
背景及需求 之前提到我們模型驅動的實現選擇的是解釋型,需要模型的元數據信息,在接到請求後動態處理邏輯. 此外,應用的通用能力中還包括:頁面dsl查詢,菜單查詢等. 而且後期加入觸發器,用戶自定義api後,這些元數據也需要提供查詢服務. 所以我們需要一個元數據模塊,需要提供兩個基礎功能:載入元數據和提 ...
背景及需求
之前提到我們模型驅動的實現選擇的是解釋型,需要模型的元數據信息,在接到請求後動態處理邏輯.
此外,應用的通用能力中還包括:頁面dsl查詢,菜單查詢等.
而且後期加入觸發器,用戶自定義api後,這些元數據也需要提供查詢服務.
所以我們需要一個元數據模塊,需要提供兩個基礎功能:載入元數據和提供元數據查詢服務.
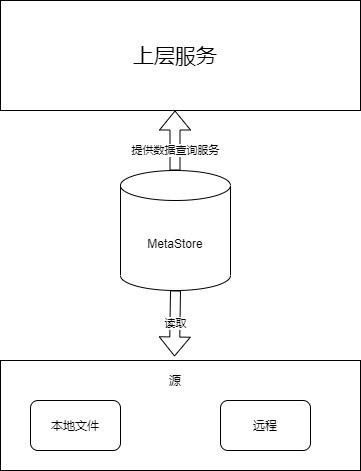
特殊說明:最開始的時候我們支持兩種源:本地和遠程,後期防止單獨部署網路隔離問題把遠程邏輯去掉了.
第一版迭代處理的元數據有:模型,頁面dsl及菜單,後期加入觸發器,用戶自定義api,攔截器等,我們今天按照第一版迭代來討論設計及實現.
模型元數據的需求是緩存一批模型元數據,可以根據模型name獲取模型的具體信息.
頁面dsl的需求是緩存一批頁面dsl,根據dslId獲取頁面dsl信息.
菜單的需求比較簡單,緩存菜單列表和獲取菜單列表.
上邊說的是功能性需求,接著說下非功能性需求:
- 性能,元數據的查詢特別頻繁,必須保證高性能,通常會使用緩存,這也是我們這個模塊的核心價值之一.
- 數據要準確,從MetaStore獲取的數據不能有問題和差異.
- 易於擴展,首先元數據不僅僅有根據id獲取的需求,可能還有其他查詢需求;其次後期加入其他元數據存儲的時候要改動小.
初版設計
設計思路
上邊說了需求,下邊我們開始正式的設計,先選一個具體場景來說:模型元數據.
為了高性能肯定要使用緩存,開發中常用緩存方式有兩種:遠程和本地.
遠程通常使用NoSql的中間件,如Redis和MemCache,在這種場景下肯定不適合.
該場景最適合的方式是使用記憶體緩存,查詢邏輯簡單:根據name或者id獲取,所以直接使用map的數據結構即可.
元數據是在應用啟動時載入,不會再有變動(後期熱部署此處需要重構),利用spring的啟動機制,也不用考慮線程安全問題,直接使用HashMap就可以,這裡應該是利用的jvm的Happens-before原則.
到此,我們確定了緩存的數據結構及介面:

包含一個內部變數cache是HashMAP類型,一個內部方法去載入數據,對外一個介面方法getByKey,功能比較內聚,類設計是沒問題的,下邊我們看下具體的邏輯.
詳細邏輯
getByKey的邏輯是從緩存變數cache中獲取,直接使用map的get方法,不用贅述(此處有坑,下文會有說明),主要看下load載入數據的方法
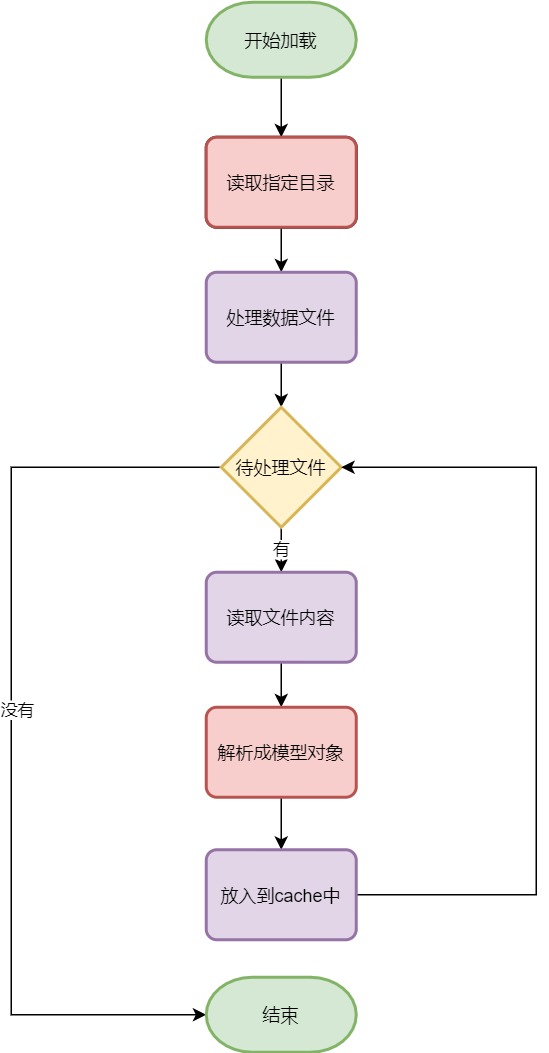
主要邏輯:
-
讀取指定的目錄,可以從配置中獲取,獲取不到使用預設值:models,讀取出目錄下所有文件.
-
開始迴圈處理每個文件,詳細步驟:
-
讀取出文件內容:json格式.
-
json數據轉換成Model對象.
-
把Model對象放入到cache中,key是modelName,value是Model對象.
抽象
當具體方案確定後,如上邊所述的邏輯實現起來並不複雜,甚至可以說是簡單.
但我們在整體看下會發現:模型和頁面dsl的元數據緩存邏輯相似度特別高!
再回頭看下上邊的邏輯流程圖,紫色的部分都是完全相同的,差異只存在與紅色的兩塊邏輯:"讀取指定目錄"和"解析成對象",我們可以把公共的邏輯抽象出去,做成抽象的父類讓子類去繼承,利用了繼承的代碼復用的場景,這是一個典型的模板模式的應用場景.
簡單說下模板模式的定義:在一個方法中定義一個演算法骨架,並將某些步驟推遲到子類中實現,讓子類在不改變演算法整體結構的情況下,重新定義演算法中的某些步驟.
結合我們的場景來說下:演算法骨架就是整體的載入數據流程和獲取元數據方法,子類(ModelMetaStore和PageMetaModel)需要實現骨架中的兩個擴展方法:"讀取指定目錄"和"解析成對象".
第一版設計重構後,類圖如下
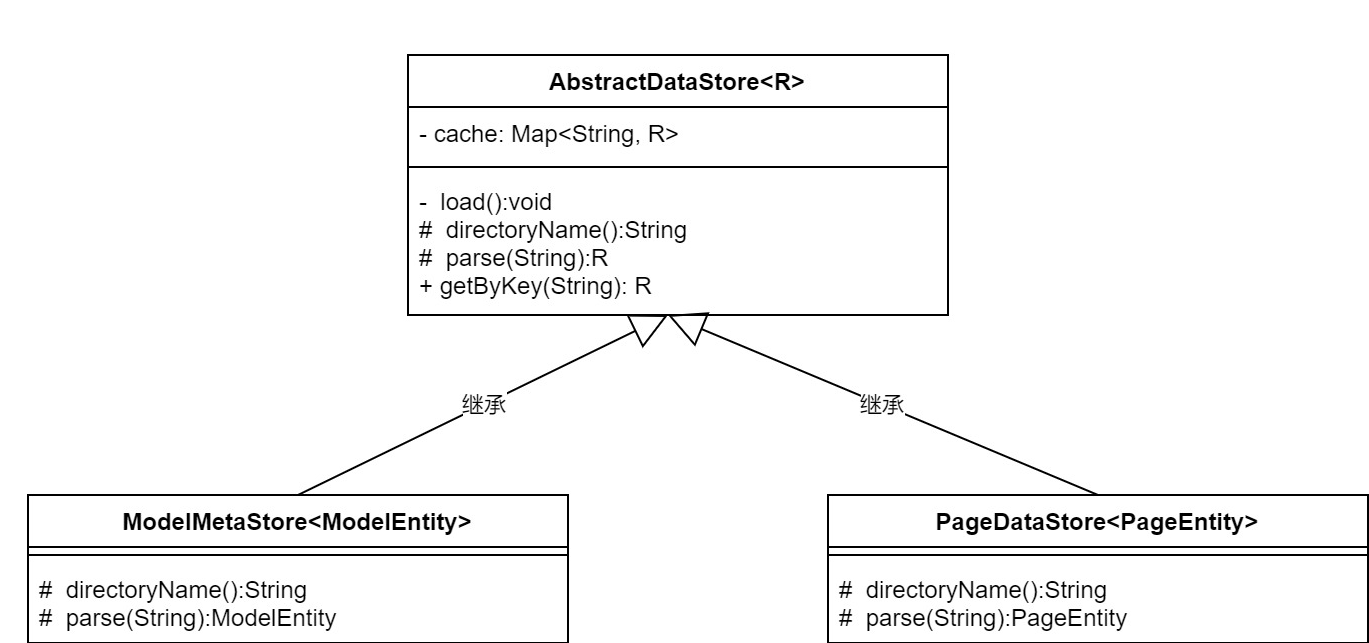
說明:
- 模型數據文件和頁面dsl文件都放到各自的目錄:models和dsls下,上邊兩個目錄是預設的,但可自定義配置.
- 模型數據目錄下的文件類型都是json,文件名是模型名稱.
- 頁面dsl目錄下的文件類型也都是json,文件名是page的id.
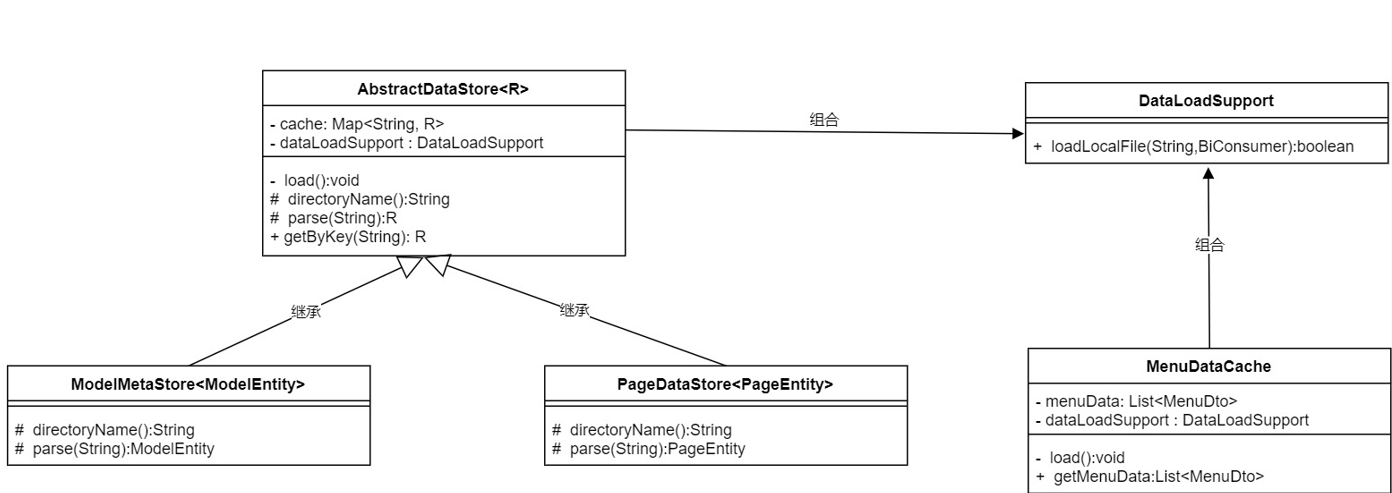
- 抽象出一個父類AbstractDataStore
,泛型是子類的對象類型,包含核心邏輯和骨架.內部有一個map類型的cache變數和一個load私有函數用於載入數據,此外提供了兩個抽象方法,一個是directoryName:獲取文件所在目錄,另一個方式是parse:根據文件內容解析成單個對象,這兩個抽象方法需要子類實現,最後還有一個根據key獲取元數據的公共方法. - ModelMetaStore和PageDataStore繼承了父類AbstractDataStore,泛型分別是ModelEntity和PageEntity,實現上述的兩個抽象方法:directoryName和parse,兩個方法的邏輯都特別簡單,第一個直接返回自己的目錄,第二個利用fastjson把字元串解析成指定對象.
組合
上面把模型和頁面的元數據緩存設計完成了,還有一個菜單的元數據緩存.
菜單的元數據結構與上邊的兩個差異很大,每個應用中只會有一個菜單的元數據文件,所以無法使用上邊的模板模式,我們需要單獨去處理它的邏輯.
實際上菜單的元數據載入邏輯和其他兩個(更準確的說應該是抽象類)有一部分重疊:讀取文件的內容,這裡面需要判斷文件是否為空,讀取內容字元串及io讀取報錯等.
這部分邏輯可以複製出來放到菜單的元數據緩存類中,但實際違背了DRY 原則:不要寫重覆的代碼.
那麼該如何解決這塊重覆代碼的問題呢?有兩個方案:
第一個方案:使用繼承.
在AbstractDataStore
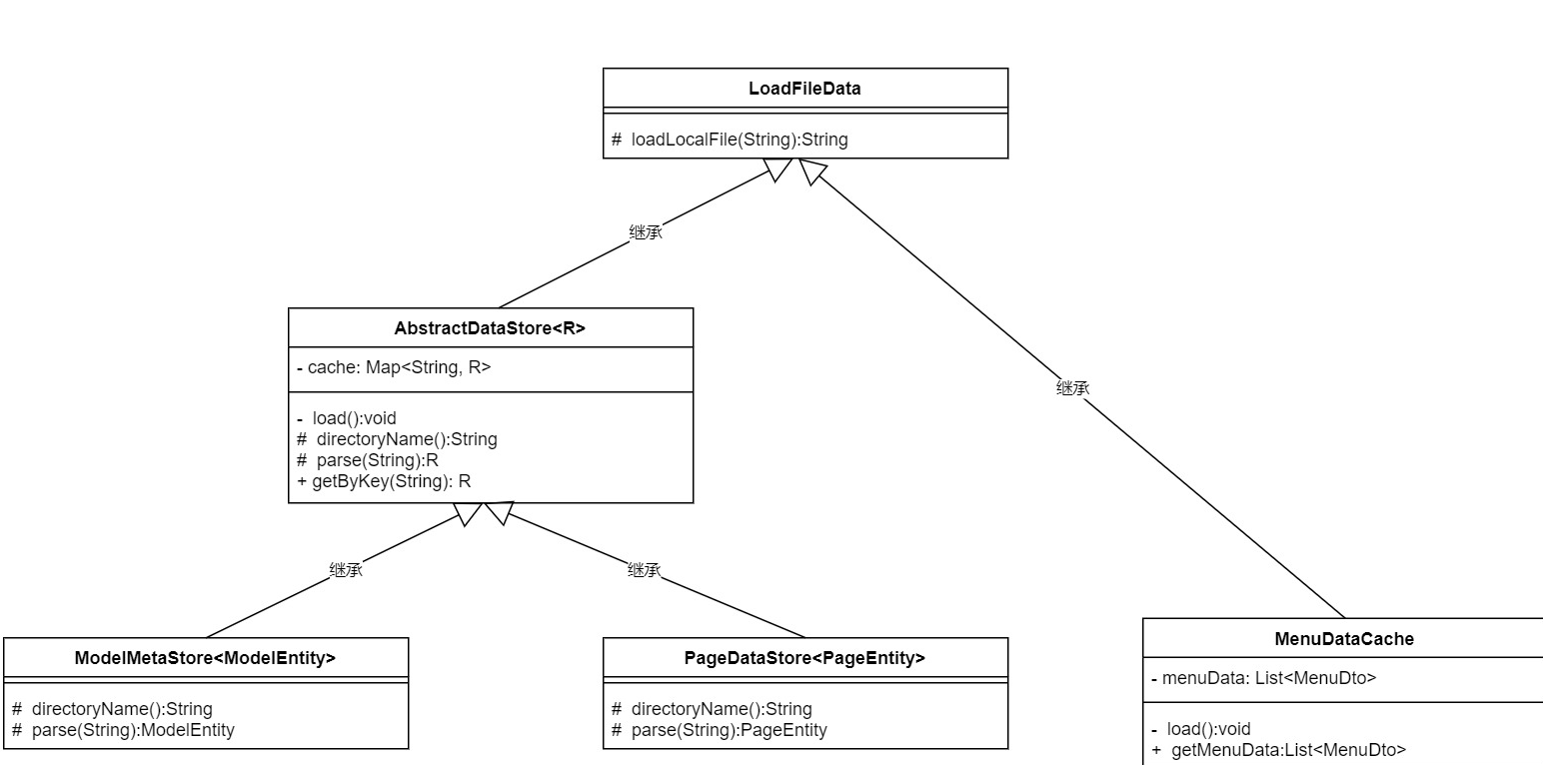
這個方案有兩個問題:
- 繼承層次太深,邏輯有點亂
- 最上層的抽象類很難起名
AbstractDataStore和MenuDataCache繼承LoadFileData從代碼上是可行的,但邏輯上不太合理,抽象繼承是is-a的關係,這裡需要給LoadFileData一個合適的名字才滿足設計規範,而這個名字並不太好起.
第一個方案:使用組合.
這個方案實際上更合理一些,面向對象設計有一個原則:組合優於繼承.
可以把讀取文件內容的邏輯獨立出去作為一個新的幫助類DataLoadSupport,AbstractDataStore和MenuDataCache引入它就可以解決代碼重覆問題.
初始化載入
上一步幾乎完成了所有邏輯,但是少了數據載入的觸發,這個需要放到服務啟動的時候觸發.
我們利用了spring的ApplicationListener,有一個細節問題要確定:如何實現ApplicationListener,是每一個類中單獨實現,還是統一實現.
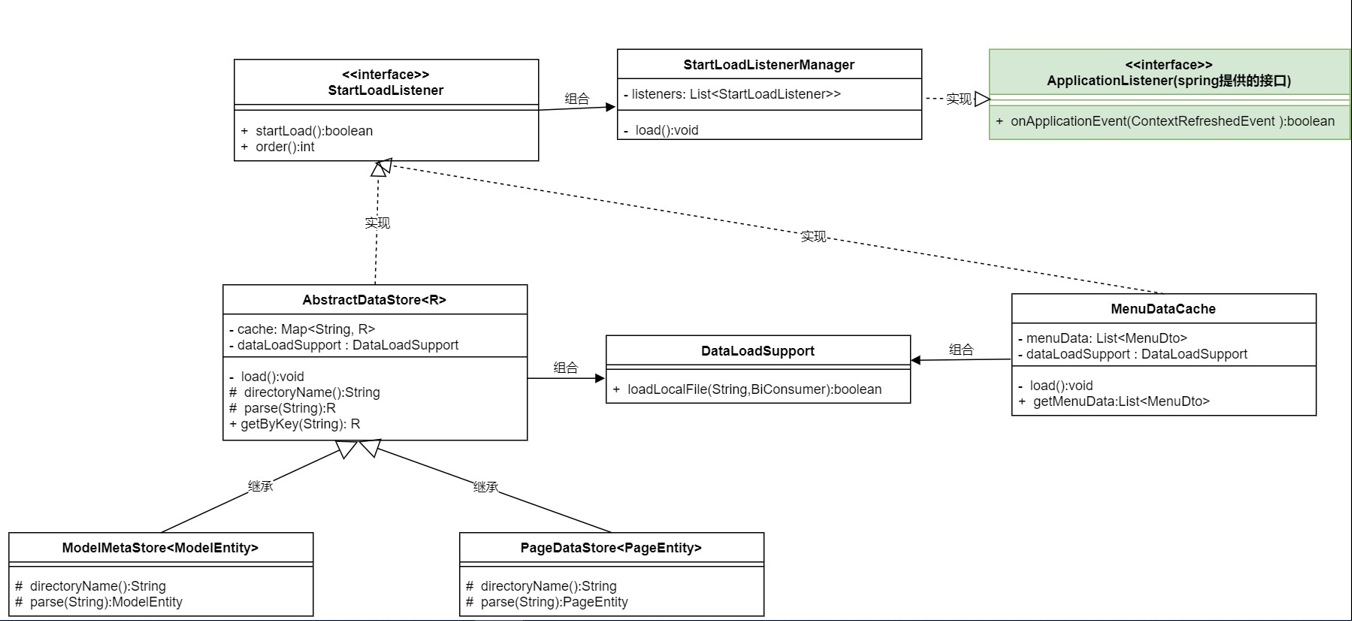
為了邏輯的統一,還有後期其他服務需要啟動時載入的考慮,我選擇了統一實現,具體邏輯和類圖如下:
具體邏輯:
- 新增一個介面StartLoadListener:啟動載入監聽,啟動時需要被觸發的操作類實現該介面.
- AbstractDataStore和MenuDataCache實現StartLoadListener介面,標記需要在應用啟動時觸發,應用啟動後觸發自己的load方法.
- 新增StartLoadListenerManager類,裡面會自動註入所有實現StartLoadListener介面的對象,該類同時實現了spring的ApplicationListener介面,在spring啟動後被觸發,觸發後調用所有的StartLoadListener的startLoad方法,完成所有需要啟動時觸發的操作.
類圖:
第二版設計
如文章開頭所說,從元數據緩存中使用key從map中獲取信息後直接返回是有問題的,開發完的時候也意識到了一些,但沒有去處理,直到某天雷真的炸了.
先說下問題出現的過程,初期功能簡單,低代碼平臺生成的應用都跑的好好的,迭代數次版本後,新增了許可權能力:支持簡單的數據許可權和菜單許可權.
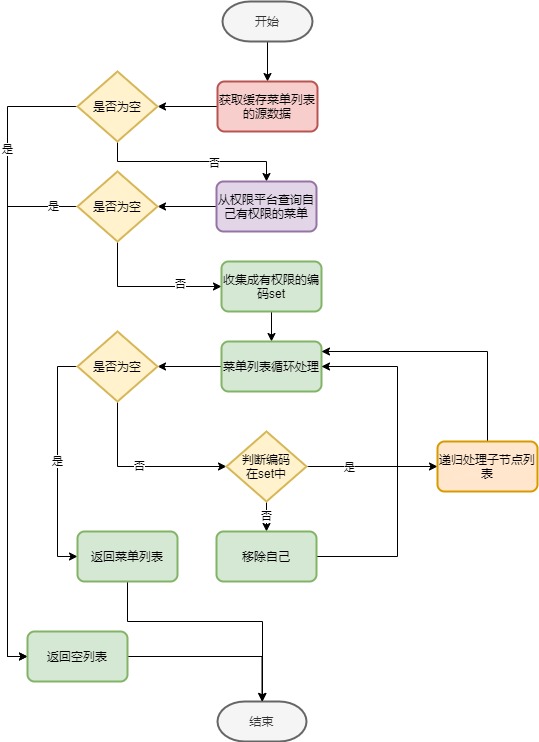
菜單許可權的處理邏輯大體如下:
- 從菜單緩存中直接獲取緩存的數據.
- 如果菜單列表為空,直接返回給客戶端空的列表,結束菜單查詢.
- 查詢用戶有許可權的菜單編碼列表(set),數據源頭是科技許可權系統,初期比較粗暴代碼耦合到菜單許可權代碼中,但這不是今天討論的重點,後邊的文章會講到許可權模塊的重構.
- 如果用戶有許可權的菜單編碼列表(set)為空,直接返回給客戶端空的列表,結束菜單查詢.
- 遞歸處理獲取的緩存菜單,如果編碼在許可權系統返回的編碼列表(set)中,遞歸處理子節點列表(菜單是樹形的),否則直接刪除該節點,返回到上級遞歸.
- 迴圈上步操作,直到所有菜單節點校驗完成.
邏輯並不太複雜,開發的時候特意重點關註了遞歸和許可權系統查詢,本地測試沒什麼問題,部署到測試環境也沒發現什麼問題.
但最後要上線前測試發現了一個問題:切換賬號後,菜單不對,有許可權的菜單變少了!!!
定位問題的時候,先排查許可權系統的返回,結果沒問題;在把數據拿到本地走mock測試也沒有問題;在最後debug的時候發現了真正的問題,也就是之前意識到但沒有解決的問題:在菜單許可權邏輯中操作的菜單列表和菜單元數據緩存的菜單列表是同一個對象!
在某個用戶處理完自己的許可權菜單邏輯後,可能會移除一些節點,下一個用戶在獲取菜單的時候他的菜單元數據可能就是被處理過(在許可權處理中被移除)的了.
元數據存儲實際上類似原型模型,原型模式的定義:如果對象的創建成本比較大,而同一個類的不同對象之間差別不大(大部分欄位都相同),在這種情況下,我們可以利用對已有對象進行複製(或者叫拷貝)的方式來創建新對象,以達到節省創建時間的目的.
我的實現只做了緩存,但沒有實現複製,使得同一對象被多個場景操作.最後導致數據的錯誤及混亂.
而複製一般也叫拷貝,分為兩類:
- 淺拷貝:只會拷貝對象中的基本數據類型的數據(比如,int、long),以及引用對象的記憶體地址,不會遞歸地拷貝引用對象本身.
- 深拷貝:不僅僅會複製索引,還會複製數據本身
我們肯定要選擇深拷貝,但出現問題的時候已經有幾個元數據存儲了,特別是菜單數據的結構複雜(樹形),短時間沒法完成深度複製,市面上的工具類通常只能複製一層,無法自動完成深層次的複製.
當時的解決方案比較粗暴:問題出現在菜單,那隻在菜單許可權處理的時候做手腳:定義一個新的菜單列表,有許可權的菜單深度複製當前對象後加入到list;遞歸處理子節點.繼續重新定義一個list設置為上層節點的子節點,有許可權的子節點放入到新的list,遞歸迴圈上述步驟.
表象的bug解決了,但實際問題還沒有解決,只是被遮蓋了,就拿菜單來說,我是在許可權服務那處理了,但如果在其他地方使用呢,一樣會出現數據缺失的錯誤.
更嚴重的是在觸發器中提供了獲取模型元數據的介面,開發者獲取模型元數據後如果進行了修改,導致的錯誤會更加嚴重,也更加的難已排查,因為模型元數據的變更會導致模型通用介面邏輯的缺失或混亂,所以深度複製的功能一定要實現.
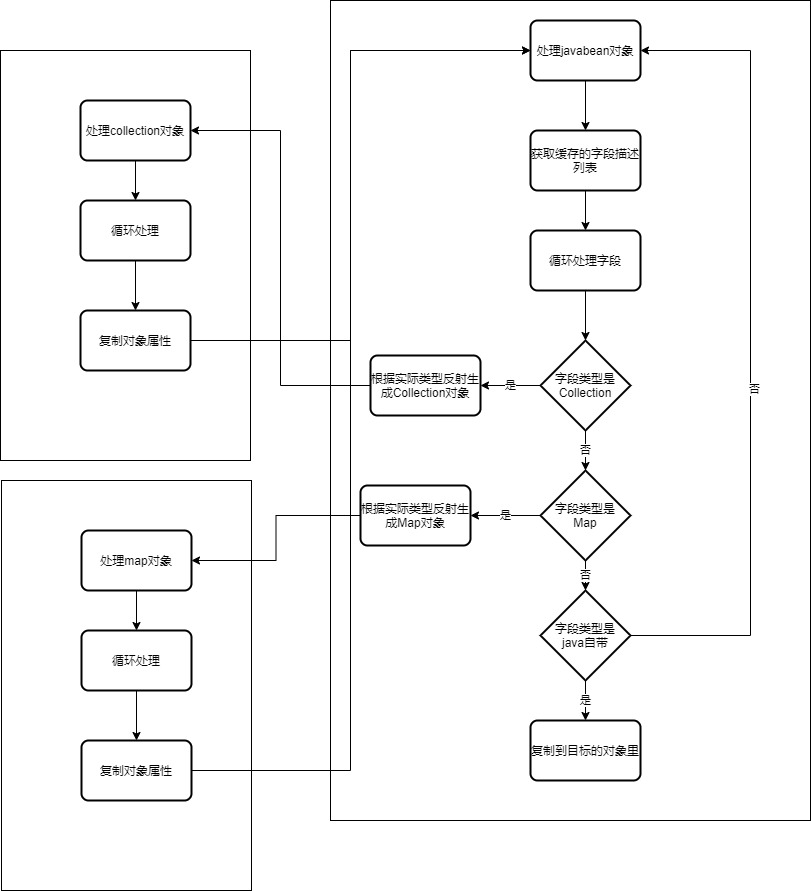
深度複製的實現一般有兩種:
第一種序列化後反序列化,比如把數據序列化成json,在反序列化回來.該方案有兩個問題:(1)繼承的子類多態容易出問題(2)序列化和反序列化是有性能消耗的,在此處方案並不適合.
第二種是遞歸處理:遇到Collection和Map及javabean類型,進行遞歸的深度拷貝.該方案開發成本稍高,大量的遞歸需要特殊註意,此外一些特殊的bean也無法複製:如內部變數是final類型,或者只支持構造函數傳入.
我們使用的是第二種,這種方法純粹是演算法類,不再細說,在中間碰到了一個坑:我有一個習慣遇到一些沒有數據需要返回空的list的時候我會直接使用Collections.emptyList(),在深度複製的時候根據構造函數新建對象會直接報錯,修複方案是:如果是list或者map不是常見的對象類型直接使用常見的對象ArrayList和HashMap.
實際上還有一種方案能解決數據修改問題,使用不變對象,不變對象就是對象在創建後,不可以被修改:沒有set方法,且內部變數不會暴露,需要註意的是,內部變數也要進行保護:不變或者深拷貝.
作者:京東科技 吳籽良
來源:京東雲開發者社區 轉載請註明來源


