
百分比堆疊式柱狀圖是一種特殊的柱狀圖,它的每根柱子是等長的,總額為100%。柱子內部被分割為多個部分,高度由該部分占總體的百分比決定。 百分比堆疊式柱狀圖不顯示數據的“絕對數值”,而是顯示“相對比例”。但同時,它也仍然具有柱狀圖的固有功能,即“比較”——我們可以通過比較多個柱子的構成,分析數值之間的 ...
百分比堆疊式柱狀圖是一種特殊的柱狀圖,它的每根柱子是等長的,總額為100%。
柱子內部被分割為多個部分,高度由該部分占總體的百分比決定。
百分比堆疊式柱狀圖不顯示數據的“絕對數值”,而是顯示“相對比例”。
但同時,它也仍然具有柱狀圖的固有功能,即“比較”——我們可以通過比較多個柱子的構成,分析數值之間的相對差異,或者得出數值變化的趨勢。
1. 主要元素
百分比柱狀圖是一種用於可視化比較不同類別或組的百分比或比例的圖表。
它的主要元素包括:
- 橫軸:表示數據的主分類。
- 縱軸:每個子分類的比例關係。
- 堆疊的矩形:每個柱狀圖由多個堆疊部分組成,和堆疊柱狀圖不同的是,每個柱子都是一樣高的。
- 圖例:每個堆疊部分代表的意義。

2. 適用的場景
百分比柱狀圖適用的場景很多,比如:
- 市場份額:比較不同產品或服務的市場份額,幫助決策者瞭解市場競爭情況。
- 人口比例:顯示不同地區或不同群體的人口比例,或不同年齡段的人口比例。
- 問卷調查結果:比較不同選項或答案的頻率或比例,或者用戶對產品特性的滿意度。
- 部門預算分配:顯示不同部門或項目的預算分配比例,幫助管理者瞭解資源分配情況。
- 等等。。。
3. 不適用的場景
百分比柱狀圖也有不適用於的場景,比如:
- 比較絕對數值:如果需要比較具體的數值大小而不僅僅是比例,那麼百分比柱狀圖可能不是最合適的選擇。
- 數據存在重疊:如果不同類別的數據存在重疊或者相互依賴的情況,百分比柱狀圖可能無法清晰地展示比例關係。
- 數據量過大或過小:如果數據量過大或過小,百分比柱狀圖可能無法有效地顯示比例關係。
4. 分析實戰
和上一篇堆疊柱狀圖使用相同的原始數據,繪製圖形之後可以看看這兩種柱狀圖展示分析結果的區別。
4.1. 數據來源
數據來自國家統計局公開的人民生活數據,可從下麵的網址下載:
https://databook.top/nation/A0A
使用的是其中 A0A0A.csv文件(全國居民主要食品消費量)
fp = "d:/share/A0A0A.csv"
df = pd.read_csv(fp)
df
4.2. 數據清理
選取和上一篇堆疊柱狀圖一樣,還是5類:
- 居民人均蔬菜及食用菌消費量(千克)
- 居民人均肉類消費量(千克)
- 居民人均禽類消費量(千克)
- 居民人均水產品消費量(千克)
- 居民人均蛋類消費量(千克)
和堆疊柱狀圖不同的是,繪製百分比柱狀圖用的是百分比數值,
所有要把原始數據中每年的絕對數值轉換為百分比數值。
data = df[(df["sj"] >= 2013) &
(df["sj"] <= 2021) &
(df["zb"].isin(["A0A0A03",
"A0A0A04",
"A0A0A05",
"A0A0A06",
"A0A0A07"]))].copy()
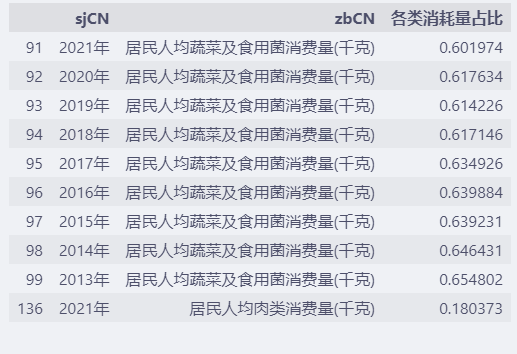
data["年消耗總量"] = data.groupby("sj").value.transform("sum")
data["各類消耗量占比"] = data["value"] / data["年消耗總量"]
data.loc[:, ["sjCN", "zbCN", "各類消耗量占比"]].head(10)
4.3. 分析結果可視化
import matplotlib.ticker as mticker
data = data.sort_values("sj")
data["各類消耗量占比"] = data["各類消耗量占比"]*100
with plt.style.context("seaborn-v0_8"):
fig = plt.figure()
ax = fig.add_axes([0.1, 0.1, 0.8, 0.8])
years = data["sjCN"].drop_duplicates(keep="first").tolist()
bar_data = {
"蔬菜及菌類(%)": data[data["zb"] == "A0A0A03"]["各類消耗量占比"].tolist(),
"肉類(%)": data[data["zb"] == "A0A0A04"]["各類消耗量占比"].tolist(),
"禽類(%)": data[data["zb"] == "A0A0A05"]["各類消耗量占比"].tolist(),
"水產品(%)": data[data["zb"] == "A0A0A06"]["各類消耗量占比"].tolist(),
"蛋類(%)": data[data["zb"] == "A0A0A07"]["各類消耗量占比"].tolist(),
}
bottom = np.zeros(len(years))
for key, vals in bar_data.items():
ax.bar(years, vals, label=key, bottom=bottom)
bottom += vals
# 設置Y軸刻度的顯示格式
ax.set_ylim(0, 110)
yticks = ax.get_yticks().tolist()
ax.yaxis.set_major_locator(mticker.FixedLocator(yticks))
ax.set_yticklabels(["{}%".format(x) for x in yticks])
ax.set_title("全國居民主要糧食消耗情況")
ax.legend(loc="upper left", ncol=5)

百分比柱狀圖每年的數據高度都一樣,與堆疊柱狀圖相比,更容易比較每個種類糧食的消耗情況。
不過,這種圖看不出糧食總量的變化情況了。


