
當談到[數據湖](https://www.dtstack.com/dtengine/easylake?src=szsm)的時候,大家都在說,可以把所有數據(結構化/半結構化/非結構化)一股腦都丟進去,進行統一的元數據管理。然後上層計算對接,進行[流批計算](https://www.dtstack.c ...
當談到數據湖的時候,大家都在說,可以把所有數據(結構化/半結構化/非結構化)一股腦都丟進去,進行統一的元數據管理。然後上層計算對接,進行流批計算/OLAP 分析/演算法分析。
這個沒問題,數據湖確實能承接底層的這部分能力,但是同時出現的問題也是不容忽視的。
本文將關註討論,利用湖倉架構,統一結構化/半結構化數據的流批計算,和大家聊聊為什麼企業需要實時湖倉。非結構化的視頻/圖片/文本等數據的存儲和計算不在本文的討論範圍內。
當前的企業困境
下圖是一個經典的 Lambda 架構,雖然這套架構的優點很明顯:技術方案成熟、應用實踐廣泛,適用於企業發展過程中各階段、各場景下的大數據開發需求。
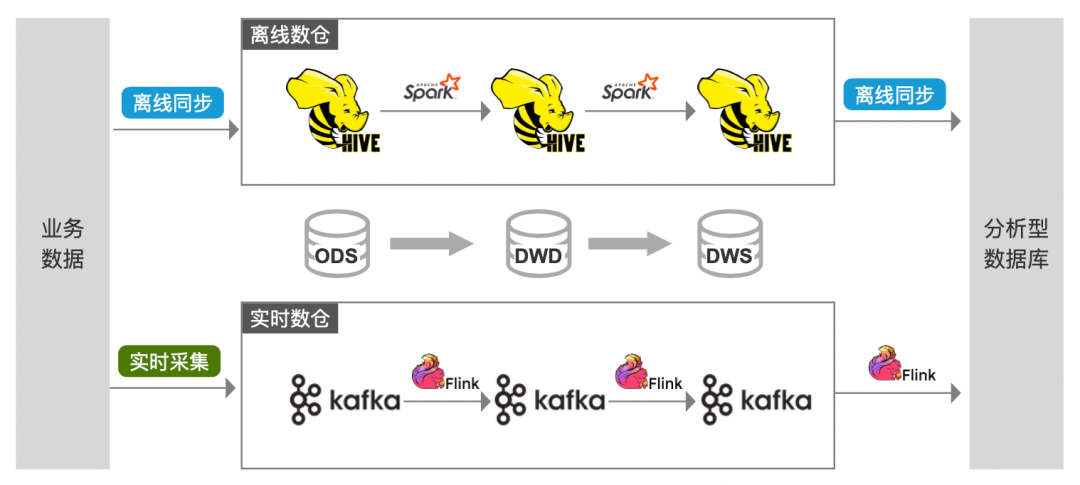
但是,隨著業務對數據時效性要求的提高,許多企業的實時任務體量,正在逐步接近存量離線任務。在數據開發和運維資源有限的情況下,這套架構的問題正在逐漸暴露出來:
· 離線開發鏈路中的數據更新問題,在當前技術環境下顯得越來越難以容忍
· 實時開發鏈路中的數據不落地問題,無法支持歷史數據回溯、查詢分析等場景
· 多種計算引擎,造成數據開發學習成本和運維管理成本的居高不下
· 多種存儲介質,造成數據存儲冗餘、批/流數據不一致
· ……
解決之道:實時湖倉
下圖是一種實時湖倉解決方案,利用湖存儲的特性和 Flink 的流批計算能力,統一存儲和計算,解決 Lambda 架構的問題。
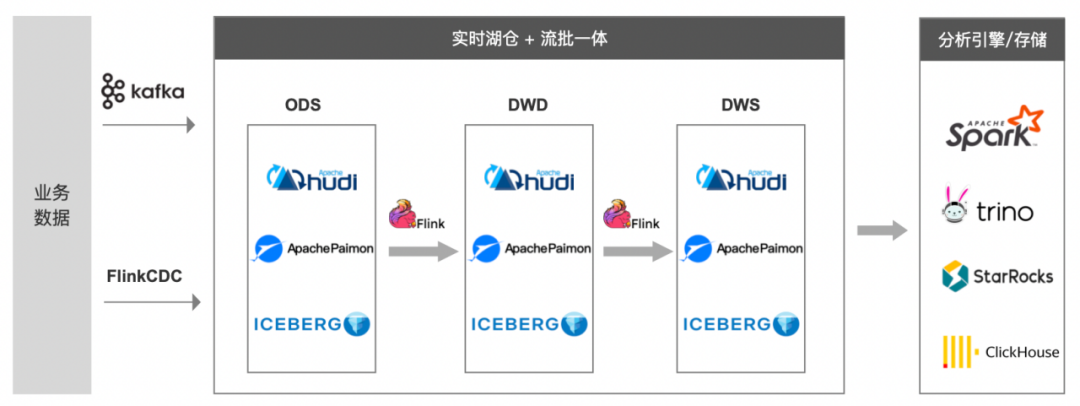
本文以 Paimon 為例,Paimon 是 Flink 內部基於 Flink Tablestore 孵化的一款湖存儲產品。和 Hudi/Iceberg 相比,Paimon 和 Flink 引擎有著更完整的相容能力。
下麵將就袋鼠雲的實踐經驗,展開說說如何使用“Flink+數據湖”三步構建實時湖倉。
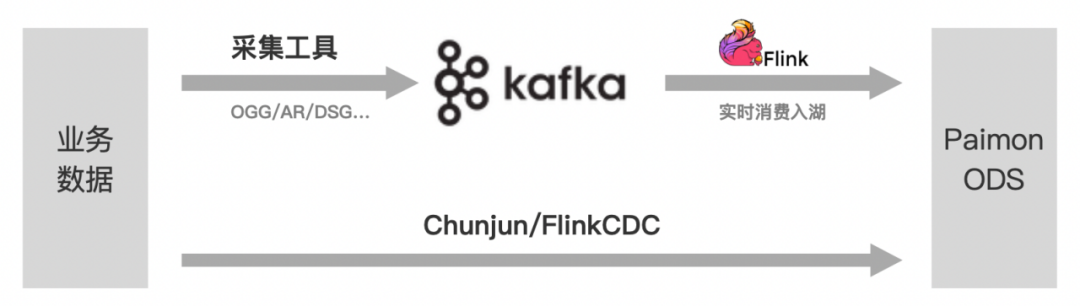
● Step1:搭建實時 ODS 層
不管是通過 Flink 消費 Kafka,還是通過 FlinkCDC 採集日誌,都可以將源庫數據實時同步至 Paimon 中。
這樣,無論上層是要做批計算還是流計算,都有份統一的實時 ODS 數據做基礎,避免了數據不一致和存儲冗餘的問題。
● Step2:加工湖倉中間層
關於實時湖倉的層級設計,可以參考成熟的離線數倉劃分方案。
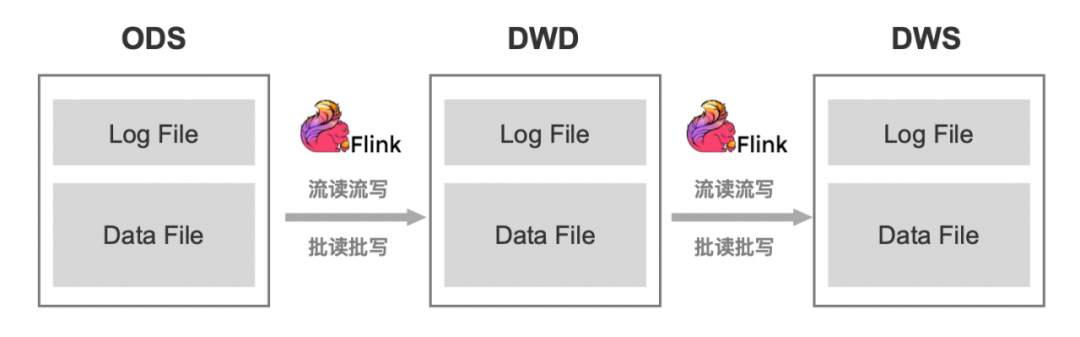
從上面的架構圖中可以看出,Paimon 存儲將文件分為 DataFile 和 LogFile:
· DataFile 用於存量數據的批計算
· LogFile 用於增量數據的流計算,但畢竟是一種文件存儲格式,其實時性只能做到分鐘級別。如果業務場景對實時性有秒級/毫秒級要求,Paimon 也支持將 Kafka 外掛為 LogFile 使用,同時對上層應用暴露的,仍然只有一張 Paimon 表。
基於上面的特性,如何在實際應用體現出流/批一體能力,可以參考如下幾種開發場景:
01 流、批獨立任務
根據實際業務場景需要,使用 Flink+Paimon 的統一技術棧,進行離線任務和實時任務的獨立開發。
02 批流一體任務
在很多實時統計類的數據開發場景下,往往需要在完成存量數據統計的基礎上,再銜接實時增量計算。傳統的 Lambda 架構要完成這種場景,實現上相對比較複雜,而使用 Flink+Paimon,一個任務即可滿足。
03 流批一體任務
傳統的 Lambda 架構中,為了保障 Flink+Kafka 實時計算的準確性,往往需要將 Kafka 數據雙寫一份到離線存儲中,然後通過離線定時任務對實時計算結果做一次覆蓋修正。而使用 Flink+Paimon,一個任務即可滿足。
● Step3:湖倉分析應用層
這層有兩種不同的落地方案,可以根據企業技術棧自由選型:
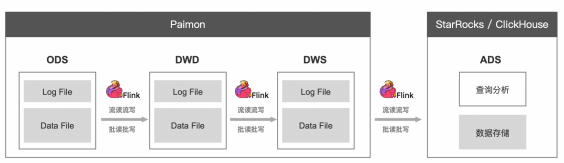
· ADS 層數據也在數據湖加工落地,然後使用 OLAP 引擎如 Trino、StarRocks 直接對接數據湖,向上層提供數據分析能力。這樣做可以實現存儲的完全統一,但是在查詢分析性能上會有一定的犧牲。
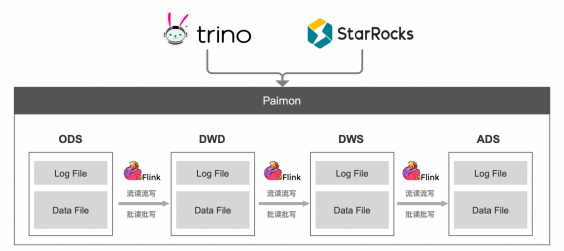
· 將 DWS 層數據加工後打入 StarRocks 或者 ClickHouse 這類存儲+分析的統一引擎。該方案可以充分利用這類引擎的查詢加速能力,對於 OLAP 場景有較高要求的企業,是個比較合適的方案。
企業的其他選擇?
目前業內比較熱門的探索實踐,不依賴 Hadoop 體系,僅利用 StarRocks/Doris 構建實時數倉的方式,大致的架構圖如下:
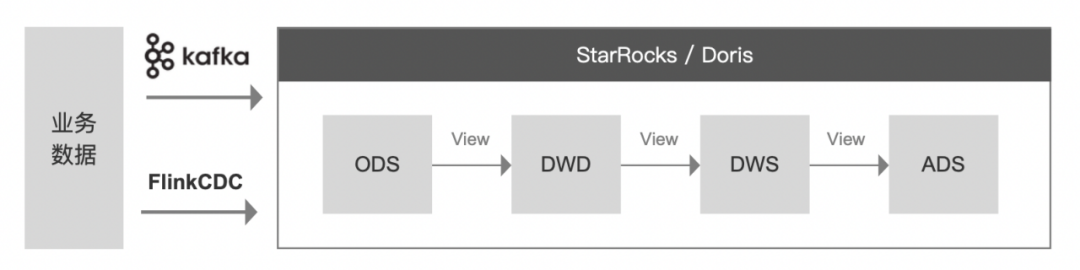
理論上,該方案確實可行。StarRocks/Doris 本身作為計算+存儲一體的引擎,具備向量化、MPP 架構、CBO、智能物化視圖、可實時更新等能力,在一定程度上可以滿足構建實時數倉的要求。
但是,在我們接觸過的一些金融客戶的實際應用中發現,當數據體量較大、視圖邏輯較複雜時,該方案存在明顯的性能瓶頸。
而根據 StarRocks/Doris 官網對自己高性能分析型數倉的定位,將它作為企業 OLAP 的選型,完全沒有問題,但是寄希望於它承擔全鏈路的大數據計算,目前來看還有很長的路要走。
所以,將實時湖倉部分層級的計算,前移至“Flink+數據湖”的架構中,仍然是當前技術方案中最優的選擇。
本文根據《實時湖倉實踐五講第一期》直播內容總結而來,感興趣的朋友們可免費獲取直播課件:
直播課件:
https://www.dtstack.com/resources/1050?src=szsm
《數棧產品白皮書》:https://www.dtstack.com/resources/1004?src=szsm
《數據治理行業實踐白皮書》下載地址:https://www.dtstack.com/resources/1001?src=szsm
想瞭解或咨詢更多有關袋鼠雲大數據產品、行業解決方案、客戶案例的朋友,瀏覽袋鼠雲官網:https://www.dtstack.com/?src=szbky
同時,歡迎對大數據開源項目有興趣的同學加入「袋鼠雲開源框架釘釘技術qun」,交流最新開源技術信息,qun號碼:30537511,項目地址:https://github.com/DTStack


