
共兩個依賴的需提前安裝的第三方庫:requests和bs4庫 cmd命令行輸入安裝requests庫:pip3 install -i https://pypi.douban.com/simple requests 安裝bs4庫:pip3 install -i https://pypi.douban. ...
共兩個依賴的需提前安裝的第三方庫:requests和bs4庫
cmd命令行輸入安裝requests庫:pip3 install -i https://pypi.douban.com/simple requests
安裝bs4庫:pip3 install -i https://pypi.douban.com/simple beautifulsoup4
本微項目源文件下載地址:
https://wwuw.lanzouj.com/i1Au51a0312d
解壓文件後,需按照解壓包內教程裝載Cookie即可使用。 本py腳本文件較符合有需求者使用,更適合python爬蟲初學者學習使用,代碼註釋較多,思路易理解。
本py腳本文件使用教程:
首先解壓壓縮包,打開包內的 “運行py文件前請閱讀!.txt” 文件,按其步驟裝載Cookie後方可使用腳本:
運行該程式前:請打開瀏覽器前往"https://www.baidu.com"手動登錄自己的百度賬戶,按F12打開開發者模式,選擇最上面一排Network/網路選項卡。

接著按F5刷新本網頁,捕獲到的請求里一直往上翻到最頂端,選擇第一次請求(即名稱為www.baidu.com的請求)。
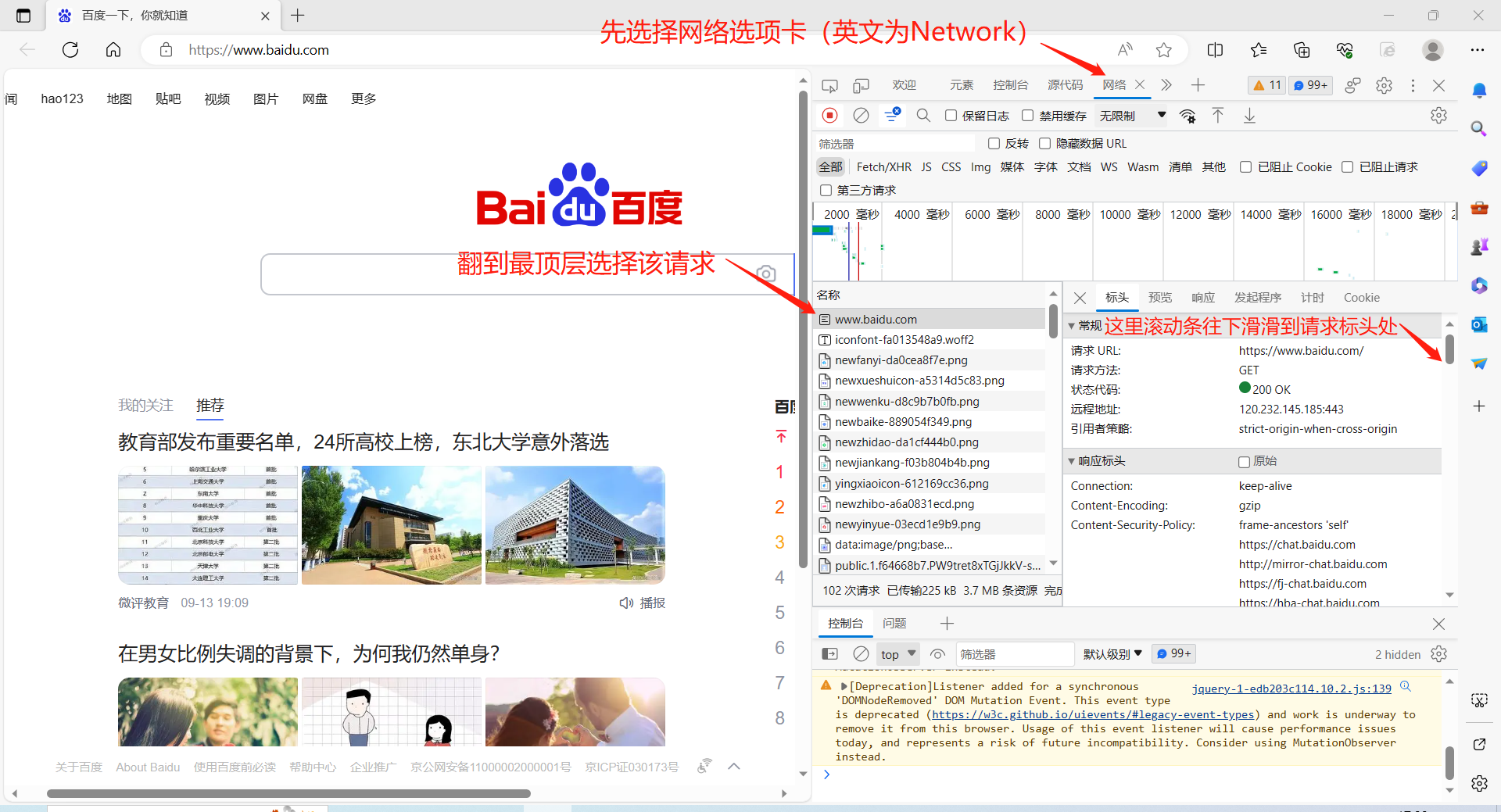
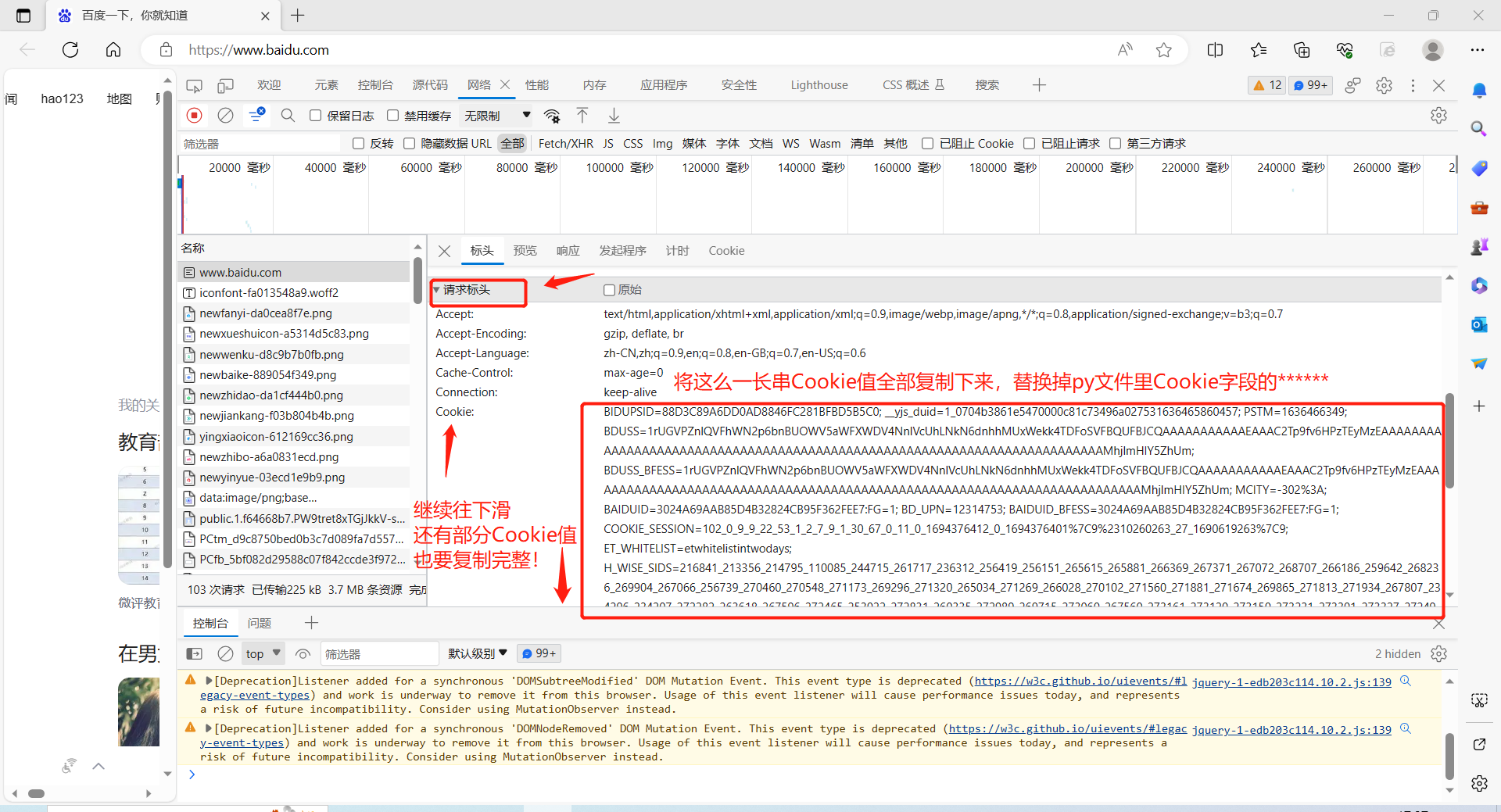
再選擇右側標頭選項卡,往下滑到請求標頭處,將Cookie欄位的值全部複製下來(有很長一段的)替換掉下行的****** 替換後可直接運行該文件。
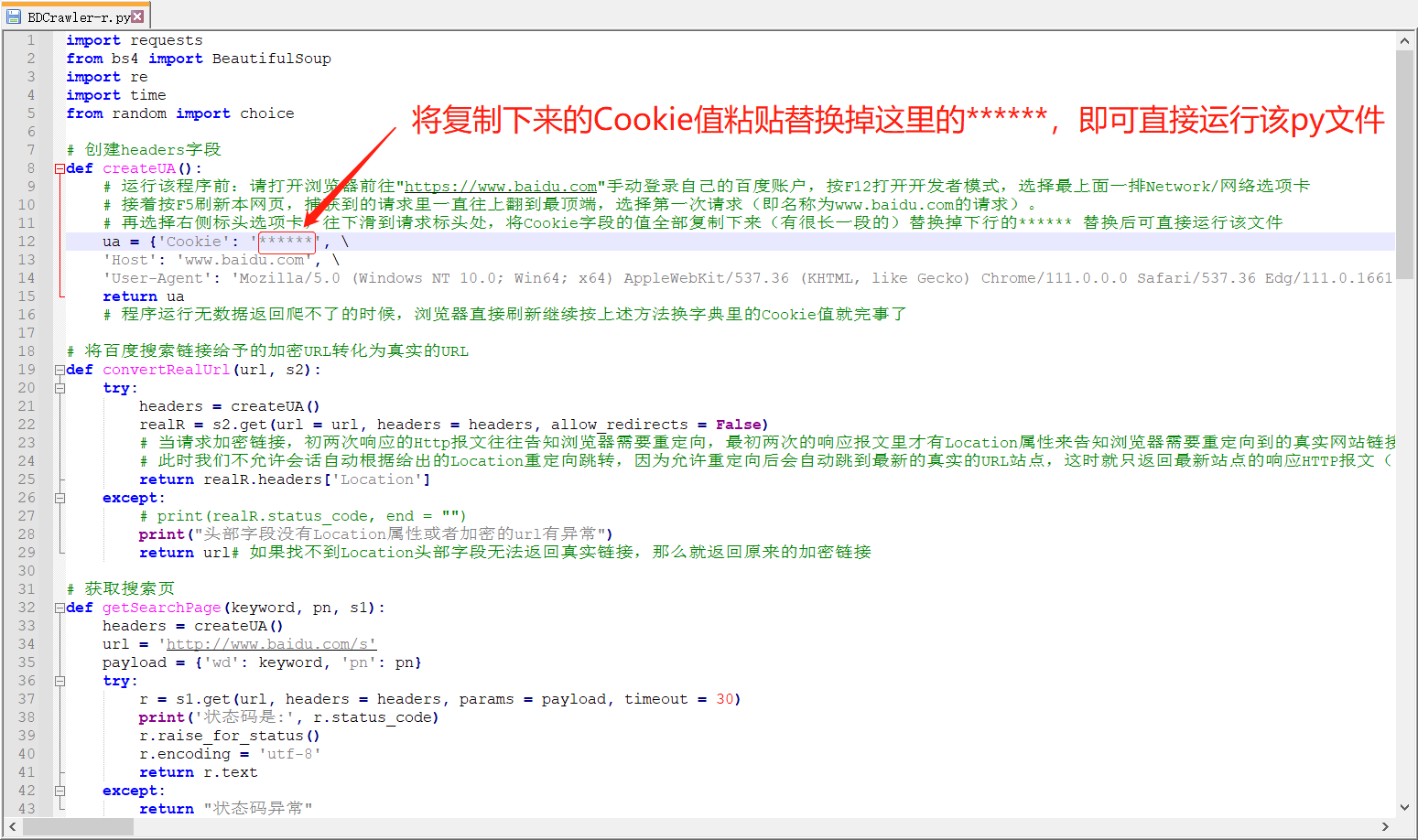
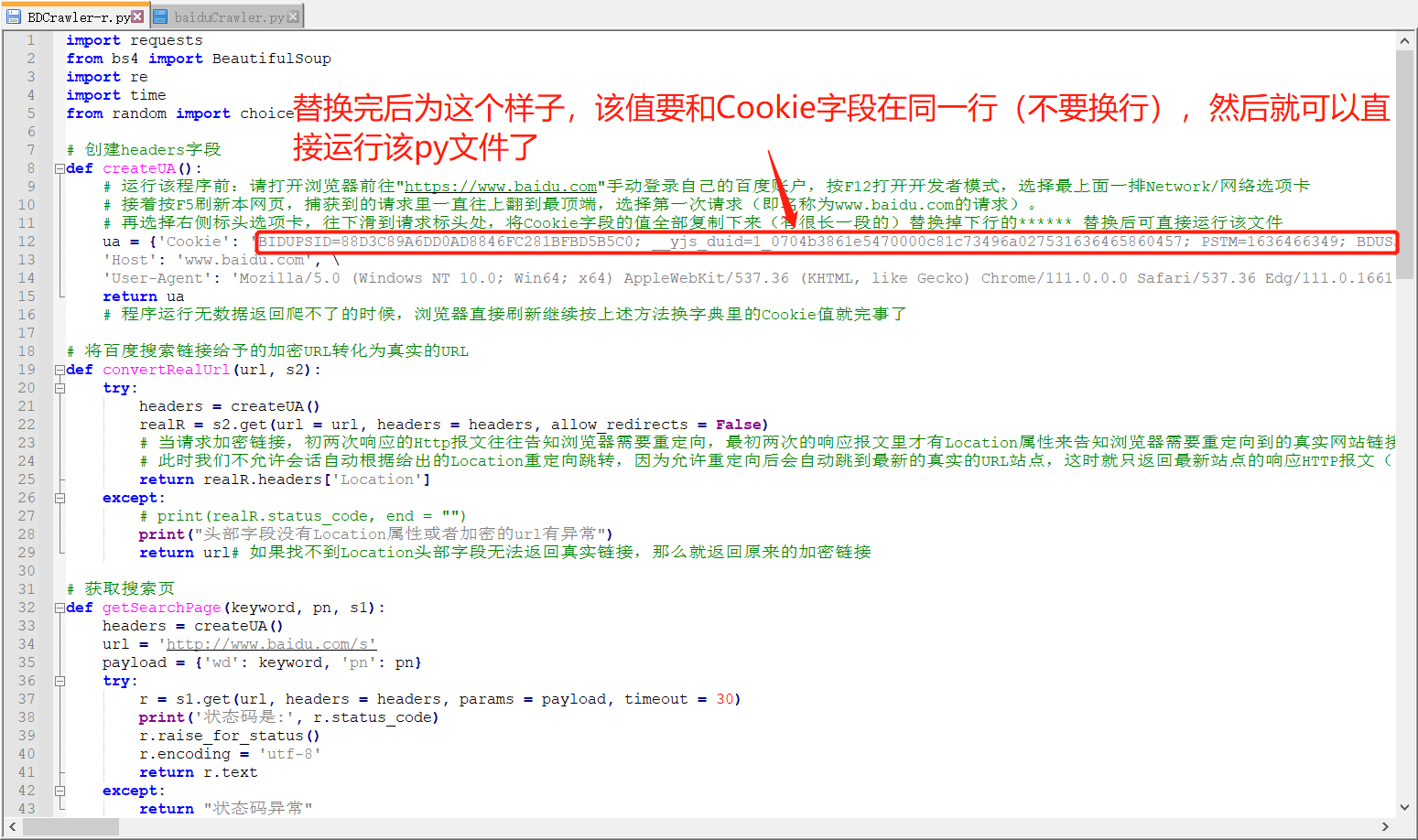
按上述步驟裝載完Cookie後記得保存py腳本文件,就可以直接F5運行該腳本了。下圖這裡我用的是cmd控制台環境來跑腳本。


找到保存結果的BDlinks.csv文件後,可用WPS、微軟Excel等軟體直接打開。
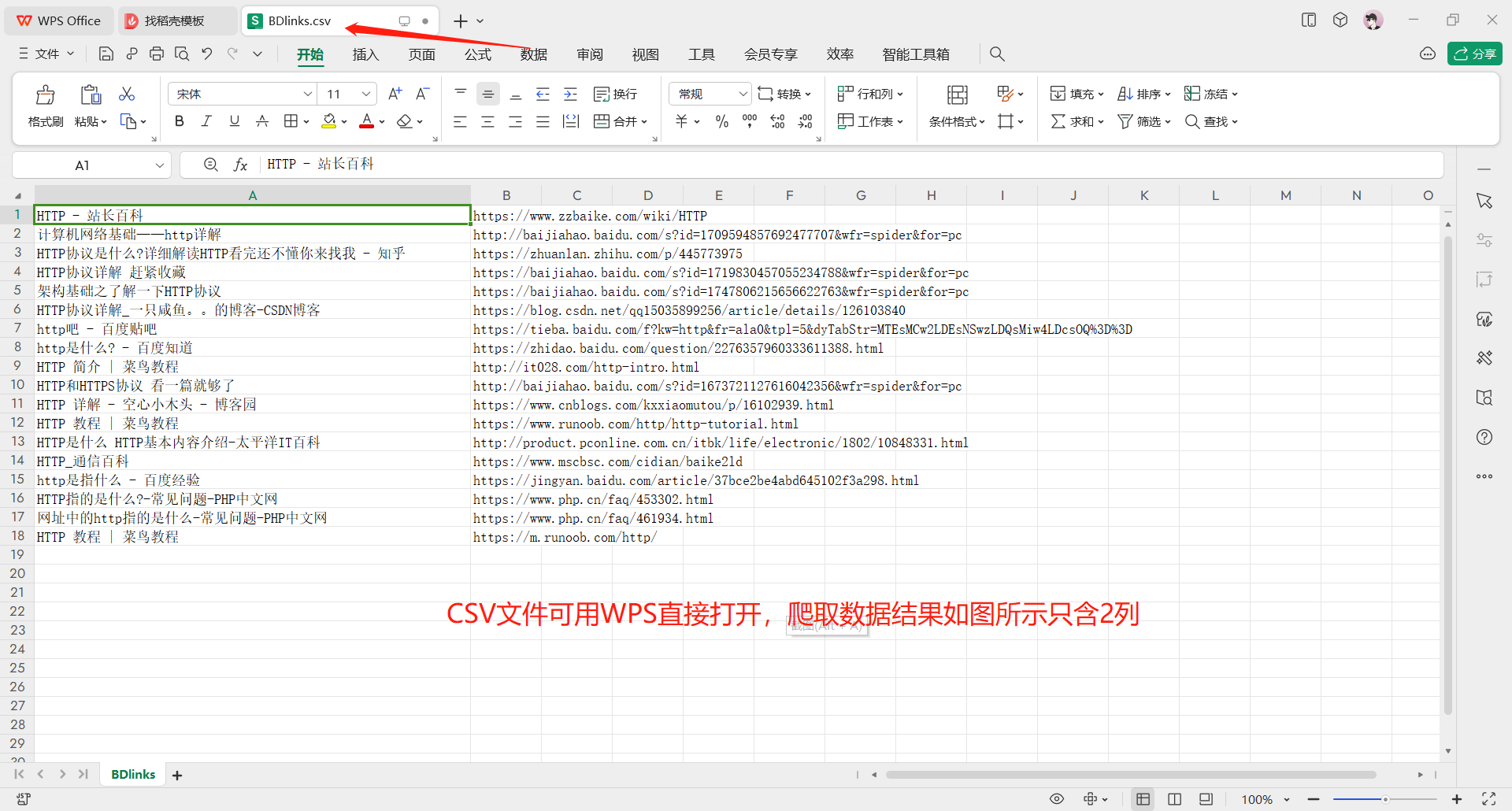
如若該py腳本首次運行就失敗,運行後無數據列印出來,一般是未成功裝載Cookie的問題,請按開頭的步驟重新裝載Cookie。
如若該py腳本多次運行後突然無數據列印出來,一般是 “高頻訪問百度伺服器/被識別爬蟲” 導致無數據返回,通常解決方法為換新Cookie:瀏覽器F5刷新後繼續按按開頭的步驟重新裝載Cookie。
最後可考慮是爬蟲代碼失效等其他問題,發文近日該爬蟲仍有效。
本微項目源碼:
1 import requests 2 from bs4 import BeautifulSoup 3 import re 4 import time 5 from random import choice 6 7 # 創建headers欄位 8 def createUA(): 9 # 運行該程式前:請打開瀏覽器前往"https://www.baidu.com"手動登錄自己的百度賬戶,按F12打開開發者模式,選擇最上面一排Network/網路選項卡 10 # 接著按F5刷新本網頁,捕獲到的請求里一直往上翻到最頂端,選擇第一次請求(即名稱為www.baidu.com的請求)。 11 # 再選擇右側標頭選項卡,往下滑到請求標頭處,將Cookie欄位的值全部複製下來(有很長一段的)替換掉下行的****** 替換後可直接運行該文件 12 ua = {'Cookie': '******', \ 13 'Host': 'www.baidu.com', \ 14 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36 Edg/111.0.1661.54'} 15 return ua 16 # 程式運行無數據返回爬不了的時候,瀏覽器直接刷新繼續按上述方法換字典里的Cookie值就完事了 17 18 # 將百度搜索鏈接給予的加密URL轉化為真實的URL 19 def convertRealUrl(url, s2): 20 try: 21 headers = createUA() 22 realR = s2.get(url = url, headers = headers, allow_redirects = False) 23 # 當請求加密鏈接,初兩次響應的Http報文往往告知瀏覽器需要重定向,最初兩次的響應報文里才有Location屬性來告知瀏覽器需要重定向到的真實網站鏈接。 24 # 此時我們不允許會話自動根據給出的Location重定向跳轉,因為允許重定向後會自動跳到最新的真實的URL站點,這時就只返回最新站點的響應HTTP報文(已完成重定向後),此時響應標頭裡不再有指示重定向url的Location欄位。此方法就會失效! 25 return realR.headers['Location'] 26 except: 27 # print(realR.status_code, end = "") 28 print("頭部欄位沒有Location屬性或者加密的url有異常") 29 return url# 如果找不到Location頭部欄位無法返回真實鏈接,那麼就返回原來的加密鏈接 30 31 # 獲取搜索頁 32 def getSearchPage(keyword, pn, s1): 33 headers = createUA() 34 url = 'http://www.baidu.com/s' 35 payload = {'wd': keyword, 'pn': pn} 36 try: 37 r = s1.get(url, headers = headers, params = payload, timeout = 30) 38 print('狀態碼是:', r.status_code) 39 r.raise_for_status() 40 r.encoding = 'utf-8' 41 return r.text 42 except: 43 return "狀態碼異常" 44 45 # 升級!爬取一頁的標題和真實鏈接 46 def upgradeCrawler(html, s2): 47 soup = BeautifulSoup(html, 'lxml') 48 titles = [] 49 links = [] 50 for h3 in soup.find_all('h3', {'class': re.compile('c-title t')}): 51 # a.text為獲取該路徑下所有子孫字元串吧。可能剛好a元素和em元素間沒有換行符,所以抓取的字元串里沒有\n換行符 52 g_title = h3.a.text.replace('\n', '').replace(',', ' ').strip()# 去掉換行和空格,部分標題中還有逗號會影響CSV格式存儲,也要去除。 53 g_url = h3.a.attrs['href'] 54 g_url = convertRealUrl(g_url, s2) 55 print("{}\t{}\t".format(g_title, g_url)) 56 titles.append(g_title) 57 links.append(g_url) 58 return titles, links 59 60 # 將二維列表數據寫入CSV文件 61 def writeCSV(titles, links): 62 infos = list(zip(titles, links)) 63 fo = open('./BDlinks.csv', 'at', encoding='utf-8')# 需要鎖定用utf-8編碼打開,不然該文件很可能會以gbk中文編碼存儲,這導致部分url中的西文字元存儲到本文件時無法通過gbk模式編碼存儲。 64 for row in infos: 65 fo.write(",".join(row) + "\n") 66 fo.close() 67 print("CSV文件已保存!") 68 69 # 頂層設計 70 def main(): 71 while True: # 迴圈 72 keyword = input("請輸入搜索關鍵詞:") 73 num = int(input("請輸入爬取頁數:")) 74 titles = [] 75 links = [] 76 # s1會話用於獲取搜索結果頁 77 s1 = requests.session() 78 # s2會話用於轉真實URL 79 s2 = requests.session() 80 # 第1頁為0,第2頁為10,第3頁為20,依次類推 81 num = num * 10 82 for pn in range(0, num, 10): 83 html = getSearchPage(keyword, pn, s1) 84 print('標題\tURL\t') 85 ti, li = upgradeCrawler(html, s2) 86 titles += ti 87 links += li 88 print("{0:->41}{1:-<36.0f}".format("當前頁碼為:", pn / 10 + 1)) 89 time.sleep(5) 90 print('爬取完成!') 91 writeCSV(titles, links) 92 93 if __name__ == '__main__': 94 main()
有一小部分註釋是作者開發學習過程中寫的個人筆記,看不懂的還請跳過。
以上皆為原創內容,倘若本文對你有幫助的話還請點下下方的推薦和贊,你的鼓勵就是作者創作的最大動力呀!
本文來自博客園,作者:onullo,轉載請註明原文鏈接:https://www.cnblogs.com/onullo/p/17731811.html


