
本文給大家介紹了什麼是"編程範式",選擇合適的編程範式可以提高代碼的可讀性、可維護性和可擴展性。 一、 什麼是編程範式? "編程範式"是一種編程思想的總稱,它是指在編寫程式時所採用的基本方法和規範。常見的編程範式有面向對象、函數式、邏輯式等。 選擇合適的編程範式可以提高代碼的可讀性、可維護性和可擴展 ...
5 設計一致哈希(HASHING)
要實現橫向擴展,就必須在伺服器之間高效、均勻地分配請求/數據。一致哈希是實現這一目標的常用技術。不過,首先讓我們深入瞭解一下這個問題。
5.1 重散列(rehashing)問題
如果有n台緩存伺服器,平衡負載的常用方法是使用下麵的散列方法:
serverIndex = hash(key)%N,其中N是伺服器池的大小。

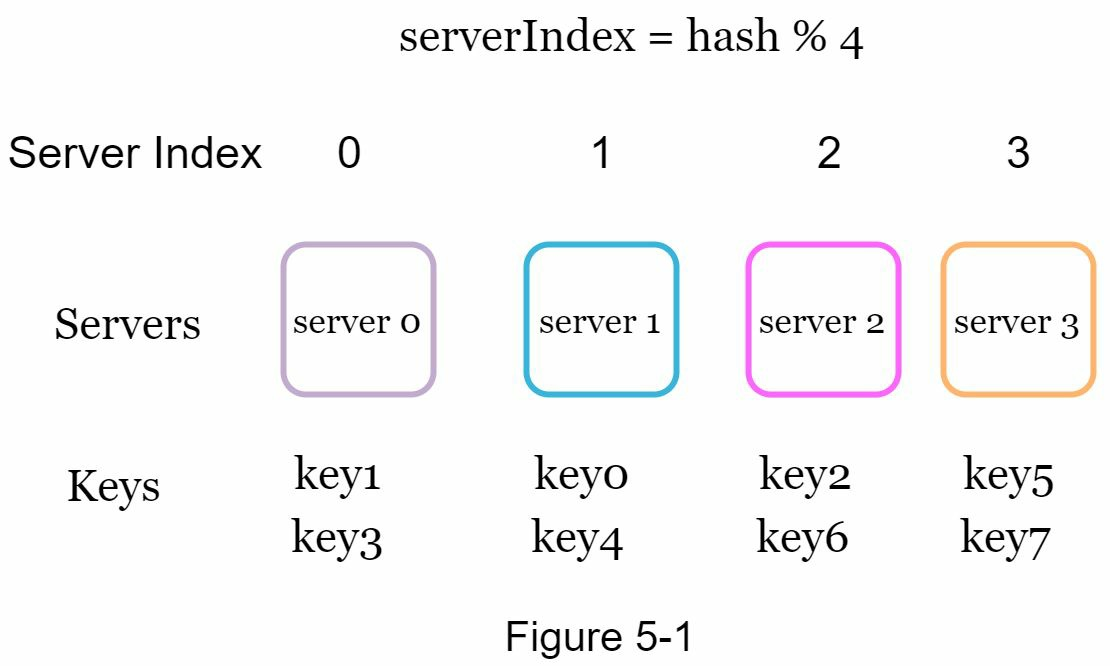
當伺服器池的大小固定且數據分佈均勻時,這種方法效果很好。但是,當添加新伺服器或移除現有伺服器時,問題就會出現。例如,如果伺服器1離線,伺服器池的大小就會變成3。這意味著當伺服器1離線時,大多數緩存客戶端會連接到錯誤的伺服器來獲取數據。這將導致緩存丟失風暴。一致性散列是緩解這一問題的有效技術。
5.2 一致散列(Consistent hashing)
引自維基百科:"一致散列是一種特殊的散列方式,當重新調整哈希表大小並使用一致散列時,平均只需重新映射 k/n 個鍵,其中k是鍵的個數,n是槽的個數。相比之下,在大多數傳統哈希表中,數組槽數的變化會導致幾乎所有的鍵都要重新映射"。
5.3 散列空間和散列環
既然我們已經理解了一致散列的定義,那就讓我們來看看它是如何工作的。假設使用SHA-1作為散列函數f,散列函數的輸出範圍為:x0, x1, x2, x3, ..., xn。在密碼學中,SHA-1 的散列空間從 0 到 2^160 - 1。也就是說,x0 對應 0,xn 對應 2^160 - 1,中間的所有其他散列值都在 0 和 2^160 - 1 之間。
5.4 散列伺服器
使用相同的哈希函數f,我們根據伺服器IP或名稱將伺服器映射到哈希環上。

5.5 散列鍵
值得一提的是,這裡使用的哈希函數與 "重洗問題 "中的哈希函數不同,沒有模塊化操作。
5.6 伺服器查詢
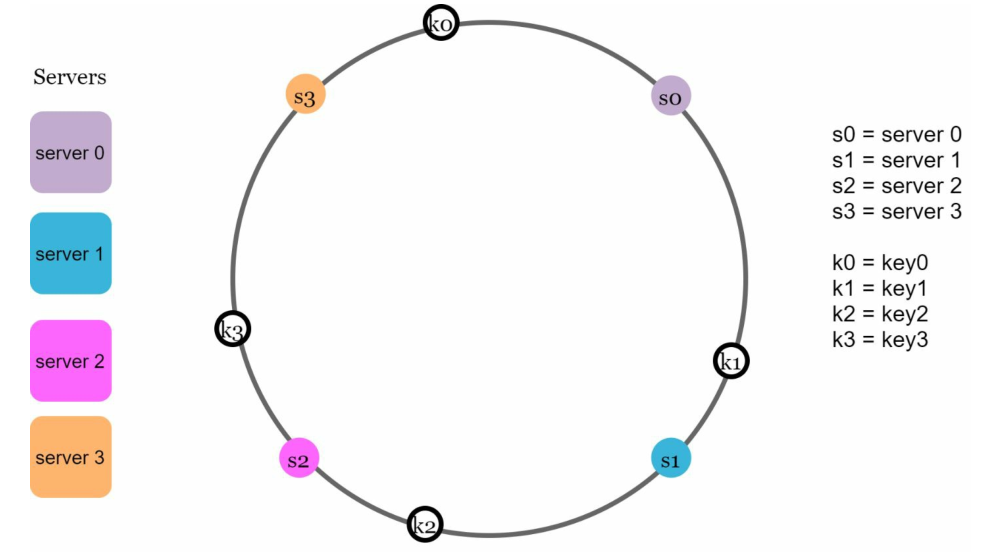
要確定密鑰存儲在哪個伺服器上,我們要從密鑰在哈希環上的位置開始順時針查找,直到找到伺服器為止。下圖解釋了這一過程。按順時針方向,0存放在伺服器0上;1存放在伺服器1上;2存放在伺服器2上;3存放在伺服器3上。

5.7 添加伺服器
使用上述邏輯,添加新伺服器只需重新分配一部分密鑰。
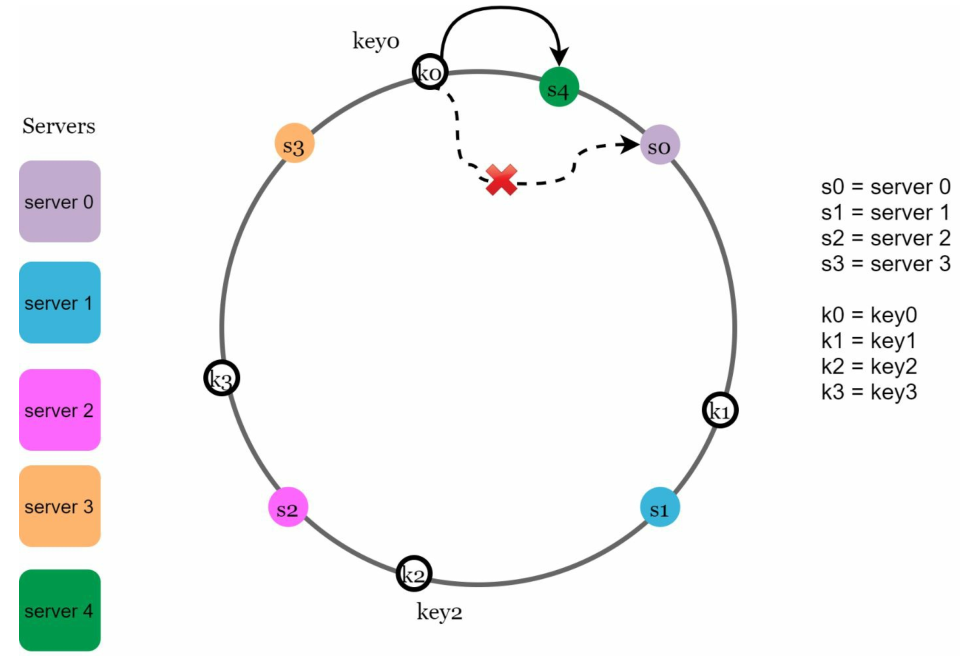
添加新伺服器 4後,只需重新分配0,而 k1、k2 和 k3 仍保存在相同的伺服器上。讓我們仔細看看其中的邏輯。在伺服器4添加之前,0保存在伺服器0上。現在,密鑰0將被保存在伺服器4上,因為伺服器4是它從密鑰0在環上的位置順時針旋轉遇到的第一個伺服器。其他Key不會根據一致的哈希演算法重新分配。
5.8 移除伺服器
移除伺服器時,只有一小部分Key需要使用一致散列演算法重新分配。下圖中,當伺服器1被移除時,只有key1必須重新映射到伺服器2。其餘的密鑰不受影響。

5.9 基本方法中的兩個問題
一致散列演算法是由麻省理工學院的Karger等人提出的。基本步驟如下
-
使用均勻分佈的散列函數將伺服器和密鑰映射到環上。
-
要找出密鑰映射到哪個伺服器上,就從密鑰位置開始順時針查找,直到找到環上的第一個伺服器為止。
這種方法存在兩個問題。首先,考慮到伺服器可以添加或刪除,環上所有伺服器的分區大小不可能保持一致。分區是相鄰伺服器之間的散列空間。分配給每個伺服器的環上分區的大小有可能非常小,也有可能相當大。下圖如果刪除 s1,s2 的分區(雙向箭頭突出顯示)將是 s0 和 s3 分區的兩倍。

其次,環上有可能出現密鑰分佈不均勻的情況。例如,如果將伺服器映射到下圖所列的位置,則大部分密鑰都存儲在伺服器 2 上。然而,伺服器 1 和伺服器 3 卻沒有數據。

一種稱為虛擬節點或副本的技術可用於解決這些問題。
參考資料
- 軟體測試精品書籍文檔下載持續更新 https://github.com/china-testing/python-testing-examples 請點贊,謝謝!
- 本文涉及的python測試開發庫 謝謝點贊! https://github.com/china-testing/python_cn_resouce
- python精品書籍下載 https://github.com/china-testing/python_cn_resouce/blob/main/python_good_books.md
- Linux精品書籍下載 https://www.cnblogs.com/testing-/p/17438558.html
- 一致散列:https://en.wikipedia.org/wiki/Consistent_hashing
- 一致散列:
https://tom-e-white.com/2007/11/consistent-hashing.html - Dynamo: 亞馬遜的高可用鍵值存儲:
https://www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pdf - Cassandra - 一種分散的結構化存儲系統:
http://www.cs.cornell.edu/Projects/ladis2009/papers/Lakshman-ladis2009.PDF - Discord 如何將 Elixir 擴展到 5,000,000 併發用戶:
https://blog.discord.com/scaling-elixir-f9b8e1e7c29b - CS168: 現代演算法工具箱講座 #1:導論和一致性
哈希演算法:http://theory.stanford.edu/~tim/s16/l/l1.pdf - Maglev: A Fast and Reliable Software Network Load Balancer:
https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/44824.pdf
5.10 虛擬節點
虛擬節點指的是真實節點,每個伺服器都由環上的多個虛擬節點表示。下圖中,伺服器 0 和伺服器 1 都有 3 個虛擬節點。3 是任意選擇的;而在實際系統中,虛擬節點的數量要大得多。我們不用 s0,而是用 s0_0、s0_1 和 s0_2 來表示環上的伺服器 0。同樣,s1_0、s1_1 和 s1_2 代表環上的伺服器 1。通過虛擬節點,每個伺服器負責多個分區。標簽為 s0 的分區(邊)由伺服器 0 管理,而標簽為 s1 的分區則由伺服器 1 管理。

要查找密鑰存儲在哪台伺服器上,我們可以從密鑰所在位置出發,順時針方向查找環上遇到的第一個虛擬節點。下圖,要找出 k0 存放在哪個伺服器上,我們從 k0 所在位置開始順時針方向查找虛擬節點 s1_1,它指的是伺服器 1。

隨著虛擬節點數量的增加,密鑰的分佈也變得更加均衡。這是因為虛擬節點越多,標準偏差就越小,從而導致數據分佈均衡。標準偏差衡量數據的分佈情況。線上研究[2]的實驗結果表明,在有一兩百個虛擬節點的情況下,標準偏差介於平均值的 5%(200 個虛擬節點)和 10%(100 個虛擬節點)之間。當我們增加虛擬節點的數量時,標準偏差會更小。但是,需要更多空間來存儲虛擬節點的數據。這是一個權衡問題,我們可以根據系統要求調整虛擬節點的數量。
5.11 找受影響的鍵
添加或刪除伺服器時,需要重新分配一部分數據。我們如何找到受影響的範圍來重新分配密鑰呢?
下圖中,伺服器 4 被添加到環上。受影響的範圍從 s4(新添加的節點)開始,圍繞環逆時針移動,直到找到一個伺服器(s3)。因此,位於 s3 和 s4 之間的密鑰需要重新分配到 s4。

下圖當伺服器(s1)被移除時,受影響的範圍從 s1(被移除的節點)開始,圍繞環路逆時針移動,直到找到伺服器(s0)為止。因此,位於 s0 和 s1 之間的密鑰必須重新分配到 s2。

5.12 總結
在本章中,我們深入討論了一致散列,包括為什麼需要一致散列以及一致散列的工作原理。一致散列的好處包括
- 當伺服器添加或刪除時,最小化的密鑰會重新分配。
- 由於數據分佈更均勻,因此易於橫向擴展。
- 緩解熱點密鑰問題。對特定分片的過度訪問可能會導致伺服器過載。想象一下,凱蒂-佩里、賈斯汀-比伯和 Lady Gaga 的數據最終都在同一個分片上。一致散列法通過更均勻地分配數據,有助於緩解這一問題。
一致散列在現實世界的系統中得到了廣泛應用,其中包括一些著名的系統:
- 亞馬遜Dynamo資料庫的分區組件。
- Apache Cassandra 中跨集群的數據分區。
- Discord 聊天應用程式
- Akamai 內容交付網路
- Maglev 網路負載平衡器


