
### 前言 上篇文章 [13分鐘聊聊併發包中常用同步組件並手寫一個自定義同步組件](https://juejin.cn/post/7274475842998042665) 聊到併發包中常用的同步組件,並且還手把手實現了自定義的同步組件 本篇文章來聊聊併發包下的另一個核心-線程池 閱讀本文大概12分 ...
前言
上篇文章 13分鐘聊聊併發包中常用同步組件並手寫一個自定義同步組件 聊到併發包中常用的同步組件,並且還手把手實現了自定義的同步組件
本篇文章來聊聊併發包下的另一個核心-線程池
閱讀本文大概12分鐘
通讀本篇文章前先來看看幾個問題,看看你是否以及理解線程池
- 什麼是池化技術?它有什麼特點,哪些場景使用?
- Executor是什麼?它的設計思想是什麼樣的?
- 工作任務有幾種?有什麼特點?如何適配然後交給Executor的?
- 線程池是如何實現的?有哪些核心參數,該如何配置?工作流程是怎樣的?
- 線程池如何優雅的處理異常?如何關閉線程池?
- 處理定時的線程池是如何實現的?
池化技術
線程的創建、銷毀都會帶來一定的開銷
如果當我們需要使用到多線程時再去創建,使用完又去銷毀,這樣去使用不僅會拉長業務流程,還會增加創建、銷毀線程的開銷
於是有了池化技術的思想,將線程提前創建出來,放在一個池子(容器)中進行管理
當需要使用時,從池子里拿取一個線程來執行任務,執行完畢後再放回池子
不僅是線程有池化的思想,連接也有池化的思想,也就是連接池
池化技術不僅能復用資源、提高響應,還方便管理
Executor框架
Executor框架是什麼?
可以暫時把Executor看成線程池的抽象,它定義如何去執行任務
public interface Executor {
void execute(Runnable command);
}
Executor將工作任務與線程池進行分離解耦
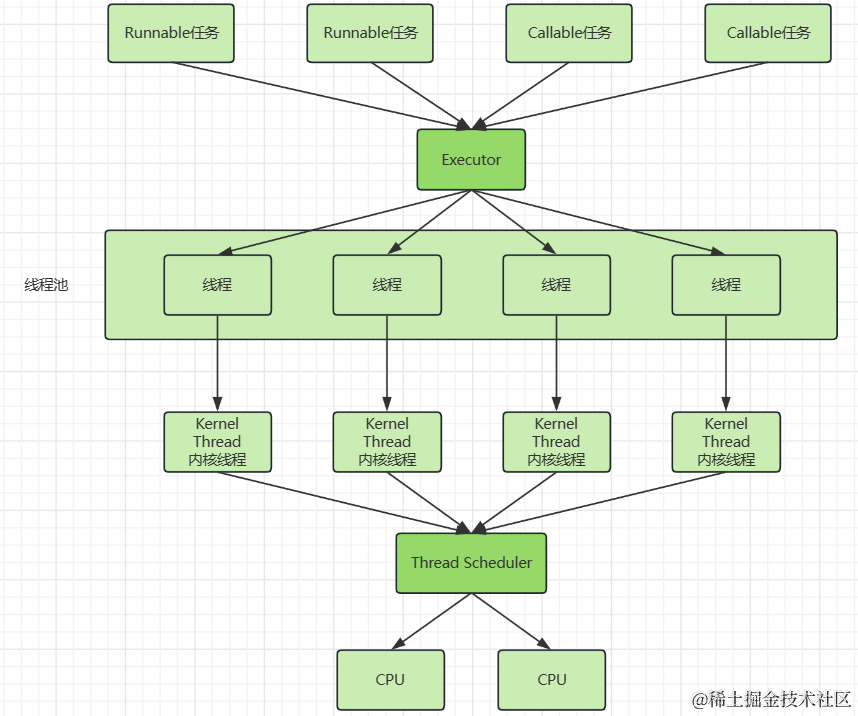
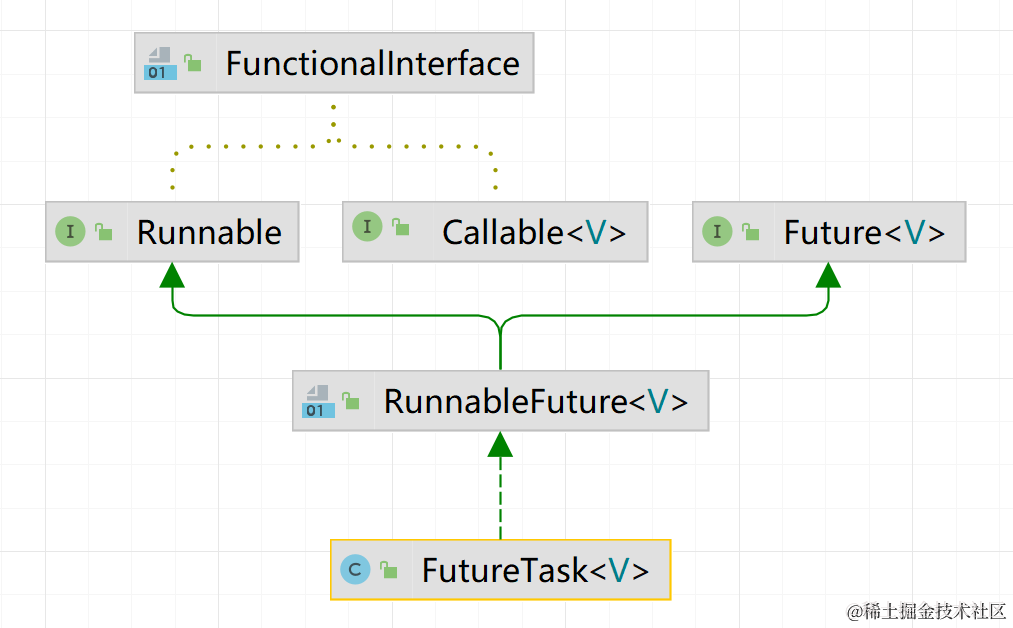
工作任務被分為兩種:無返回結果的Runnable和有返回結果的Callable
線上程池中允許執行這兩種任務,其中它們都是函數式介面,可以使用lambda表達式來實現
有的同學可能會有疑問,上文Executor框架定義的執行方法不是只允許傳入Runnable任務嗎?
那Callable任務調用哪個方法來執行呢?
Future介面用來定義獲取非同步任務的結果,它的實現類常是FutureTask
FutureTask實現Runnable的同時,還用欄位存儲Callable,在其實現Runnable時實際上會去執行Callable任務
線程池在執行Callable任務時,會將使用FutureTask將其封裝成Runnable執行(具體源碼我們後面再聊),因此Executor的執行方法入參只有Runnable
FutureTask相當於適配器,將Callable轉換為Runnable再進行執行
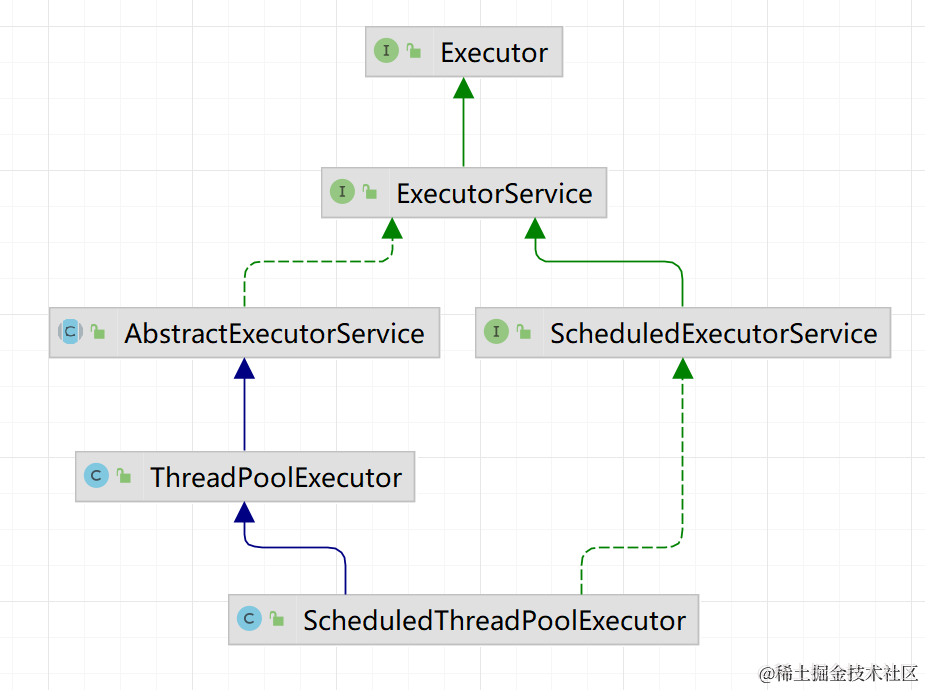
Executor 定義線程池,而它的重要實現是ThreadPoolExecutor
在ThreadPoolExecutor的基礎上,還有個做定時的線程池ScheduledThreadPoolExecutor
ThreadPoolExecutor
核心參數
ThreadPoolExecutor主要有七個重要的參數
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
- corePoolSize 線程池核心線程數量
- maximumPoolSize 線程池允許創建的最大線程數
- keepAliveTime 超時時間,TimeUnit時間單位:非核心線程空閑後存活的時間
- workQueue 存放等待執行任務的阻塞隊列
- threadFactory線程工廠:規定如何創建線程,可以根據業務不同規定 不同的線程組名稱
- RejectedExecutionHandler 拒絕策略:當線程不夠用,並且阻塞隊列爆滿時如何拒絕任務的策略
| 拒絕策略 | 作用 |
|---|---|
| AbortPolicy 預設 | 拋出異常 |
| CallerRunsPolicy | 調用線程來執行任務 |
| DiscardPolicy | 不處理,丟棄 |
| DiscardOldestPolicy | 丟棄隊列中最近一個任務,並立即執行當前任務 |
線程池中除了構造時的核心參數外,還使用內部類Worker來封裝線程和任務,並使用HashSet容器workes工作隊列存儲工作線程worker
實現原理
流程圖
為了清晰的理解線程池實現原理,我們先用流程圖和總結概述原理,最後來看源碼實現
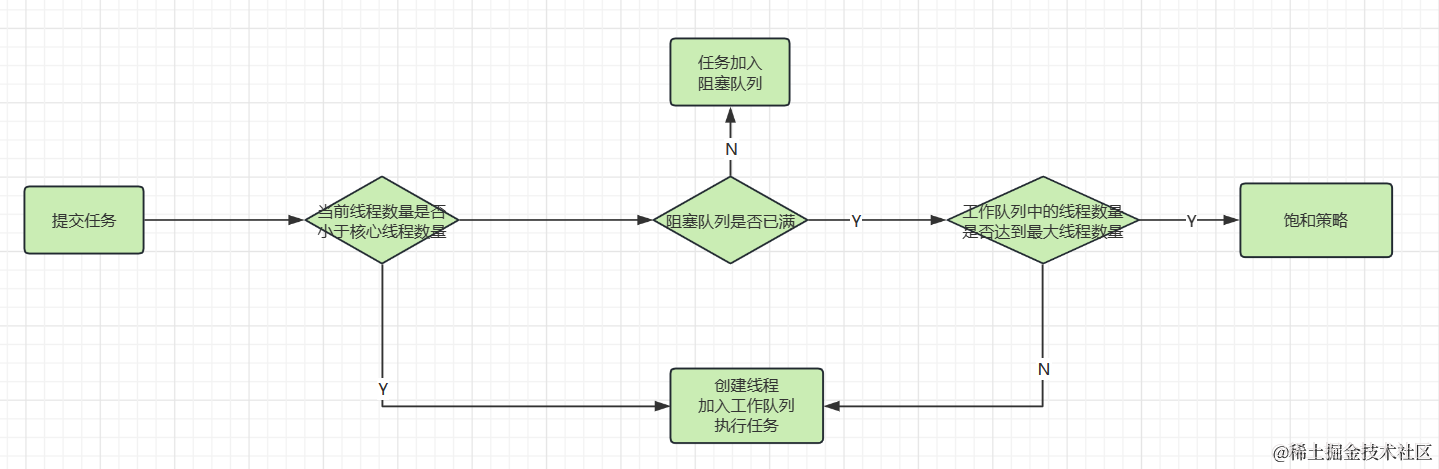
- 如果工作線程數量小於核心線程數量,創建線程、加入工作隊列、執行任務
- 如果工作線程數量大於等於核心線程數量並且線程池還在運行則嘗試將任務加入阻塞隊列
- 如果任務加入阻塞隊列失敗(說明阻塞隊列已滿),並且工作線程小於最大線程數,則創建線程執行
- 如果阻塞隊列已滿、並且工作線程數量達到最大線程數量則執行拒絕策略
execute
線程池有兩種提交方式execute和submit,其中submit會封裝成RunnableFuture最終都來執行execute
public <T> Future<T> submit(Callable<T> task) {
if (task == null) throw new NullPointerException();
RunnableFuture<T> ftask = newTaskFor(task);
execute(ftask);
return ftask;
}
execute中實現線程池的整個運行流程
public void execute(Runnable command) {
//任務為空直接拋出空指針異常
if (command == null)
throw new NullPointerException();
//ctl是一個整型原子狀態,包含workerCount工作線程數量 和 runState是否運行兩個狀態
int c = ctl.get();
//1.如果工作線程數 小於 核心線程數 addWorker創建工作線程
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
// 2.工作線程數 大於等於 核心線程數時
// 如果 正在運行 嘗試將 任務加入隊列
if (isRunning(c) && workQueue.offer(command)) {
//任務加入隊列成功 檢查是否運行
int recheck = ctl.get();
//不在運行 並且 刪除任務成功 執行拒絕策略 否則查看工作線程為0就創建線程
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
// 3.任務加入隊列失敗,嘗試去創建非核心線程,成功則結束
else if (!addWorker(command, false))
// 4.失敗則執行拒絕策略
reject(command);
}
addWorker
addWorker用於創建線程加入工作隊列並執行任務
第二個參數用來判斷是不是創建核心線程,當創建核心線程時為true,創建非核心線程時為false
private boolean addWorker(Runnable firstTask, boolean core) {
//方便跳出雙層迴圈
retry:
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// Check if queue empty only if necessary.
// 檢查狀態
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
for (;;) {
int wc = workerCountOf(c);
//工作線程數已滿 返回false
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
//CAS自增工作線程數量 成功跳出雙重迴圈
if (compareAndIncrementWorkerCount(c))
break retry;
//CAS失敗 重新讀取狀態 內迴圈
c = ctl.get(); // Re-read ctl
if (runStateOf(c) != rs)
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
}
//來到這裡說明已經自增工作線程數量 準備創建線程
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
//創建worker 通過線程工廠創建線程
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
//全局鎖
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// Recheck while holding lock.
// Back out on ThreadFactory failure or if
// shut down before lock acquired.
int rs = runStateOf(ctl.get());
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
//添加線程
workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
//標記線程添加完
workerAdded = true;
}
} finally {
mainLock.unlock();
}
//執行線程
if (workerAdded) {
t.start();
workerStarted = true;
}
}
} finally {
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}
addWorker中會CAS自增工作線程數量,創建線程再加鎖,將線程加入工作隊列workes(hashset),解鎖後開啟該線程去執行任務
runWorker
worker中實現Runnable的是runWorker方法,在啟動線程後會不停的執行任務,任務執行完就去獲取任務執行
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
//迴圈執行任務 getTask獲取任務
while (task != null || (task = getTask獲取任務()) != null) {
w.lock();
// If pool is stopping, ensure thread is interrupted;
// if not, ensure thread is not interrupted. This
// requires a recheck in second case to deal with
// shutdownNow race while clearing interrupt
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
//執行前 鉤子方法
beforeExecute(wt, task);
Throwable thrown = null;
try {
//執行
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
//執行後鉤子方法
afterExecute(task, thrown);
}
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}
在執行前後預留兩個鉤子空方法,留給子類來擴展,後文處理線程池異常也會用到
配置參數
線程池中是不是越多線程就越好呢?
首先,我們要明白創建線程是有開銷的,程式計數器、虛擬機棧、本地方法棧都是線程私有的空間
並且線程在申請空間時,是通過CAS申請年輕代的Eden區中一塊記憶體(因為可能存在多線程同時申請所以要CAS)
線程太多可能導致Eden空間被使用太多導致young gc,並且線程上下文切換也需要開銷
因此,線程池中線程不是越多越好,行業內分為兩種大概方案
針對CPU密集型,線程池設置最大線程數量為CPU核心數量+1,避免上下文切換,提高吞吐量,多留一個線程兜底
針對IO密集型,線程池設置最大線程數量為2倍CPU核心數量,由於IO需要等待,為了避免CPU空閑就多一些線程
具體業務場景需要具體分析,然後加上大量測試才能得到最合理的配置
Executor框架通過靜態工廠方法提供幾種線程池,比如:Executors.newSingleThreadExecutor()、Executors.newFixedThreadPool()、Executors.newCachedThreadPool()
但由於業務場景的不同,最好還是自定義線程池;當理解線程池參數和實現原理後,查看它們的源碼並不難,我們不過多敘述
處理異常
線程池中如果出現異常會怎麼樣?
Runnable
當我們使用Runnable任務時,出現異常會直接拋出
threadPool.execute(() -> {
int i = 1;
int j = 0;
System.out.println(i / j);
});
面對這種情況,我們可以在Runnable任務中使用try-catch進行捕獲
threadPool.execute(() -> {
try {
int i = 1;
int j = 0;
System.out.println(i / j);
} catch (Exception e) {
System.out.println(e);
}
});
實際操作的話用日誌記錄哈,不要列印到控制台
Callable
當我們使用Callable任務時,使用submit方法會獲取Future
Future<Integer> future = threadPool.submit(() -> {
int i = 1;
int j = 0;
return i / j;
});
如果不使用Future.get()去獲取返回值,那麼異常就不會拋出,這是比較危險的
為什麼會出現這樣的情況呢?
前文說過執行submit時會將Callable封裝成FutureTask執行
在其實現Runnable中,在執行Callable任務時,如果出現異常會封裝在FutureTask中
public void run() {
//...其他略
try {
//執行call任務
result = c.call();
ran = true;
} catch (Throwable ex) {
//出現異常 封裝到FutureTask
result = null;
ran = false;
setException(ex);
}
//..
}
等到執行get時,先阻塞、直到完成任務再來判斷狀態,如果狀態不正常則拋出封裝的異常
private V report(int s) throws ExecutionException {
Object x = outcome;
if (s == NORMAL)
return (V)x;
if (s >= CANCELLED)
throw new CancellationException();
throw new ExecutionException((Throwable)x);
}
因此在處理Callable任務時,可以對任務進行捕獲也可以對get進行捕獲
//捕獲任務
Future<?> f = threadPool.submit(() -> {
try {
int i = 1;
int j = 0;
return i / j;
} catch (Exception e) {
System.out.println(e);
} finally {
return null;
}
});
//捕獲get
Future<Integer> future = threadPool.submit(() -> {
int i = 1;
int j = 0;
return i / j;
});
try {
Integer integer = future.get();
} catch (Exception e) {
System.out.println(e);
}
afterExecutor
還記得線程池的runWorker嗎?
它在迴圈中不停的獲取阻塞隊列中的任務執行,在執行前後預留鉤子方法
繼承ThreadPoolExecutor來重寫執行後的鉤子方法,記錄執行完是否發生異常,如果有異常則進行日誌記錄,作一層兜底方案
public class MyThreadPool extends ThreadPoolExecutor {
//...
@Override
protected void afterExecute(Runnable r, Throwable t) {
//Throwable為空 可能是submit提交 如果runnable為future 則捕獲get
if (Objects.isNull(t) && r instanceof Future<?>) {
try {
Object res = ((Future<?>) r).get();
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
} catch (ExecutionException e) {
t = e;
}
}
if (Objects.nonNull(t)) {
System.out.println(Thread.currentThread().getName() + ": " + t.toString());
}
}
}
這樣即使使用submit,忘記使用get時,異常也不會“消失”
setUncaughtException
創建線程時,可以設置未捕獲異常uncaughtException方法,當線程出現異常未捕獲時調用,也可以列印日誌作兜底
我們定義我們自己的線程工廠,以業務組group為單位,創建線程(方便出錯排查)並設置uncaughtException方法
public class MyThreadPoolFactory implements ThreadFactory {
private AtomicInteger threadNumber = new AtomicInteger(1);
private ThreadGroup group;
private String namePrefix = "";
public MyThreadPoolFactory(String group) {
this.group = new ThreadGroup(group);
namePrefix = group + "-thread-pool-";
}
@Override
public Thread newThread(Runnable r) {
Thread t = new Thread(group, r,
namePrefix + threadNumber.getAndIncrement(),
0);
t.setUncaughtExceptionHandler(new Thread.UncaughtExceptionHandler() {
@Override
public void uncaughtException(Thread t, Throwable e) {
System.out.println(t.getName() + ":" + e);
}
});
if (t.isDaemon()) {
t.setDaemon(false);
}
if (t.getPriority() != Thread.NORM_PRIORITY) {
t.setPriority(Thread.NORM_PRIORITY);
}
return t;
}
}
關閉線程池
關閉線程池的2種方法: shutdown(),shutdownNow()
它們的原理都是: 遍歷工作隊列wokers中的線程,逐個中斷(調用線程的interrupt方法) 無法響應中斷的任務可能永遠無法終止
shutdown 任務會被執行完
- 將線程池狀態設置為SHUTDOWN
- 中斷所有未正在執行任務的線程
shutdownNow 任務不一定會執行完
- 將線程池狀態設置為STOP
- 嘗試停止所有正在執行或暫停任務的線程
- 返回等待執行任務列表
通常使用shutdown,如果任務不一定要執行完可以使用shutdownNow
SecheduledThreadPoolExecutor
ScheduledThreadPoolExecutor在ThreadPoolExecutor的基礎上提供定時執行的功能
它有兩個定時的方法
scheduleAtFixedRate 以任務開始為周期起點,比如說一個任務執行要0.5s,每隔1s執行,相當於執行完任務過0.5s又開始執行任務
scheduledWithFixedDelay 以任務結束為周期起點,比如說一個任務執行要0.5s,每隔1s執行,相當於執行完任務過1s才開始執行任務
ScheduledThreadPoolExecutor scheduledThreadPoolExecutor = new ScheduledThreadPoolExecutor(2);
//scheduleAtFixedRate 固定頻率執行任務 周期起點為任務開始
scheduledThreadPoolExecutor.scheduleAtFixedRate(()->{
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("scheduleAtFixedRate 周期起點為任務開始");
//初始延遲:1s 周期:1s
},1,1, TimeUnit.SECONDS);
//scheduledWithFixedDelay 固定延遲執行任務,周期起點為任務結束
scheduledThreadPoolExecutor.scheduleWithFixedDelay(()->{
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("scheduledWithFixedDelay 周期起點為任務結束 ");
//初始延遲:1s 周期:1s
},1,1, TimeUnit.SECONDS);
定時線程池使用延遲隊列充當阻塞隊列實現的
延遲隊列是一個優先順序隊列,它排序存儲定時任務,時間越小越先執行
線程獲取任務時,會從延遲隊列中獲取定時任務,如果時間已到就執行
public RunnableScheduledFuture<?> take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
for (;;) {
RunnableScheduledFuture<?> first = queue[0];
//沒有定時任務 等待
if (first == null)
available.await();
else {
//獲取延遲時間
long delay = first.getDelay(NANOSECONDS);
//小於等於0 說明超時,拿出來執行
if (delay <= 0)
return finishPoll(first);
first = null; // don't retain ref while waiting
//當前線程是leader則等待對應的延遲時間,再進入迴圈取出任務執行
//不是leader則一直等待,直到被喚醒
if (leader != null)
available.await();
else {
Thread thisThread = Thread.currentThread();
leader = thisThread;
try {
available.awaitNanos(delay);
} finally {
if (leader == thisThread)
leader = null;
}
}
}
}
} finally {
if (leader == null && queue[0] != null)
available.signal();
lock.unlock();
}
}
這兩個定時方法一個以任務開始為周期起點、另一個以任務結束為周期起點
獲取定時任務的流程是相同的,只是它們構建的定時任務中延遲的時間不同
定時任務使用period 區別,為正數周期起點為任務開始,為負數時周期起點為任務結束
總結
本篇文章圍繞線程池,深入淺出的講解池化技術,Executor,線程池的參數、配置、實現原理、處理異常、關閉等
使用池化技術能夠節省頻繁創建、關閉的開銷,提升響應速度,方便管理,常應用於線程池、連接池等
Executor框架將工作任務與執行(線程池)解耦分離,工作任務分為無返回值的Runnable和有返回值的Callable
Executor實際只處理Runnable任務,會將Callable任務封裝成FutureTask適配Runnable執行
線程池使用工作隊列來管理線程,線程執行完任務會從阻塞隊列取任務執行,當非核心線程空閑一定時間後會被關閉
線程池執行時,如果工作隊列線程數量小於核心線程數,則創建線程來執行(相當預熱)
如果工作隊列線程數量大於核心線程數量,並且阻塞隊列未滿則放入阻塞隊列
如果阻塞隊列已滿,還未達到最大線程數量則創建非核心線程執行任務
如果已達到最大線程數量則使用拒絕策略
配置參數CPU密集型為CPU核數+1;IO密集型為2倍CPU核數;具體配置需要測試
處理異常可以直接捕獲任務,Callable可以捕獲get,也可以繼承線程池實現afterExecutor記錄異常,還可以在創建線程時就設置處理未捕獲異常方法
處理定時任務的線程池由延遲隊列實現,時間越短的定時任務越先執行,線程會從延遲隊列中獲取定時任務(時間已到的情況),時間未到就等待
最後(不要白嫖,一鍵三連求求拉~)
本篇文章被收入專欄 由點到線,由線到面,深入淺出構建Java併發編程知識體系,感興趣的同學可以持續關註喔
本篇文章筆記以及案例被收入 gitee-StudyJava、 github-StudyJava 感興趣的同學可以stat下持續關註喔~
案例地址:
Gitee-JavaConcurrentProgramming/src/main/java/D_ThreadPool
Github-JavaConcurrentProgramming/src/main/java/D_ThreadPool
有什麼問題可以在評論區交流,如果覺得菜菜寫的不錯,可以點贊、關註、收藏支持一下~
關註菜菜,分享更多乾貨,公眾號:菜菜的後端私房菜
本文由博客一文多發平臺 OpenWrite 發佈!


