
前言 作為一名後端軟體工程師,工作中你肯定和 Redis 打過交道。但是Redis 為什麼快呢?很多人只能答出Redis 因為它是基於記憶體實現的,但是對於其它原因都是模棱兩可。 那麼今天就一起來看看是Redis 為什麼快吧: Redis 為什麼這麼快? 一、基於記憶體實現 Redis 是基於記憶體的數據 ...
前言
作為一名後端軟體工程師,工作中你肯定和 Redis 打過交道。但是Redis 為什麼快呢?很多人只能答出Redis 因為它是基於記憶體實現的,但是對於其它原因都是模棱兩可。
那麼今天就一起來看看是Redis 為什麼快吧:
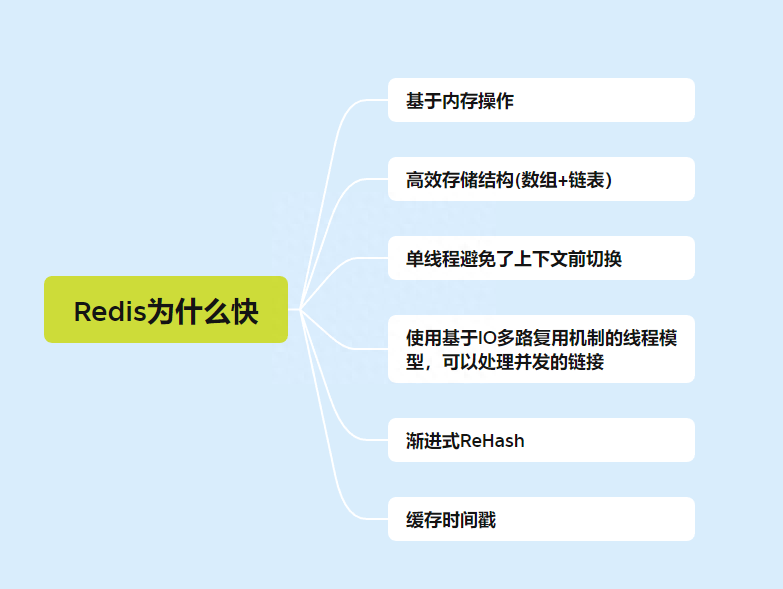
Redis 為什麼這麼快?
一、基於記憶體實現
Redis 是基於記憶體的資料庫,那不可避免的就要與磁碟資料庫做對比。對於磁碟資料庫來說,是需要將數據讀取到記憶體里的,這個過程會受到磁碟 I/O 的限制。而對於記憶體資料庫來說,本身數據就存在於記憶體里,也就沒有了這方面的開銷。
二、高效存儲結構
為了實現從鍵到值的快速訪問,Redis 使用了一個哈希表來保存所有鍵值對。一個哈希表,其實就是一個數組,數組的每個元素稱為一個哈希桶。所以,我們常說,一個哈希表是由多個哈希桶組成的,每個哈希桶中保存了鍵值對數據。
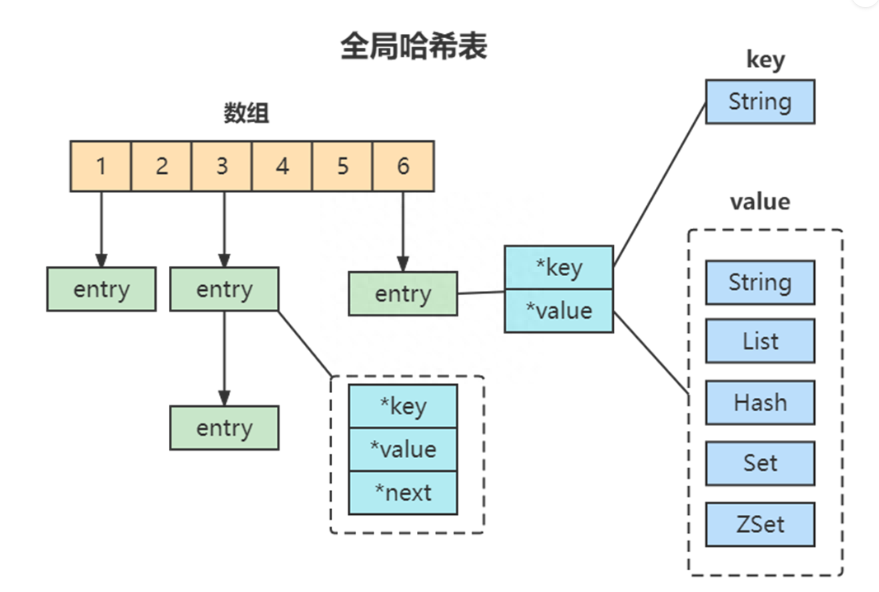
全局哈希表
哈希桶中的 entry 元素中保存了key和value指針,分別指向了實際的鍵和值,因為其value的多樣性,哈希表中存儲的並不是具體的值,而是一個記憶體引用地址,在通過記憶體引用的地址查找到對應的具體的值。這樣一來,即使value是一個集合,也可以通過*value指針被查找到。因為這個哈希表保存了所有的鍵值對,所以,我也把它稱為全局哈希表。
哈希表的最大好處很明顯,就是讓我們可以用 O(1) 的時間複雜度來快速查找到鍵值對:我們只需要計算鍵的哈希值,就可以知道它所對應的哈希桶位置,然後就可以訪問相應的 entry 元素。但當你往 Redis 中寫入大量數據後,就可能發現操作有時候會突然變慢了。這其實是因為你忽略了一個潛在的風險點,那就是哈希表的衝突問題和 rehash 可能帶來的操作阻塞。
當你往哈希表中寫入更多數據時,哈希衝突是不可避免的問題。這裡的哈希衝突,兩個 key 的哈希值和哈希桶計算對應關係時,正好落在了同一個哈希桶中。
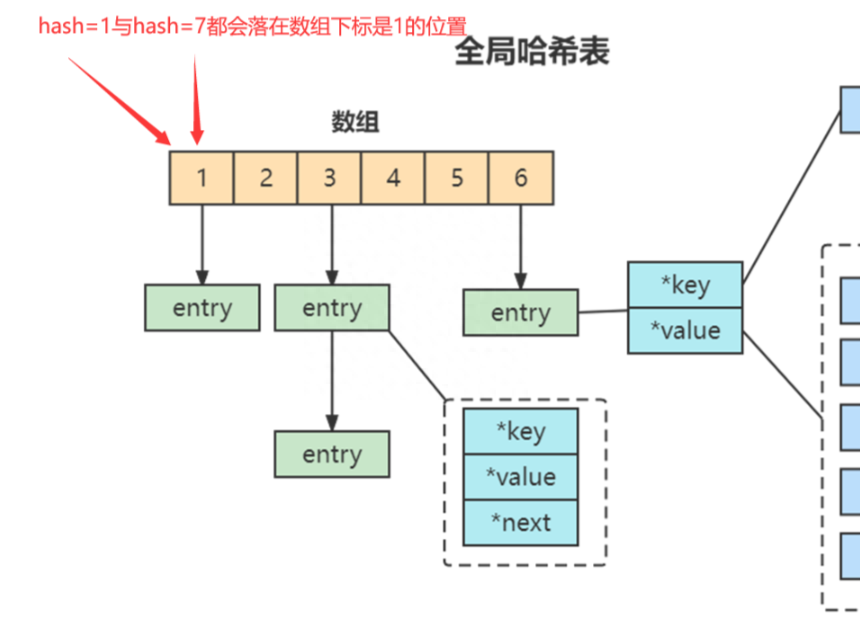
哈希表的哈希衝突
Redis 解決哈希衝突的方式,就是鏈式哈希。鏈式哈希也很容易理解,就是指同一個哈希桶中的多個元素用一個鏈表來保存,它們之間依次用指針連接。
三、單線程避免了上下文前切換
省去了很多上下文切換的時間以及CPU消耗,不存在競爭條件,不用去考慮各種鎖的問題,不存在加鎖釋放鎖操作,也不會出現死鎖而導致的性能消耗。
四、使用基於IO多路復用機制的線程模型,可以處理併發的鏈接。
Redis採用了epoll 模型進行IO多路復用。Java中也有類似的模型比如NIO,才epoll模型之前還有selector、poll這裡不多講解,epoll模型可以參考下圖:
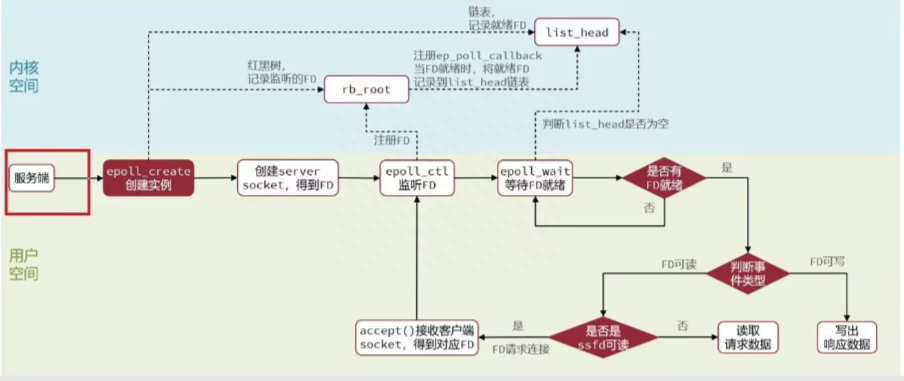
epoll 模型
五、漸進式ReHash
Redis是當然如果這個數組一直不變,那麼hash衝突會變很多,這個時候檢索效率會大打折扣,所以Redis就需要把數組進行擴容(一般是擴大到原來的兩倍),但是問題來了,擴容後每個hash桶的數據會分散到不同的位置,這裡設計到元素的移動,必定會阻塞IO,所以這個ReHash過程會導致很多請求阻塞。
為了避免這個問題,Redis 採用了漸進式 rehash。
首先、Redis 預設使用了兩個全局哈希表:哈希表 1 和哈希表 2。一開始,當你剛插入數據時,預設使用哈希表 1,此時的哈希表 2 並沒有被分配空間。隨著數據逐步增多,Redis 開始執行 rehash。
1、給哈希表 2 分配更大的空間,例如是當前哈希表 1 大小的兩倍
2、把哈希表 1 中的數據重新映射並拷貝到哈希表 2 中
3、釋放哈希表 1 的空間
在上面的第二步涉及大量的數據拷貝,如果一次性把哈希表 1 中的數據都遷移完,會造成 Redis 線程阻塞,無法服務其他請求。此時,Redis 就無法快速訪問數據了。
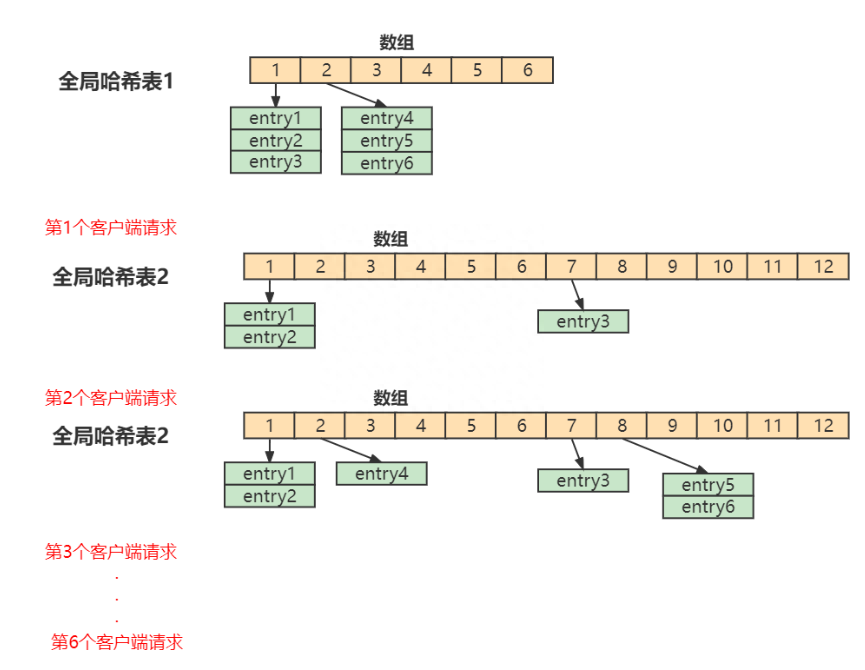
漸進式rehash
在Redis 開始執行 rehash,Redis仍然正常處理客戶端請求,但是要加入一個額外的處理:
處理第1個請求時,把哈希表 1中的第1個索引位置上的所有 entries 拷貝到哈希表 2 中
處理第2個請求時,把哈希表 1中的第2個索引位置上的所有 entries 拷貝到哈希表 2 中
如此迴圈,直到把所有的索引位置的數據都拷貝到哈希表 2 中。
這樣就巧妙地把一次性大量拷貝的開銷,分攤到了多次處理請求的過程中,避免了耗時操作,保證了數據的快速訪問。
所以這裡基本上也可以確保根據key找value的操作在O(1)左右。
過這裡要註意,如果Redis中有海量的key值的話,這個Rehash過程會很長很長,雖然採用漸進式Rehash,但在Rehash的過程中還是會導致請求有不小的卡頓。並且像一些統計命令也會非常卡頓:比如keys
按照Redis的配置每個實例能存儲的最大的key的數量為2的32次方,即2.5億,但是儘量把key的數量控制在千萬以下,這樣就可以避免Rehash導致的卡頓問題,如果數量確實比較多,建議採用分區hash存儲。
六、緩存時間戳
我們平常使用系統時間戳時, 常常是不假思索地使用System.currentTimeMillis()或者new Date() .getTime() 來獲取系統的毫秒時間戳。但是Redis不能這樣做,因為每一次獲取系統時間戳都是一次系統調用,而且每次去系統調用是比較費時間的,作為單線程的Redis是無法承受的,所以它需要對於時間戳進行一次緩存,由一個定時任務進行每毫秒更新時間戳,從而獲取時間戳都是直接從緩存就取出。

