
本文分享自華為雲社區《GaussDB AP是如何執行SQL的》,作者:yd_270088468。 前言 介紹GaussDB AP各組件是如何協調工作的,會著重介紹SQL引擎。 1、SQL引擎組件和SQL生命周期 Parser: 詞法/語法分析模塊。詞法分析會從SQL字元串中解析出一個個單詞,作為語法 ...
本文分享自華為雲社區《GaussDB AP是如何執行SQL的》,作者:yd_270088468。
前言
介紹GaussDB AP各組件是如何協調工作的,會著重介紹SQL引擎。
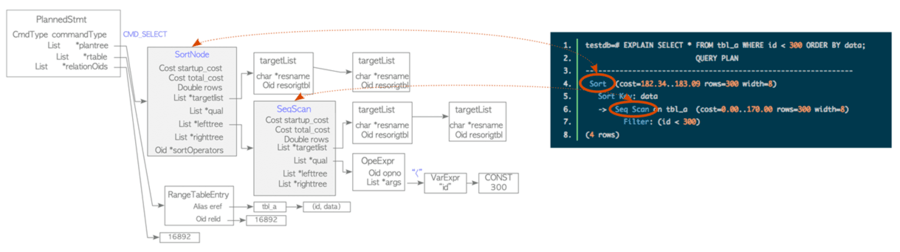
1、SQL引擎組件和SQL生命周期
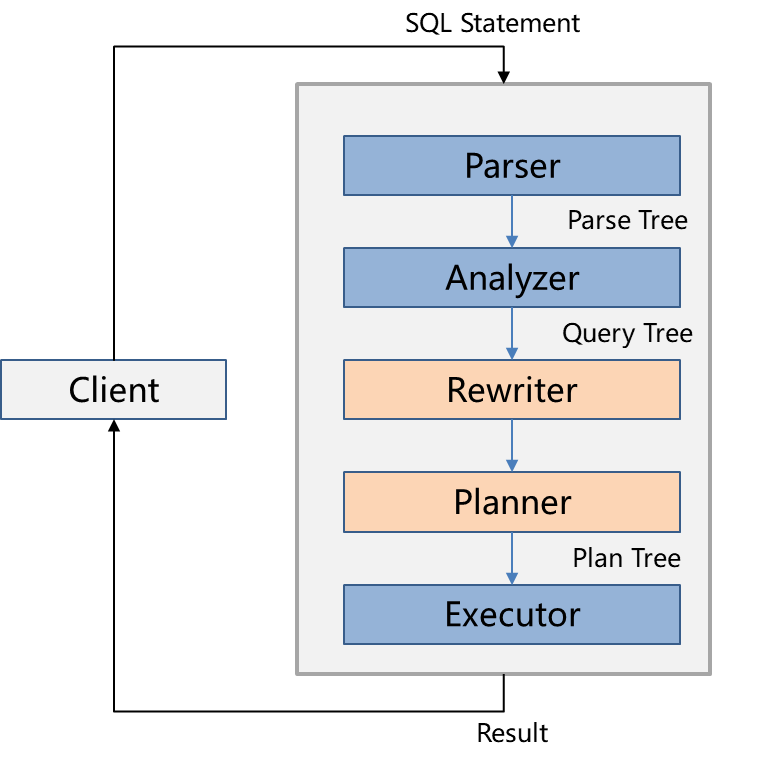
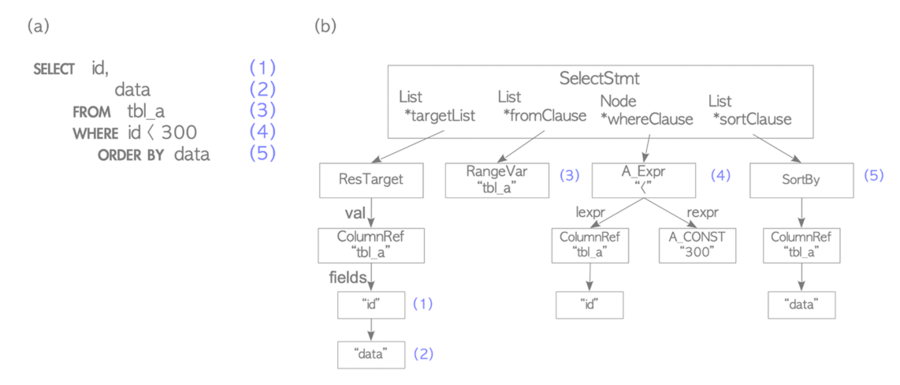
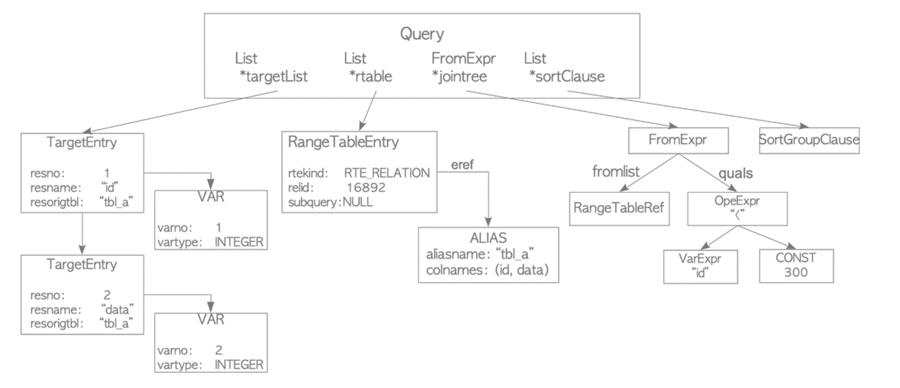
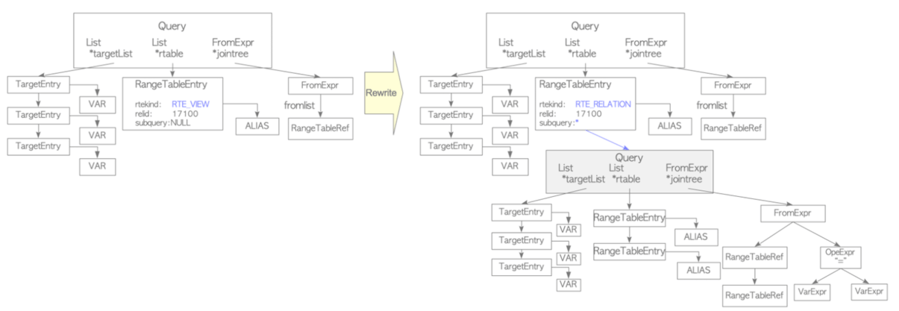
2、SQL執行整體架構
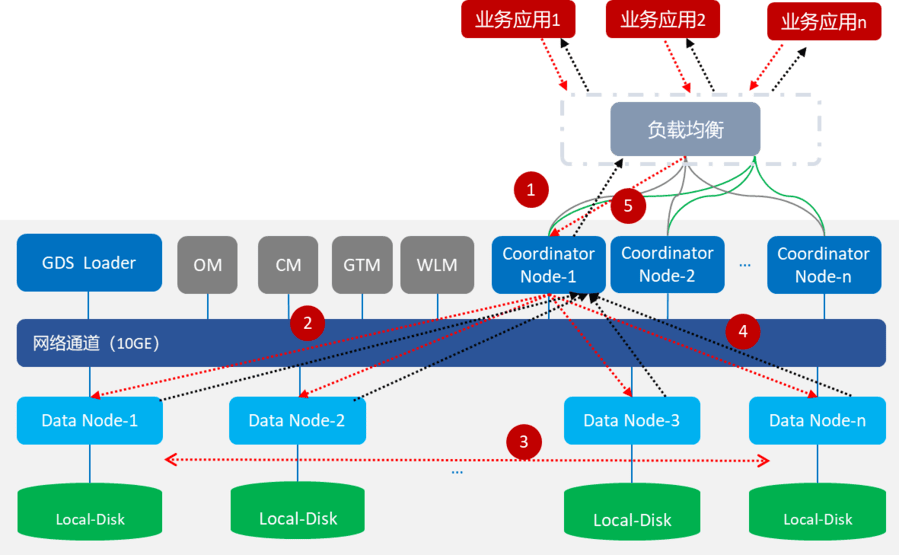
步驟一:業務通過ELB下發SQL給CN,SQL可以是DDL,DML,DCL。
步驟二:CN判斷SQL類型,如果SQL類型是DDL/DCL,不用生成plan,將SQL發送到其他CN和所有DN,在所有CN/DN上執行。如果SQL類型是DML,對於不需要使用stream運算元的(可以分成3小類),會將SQL直接發給各DN執行,對於需要使用stream運算元的,會生成plan下發給DN執行。
步驟三:DN執行DML過程中,可能會從其他DN獲取數據,DWS提供了三種stream運算元(Redistribute/Broadcast/Gather),降低數據在DN節點間的流動。
步驟四:DN將結果集返回給CN進行彙總。
步驟五:CN將彙總後的結果返回給業務。
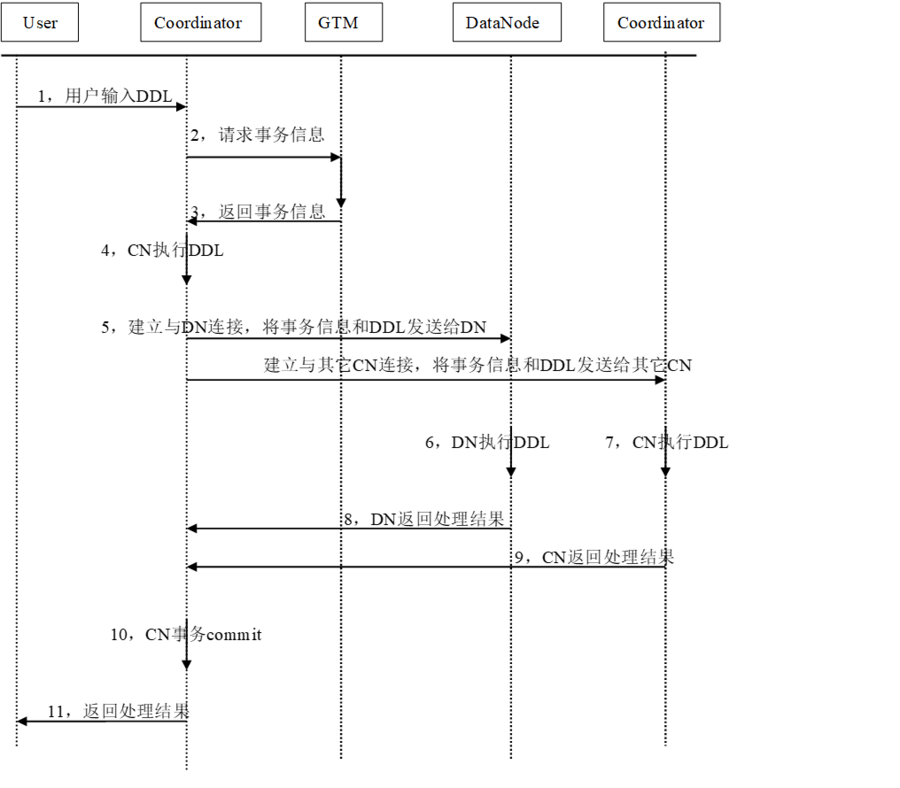
3、DDL在CN/DN如何交互
3.1 單DDL的情況
3.2 併發DDL的情況
為了避免併發DDL造成死鎖,預設開啟enable_parallel_ddl,控制從所有CN下發的DDL都使用同一個CN作為起點開始執行。
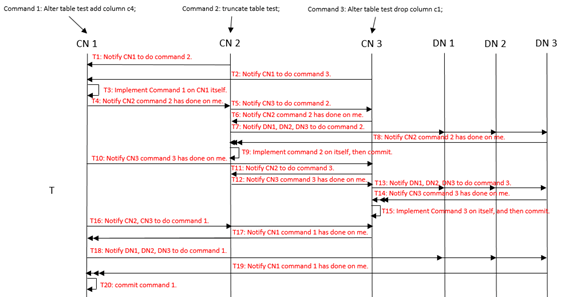
消息序列圖說明
前提:CN 1,CN 2,CN 3上各收到一條對錶test進行DDL操作的請求。CN 1為被選定的第一個執行DDL的節點。
T1:CN 2不是第一個執行DDL操作的節點,所以CN 2將Command 2命令發送給第一個執行的節點CN 1,然後等待CN 1回覆;
T2:CN 3也不是第一個執行DDL操作的節點,所以CN 3將Command 3命令發送給第一個執行的節點CN 1,然後等待CN1回覆;
T3:CN 1是第一個執行DDL操作的節點,故按基線原有邏輯執行,即先在本地執行;
T4:CN 1執行Command 2,對錶test拿鎖。Command 2執行完成後,CN 1告知CN2:Command 2在我上面已經完成。此時,Command 1和Command 3拿不到鎖,處於等待狀態。
T5:CN 2收到CN 1的Command 2執行完畢的回覆之後,給CN 3發送command 2命令,等待CN 3的回覆。
T6:CN 3執行command 2,回覆執行結果給CN 2;
T7:CN 2將command 2發送給DN1,DN2,DN3,要求它們在本地執行並等待他們的回覆;
T8:DN1,DN2,DN3分別在本地執行Command 2,回覆CN 2執行結果;
T9:CN 2本地執行Command 2,成功後提交,至此集群中所有的CN和DN全部放鎖,Command 2執行完畢。
T10:CN 1執行Command 3,對錶test拿鎖。Command 3執行完成後,CN 1告知CN3:Command 3在我上面已經完成。此時,Command 1拿不到鎖,處於等待狀態。
T11:CN 3收到CN 1的Command 3執行完畢的回覆之後,給CN 2發送command 3命令,等待CN 2的回覆。
T12:CN 2執行command 3,回覆執行結果給CN 3;
T13:CN 3將command 3發送給DN1,DN2,DN3,要求它們在本地執行並等待他們的回覆;
T14:DN1,DN2,DN3分別在本地執行Command 3,回覆CN 3執行結果;
T15:CN 3本地執行Command 3,成功後提交,至此集群中所有的CN和DN全部放鎖,Command 3執行完畢。
T16:CN 1將Command 1發送給CN2,CN3,並等待他們的回覆;
T17:CN2,CN3分別在本地執行Command 1,回覆執行結果給CN 1;
T18:CN 1將command 1發送給DN1,DN2,DN3,要求它們在本地執行並等待他們的回覆;
T19:DN1,DN2,DN3分別在本地執行Command 1,回覆CN 1執行結果;
T20:CN 1本地執行Command 1,成功後提交,至此集群中所有的CN和DN全部放鎖,Command 3執行完畢。
從上面實現可以看到,其中心思想是將多CN上併發的DDL操作串列化,即指定一個最先執行的CN,所有的DDL都必須先在這個CN上執行完成後才可以在別的節點上執行。這樣的話,在這個被指定的CN上面,DDL操作就是串列的,拿不到鎖的DDL會等待,但不再會出現拿不到鎖的死鎖情況。
4、DML執行計劃生成
4.1 CBO模型
CBO: Cost-Based Optimization也即"基於代價的優化器",相對於RBO(Rule-Based Optimization),CBO對數據很敏感,執行計劃更靈活,當數據量變化的時候,CBO往往能生成更優的執行計劃。
CBO 的基本優化流程:搜索引擎利用轉換規則,對輸入的邏輯執行計划進行(邏輯/物理)轉換,構造出執行計劃的搜索空間。之後,利用代價模型對搜索空間中的每一個執行計划進行代價估算,選出代價最低的物理執行計劃。而代價估算的過程離不開基數估計:它利用各個表、列的統計信息,估算出各運算元的輸入行數、選擇率等信息,提供給運算元的代價模型,從而估算出查詢計劃的代價。
DWS優化器是基於代價的優化器(CBO),它可以為每一條SQL構造出搜索空間,並根據數據的統計信息、基數估計、運算元代價模型,為搜索空間中的執行機計劃估算出執行所需要的代價(CPU/MEM/IO/NET),最終選出代價最小的執行計劃作為SQL的具體執行方式。
4.2 搜索空間
採用Cascade(動態規劃)/GEQO(遺傳基因)的方式進行計劃搜索。通過Cascade演算法可以實現精確計算,但時間複雜度高,適用於表連接較少的情況。GEQO是非精確計算的方法,適用於表很多的情況。
4.3 統計信息
包括邏輯表的行數,列的非重覆值數(NDV),列Null值信息等。
4.4 基數估計
基數估計會估算各個運算元中間結果的行數或基數等信息,例如Join輸出行數,Agg會產生的Group數量等等。
4.5 運算元代價
對於同類運算元,將所有實現運算元的消耗(代價)均計算出來,選擇代價最小的。
輸入:兩個表的大小、Join列的數據特征、有序性、可用記憶體大小work_mem;
輸出:運算元的代價(消耗時間的維度)
4.6 分散式計劃
|
序號 |
分類 |
作用 |
執行原理 |
適用場景 |
|---|---|---|---|---|
|
1 |
CN下發語句 |
生成完全下推語句的計劃(FQS計劃) |
各DN分別根據下推語句生成執行計劃,進行執行,執行結果在CN上進行彙總(FQS,即Fast Query Shipping) |
各DN執行時無數據交互,像基表掃描的場景 |
|
2 |
CN下發語句 |
生成發送語句的分散式計劃(部分下推計劃) |
CN下推原語句的部分語句(通常為基表掃描)到DN,各DN分別根據下推語句生成執行計劃,執行後將結果發送給CN,CN執行剩餘計劃 |
不能滿足1,3,4的極端場景,性能非常差。目前不支持下推的特征主要有:record數據類型、volatile函數等 |
|
3 |
CN下發語句 |
生成CN輕量化的計劃 |
由DN生成執行計劃返回結果 |
只有單DN執行語句,且DN結果即為最終返回結果 |
|
4 |
CN生成計劃 |
生成下發Plan的分散式計劃(Stream計劃) |
CN根據原語句生成計劃,下發給DN進行執行,各DN執行過程中存在數據交互(Stream操作符) |
各DN執行時有數據交互,AP場景下的複雜語句 |
前3個計劃都是CN下發語句給DN,第4個計劃是CN生成計劃,將計划下發給DN,第4個計劃也被稱為stream計劃,是最為常用的計劃。
為什麼會有下發語句的計劃?
CN生成執行計劃,需要耗費較多CPU資源,且計劃較原始語句大許多,下發語句對於CN以及網路傳輸的開銷小很多。
號外!

華為將於2023年9月20-22日,在上海世博展覽館和上海世博中心舉辦第八屆華為全聯接大會(HUAWEICONNECT 2023)。本次大會以“加速行業智能化”為主題,邀請思想領袖、商業精英、技術專家、合作伙伴、開發者等業界同仁,從商業、產業、生態等方面探討如何加速行業智能化。
我們誠邀您蒞臨現場,分享智能化的機遇和挑戰,共商智能化的關鍵舉措,體驗智能化技術的創新和應用。您可以:
- 在100+場主題演講、峰會、論壇中,碰撞加速行業智能化的觀點
- 參觀17000平米展區,近距離感受智能化技術在行業中的創新和應用
- 與技術專家面對面交流,瞭解最新的解決方案、開發工具並動手實踐
- 與客戶和伙伴共尋商機
感謝您一如既往的支持和信賴,我們熱忱期待與您在上海見面。
大會官網:https://www.huawei.com/cn/events/huaweiconnect
歡迎關註“華為雲開發者聯盟”公眾號,獲取大會議程、精彩活動和前沿乾貨。


