
康師傅yyds MySQL的索引包括普通索引、唯一性索引、全文索引、單列索引、多列索引和空間索引等。 從 功能邏輯 上說,索引主要有 4 種,分別是普通索引、唯一索引、主鍵索引、全文索引。 按照 物理實現方式 ,索引可以分為 2 種:聚簇索引和非聚簇索引。 按照 作用欄位個數 進行劃分,分成單列索引 ...
康師傅yyds
MySQL的索引包括普通索引、唯一性索引、全文索引、單列索引、多列索引和空間索引等。 從 功能邏輯 上說,索引主要有 4 種,分別是普通索引、唯一索引、主鍵索引、全文索引。 按照 物理實現方式 ,索引可以分為 2 種:聚簇索引和非聚簇索引。 按照 作用欄位個數 進行劃分,分成單列索引和聯合創建索引的原則
1 show index from channel_detail; 2 DROP INDEX idx_cl_channel_id ON channel_label; 3 4 CREATE [UNIQUE | FULLTEXT | SPATIAL] INDEX index_name 5 ON table_name (col_name[length],...) [ASC | DESC] 6 CREATE INDEX idx_cd_channel_id ON channel_detail(channel_id);
適合創建索引的情況
1、欄位的數值有唯一性的限制
業務上具有唯一特性的欄位,即使是組合欄位,也必須建成唯一索引。(來源:Alibaba) 說明:不要以為唯一索引影響了 insert 速度,這個速度損耗可以忽略,但提高查找速度是明顯的。2、頻繁作為 WHERE 查詢條件的欄位
3. 經常 GROUP BY 和 ORDER BY 的列
4、UPDATE、DELETE 的 WHERE 條件列
如果進行更新的時候,更新的欄位是非索引欄位,提升的效率會更明顯,這是因為非索引欄位更新不需要對索引進行維護。5.DISTINCT 欄位需要創建索引
對某個欄位去重,要對該欄位創索引
6. 多表 JOIN 連接操作時,創建索引註意事項
首先, 連接表的數量儘量不要超過 3 張 其次, 對 WHERE 條件創建索引 最後, 對用於連接的欄位創建索引7. 使用列的類型小的創建索引
能用小一點的數據類型就用小一點的 int->bigint,InnoDB創建的索引B-tree小一點,查的快一點
8. 使用字元串首碼創建索引
對字元串創建索引時,截取一部分首碼就可以了。
Alibaba《Java開發手冊》 【 強制 】在 varchar 欄位上建立索引時,必須指定索引長度,沒必要對全欄位建立索引,根據實際文本區分度決定索引長度。 說明:索引的長度與區分度是一對矛盾體,一般對字元串類型數據,長度為 20 的索引,區分度會 高達90% 以上 ,可以使用 count(distinct left(列名, 索引長度))/count(*)的區分度來確定。9. 區分度高(散列性高)的列適合作為索引
10. 使用最頻繁的列放到聯合索引的左側
11. 在多個欄位都要創建索引的情況下,聯合索引優於單值索引
不適合創建索引的情況
where不到的欄位不創建
重覆數據太多的不創建(如不要對 is_delete 欄位創建索引)
數據量小的表不要創建索引
經常更新操作的表不要創建太多索引
不建議用無須的欄位撞見索引
例如身份證、UUID(在索引比較時需要轉為ASCII,並且插入時可能造成頁分裂)、MD5、HASH、無序長字元串等。不要定義冗餘或重覆的索引
重點提現在聯合索引和單行索引的重覆上
SQL優化的思路
1、SHOW INDEX FROM student_info; //查表中索引
2、DROP INDEX index_name ON table_name; //刪除索引
3、set global slow_query_log='ON'; //開啟慢查詢日誌 不用的時候,最好關閉掉。
4、set global long_query_time = 1; //修改long_query_time閾值為一秒 預設我們本地超過一秒為慢查詢
set long_query_time=1; //上面修改了全局的,還要修改當前回話的
5、show variables like '%slow_query_log%'; // 查看兩個參數
6、SHOW GLOBAL STATUS LIKE '%Slow_queries%'; //查看慢查詢的次數
資料庫重啟的話,上面參數要重新設置,可以去配置文件中設置。
慢查詢分析工具mysqldumpslow
mysqldumpslow 命令的具體參數如下: -a: 不將數字抽象成N,字元串抽象成S -s: 是表示按照何種方式排序: c: 訪問次數 l: 鎖定時間 r: 返回記錄 t: 查詢時間 al:平均鎖定時間 ar:平均返回記錄數 at:平均查詢時間 (預設方式) ac:平均查詢次數 -t: 即為返回前面多少條的數據; -g: 後邊搭配一個正則匹配模式,大小寫不敏感的;mysqldumpslow -s t -t 5 /var/lib/mysql/atguigu01-slow.log //按照查詢時間排序,查看前五條 SQL 語句#得到返回記錄集最多的10個SQL mysqldumpslow -s r -t 10 /var/lib/mysql/atguigu-slow.log #得到訪問次數最多的10個SQL mysqldumpslow -s c -t 10 /var/lib/mysql/atguigu-slow.log #得到按照時間排序的前10條裡面含有左連接的查詢語句 mysqldumpslow -s t -t 10 -g "left join" /var/lib/mysql/atguigu-slow.log #另外建議在使用這些命令時結合 | 和more 使用 ,否則有可能出現爆屏情況 mysqldumpslow -s r -t 10 /var/lib/mysql/atguigu-slow.log | more
分析查詢語句:EXPLAIN
show variables like 'profiling'; //查看 SQL 執行成本:SHOW PROFILEset profiling = 'ON'; //設置 profiling='ON’ 來開啟 show profile show profiles; //執行相關的查詢語句。接著看下當前會話都有哪些 profiles show profile; //查看最近一次查詢的開銷 show profile cpu,block io for query 2; //查詢編號2的sql開銷
EXPLAIN SELECT select_options;
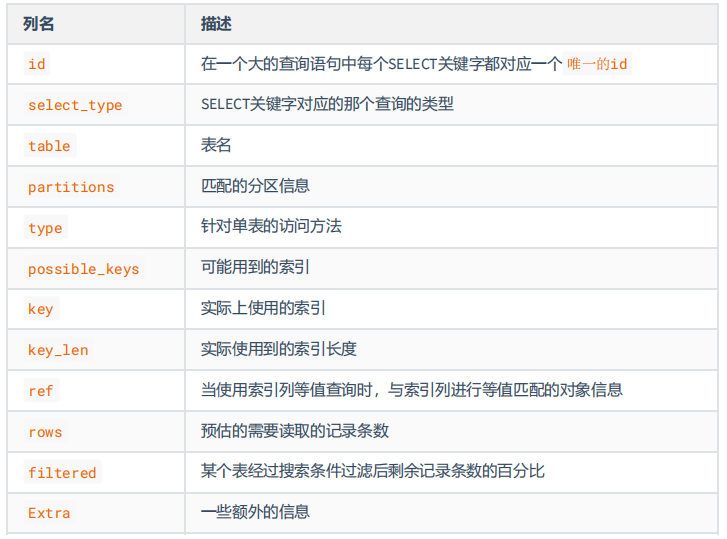
EXPLAIN 各列
數據表,s1、s2 相同的
1 CREATE TABLE s1 ( 2 id INT AUTO_INCREMENT, 3 key1 VARCHAR(100), 4 key2 INT, 5 key3 VARCHAR(100), 6 key_part1 VARCHAR(100), 7 key_part2 VARCHAR(100), 8 key_part3 VARCHAR(100), 9 common_field VARCHAR(100), 10 PRIMARY KEY (id), 11 INDEX idx_key1 (key1), 12 UNIQUE INDEX idx_key2 (key2), 13 INDEX idx_key3 (key3), 14 INDEX idx_key_part(key_part1, key_part2, key_part3) 15 ) ENGINE=INNODB CHARSET=utf8;
table:表名
#1. table:表名
#查詢的每一行記錄都對應著一個單表
EXPLAIN SELECT * FROM s1;
SHOW INDEX FROM s1;
#s1:驅動表 s2:被驅動表
EXPLAIN SELECT * FROM s1 INNER JOIN s2;
id:在一個大的查詢語句中每個SELECT關鍵字都對應一個唯一的id
id如果相同,可以認為是一組,從上往下順序執行 在所有組中,id值越大,優先順序越高,越先執行 關註點:id號每個號碼,表示一趟獨立的查詢, 一個sql的查詢趟數越少越好1 #2. id:在一個大的查詢語句中每個SELECT關鍵字都對應一個唯一的id 2 SELECT * FROM s1 WHERE key1 = 'a'; 3 4 5 SELECT * FROM s1 INNER JOIN s2 6 ON s1.key1 = s2.key1 7 WHERE s1.common_field = 'a'; 8 9 10 SELECT * FROM s1 11 WHERE key1 IN (SELECT key3 FROM s2); 12 13 14 SELECT * FROM s1 UNION SELECT * FROM s2; 15 16 17 EXPLAIN SELECT * FROM s1 WHERE key1 = 'a'; 18 19 20 EXPLAIN SELECT * FROM s1 INNER JOIN s2; 21 22 23 EXPLAIN SELECT * FROM s1 WHERE key1 IN (SELECT key1 FROM s2) OR key3 = 'a'; 24 25 ######查詢優化器可能對涉及子查詢的查詢語句進行重寫,轉變為多表查詢的操作######## 26 EXPLAIN SELECT * FROM s1 WHERE key1 IN (SELECT key2 FROM s2 WHERE common_field = 'a'); 27 28 #Union去重 29 EXPLAIN SELECT * FROM s1 UNION SELECT * FROM s2; 30 31 32 EXPLAIN SELECT * FROM s1 UNION ALL SELECT * FROM s2;
select_type:SELECT關鍵字對應的那個查詢的類型,確定小查詢在整個大查詢中扮演了一個什麼角色

1 #3. select_type:SELECT關鍵字對應的那個查詢的類型,確定小查詢在整個大查詢中扮演了一個什麼角色 2 3 # 查詢語句中不包含`UNION`或者子查詢的查詢都算作是`SIMPLE`類型 4 EXPLAIN SELECT * FROM s1; 5 6 7 #連接查詢也算是`SIMPLE`類型 8 EXPLAIN SELECT * FROM s1 INNER JOIN s2; 9 10 11 #對於包含`UNION`或者`UNION ALL`或者子查詢的大查詢來說,它是由幾個小查詢組成的,其中最左邊的那個 12 #查詢的`select_type`值就是`PRIMARY` 13 14 15 #對於包含`UNION`或者`UNION ALL`的大查詢來說,它是由幾個小查詢組成的,其中除了最左邊的那個小查詢 16 #以外,其餘的小查詢的`select_type`值就是`UNION` 17 18 #`MySQL`選擇使用臨時表來完成`UNION`查詢的去重工作,針對該臨時表的查詢的`select_type`就是 19 #`UNION RESULT` 20 EXPLAIN SELECT * FROM s1 UNION SELECT * FROM s2; 21 22 EXPLAIN SELECT * FROM s1 UNION ALL SELECT * FROM s2; 23 24 #子查詢: 25 #如果包含子查詢的查詢語句不能夠轉為對應的`semi-join`的形式,並且該子查詢是不相關子查詢。 26 #該子查詢的第一個`SELECT`關鍵字代表的那個查詢的`select_type`就是`SUBQUERY` 27 EXPLAIN SELECT * FROM s1 WHERE key1 IN (SELECT key1 FROM s2) OR key3 = 'a'; 28 29 30 #如果包含子查詢的查詢語句不能夠轉為對應的`semi-join`的形式,並且該子查詢是相關子查詢, 31 #則該子查詢的第一個`SELECT`關鍵字代表的那個查詢的`select_type`就是`DEPENDENT SUBQUERY` 32 EXPLAIN SELECT * FROM s1 33 WHERE key1 IN (SELECT key1 FROM s2 WHERE s1.key2 = s2.key2) OR key3 = 'a'; 34 #註意的是,select_type為`DEPENDENT SUBQUERY`的查詢可能會被執行多次。 35 36 37 #在包含`UNION`或者`UNION ALL`的大查詢中,如果各個小查詢都依賴於外層查詢的話,那除了 38 #最左邊的那個小查詢之外,其餘的小查詢的`select_type`的值就是`DEPENDENT UNION`。 39 EXPLAIN SELECT * FROM s1 40 WHERE key1 IN (SELECT key1 FROM s2 WHERE key1 = 'a' UNION SELECT key1 FROM s1 WHERE key1 = 'b'); 41 42 43 #對於包含`派生表`的查詢,該派生表對應的子查詢的`select_type`就是`DERIVED` 44 EXPLAIN SELECT * 45 FROM (SELECT key1, COUNT(*) AS c FROM s1 GROUP BY key1) AS derived_s1 WHERE c > 1; 46 47 48 #當查詢優化器在執行包含子查詢的語句時,選擇將子查詢物化之後與外層查詢進行連接查詢時, 49 #該子查詢對應的`select_type`屬性就是`MATERIALIZED` 50 EXPLAIN SELECT * FROM s1 WHERE key1 IN (SELECT key1 FROM s2); #子查詢被轉為了物化表
partition:匹配的分區信息
type:針對單表的訪問方法
小結: 結果值從最好到最壞依次是: system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL 其中比較重要的幾個提取出來(見上圖中的藍 色)。SQL 性能優化的目標:至少要達到 range 級別,要求是 ref 級別,最好是 consts級別。(阿裡巴巴 開發手冊要求)1 # 5. type:針對單表的訪問方法 2 3 #當表中`只有一條記錄`並且該表使用的存儲引擎的統計數據是精確的,比如MyISAM、Memory, 4 #那麼對該表的訪問方法就是`system`。 5 CREATE TABLE t(i INT) ENGINE=MYISAM; 6 INSERT INTO t VALUES(1); 7 8 EXPLAIN SELECT * FROM t; 9 10 #換成InnoDB ALL 11 CREATE TABLE tt(i INT) ENGINE=INNODB; 12 INSERT INTO tt VALUES(1); 13 EXPLAIN SELECT * FROM tt; 14 15 16 #當我們根據主鍵或者唯一二級索引列與常數進行等值匹配時,對單表的訪問方法就是`const` 17 EXPLAIN SELECT * FROM s1 WHERE id = 10005; 18 19 EXPLAIN SELECT * FROM s1 WHERE key2 = 10066; 20 21 22 #在連接查詢時,如果被驅動表是通過主鍵或者唯一二級索引列等值匹配的方式進行訪問的 23 #(如果該主鍵或者唯一二級索引是聯合索引的話,所有的索引列都必須進行等值比較),則 24 #對該被驅動表的訪問方法就是`eq_ref` 25 EXPLAIN SELECT * FROM s1 INNER JOIN s2 ON s1.id = s2.id; 26 27 28 #當通過普通的二級索引列與常量進行等值匹配時來查詢某個表,那麼對該表的訪問方法就可能是`ref` 29 EXPLAIN SELECT * FROM s1 WHERE key1 = 'a'; 30 31 32 #當對普通二級索引進行等值匹配查詢,該索引列的值也可以是`NULL`值時,那麼對該表的訪問方法 33 #就可能是`ref_or_null` 34 EXPLAIN SELECT * FROM s1 WHERE key1 = 'a' OR key1 IS NULL; 35 36 37 #單表訪問方法時在某些場景下可以使用`Intersection`、`Union`、 38 #`Sort-Union`這三種索引合併的方式來執行查詢 39 EXPLAIN SELECT * FROM s1 WHERE key1 = 'a' OR key3 = 'a'; 40 41 42 #`unique_subquery`是針對在一些包含`IN`子查詢的查詢語句中,如果查詢優化器決定將`IN`子查詢 43 #轉換為`EXISTS`子查詢,而且子查詢可以使用到主鍵進行等值匹配的話,那麼該子查詢執行計劃的`type` 44 #列的值就是`unique_subquery` 45 EXPLAIN SELECT * FROM s1 46 WHERE key2 IN (SELECT id FROM s2 WHERE s1.key1 = s2.key1) OR key3 = 'a'; 47 48 49 #如果使用索引獲取某些`範圍區間`的記錄,那麼就可能使用到`range`訪問方法 50 EXPLAIN SELECT * FROM s1 WHERE key1 IN ('a', 'b', 'c'); 51 52 #同上 53 EXPLAIN SELECT * FROM s1 WHERE key1 > 'a' AND key1 < 'b'; 54 55 56 #當我們可以使用索引覆蓋,但需要掃描全部的索引記錄時,該表的訪問方法就是`index` 57 EXPLAIN SELECT key_part2 FROM s1 WHERE key_part3 = 'a'; 58 59 60 #最熟悉的全表掃描 61 EXPLAIN SELECT * FROM s1;
possible_keys和key:可能用到的索引 和 實際上使用的索引
key_len:實際使用到的索引長度(即:位元組數)
1 #7. key_len:實際使用到的索引長度(即:位元組數) 2 # 幫你檢查`是否充分的利用上了索引`,`值越大越好`,主要針對於聯合索引,有一定的參考意義。 3 EXPLAIN SELECT * FROM s1 WHERE id = 10005; 4 5 6 EXPLAIN SELECT * FROM s1 WHERE key2 = 10126; 7 8 9 EXPLAIN SELECT * FROM s1 WHERE key1 = 'a'; 10 11 12 EXPLAIN SELECT * FROM s1 WHERE key_part1 = 'a'; 13 14 15 EXPLAIN SELECT * FROM s1 WHERE key_part1 = 'a' AND key_part2 = 'b'; 16 17 EXPLAIN SELECT * FROM s1 WHERE key_part1 = 'a' AND key_part2 = 'b' AND key_part3 = 'c'; 18 19 EXPLAIN SELECT * FROM s1 WHERE key_part3 = 'a'; 20 21 #練習: 22 #varchar(10)變長欄位且允許NULL = 10 * ( character set:utf8=3,gbk=2,latin1=1)+1(NULL)+2(變長欄位) 23 24 #varchar(10)變長欄位且不允許NULL = 10 * ( character set:utf8=3,gbk=2,latin1=1)+2(變長欄位) 25 26 #char(10)固定欄位且允許NULL = 10 * ( character set:utf8=3,gbk=2,latin1=1)+1(NULL) 27 28 #char(10)固定欄位且不允許NULL = 10 * ( character set:utf8=3,gbk=2,latin1=1)
ref:當使用索引列等值查詢時,與索引列進行等值匹配的對象信息。
1 # 8. ref:當使用索引列等值查詢時,與索引列進行等值匹配的對象信息。 2 #比如只是一個常數或者是某個列。 3 4 EXPLAIN SELECT * FROM s1 WHERE key1 = 'a'; 5 6 7 EXPLAIN SELECT * FROM s1 INNER JOIN s2 ON s1.id = s2.id; 8 9 10 EXPLAIN SELECT * FROM s1 INNER JOIN s2 ON s2.key1 = UPPER(s1.key1);
rows:預估的需要讀取的記錄條數
1 # 9. rows:預估的需要讀取的記錄條數 2 # `值越小越好` 3 EXPLAIN SELECT * FROM s1 WHERE key1 > 'z';
filtered: 某個表經過搜索條件過濾後剩餘記錄條數的百分比
1 # 10. filtered: 某個表經過搜索條件過濾後剩餘記錄條數的百分比 2 3 #如果使用的是索引執行的單表掃描,那麼計算時需要估計出滿足除使用 4 #到對應索引的搜索條件外的其他搜索條件的記錄有多少條。 5 EXPLAIN SELECT * FROM s1 WHERE key1 > 'z' AND common_field = 'a'; 6 7 8 #對於單表查詢來說,這個filtered列的值沒什麼意義,我們`更關註在連接查詢 9 #中驅動表對應的執行計劃記錄的filtered值`,它決定了被驅動表要執行的次數(即:rows * filtered) 10 EXPLAIN SELECT * FROM s1 INNER JOIN s2 ON s1.key1 = s2.key1 WHERE s1.common_field = 'a';
Extra:一些額外的信息
1 #11. Extra:一些額外的信息 2 #更準確的理解MySQL到底將如何執行給定的查詢語句 3 4 5 #當查詢語句的沒有`FROM`子句時將會提示該額外信息 6 EXPLAIN SELECT 1; 7 8 9 #查詢語句的`WHERE`子句永遠為`FALSE`時將會提示該額外信息 10 EXPLAIN SELECT * FROM s1 WHERE 1 != 1; 11 12 13 #當我們使用全表掃描來執行對某個表的查詢,並且該語句的`WHERE` 14 #子句中有針對該表的搜索條件時,在`Extra`列中會提示上述額外信息。 15 EXPLAIN SELECT * FROM s1 WHERE common_field = 'a'; 16 17 18 #當使用索引訪問來執行對某個表的查詢,並且該語句的`WHERE`子句中 19 #有除了該索引包含的列之外的其他搜索條件時,在`Extra`列中也會提示上述額外信息。

