的問題?
那麼,我們該如何更新緩存呢?
目前有以下4種方案:
-
先寫緩存,再寫資料庫
-
先寫資料庫,再寫緩存
-
先刪緩存,再寫資料庫
-
先寫資料庫,再刪緩存
接下來,我們詳細說說這4種方案。
2. 先寫緩存,再寫資料庫
對於更新緩存的方案,很多人第一個想到的可能是在寫操作中直接更新緩存(寫緩存),更直接明瞭。
那麼,問題來了:在寫操作中,到底是先寫緩存,還是先寫資料庫呢?
我們在這裡先聊聊先寫緩存,再寫資料庫的情況,因為它的問題最嚴重。
某一個用戶的每一次寫操作,如果剛寫完緩存,突然網路出現了異常,導致寫資料庫失敗了。
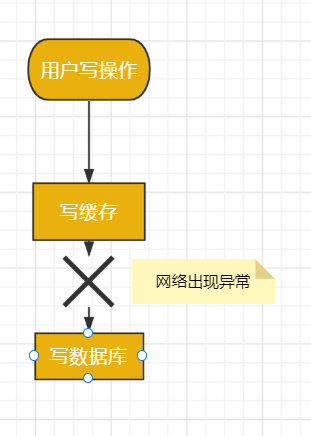
其結果是緩存更新成了最新數據,但資料庫沒有,這樣緩存中的數據不就變成臟數據了?如果此時該用戶的查詢請求,正好讀取到該數據,就會出現問題,因為該數據在資料庫中根本不存在,這個問題非常嚴重。
我們都知道,緩存的主要目的是把資料庫的數據臨時保存在記憶體,便於後續的查詢,提升查詢速度。
但如果某條數據,在資料庫中都不存在,你緩存這種“假數據”又有啥意義呢?
因此,先寫緩存,再寫資料庫的方案是不可取的,在實際工作中用得不多。
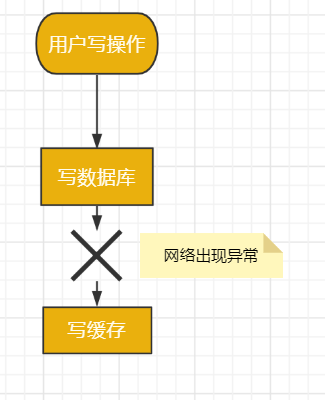
3. 先寫資料庫,再寫緩存
既然上面的方案行不通,接下來,聊聊先寫資料庫,再寫緩存的方案,該方案在低併發編程中有人在用(我猜的)。

用戶的寫操作,先寫資料庫,再寫緩存,可以避免之前“假數據”的問題。但它卻帶來了新的問題。
什麼問題呢?
3.1 寫緩存失敗了
如果把寫資料庫和寫緩存操作,放在同一個事務當中,當寫緩存失敗了,我們可以把寫入資料庫的數據進行回滾。
如果是併發量比較小,對介面性能要求不太高的系統,可以這麼玩。
但如果在高併發的業務場景中,寫資料庫和寫緩存,都屬於遠程操作。為了防止出現大事務,造成的死鎖問題,通常建議寫資料庫和寫緩存不要放在同一個事務中。
也就是說在該方案中,如果寫資料庫成功了,但寫緩存失敗了,資料庫中已寫入的數據不會回滾。
這就會出現:資料庫是新數據,而緩存是舊數據,兩邊數據不一致的情況。
3.1 高併發下的問題
假設在高併發的場景中,針對同一個用戶的同一條數據,有兩個寫數據請求:a和b,它們同時請求到業務系統。
其中請求a獲取的是舊數據,而請求b獲取的是新數據
-
請求a先過來,剛寫完了資料庫。但由於網路原因,卡頓了一下,還沒來得及寫緩存。
-
這時候請求b過來了,先寫了資料庫。
-
接下來,請求b順利寫了緩存。
-
此時,請求a卡頓結束,也寫了緩存。
很顯然,在這個過程當中,請求b在緩存中的新數據,被請求a的舊數據覆蓋了。
也就是說:在高併發場景中,如果多個線程同時執行先寫資料庫,再寫緩存的操作,可能會出現資料庫是新值,而緩存中是舊值,兩邊數據不一致的情況。
3.2 浪費系統資源
該方案還有一個比較大的問題就是:每個寫操作,寫完資料庫,會馬上寫緩存,比較浪費系統資源。
為什麼這麼說呢?
你可以試想一下,如果寫的緩存,並不是簡單的數據內容,而是要經過非常複雜的計算得出的最終結果。這樣每寫一次緩存,都需要經過一次非常複雜的計算,不是非常浪費系統資源嗎?
尤其是cpu和記憶體資源。
還有些業務場景比較特殊:寫多讀少。
如果在這類業務場景中,每個用的寫操作,都需要寫一次緩存,有點得不償失。
由此可見,在高併發的場景中,先寫資料庫,再寫緩存,這套方案問題挺多的,也不太建議使用。
如果你已經用了,趕緊看看踩坑了沒?
4. 先刪緩存,再寫資料庫
通過上面的內容我們得知,如果直接更新緩存的問題很多。
那麼,為何我們不能換一種思路:不去直接更新緩存,而改為刪除緩存呢?
刪除緩存方案,同樣有兩種:
-
先刪緩存,再寫資料庫
-
先寫資料庫,再刪緩存
我們一起先看看:先刪緩存,再寫資料庫的情況。
說白了,在用戶的寫操作中,先執行刪除緩存操作,再去寫資料庫。這套方案,可以是可以,但也會有一樣問題。
4.1 高併發下的問題
假設在高併發的場景中,同一個用戶的同一條數據,有一個讀數據請求c,還有另一個寫數據請求d(一個更新操作),同時請求到業務系統。
-
請求d先過來,把緩存刪除了。但由於網路原因,卡頓了一下,還沒來得及寫資料庫。
-
這時請求c過來了,先查緩存發現沒數據,再查資料庫,有數據,但是舊值。
-
請求c將資料庫中的舊值,更新到緩存中。
-
此時,請求d卡頓結束,把新值寫入資料庫。
在這個過程當中,請求d的新值並沒有被請求c寫入緩存,同樣會導致緩存和資料庫的數據不一致的情況。更正:圖中步驟7寫入舊值,步驟9要刪掉。
那麼,這種場景的數據不一致問題,能否解決呢?
4.2 緩存雙刪
在上面的業務場景中,一個讀數據請求,一個寫數據請求。當寫數據請求把緩存刪了之後,讀數據請求,可能把當時從資料庫查詢出來的舊值,寫入緩存當中。
有人說還不好辦,請求d在寫完資料庫之後,把緩存重新刪一次不就行了?這就是我們所說的緩存雙刪,即在寫資料庫之前刪除一次,寫完資料庫後,再刪除一次。
該方案有個非常關鍵的地方是:第二次刪除緩存,並非立馬就刪,而是要在一定的時間間隔之後。
我們再重新回顧一下,高併發下一個讀數據請求,一個寫數據請求導致數據不一致的產生過程:
-
請求d先過來,把緩存刪除了。但由於網路原因,卡頓了一下,還沒來得及寫資料庫。
-
這時請求c過來了,先查緩存發現沒數據,再查資料庫,有數據,但是舊值。
-
請求c將資料庫中的舊值,更新到緩存中。
-
此時,請求d卡頓結束,把新值寫入資料庫。
-
一段時間之後,比如:500ms,請求d將緩存刪除。
這樣來看確實可以解決緩存不一致問題。
那麼,為什麼一定要間隔一段時間之後,才能刪除緩存呢?
請求d卡頓結束,把新值寫入資料庫後,請求c將資料庫中的舊值,更新到緩存中。
此時,如果請求d刪除太快,在請求c將資料庫中的舊值更新到緩存之前,就已經把緩存刪除了,這次刪除就沒任何意義。必須要在請求c更新緩存之後,再刪除緩存,才能把舊值及時刪除了。
所以需要在請求d中加一個時間間隔,確保請求c,或者類似於請求c的其他請求,如果在緩存中設置了舊值,最終都能夠被請求d刪除掉。
接下來,還有一個問題:如果第二次刪除緩存時,刪除失敗了該怎麼辦?
這裡先留點懸念,後面會詳細說。
5. 先寫資料庫,再刪緩存
從前面得知,先刪緩存,再寫資料庫,在併發的情況下,也可能會出現緩存和資料庫的數據不一致的情況。
那麼,我們只能寄希望於最後的方案了。
接下來,我們重點看看先寫資料庫,再刪緩存的方案。
在高併發的場景中,有一個讀數據請求,有一個寫數據請求,更新過程如下:
-
請求e先寫資料庫,由於網路原因卡頓了一下,沒有來得及刪除緩存。
-
請求f查詢緩存,發現緩存中有數據,直接返回該數據。
-
請求e刪除緩存。
在這個過程中,只有請求f讀了一次舊數據,後來舊數據被請求e及時刪除了,看起來問題不大。
但如果是讀數據請求先過來呢?
-
請求f查詢緩存,發現緩存中有數據,直接返回該數據。
-
請求e先寫資料庫。
-
請求e刪除緩存。
這種情況看起來也沒問題呀?
答:對的。
但就怕出現下麵這種情況,即緩存自己失效了。
-
緩存過期時間到了,自動失效。
-
請求f查詢緩存,發緩存中沒有數據,查詢資料庫的舊值,但由於網路原因卡頓了,沒有來得及更新緩存。
-
請求e先寫資料庫,接著刪除了緩存。
-
請求f更新舊值到緩存中。
這時,緩存和資料庫的數據同樣出現不一致的情況了。
但這種情況還是比較少的,需要同時滿足以下條件才可以:
-
緩存剛好自動失效。
-
請求f從資料庫查出舊值,更新緩存的耗時,比請求e寫資料庫,並且刪除緩存的還長。
我們都知道查詢資料庫的速度,一般比寫資料庫要快,更何況寫完資料庫,還要刪除緩存。所以絕大多數情況下,寫數據請求比讀數據情況耗時更長。
由此可見,系統同時滿足上述兩個條件的概率非常小。
推薦大家使用先寫資料庫,再刪緩存的方案,雖說不能100%避免數據不一致問題,但出現該問題的概率,相對於其他方案來說是最小的。
但在該方案中,如果刪除緩存失敗了該怎麼辦呢?
6. 刪緩存失敗怎麼辦?
其實先寫資料庫,再刪緩存的方案,跟緩存雙刪的方案一樣,有一個共同的風險點,即:如果緩存刪除失敗了,也會導致緩存和資料庫的數據不一致。
那麼,刪除緩存失敗怎麼辦呢?
答:需要加重試機制。
在介面中如果更新了資料庫成功了,但更新緩存失敗了,可以立刻重試3次。如果其中有任何一次成功,則直接返回成功。如果3次都失敗了,則寫入資料庫,準備後續再處理。
當然,如果你在介面中直接同步重試,該介面併發量比較高的時候,可能有點影響介面性能。
這時,就需要改成非同步重試了。
非同步重試方式有很多種,比如:
-
每次都單獨起一個線程,該線程專門做重試的工作。但如果在高併發的場景下,可能會創建太多的線程,導致系統OOM問題,不太建議使用。
-
將重試的任務交給線程池處理,但如果伺服器重啟,部分數據可能會丟失。
-
將重試數據寫表,然後使用elastic-job等定時任務進行重試。
-
將重試的請求寫入mq等消息中間件中,在mq的consumer中處理。
-
訂閱mysql的binlog,在訂閱者中,如果發現了更新數據請求,則刪除相應的緩存。
7. 定時任務
使用定時任務重試的具體方案如下:
-
當用戶操作寫完資料庫,但刪除緩存失敗了,需要將用戶數據寫入重試表中。
-
在定時任務中,非同步讀取重試表中的用戶數據。重試表需要記錄一個重試次數欄位,初始值為0。然後重試5次,不斷刪除緩存,每重試一次該欄位值+1。如果其中有任意一次成功了,則返回成功。如果重試了5次,還是失敗,則我們需要在重試表中記錄一個失敗的狀態,等待後續進一步處理。
-
在高併發場景中,定時任務推薦使用
elastic-job。相對於xxl-job等定時任務,它可以分片處理,提升處理速度。同時每片的間隔可以設置成:1,2,3,5,7秒等。
使用定時任務重試的話,有個缺點就是實時性沒那麼高,對於實時性要求特別高的業務場景,該方案不太適用。但是對於一般場景,還是可以用一用的。
但它有一個很大的優點,即數據是落庫的,不會丟數據。
8. mq
在高併發的業務場景中,mq(消息隊列)是必不可少的技術之一。它不僅可以非同步解耦,還能削峰填谷。對保證系統的穩定性是非常有意義的。
mq的生產者,生產了消息之後,通過指定的topic發送到mq伺服器。然後mq的消費者,訂閱該topic的消息,讀取消息數據之後,做業務邏輯處理。
使用mq重試的具體方案如下:
-
當用戶操作寫完資料庫,但刪除緩存失敗了,產生一條mq消息,發送給mq伺服器。
-
mq消費者讀取mq消息,重試5次刪除緩存。如果其中有任意一次成功了,則返回成功。如果重試了5次,還是失敗,則寫入
死信隊列中。 -
推薦mq使用
rocketmq,重試機制和死信隊列預設是支持的。使用起來非常方便,而且還支持順序消息,延遲消息和事務消息等多種業務場景。
當然在該方案中,刪除緩存可以完全走非同步。即用戶的寫操作,在寫完資料庫之後,不用立刻刪除一次緩存。而直接發送mq消息,到mq伺服器,然後有mq消費者全權負責刪除緩存的任務。
因為mq的實時性還是比較高的,因此改良後的方案也是一種不錯的選擇。
9. binlog
前面我們聊過的,無論是定時任務,還是mq(消息隊列),做重試機制,對業務都有一定的侵入性。
在使用定時任務的方案中,需要在業務代碼中增加額外邏輯,如果刪除緩存失敗,需要將數據寫入重試表。
而使用mq的方案中,如果刪除緩存失敗了,需要在業務代碼中發送mq消息到mq伺服器。
其實,還有一種更優雅的實現,即監聽binlog,比如使用:canal等中間件。
具體方案如下
-
在業務介面中寫資料庫之後,就不管了,直接返回成功。
-
mysql伺服器會自動把變更的數據寫入binlog中。
-
binlog訂閱者獲取變更的數據,然後刪除緩存。
這套方案中業務介面確實簡化了一些流程,只用關心資料庫操作即可,而在binlog訂閱者中做緩存刪除工作。
但如果只是按照圖中的方案進行刪除緩存,只刪除了一次,也可能會失敗。
如何解決這個問題呢?
答:這就需要加上前面聊過的重試機制了。如果刪除緩存失敗,寫入重試表,使用定時任務重試。或者寫入mq,讓mq自動重試。
在這裡推薦使用mq自動重試機制。在binlog訂閱者中如果刪除緩存失敗,則發送一條mq消息到mq伺服器,在mq消費者中自動重試5次。如果有任意一次成功,則直接返回成功。如果重試5次後還是失敗,則該消息自動被放入死信隊列,後面可能需要人工介入

