
一、安裝python 官網 下載python3.9及以上版本 二、安裝playwright playwright是微軟公司2020年初發佈的新一代自動化測試工具,相較於目前最常用的Selenium,它僅用一個API即可自動執行Chromium、Firefox、WebKit等主流瀏覽器自動化操作。 ( ...
一、安裝python
下載python3.9及以上版本
二、安裝playwright
playwright是微軟公司2020年初發佈的新一代自動化測試工具,相較於目前最常用的Selenium,它僅用一個API即可自動執行Chromium、Firefox、WebKit等主流瀏覽器自動化操作。
(1)安裝Playwright依賴庫
1 pip install playwright
(2)安裝Chromium、Firefox、WebKit等瀏覽器的驅動文件(內置瀏覽器)
1 python -m playwright install
三、分析網站的HTML結構
魔筆小說網是一個輕小說下載網站,提供了mobi、epub等格式小說資源,美中不足的是,需要跳轉城通網盤下載,無會員情況下被限速且同一時間只允許一個下載任務。
當使用chrome瀏覽器時點擊鍵盤的F12進入開發者模式。
(一)小說目錄

HTML內容

通過href標簽可以獲得每本小說的詳細地址,隨後打開該地址獲取章節下載地址。
(二)章節下載目錄
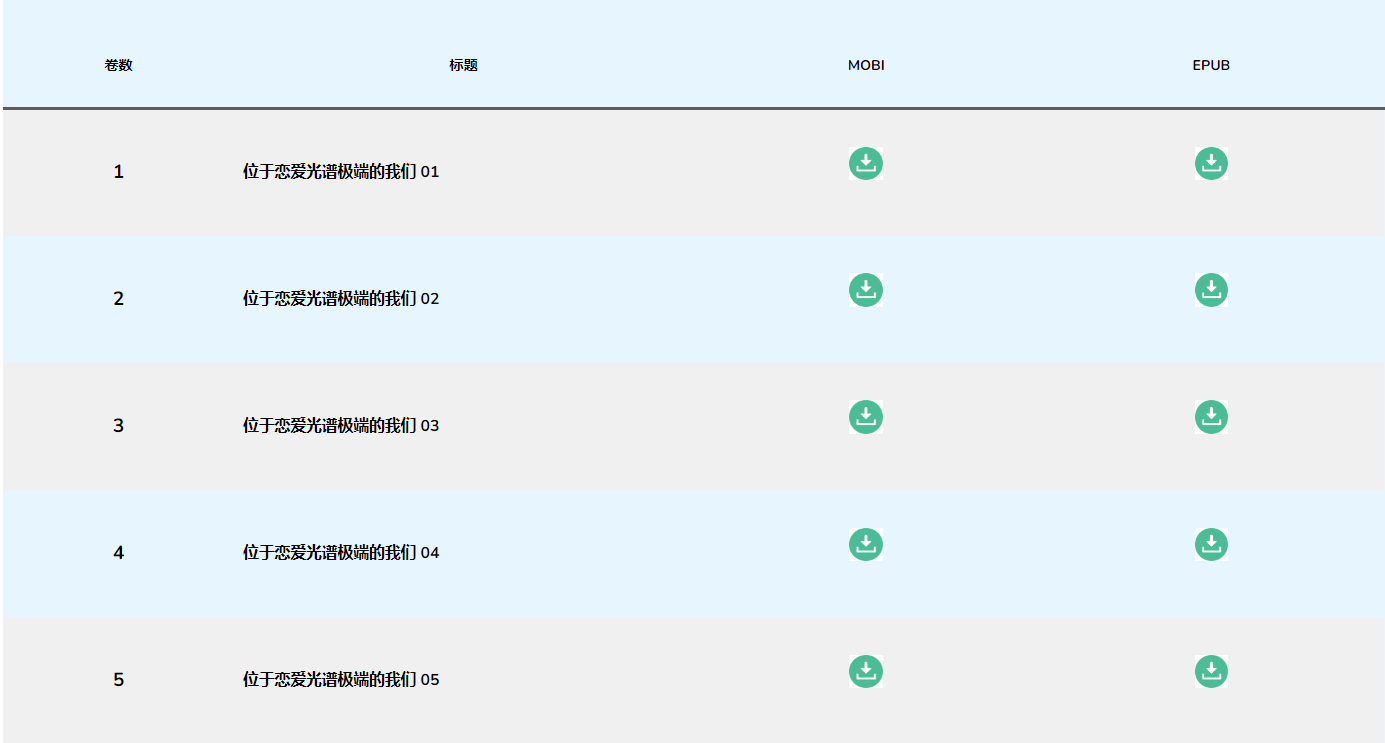
HTML內容
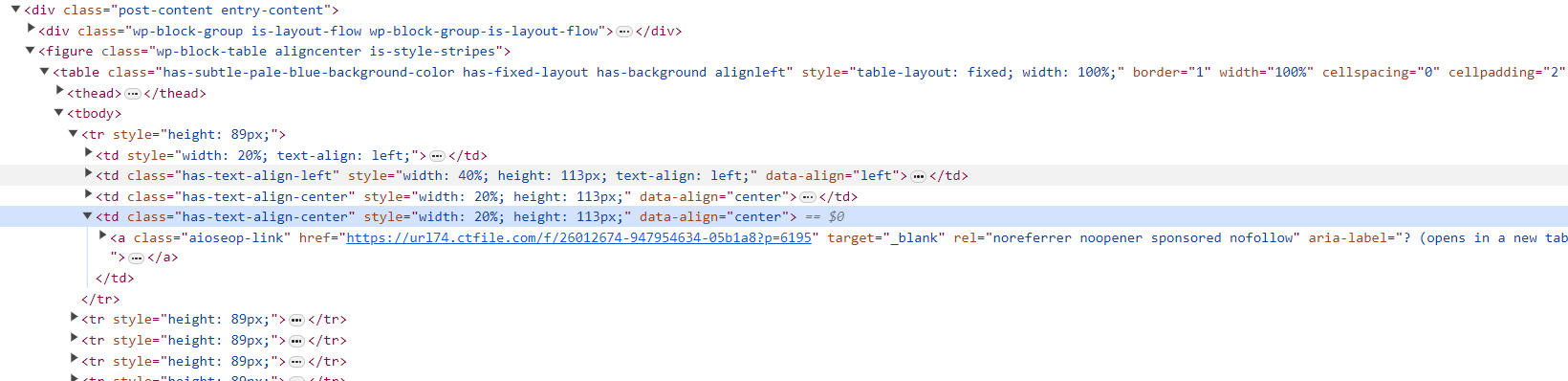
遍歷每本小說的地址並保存到單獨的txt文件中供後續下載。
(三)代碼
1 import time,re 2 3 from playwright.sync_api import Playwright, sync_playwright, expect 4 5 def cancel_request(route,request): 6 route.abort() 7 def run(playwright: Playwright) -> None: 8 browser = playwright.chromium.launch(headless=False) 9 context = browser.new_context() 10 page = context.new_page() 11 # 不載入圖片 12 # page.route(re.compile(r"(\.png)|(\.jpg)"), cancel_request) 13 page.goto("https://mobinovels.com/") 14 # 由於魔筆小說首頁是動態載入列表,因此在此處加30s延遲,需手動滑動頁面至底部直至載入完全部內容 15 for i in range(30): 16 time.sleep(1) 17 print(i) 18 # 定位至列表元素 19 novel_list = page.locator('[class="post-title entry-title"]') 20 # 統計小說數量 21 total = novel_list.count() 22 # 遍歷獲取小說詳情地址 23 for i in range(total): 24 novel = novel_list.nth(i).locator("a") 25 title = novel.inner_text() 26 title_url = novel.get_attribute("href") 27 page1 = context.new_page() 28 page1.goto(title_url,wait_until='domcontentloaded') 29 print(i+1,total,title) 30 try: 31 content_list = page1.locator("table>tbody>tr") 32 # 保存至單獨txt文件中供後續下載 33 with open('./novelurl/'+title+'.txt', 'a') as f: 34 for j in range(content_list.count()): 35 if content_list.nth(j).locator("td").count() > 2: 36 content_href = content_list.nth(j).locator("td").nth(3).locator("a").get_attribute("href") 37 f.write(title+str(j+1)+'分割'+content_href + '\n') 38 except: 39 pass 40 page1.close() 41 # 程式結束後手動關閉程式 42 time.sleep(50000) 43 page.close() 44 45 # --------------------- 46 context.close() 47 browser.close() 48 49 50 with sync_playwright() as playwright: 51 run(playwright)
(四)運行結果

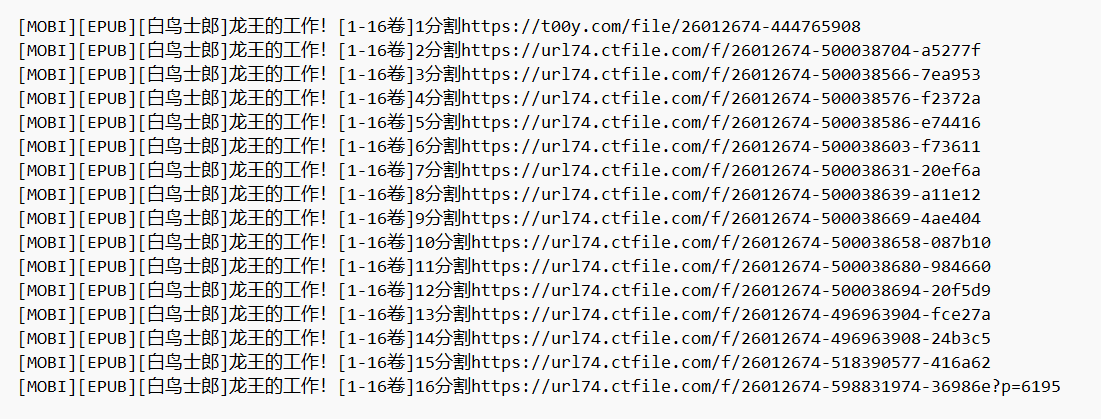
四、開始下載
之所以先將下載地址保存到txt再下載而不是立即下載,是防止程式因網路等原因異常崩潰後記錄進度,下次啟動避免重覆下載。
(一)獲取cookies
城通網盤下載較大資源時需要登陸,有的輕小說文件較大時,頁面會跳轉到登陸頁面導致程式卡住,因此需利用cookies保存登陸狀態,或增加延遲手動在頁面登陸。
chrome瀏覽器可以通過cookies editor插件獲取cookies,導出後即可使用。
(二)分析下載地址
下載地址有三種類型,根據判斷條件分別處理:
(1)文件的訪問密碼統一為6195,當功能變數名稱為 https://url74.ctfile.com/ 地址尾碼帶有 ?p=6195 時,頁面自動填入訪問密碼,我們需要在腳本中判斷尾碼是否為 ?p=6195 ,如不是則拼接字元串後訪問;
(2)有尾碼時無需處理;
(3)當功能變數名稱為 https://t00y.com/ 時無需密碼;
1 if "t00y.com" in new_url: 2 page.goto(new_url) 3 elif "?p=6195" not in new_url: 4 page.goto(new_url+"?p=6195") 5 page.get_by_placeholder("文件訪問密碼").click() 6 page.get_by_role("button", name="解密文件").click() 7 else: 8 page.goto(new_url) 9 page.get_by_placeholder("文件訪問密碼").click() 10 page.get_by_role("button", name="解密文件").click()
(三)開始下載
playWright下載資源需利用 page.expect_download 函數。
下載完整代碼如下:
1 import time,os 2 3 from playwright.sync_api import Playwright, sync_playwright, expect 4 5 6 def run(playwright: Playwright) -> None: 7 browser = playwright.chromium.launch(channel="chrome", headless=False) # 此處使用的是本地chrome瀏覽器 8 context = browser.new_context() 9 path = r'D:\PycharmProjects\wxauto\novelurl' 10 dir_list = os.listdir(path) 11 # 使用cookies 12 # cookies = [] 13 # context.add_cookies(cookies) 14 page = context.new_page() 15 for i in range(len(dir_list)): 16 try: 17 novel_url = os.path.join(path, dir_list[i]) 18 print(novel_url) 19 with open(novel_url) as f: 20 for j in f.readlines(): 21 new_name,new_url = j.strip().split("分割") 22 if "t00y.com" in new_url: 23 page.goto(new_url) 24 elif "?p=6195" not in new_url: 25 page.goto(new_url+"?p=6195") 26 page.get_by_placeholder("文件訪問密碼").click() 27 page.get_by_role("button", name="解密文件").click() 28 else: 29 page.goto(new_url) 30 page.get_by_placeholder("文件訪問密碼").click() 31 page.get_by_role("button", name="解密文件").click() 32 33 with page.expect_download(timeout=100000) as download_info: 34 page.get_by_role("button", name="立即下載").first.click() 35 print(new_name,"開始下載") 36 download_file = download_info.value 37 download_file.save_as("./novel/"+dir_list[i][:-4]+"/"+download_file.suggested_filename) 38 time.sleep(3) 39 os.remove(novel_url) 40 print(i+1,dir_list[i],"下載結束") 41 except: 42 print(novel_url,"出錯") 43 time.sleep(60) 44 page.close() 45 46 # --------------------- 47 context.close() 48 browser.close() 49 50 51 with sync_playwright() as playwright: 52 run(playwright)
(四)運行結果
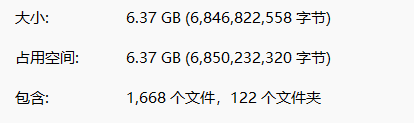
TRANSLATE with


