
直方圖,又稱質量分佈圖,用於表示數據的分佈情況,是一種常見的統計圖表。 一般用橫軸表示數據區間,縱軸表示分佈情況,柱子越高,則落在該區間的數量越大。構建直方圖時,首先首先就是對數據劃分區間,通俗的說即是劃定有幾根柱子(比如,1980年~2020年的數據,每5年劃分一個區間的話,共8個區間)。接著,對 ...
直方圖,又稱質量分佈圖,用於表示數據的分佈情況,是一種常見的統計圖表。
一般用橫軸表示數據區間,縱軸表示分佈情況,柱子越高,則落在該區間的數量越大。
構建直方圖時,首先首先就是對數據劃分區間,通俗的說即是劃定有幾根柱子(比如,1980年~2020年的數據,每5年劃分一個區間的話,共8個區間)。
接著,對落在每個區間的數值進行統計計算, 最後,繪製矩形,高度由每個區間的統計結果決定。
直方圖與柱狀圖看似相像,實則完全不同。
前者反映數據分佈情況,後者則不具備此功能,只能對數值進行比較。
也就是說,柱狀圖是離散的因此柱子間有空隙;但直方圖的數據是連續的數值變數,因此柱子間是沒有空隙的。
1. 主要元素
直方圖的主要元素包括:
- 橫軸:表示數據的取值範圍或分組區間。
- 縱軸:表示該區間內數據的頻率或數量。
- 柱狀條高度:表示每個區間內數據的頻率或數量,柱狀條的高度代表該區間內數據的數量多少。
- 柱狀條面積:表示不同區間內數據的總和,有時候面積是無意義的,只看高度。

2. 適用的場景
直方圖適用於以下分析場景:
- 數據分佈分析:直方圖可以幫助我們瞭解數據的分佈情況,包括數據的中心趨勢、離散程度和偏斜程度等。通過觀察直方圖的形狀,我們可以判斷數據是正態分佈、偏態分佈還是有其他特殊的分佈形式。
- 異常檢測:直方圖可以幫助我們識別出數據中的異常情況。通過觀察直方圖中的離群點或異常值,我們可以發現數據中的異常情況,從而進行數據清洗和異常檢測。
- 數據預處理:直方圖可以指導我們選擇合適的數據預處理方法。通過觀察直方圖,我們可以瞭解數據的分佈範圍和形態,從而決定是否需要對數據進行歸一化、標準化或對數變換等預處理操作。
- 數據比較:直方圖可以幫助我們比較不同數據集之間的差異。通過繪製多個直方圖併進行對比,我們可以觀察到不同數據集之間的分佈差異,從而進行數據分析和解釋。
3. 不適用的場景
直方圖可能不適用於以下分析場景:
- 時間序列分析:直方圖通常用於表示數據的分佈情況,而對於時間序列數據,直方圖無法展示數據隨時間變化的趨勢和模式。
- 數據關聯分析:直方圖無法直接展示數據之間的相關性或關聯性。
- 多維數據分析:直方圖主要適用於一維數據的分析,無法直接展示多維數據的分佈情況。
- 數據模型擬合:直方圖可以展示數據的分佈情況,但無法直接擬合數據的概率分佈或模型。
- 數據聚類分析:直方圖無法直接展示數據的聚類情況,無法將數據點分組或分類。
4. 分析實戰
本次準備用直方圖統計下某個年度我們進出口總額的分佈情況。
4.1. 數據來源
這次選用國家統計局公開的對外經濟貿易數據:
https://databook.top/nation/A06
fp = "d:/share/A06050101.csv"
df = pd.read_csv(fp)
df
4.2. 數據清理
數據中有很多年份的數據為0,也就是有很多的缺失值。
所以,只選取了2021年與亞洲各國的進出口總額數據來分析,
其中有2個數據在分析繪圖前需要清理,
一個是中國同亞洲其他國家(地區)進出口總額(萬美元),與其他值差別很大,所以清理;
另一個是中國同亞洲進出口總額(萬美元),這是個彙總數據,也清理了。
data = df[(df["sj"] == 2021) &
(df["zb"] != "A060501011E") &
(df["zb"] != "A0605010101")].copy()
#原始數值太大,單位換成(億美元)
data["value"] = data["value"] / 10000
data.head()
一共有48條數據,這是前5條。
4.3. 分析結果可視化
繪製直方圖比較簡單,核心是兩個參數:
- **x **參數:一個列表,也就是這次示例中就是各個亞洲國家的進出口總額
- **bins **參數:設置數據分成幾組,直方圖會統計每個分組中的數據個數
plt.hist(data["value"].tolist(), bins=10)
plt.title("中國與亞洲各國進出口總額(億美元) 分佈")
plt.show()
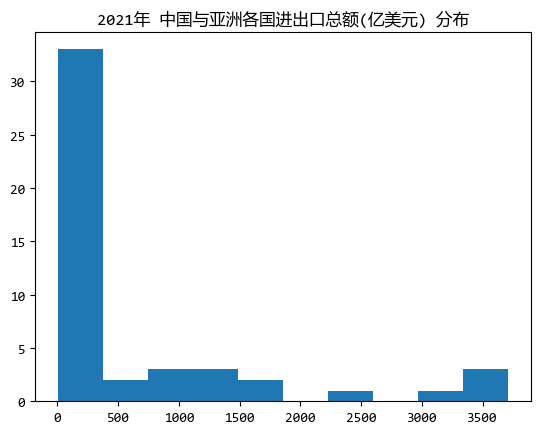
上面繪圖時,分了10個組。(可以試試調整分組個數,看看不同的圖形效果)
從圖中可以看出,2021年,亞洲各國與中國的進出口總額在 0~300(億美元)左右的國家最多,有30多個;
還有2,3個國家與中國的進出口總額甚至超過了3500億美元。


