
# pentaho使用 先展示一下用途和效果  ## 1. 環境準備 ### 1.1 pentaho是什麼? > `pentah ...
pentaho使用
先展示一下用途和效果

1. 環境準備
1.1 pentaho是什麼?
pentaho可讀作“彭塔湖”,原名keetle在keetle被pentaho公司收購後改名而來。
pentaho是一款開源ETL工具,純java編寫的C/S模式的工具,可綠色免安裝,開箱即用。支持Windows、macOS、Linux平臺。
pentaho有2個核心設計,即轉換和作業。
轉換是一個包含輸入、邏輯處理、輸出的完整過程,即ETL。
作業是一個提供定時執行轉換的機制,即定時服務調度。
pentaho官網下載鏈接:Pentaho Community Edition Download | Hitachi Vantara
pentaho由主要四部分組成
- Spoon.bat/Spoon.sh :勺子,是一個圖形化界面,可圖形化操作轉換和作業
- Pan.bat/Pan.sh : 煎鍋,可用命令行方式調用轉換
- Kitchen.bat/Kitchen.sh : 廚房,可用命令行方式調用作業
- Carte.bat/Carte.sh : 菜單,是一個輕量級web容器,可建立專用、遠程的ETL Server
1.2 pentaho安裝
Windows
由於是純java編寫,依賴jdk環境。所以需要先配置jdk環境,這裡省略。
從官網下載pentaho安裝包後,直接解壓。
MacOS
tar -zxvf 安裝包路徑 -C 目標路徑
Linux
tar -zxvf 安裝包路徑 -C 目標路徑
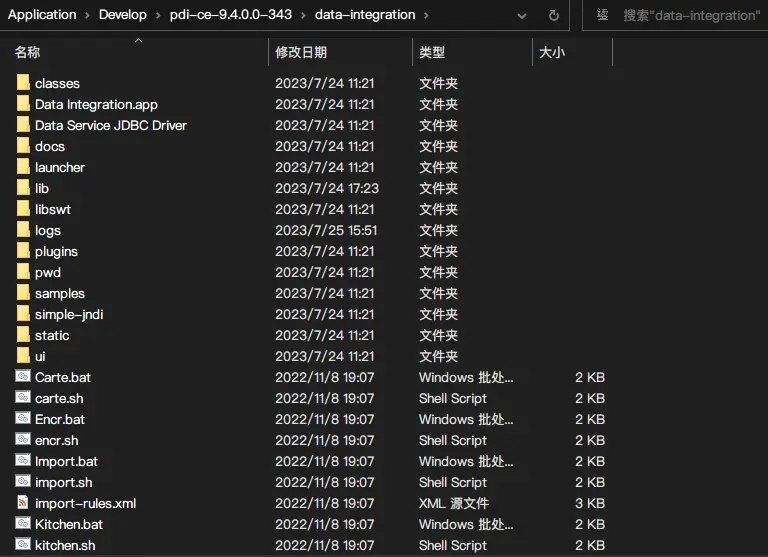
目錄結構
重點目錄以及執行文件說明
- lib目錄 : 這是依賴庫目錄,例如各個資料庫的jdbc驅動,都放在此目錄下
- logs目錄 :這是轉換和作業運行的預設日誌輸出目錄
- simple-jndi目錄 :這是各個資料庫的JNDI連接信息的全局配置
- Spoon.bat/Spoon.sh :勺子,是一個圖形化界面,可圖形化操作轉換和作業
- Pan.bat/Pan.sh : 煎鍋,可用命令行方式調用轉換
- Kitchen.bat/Kitchen.sh : 廚房,可用命令行方式調用作業
- Carte.bat/Carte.sh : 菜單,是一個輕量級web容器,可建立專用、遠程的ETL Server
在window上運行就用
.bat格式腳本,MacOS 或者 Linux 平臺上使用.sh格式腳本
2. 開始使用
pentaho內置了豐富的數據處理組件,本章節主要對pentaho界面上各個功能組件作用進行說明。
2.1 啟動圖形化界面
Windows
運行 Spoon.bat
MacOS
運行 Spoon.sh
Linux
運行 Spoon.sh
運行後會短暫沒有任何反應,等待會議,就會出現界面

主對象樹中有轉換和作業
- 轉換:所有的數據處理工作都在轉換中完成
- 作業:這是一個任務
開始數據處理工作前,必需新建一個轉換,因為只有新建了之後,才能使用數據處理組件,此時的核心對象樹是空的。
2.2 轉換
在 “核心對象樹 –> 轉換 –> 右鍵 –> 新建” 或 在 “文件 –> 新建 –> 轉換” ,新建一個轉換,核心對象樹就會出現各類組件。依靠這些組件組合使用,完成數據處理工作。

2.2.1 主對象樹
一個轉換就是一個數據處理工作流程。這裡主要是轉換的配置,例如數據源連接,運行配置等。

2.2.2 核心對象樹
包含各類數據處理組件。
2.3 數據處理組件
這裡對一些常用的組件進行說明
輸入
輸入組件,即各類數據源,例如資料庫,json,xml等
輸出
輸出組件,將處理後的數據進行輸出保存
轉換
這是數據轉換的核心,在這裡完成數據處理
應用
包含一些數據處理外的操作,例如發送郵件,寫日誌等
流程
用於控制數據處理流程,例如開始,結束,終止等
腳本
當內置轉換組件完成不了數據處理的邏輯時,即可使用腳本組件,用自定義代碼的方式來完成處理邏輯
查詢
用於一些查詢請求,例如http請求,資料庫查詢某個表是否存在等
連接
可用於多表,單表處理完後,進行記錄合併
2.4 作業組件
在“文件–>新建–>作業”創建一個作業。
主對象樹包含作業運行配置,DB連接配置等

核心對象樹包含作業的各類組件

通用
作業流程組件,有開始、轉換、成功、空處理等
郵件
發送郵件
文件管理
文件操作,創建、刪除等
條件
條件處理,例如判斷某個文件是否存在
腳本
使用shell,js、sql等腳本處理複雜作業邏輯
應用
作業處理,例如終止作業、寫日誌等
文件傳輸
定時作業來上傳、下載文件
2.5 使用
上面介紹了各個組件用途,現在來完成一個完整的數據處理工作流程。
啟動應用
略
新建轉換
在 “核心對象樹 –> 轉換 –> 右鍵 –> 新建” 或 在 “文件 –> 新建 –> 轉換” ,新建一個轉換
配置DB連接
在主對象樹中選擇DB連接,右鍵新建

註意:連接資料庫之前需要下載對應的
jdbc驅動,例如連接pgsql則需要下載postgresql-version.jar,r然後將驅動包放到安裝目錄下的\lib目錄
這裡以kingbase V8為例,因為這個踩了坑。經歷如下:
內置的數據源里有KingbaseES,本以為可以直接用,結果發現連不上,報驅動錯誤。可能是因為內置的驅動版本跟資料庫版本不一致,因為Kingbase V8的驅動不向前相容。更新驅動後,依然不行。
然後發現,內置還有Generic database選項,這個是用來自定義連接內置數據源之外的資料庫的。使用jdbc方式連接,需要一個連接串,驅動包名(前提是下載了對應的驅動包),用戶名,密碼。然而,這種方式依然不行……
後來一想,乾脆用pgsql的方式來連接kingbase,沒想到連接成功!

選擇輸入
因為數據源是資料庫,所以這裡從輸入組件中選擇表輸入,將其拖入到右側面板中

配置輸入
雙擊“表輸入”組件 或 右鍵選擇 “編輯步驟”

點擊獲取SQL查詢語句,會彈出界面選擇數據表

選擇一個數據表後,提示

選擇“是”

這裡會自動填充獲取數據的sql,也可以在這裡加上各種where條件,獲取需要的數據
點擊“確定”

配置輸出
如果是表結構一致,則可使用
因為目標數據源也是資料庫,所以這裡選擇表輸出。從輸出組件選擇表輸出,拖入轉換視圖中

然後進行步驟連接。
方式一:按住shift鍵,滑鼠左鍵點選“輸入步驟”,會出現箭頭,然後連接到“輸出步驟”
方式二:滑鼠左鍵框選輸入和輸出,然後右鍵,選擇”新建節點連接“,選擇”起始步驟“,”目標步驟“

點擊“確定”
連接後如下:

雙擊“表輸出”或右鍵選擇“編輯步驟”

選擇目標資料庫中的數據表,然後點擊”確定“
選擇表輸出,無法配置欄位映射,所以前提是表結構一致才可使用。如果是異構表,需要欄位映射的,則需要使用 插入/更新 組件
如果輸入表和輸出表結構不一致,即異構表,則需要使用插入/更新組件。從輸出中選擇插入/更新拖入轉換視圖中,然後進行步驟連接,進入輸出配置

註意:一定要正確連接步驟,否則這步無法獲取輸入欄位,輸出欄位
欄位映射配置好後如下

點擊“確定”

或

然後點擊轉換視圖中的 按鈕,這個是運行
按鈕,這個是運行

這個運行是運行一次,完成後就結束了。如果要定時運行,則需要
作業。
點擊“啟動” 會彈出界面 保存 當前轉換

輸入保存的文件名稱,然後點擊“Save”即可

每個步驟都顯示綠色的箭頭,說明沒有錯誤,正確的執行完了轉換。也可以在日誌輸出查看.
日誌:完成處理 (I=1, O=1, R=1, W=1, U=0, E=0)中的 I=1 表示 輸入 1 行,O=1表示 輸出 1 行,R=1 表示 讀取 1 行,W=1 表示 寫入 1 行
然後看一下數據輸出結果
源表

目標表

定時作業
如果需要定時執行同步過程,那麼就需要引入作業。在“文件–>新建–>作業” 創建一個作業。
在“通用”中選擇Start拖入作業視圖中

然後選擇轉換拖入視圖,併進行步驟連接。

雙擊“轉換”或右鍵選擇“編輯作業入口”

點擊“確定”
然後選成功組件拖入視圖,並連接步驟

雙擊視圖中的Start組件或右鍵”編輯作業入口“,進行作業調度配置

點擊運行視圖中的按鈕。一個定時作業即完成
定時作業調度期間,程式不能退出!程式退出,作業即停止
至此一個完整的數據處理作業完成了。
3. 案例
3.1 簡單同步
本部分對簡單同步進行說明。簡單同步是指不涉及複雜計算、轉換等同步工作。
3.1.1 單表
即一對一同步,A表數據同步到B表,A與B的欄位數量、類型、名稱可能都不一樣,因此需要一些欄位類型轉換,這都很容易。
處理過程詳見2.5章節
3.1.2 多表
即2個及以上的表往一個表同步,同樣也需要欄位映射、類型轉換等操作。
外鍵關聯
這種通過某個欄位(外鍵)關聯的表,處理思路是在獲取數據時,通過sql聯表查詢,獲取到全部需要的數據。然後用單表同步方式進行處理。
多表合併
如果是異構表的話,獲取到每個數據源後,使用Multiway merge join多路合併組件處理


合併後的記錄可作為一個單表,然後進行單表同步的處理
合併是笛卡爾積,即A表n條記錄,B表n條記錄,結果就是n x n條記錄,欄位是A、B表全部欄位,這種方式不建議採用,會消耗更多記憶體資源。建議拆分成單表同步
如果是同構表的話,可拆分為多個單表同步處理。
3.2 複雜同步
本部分對涉及到數據計算、轉換的同步工作進行說明。有些複雜操作,無法直接使用組件進行處理,需要用到Script組件。這裡主要對如何使用腳本組件完成數據處理進行說明。
這裡先展示一個實際案例

這個過程是多表同步到一個表、涉及到欄位類型轉換、補充欄位和值、數據計算、增補數據。由於計算和增補數據使用內置組件無法完成,因此這裡使用了java腳本組件,自定義代碼進行數據處理。
這裡對欄位類型轉換、增加列、給某列設置值、java腳本進行說明。
欄位類型轉換
例如 數字類型 轉為 字元串,字元串 轉為 日期時間……
從轉換中選擇欄位選擇組件

雙擊“欄位選擇”或右鍵選擇“編輯步驟”

選擇“元數據”,在“欄位名稱”列選擇欄位,然後在“類型”列選擇目標類型

增加列並設置隨機數
在輸入中找到生成隨機數組件,拖入視圖並連接步驟

雙擊生成隨機數或右鍵選擇“編輯步驟”

在“名稱”列輸入需要增加的欄位名,類型選擇生成隨機數規則

點擊“確定”後,運行轉換,在preview data處可預覽數據,可以看到增加了一列 uid 也有值

將列的值設置為常量
例如將上面隨機數組件生成的值設置為常量1。在轉換中選擇將欄位設置為常量組件,並連接步驟

雙擊“將欄位設置為常量”或右鍵選擇“編輯步驟”

在“欄位”列選擇需要設置的欄位,這裡選擇上一步驟生成的“uid”欄位,在“值替換”列輸入值。
點擊“確定”,運行轉換,然後預覽數據,可以看到uid的值被替換為1

java腳本
腳本有Java腳本、JavaScript腳本,SQL腳本等。這裡使用Java腳本,腳本的目的是處理內置組件處理不了的邏輯。例如有10個地層,但是數據源中只記錄了前9個地層,最後一個需要根據計算得到。
拖入Java腳本組件到轉換視圖中並連接步驟

雙擊“Java腳本”或右鍵選擇“編輯步驟”

然後展開Code Snippits\Common use

選擇Main拖入右側編輯區,Main是整個腳本處理入口

其預設腳本結構如下
public boolean processRow(StepMetaInterface smi, StepDataInterface sdi) throws KettleException {
if (first) {
first = false;
// 代碼邏輯區域
/* TODO: Your code here. (Using info fields)
FieldHelper infoField = get(Fields.Info, "info_field_name");
RowSet infoStream = findInfoRowSet("info_stream_tag");
Object[] infoRow = null;
int infoRowCount = 0;
// Read all rows from info step before calling getRow() method, which returns first row from any
// input rowset. As rowMeta for info and input steps varies getRow() can lead to errors.
while((infoRow = getRowFrom(infoStream)) != null){
// do something with info data
infoRowCount++;
}
*/
}
Object[] r = getRow();
if (r == null) {
setOutputDone();
return false;
}
// It is always safest to call createOutputRow() to ensure that your output row's Object[] is large
// enough to handle any new fields you are creating in this step.
r = createOutputRow(r, data.outputRowMeta.size());
/* TODO: Your code here. (See Sample)
// Get the value from an input field
String foobar = get(Fields.In, "a_fieldname").getString(r);
foobar += "bar";
// Set a value in a new output field
get(Fields.Out, "output_fieldname").setValue(r, foobar);
*/
// Send the row on to the next step.
putRow(data.outputRowMeta, r);
return true;
}
TODO區域就是代碼編輯區域,其它是預設腳本函數
點擊”確定“,然後再次打開Java腳本,就能看到輸入輸出欄位信息了

完整實現地層計算並補充最後一層的Java腳本代碼邏輯如下
// 這裡是需要用的 java API 所導入的包
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.lang.*;
import java.math.BigDecimal;
import java.util.*;
// 核心處理過程入口
public boolean processRow(StepMetaInterface smi, StepDataInterface sdi) throws KettleException {
if (first) {
first = false;
logBasic("----------------------欄位-------------------------");
String projectCount = "project_count";
String knumber = "knumber";
String depth = "depth";
String dep = "dep";
String layerorder = "layerorder";
String id = "id";
logBasic("----------------------獲取輸入流-------------------------");
// 輸入數據流 input 是消息步驟中設置的標簽名
RowSet infoStream = findInfoRowSet("input");
Object[] infoRow = null;
int infoRowCount = 0;
logBasic("----------------------遍曆數據流,將其載入到map-------------------------");
// 遍曆數據流,將其載入到map,便於操作
// 根據 項目索引+鑽孔索引 分組
Map<String, ArrayList<Object[]>> groups = new HashMap<String, ArrayList<Object[]>>();
while((infoRow = getRowFrom(infoStream)) != null){
// 獲取欄位值
String prjCode = get(TransformClassBase.Fields.In, projectCount).getString(infoRow);
String drillCode = get(TransformClassBase.Fields.In, knumber).getString(infoRow);
String groupKey = prjCode + drillCode;
if (!groups.containsKey(groupKey)) {
logBasic("----------------------創建分組-------------------------");
groups.put(groupKey,new ArrayList<Object[]>());
}
logBasic("----------------------添加數據到分組-------------------------");
ArrayList<Object[]> objects = (ArrayList<Object[]>)groups.get(groupKey);
objects.add(infoRow);
logBasic("----------------------添加數據到輸出流-------------------------");
// 將當前行拷貝一份
Object[] row=infoRow;
// 創建一個輸出行
row = createOutputRow(infoRow, data.outputRowMeta.size());
//putRow(infoStream.getRowMeta(), row);
// 將輸出行添加到輸出數據集
putRow(data.outputRowMeta, row);
infoRowCount++;
}
logBasic("----------------------分組完成,處理最後一條數據-------------------------");
// 將最後一條數據拷貝一份,場地分層索引+1,層底深度dep 賦值為 鑽孔深度 depth,然後將此行數數據添加
Object[] keys = groups.keySet().toArray();
for (int i = 0; i < keys.length; i++) {
String s = keys[i].toString();
logBasic("----------------------當前分組-----------------------:"+ s);
ArrayList<Object[]> list = (ArrayList<Object[]>) groups.get(s);
Object[] last = (Object[])list.get(list.size() - 1);
Object[] newLast=last;
// 設置 layerorder 的值
String layerorderVal = get(TransformClassBase.Fields.In, layerorder).getString(last);
BigDecimal v = new BigDecimal(layerorderVal);
v = v.add(new BigDecimal(1));
get(TransformClassBase.Fields.Out, layerorder).setValue(newLast, v);
// 設置 dep 的值
String layerDepVal = get(TransformClassBase.Fields.In, depth).getString(last);
BigDecimal v2 = new BigDecimal(layerDepVal);
get(TransformClassBase.Fields.Out, dep).setValue(newLast, v2);
// 設置id
String idVal = UUID.randomUUID().toString();
get(TransformClassBase.Fields.Out, id).setValue(newLast, idVal);
logBasic("----------------------添加數據到輸出流-------------------------");
newLast=createOutputRow(newLast, data.outputRowMeta.size());
// 將新的一行數據添加到輸出數據集
putRow(data.outputRowMeta, newLast);
}
/* TODO: Your code here. (Using info fields)
FieldHelper infoField = get(Fields.Info, "info_field_name");
RowSet infoStream = findInfoRowSet("info_stream_tag");
Object[] infoRow = null;
int infoRowCount = 0;
// Read all rows from info step before calling getRow() method, which returns first row from any
// input rowset. As rowMeta for info and input steps varies getRow() can lead to errors.
while((infoRow = getRowFrom(infoStream)) != null){
// do something with info data
infoRowCount++;
}
*/
}
Object[] r = getRow();
logBasic("----------------------getRow-----------------------:"+ r);
if (r == null) {
setOutputDone();
return false;
}
// It is always safest to call createOutputRow() to ensure that your output row's Object[] is large
// enough to handle any new fields you are creating in this step.
r = createOutputRow(r, data.outputRowMeta.size());
logBasic("----------------------createOutputRow-----------------------:"+ r);
/* TODO: Your code here. (See Sample)
// Get the value from an input field
String foobar = get(Fields.In, "a_fieldname").getString(r);
foobar += "bar";
// Set a value in a new output field
get(Fields.Out, "output_fieldname").setValue(r, foobar);
*/
// Send the row on to the next step.
putRow(data.outputRowMeta, r);
return true;
}
至此 Java腳本處理完成。
痛(坑)點總結:
1.腳本編輯區是個文本編輯框,不能像IDEA一樣幫助寫代碼,只能通過日誌進行輸出驗證邏輯
2.建議通用的不涉及pentaho的java代碼操作,可以在IDEA中完成,然後拷貝到腳本編輯區。例如需要導入的包就是在IDEA中通過智能導入,然後拷貝的
驗證一下數據,圖中標記的行,就是根據前2行數據計算而來,然後進行補充的。在數據源中只記錄了前2行數據。

本文來自博客園,作者:宣君{https://www.nhit.icu/},轉載請註明原文鏈接:https://www.cnblogs.com/ycit/p/17687558.html


