
本文將從 e2e 的基本介紹,e2e 的使用與擴展,session 日誌隔離三個維度為大家帶來 ChunJun e2e & session 日誌隔離的分享。 大量具體代碼和演示請看視頻教程⬇️ 視頻課程: https://www.bilibili.com/video/BV1ru411P7oZ/?sp ...
本文將從 e2e 的基本介紹,e2e 的使用與擴展,session 日誌隔離三個維度為大家帶來 ChunJun e2e & session 日誌隔離的分享。
大量具體代碼和演示請看視頻教程⬇️
視頻課程:
https://www.bilibili.com/video/BV1ru411P7oZ/?spm_id_from=333.999.0.0
課件獲取:
https://www.dtstack.com/resources/1052?src=szsm
ChunJun 為何選擇 e2e 測試
ChunJun 項目是基於 Flink 進行擴展,並開發了大量插件來支持數據同步和 SQL 執行,當前支持的數據源插件已經超過50個,所以如何保證各個插件的質量是 ChunJun 非常迫切的需求。以下是兩種測試方式:
● 單元測試
· 目的:測試代碼的單個部分(例如函數、方法或類)以確保它們按預期工作
· 速度:通常非常快,因為它們只測試小的代碼片段,並且經常在隔離的環境中運行,不依賴外部資源
· 範圍:覆蓋範圍有限,雖然單元測試可以高效得捕獲代碼的邏輯錯誤,但它們不能檢測集成錯誤或複雜的交互問題
● 端到端測試(e2e測試)
· 目的:模擬真實場景來驗證整個系統的行為,它從用戶的角度測試應用程式,確保所有組件(前端、後端、資料庫、其他服務等)一起工作
· 速度:相對較慢,因為它們經常需要啟動整個應用程式,與真實的資料庫或外部服務進行交互
· 範圍:更全面地測試整個應用程式的工作流程,它們可以捕獲在單元測試中可能被遺漏的錯誤,如集成問題、配置錯誤、網路問題等
使用單元測試,大量歷史插件的單測補充,成本太大,且單測的質量以及範圍等都很難把控。而 e2e 測試只需要編寫各種插件的腳本並直接運行,並根據任務結果來判斷對應插件的可用性,這是一種比較方便並且更加全面的測試方法,所以我們選擇了增加 e2e 模塊來驗證各個插件。
e2e 的使用與擴展
e2e 使用-模塊介紹
ChunJun-e2e 模塊如下圖所示:
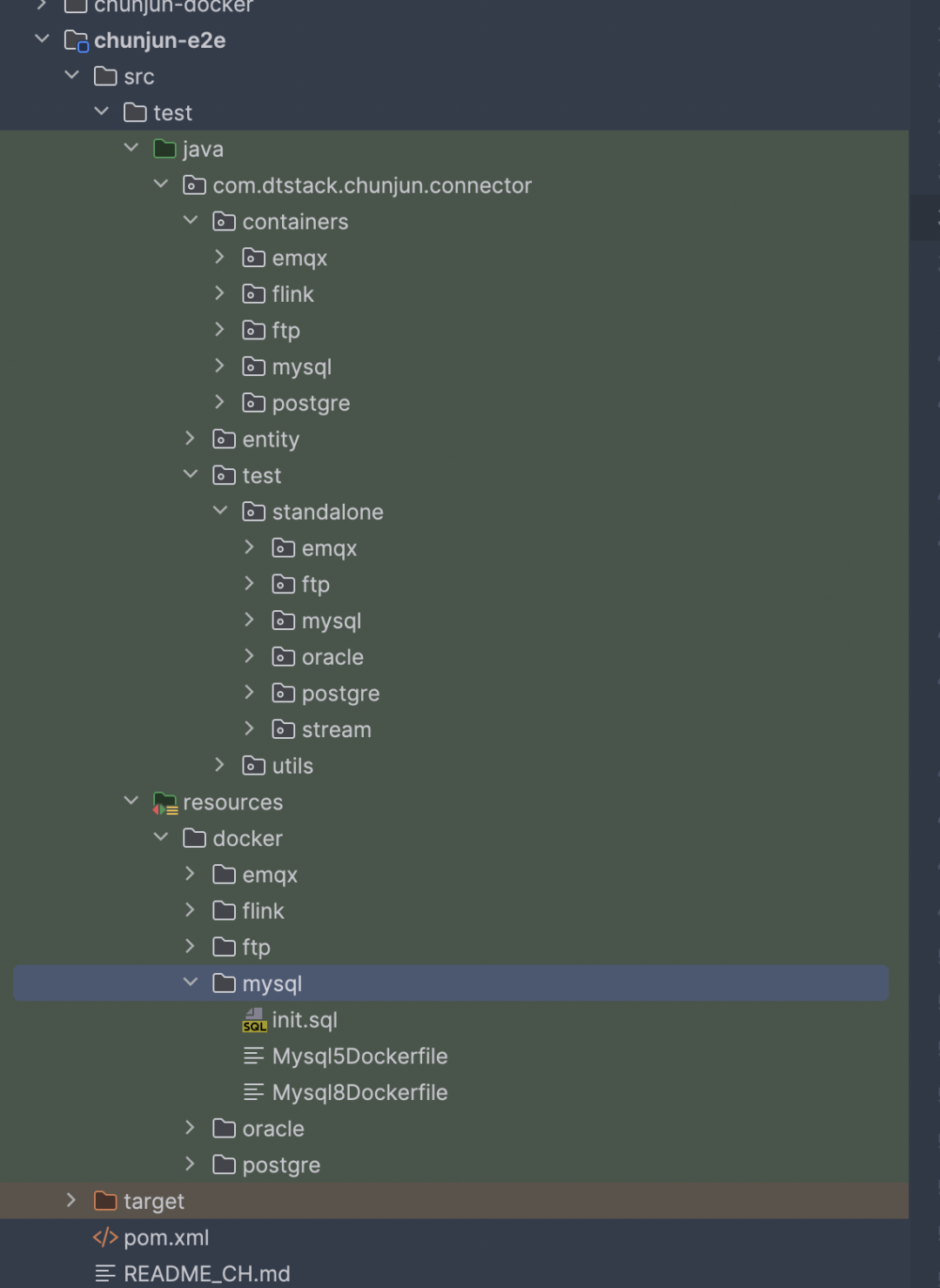
e2e 模塊主要分為3部分:
· containers 模塊:基於 TestContainer 擴展的各個數據源 container
· test 模塊:e2e 測試的各個插件入口
· resources 里的 docker 模塊: 各個數據源的 DockFile
ChunJun-e2e 模塊整合了 ChunJun-client 模塊,主要是藉助 TestContainer 在 Docker 環境中啟動 Flink 的 standlone 環境以及各個數據源。因此只需要編寫需要測試的 json 文件之後,通過 ChunJun-client 模塊快速提交任務到 standalone 集群中進行任務的運行,並根據任務運行結果等信息來判斷任務是否通過。
當前 ChunJun-e2e 模塊已經支持了 MySQL、PgSQL、Oracle、FTP、EMQX 的測試,後續社區會持續性的補充 e2e 測試的插件。
e2e 使用-代碼分析
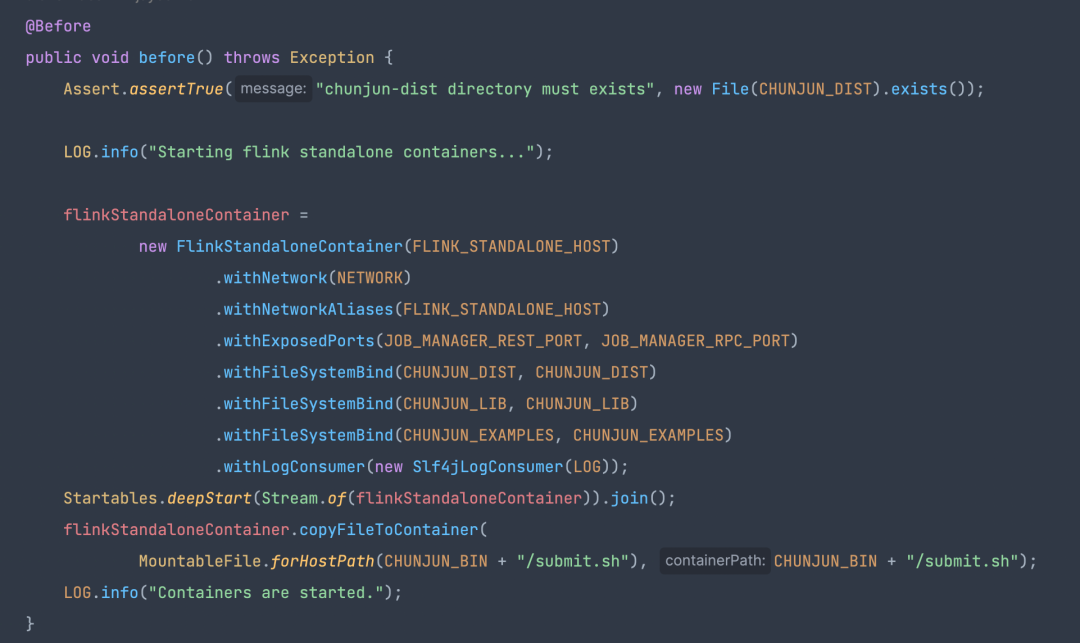
● ChunJunFlinkStandaloneTestEnvironment
· 內部封裝了一個 Flink 環境
· 提交任務和等待任務結束的方法
內置的 flinkStandaloneContainer 即為任務運行時所在的 flink standlone 集群。
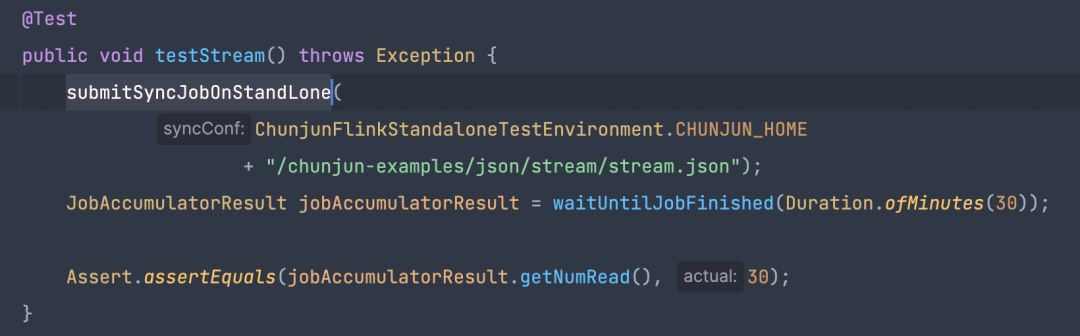
● 對 stream 插件的測試用例
test 方法里只需要 submitSyncJobOnStandLone 提交 json 腳本到 Flink 的 stabdlone 集群里,通過 waitUntilJobFinished 獲取任務結果併進行判斷。
e2e 使用-貢獻 e2e 插件
貢獻貢獻 e2e 插件的簡單流程:
· 編寫所需數據源的 DockerFile 文件
· 基於 TestContainer 和第一步的 DockerFile 創建對應的數據源 container
· 編寫插件任務 json 腳本
· 繼承 ChunjunFlinkStandaloneTestEnvironment,通過內置的提交方法提交任務即可
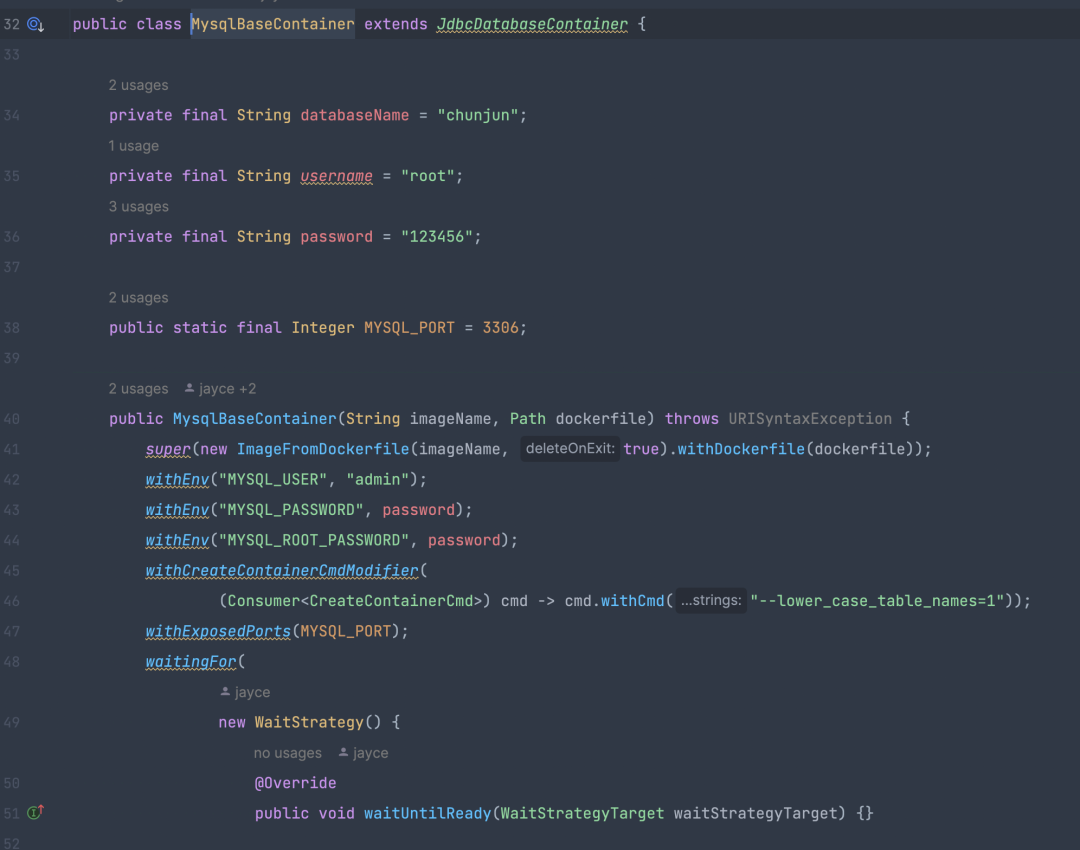
基於 TestContainer 進行擴展也是很簡單的,只需要繼承 GenericContainer 類,傳遞 DockerFile 文件路徑即可,TestContainer 對於 JDBC 類型數據源提供了 JdbcDatabaseContainer 抽象類。
框架所需要的環境 提交等介面都已經在 ChunJunFlinkStandaloneTestEnvironment 提供了,只需要編寫對應的數據源 DockerFile 和 json 腳本即可。
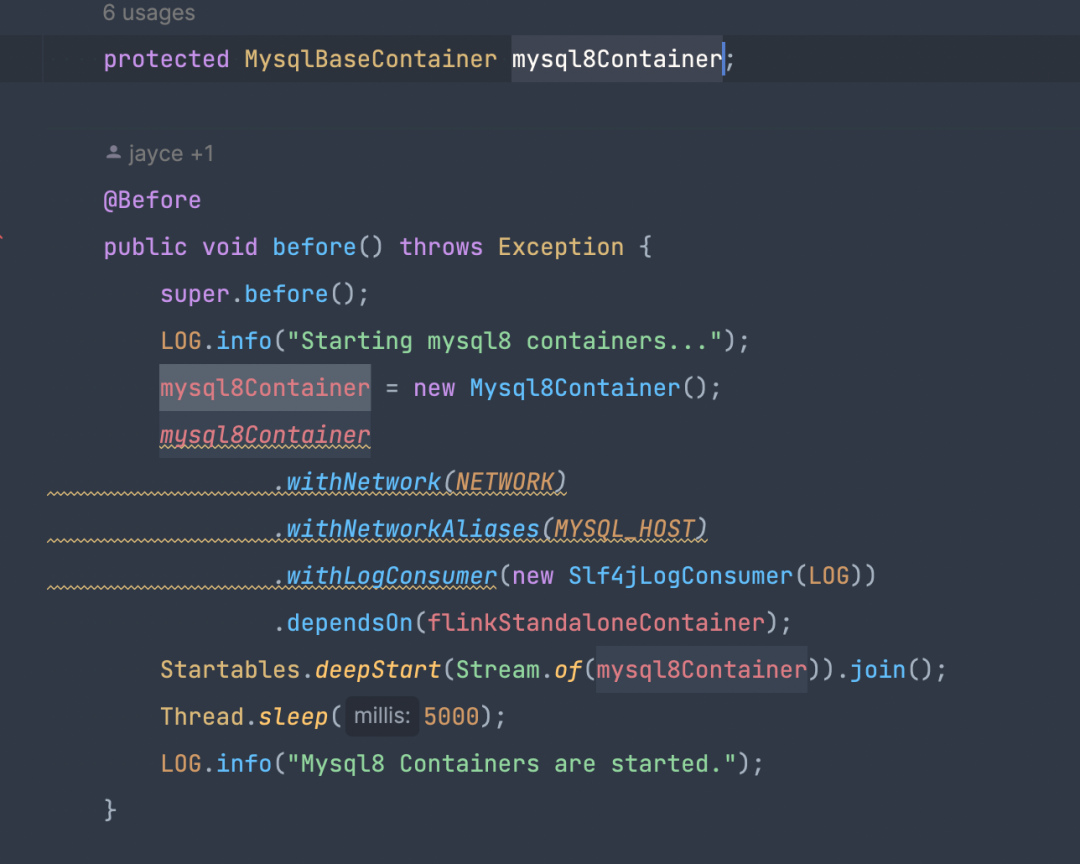
session 日誌隔離
session 日誌隔離-介紹
Flink on session 場景下,如果 TaskManager 不關閉,那麼這個 TaskManager 里的所有任務都會寫入同一個日誌文件中,導致需要查看任務日誌排查問題時,比較難查找到具體的每個任務日誌。
如果 TaskManager 里的每個任務的日誌都在不同的日誌文件里,每個日誌文件的名稱就是 jobid,那麼在查看任務日誌時只需要查看 jobid 的日誌文件即可。
為瞭解決這個問題,袋鼠雲內部通過修改 Flink 源碼以及 Log4j 的擴展,實現了 Flink on session 場景下,TaskManager 里每個任務的日誌會寫入對應的 jobid 日誌文件里。
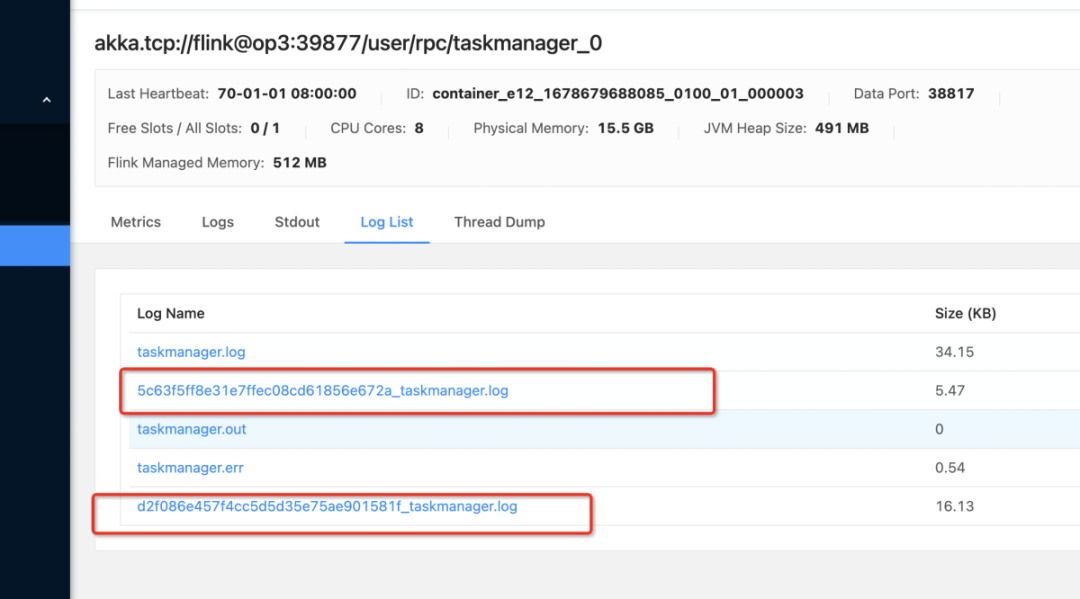
Flink 源碼改動
TaskExecutor 在接受到任務之後,會轉為 Task 對象。Task 對象是一個 Runnable 實現,內部持有一個線程,然後通過其內部線程執行客戶代碼邏輯。
因此每個 Task 都由一個 Thread 對應,在 Task 整個生命周期里,其 Thread 和 Task 都是綁定的。因此在 Run 的時候,將 jobId 放入 ThreadLocal 里即可。
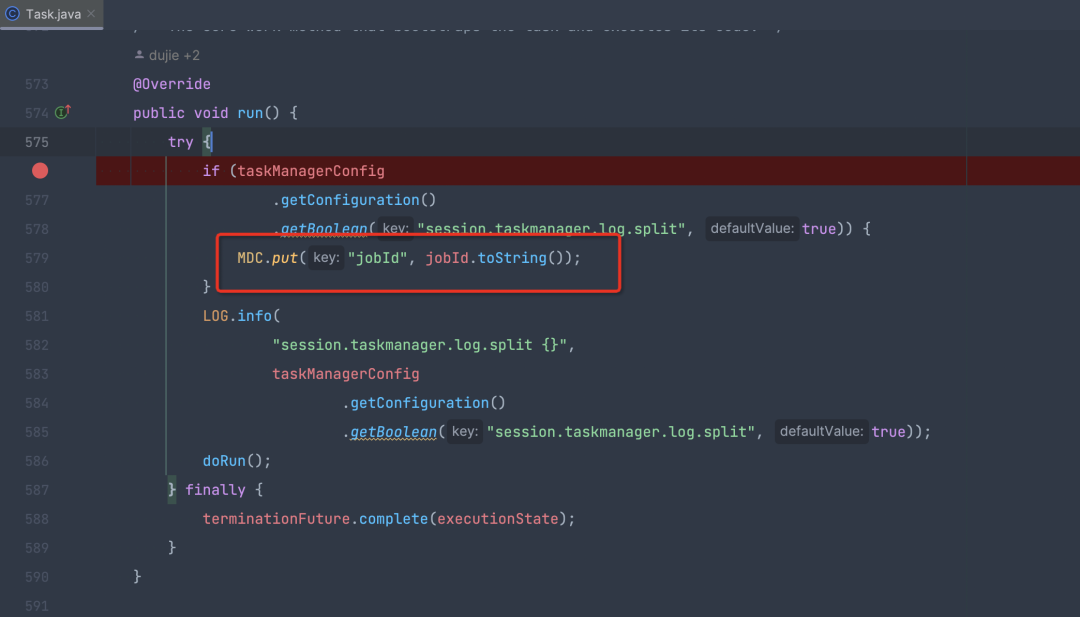
之後,我們需要在Flink 源碼中的org.apache.flink.runtime.taskmanager.Task#run裡加上 MDC.put("jobId", jobId.toString()); 即可。
父子線程場景下需要加上下述參數:
env.java.opts.taskmanager: "-DisThreadContextMapInheritable=true"
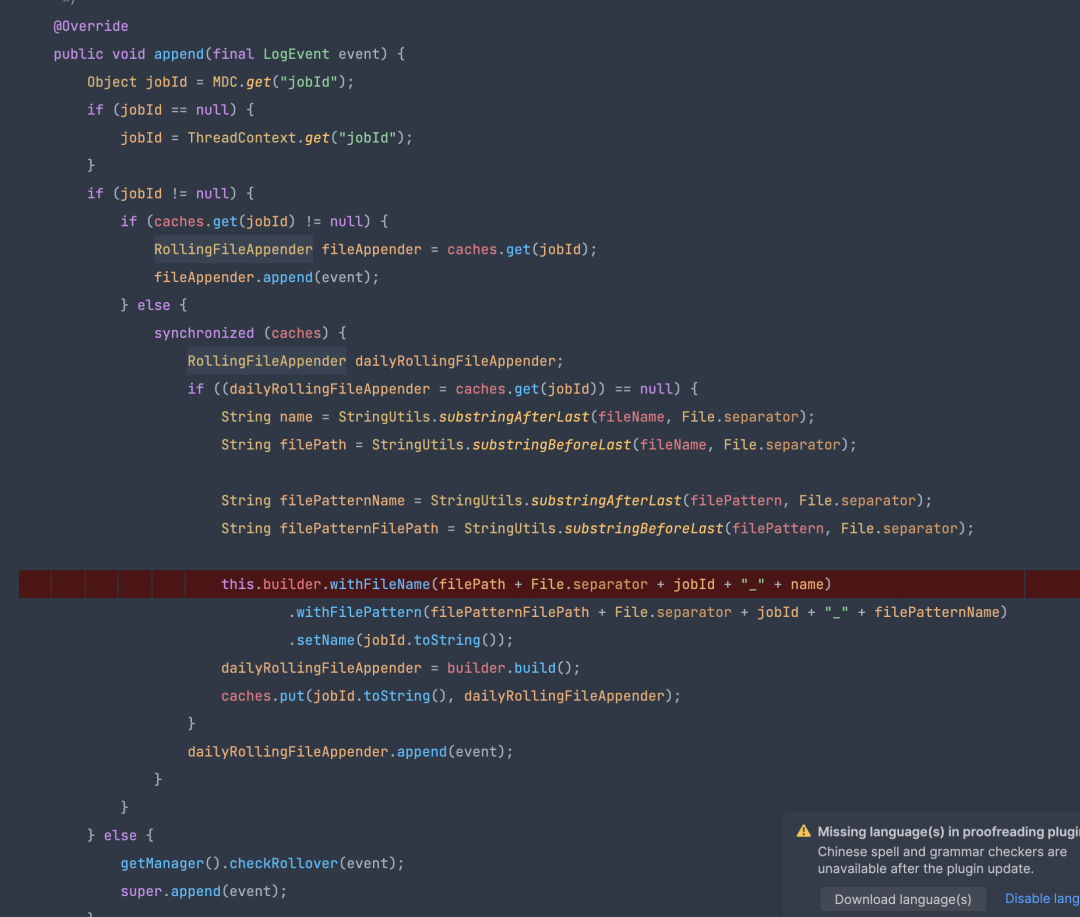
Log4j 擴展
Flink1.12 支持 Log4j2 進行日誌輸出,在日誌隔離方案中通過擴展 Log4j2 的 AbstractOutputStreamAppender,實現了通過一個自定義的 appender 來完成日誌輸出。
自定義的 appender 可以根據 MDC 里的 jobid 輸出到對應的日誌文件,因此其擴展邏輯為根據 MDC 里的 jobid 是否為空。如果不為空,則輸出到 jobid 對應的文件,否則就是預設的 taskmanager.log。
最終日誌隔離方案流程如下:
· 修改 Flink 源碼,增加 MDC.put("jobId", jobId.toString())
· 打包 Flink 源碼,將 Flink-dist 替換開源的 Flink-dist
· 基於 Log4j2 擴展 appender,並打包後的 jar 放入 Flink 的 lib 目錄下
· 修改 Flink conf 目錄下的 log4j.properties 文件,將 RollingFileAppender 替換為自定義的擴展 apped 類即可
《數棧產品白皮書》:https://www.dtstack.com/resources/1004?src=szsm
《數據治理行業實踐白皮書》下載地址:https://www.dtstack.com/resources/1001?src=szsm
想瞭解或咨詢更多有關袋鼠雲大數據產品、行業解決方案、客戶案例的朋友,瀏覽袋鼠雲官網:https://www.dtstack.com/?src=szbky
同時,歡迎對大數據開源項目有興趣的同學加入「袋鼠雲開源框架釘釘技術qun」,交流最新開源技術信息,qun號碼:30537511,項目地址:https://github.com/DTStack

