
Goroutine 是 Golang 協程的實現。相比於其他語言,Goroutine 更加輕量,更加簡單。Goroutine 是學習 Golang 必須掌握的知識。本文介紹 Goroutine 的基礎知識,包含 基礎語法使用和 Channel。 ...
基礎概念
進程與線程
進程是一次程式在操作系統執行的過程,需要消耗一定的CPU、時間、記憶體、IO等。每個進程都擁有著獨立的記憶體空間和系統資源。進程之間的記憶體是不共用的。通常需要使用 IPC 機制進行數據傳輸。進程是直接掛在操作系統上運行的,是操作系統分配硬體資源的最小單位。
線程是進程的一個執行實體,一個進程可以包含若幹個線程。線程共用進程的記憶體空間和系統資源。線程是 CPU 調度的最小單位。因為線程之間是共用記憶體的,所以它的創建、切換、銷毀會比進程所消耗的系統資源更少。
舉一個形象的例子:一個操作系統就相當於一支師級編製的軍隊作戰,一個師會把手上的作戰資源獨立的分配各個團。而一個團級的編製就相當於一個進程,團級內部會根據具體的作戰需求編製出若幹的營連級,營連級會共用這些作戰資源,它就相當於是電腦中的線程。
什麼是協程
協程是一種更輕量的線程,被稱為用戶態線程。它不是由操作系統分配的,對於操作系統來說,協程是透明的。協程是程式員根據具體的業務需求創立出來的。一個線程可以跑多個協程。協程之間切換不會阻塞線程,而且非常的輕量,更容易實現併發程式。Golang 中使用 goroutine 來實現協程。
併發與並行
可以用一句話來形容:多線程程式運行在單核CPU上,稱為併發;多線程程式運行在多核CPU上,稱為並行。
Goroutine
Golang 中開啟協程的語法非常簡單,使用 Go 關鍵詞即可:
func main() {
go hello()
fmt.Println("主線程結束")
}
func hello() {
fmt.Println("hello world")
}
// 結果
主線程結束程式列印結果並非是我們想象的先列印出 “hello world”,再列印出 “主線程結束”。這是因為協程是非同步執行的,當協程還沒有來得及列印,主線程就已經結束了。我們只需要在主線程中暫停一秒就可以列印出想要的結果。
func main() {
go hello()
time.Sleep(1 * time.Second) // 暫停一秒
fmt.Println("主線程結束")
}
// 結果
hello world
主線程結束這裡的一次程式執行其實是執行了一個進程,只不過這個進程就只有一個線程。
在 Golang 中開啟一個協程是非常方便的,但我們要知道併發編程充滿了複雜性與危險性,需要小心翼翼的使用,以防出現了不可預料的問題。
編寫一個簡單的併發程式
用來檢測各個站點是否能響應:
func main() {
start := time.Now()
apis := []string{
"https://management.azure.com",
"https://dev.azure.com",
"https://api.github.com",
"https://outlook.office.com/",
"https://api.somewhereintheinternet.com/",
"https://graph.microsoft.com",
}
for _, api := range apis {
_, err := http.Get(api)
if err != nil {
fmt.Printf("響應錯誤: %s\n", api)
continue
}
fmt.Printf("成功響應: %s\n", api)
}
elapsed := time.Since(start) // 用來記錄當前進程運行所消耗的時間
fmt.Printf("主線程運行結束,消耗 %v 秒!\n", elapsed.Seconds())
}
// 結果
成功響應: https://management.azure.com
成功響應: https://dev.azure.com
成功響應: https://api.github.com
成功響應: https://outlook.office.com/
響應錯誤: https://api.somewhereintheinternet.com/
成功響應: https://graph.microsoft.com
主線程運行結束,消耗 5.4122892 秒!我們檢測六個站點一個消耗了5秒的時間,假設現在需要對一百個站點進行檢測,那麼這個過程就會耗費大量的時間,這些時間都被消耗到了 http.Get(api) 這裡。
在 http.get(api) 還沒有獲取到結果時,主線程會等待請求的響應,會阻塞在這裡。這時候我們就可以使用協程來優化這段代碼,將各個網路請求的檢測變成非同步執行,從而減少程式響應的總時間。
func main() {
...
for _, api := range apis {
go checkApi(api)
}
time.Sleep(3 * time.Second) // 等待三秒,不然主線程會瞬間結束,導致協程被殺死
...
}
func checkApi(api string) {
_, err := http.Get(api)
if err != nil {
fmt.Printf("響應錯誤: %s\n", api)
return
}
fmt.Printf("成功響應: %s\n", api)
}
// 結果
響應錯誤: https://api.somewhereintheinternet.com/
成功響應: https://api.github.com
成功響應: https://graph.microsoft.com
成功響應: https://management.azure.com
成功響應: https://dev.azure.com
成功響應: https://outlook.office.com/
主線程運行結束,消耗 3.0013905 秒!可以看到,使用 goroutine 後,除去等待的三秒鐘,程式的響應時間產生了質的變化。但美中不足的是,我們只能在原地傻傻的等待三秒。那麼有沒有一種方法可以感知協程的運行狀態,當監聽到協程運行結束時再優雅的關閉主線程呢?
sync.waitgroup
sync.waitgroup 可以完成我們的”優雅小目標“。 sync.waitgroup 是 goroutine 的一個“計數工具”,通常用來等待一組 goroutine 的執行完成。當我們需要監聽協程是否運行完成就可以使用該工具。sync.waitgroup 提供了三種方法:
-
Add(n int):添加 n 個goroutine 到 WaitGroup 中,表示需要等待 n 個 goroutine 執行完成。
-
Done():每個 goroutine 執行完成時調用 Done 方法,表示該 goroutine 已完成執行,相當於把計數器 -1。
-
Wait():主線程調用 Wait 方法來等待所有 goroutine 執行完成,會阻塞到所有的 goroutine 執行完成。
我們來使用 sync.waitgroup 來優雅的結束程式:
package main
import (
"fmt"
"net/http"
"sync"
"time"
)
func main() {
var (
start = time.Now()
apis = []string{
"https://management.azure.com",
"https://dev.azure.com",
"https://api.github.com",
"https://outlook.office.com/",
"https://api.somewhereintheinternet.com/",
"https://graph.microsoft.com",
}
wg = sync.WaitGroup{} // 初始化WaitGroup
)
wg.Add(len(apis)) // 表示需要等待六個協程請求
for _, api := range apis {
go checkApi(api, &wg)
}
wg.Wait() // 阻塞主線程,等待 WaitGroup 歸零後再繼續
elapsed := time.Since(start) // 用來記錄當前進程運行所消耗的時間
fmt.Printf("線程運行結束,消耗 %v 秒!\n", elapsed.Seconds())
}
func checkApi(api string, wg *sync.WaitGroup) {
defer wg.Done() // 標記當前協程執行完成,計數器-1
_, err := http.Get(api)
if err != nil {
fmt.Printf("響應錯誤: %s\n", api)
return
}
fmt.Printf("成功響應: %s\n", api)
}
// 結果
響應錯誤: https://api.somewhereintheinternet.com/
成功響應: https://api.github.com
成功響應: https://management.azure.com
成功響應: https://graph.microsoft.com
成功響應: https://dev.azure.com
成功響應: https://outlook.office.com/
線程運行結束,消耗 0.9718695 秒!可以看到,我們優雅了監聽了所有協程是否執行完畢,且大幅度縮短了程式運行時間。但同時我們的列印響應信息也是無序的了,這代表了我們的協程確確實實非同步的請求了所有的站點。
Channel
channel 也可以完成我們的”優雅小目標“。 channel 的中文名字被稱為“通道”,是 goroutine 的通信機制。當需要將值從一個 goroutine 發送到另一個時,可以使用通道。Golang 的併發理念是:“通過通信共用記憶體,而不是通過共用記憶體通信”。channel 是併發編程中的一個重要概念,遵循著數據先進先出,後進後出的原則。
聲明 Channel
聲明通道需要使用內置的 make() 函數:
ch := make(chan <type>) // type 代表數據類型,如 string、intChannel 發送數據和接收數據
創建好 channle 後可以使用 <- 來發送/接受數據:
func main() {
ch := make(chan int)
go func() {
ch <- 1 // 發送
}()
a := <-ch // 接收
fmt.Println(a)
close(ch) // 關閉通道
}
// 結果
1每個發送數據都必須有正確的接受方式,否則會編譯錯誤。編譯錯誤比誤用 channel 更好!
接收 channel 中的發來的數據時, a := <-ch 這裡是處於阻塞狀態的。我們可以利用這點來監聽協程是否執行完成,還是上文的例子,但這次我們不使用 sync.waitgroup:
func main() {
var (
start = time.Now()
apis = []string{
"https://management.azure.com",
"https://dev.azure.com",
"https://api.github.com",
"https://outlook.office.com/",
"https://api.somewhereintheinternet.com/",
"https://graph.microsoft.com",
}
ch = make(chan string)
)
for _, api := range apis {
go checkApi(api, ch)
}
// 因為我們一共有六個請求,所以我們要接收六次
for i := 0; i < 6; i++ {
fmt.Println(<-ch)
}
elapsed := time.Since(start) // 用來記錄當前進程運行所消耗的時間
fmt.Printf("線程運行結束,消耗 %v 秒!\n", elapsed.Seconds())
}
func checkApi(api string, ch chan string) {
_, err := http.Get(api)
if err != nil {
ch <- fmt.Sprintf("響應錯誤: %s", api)
return
}
ch <- fmt.Sprintf("成功響應: %s", api)
}
// 結果
成功響應: https://api.github.com
成功響應: https://management.azure.com
成功響應: https://graph.microsoft.com
成功響應: https://outlook.office.com/
成功響應: https://dev.azure.com
線程運行結束,消耗 0.9013927 秒!可以看到,我們利用通道接收數據的阻塞特性,達到了和使用 sync.waitgroup 一樣的效果。
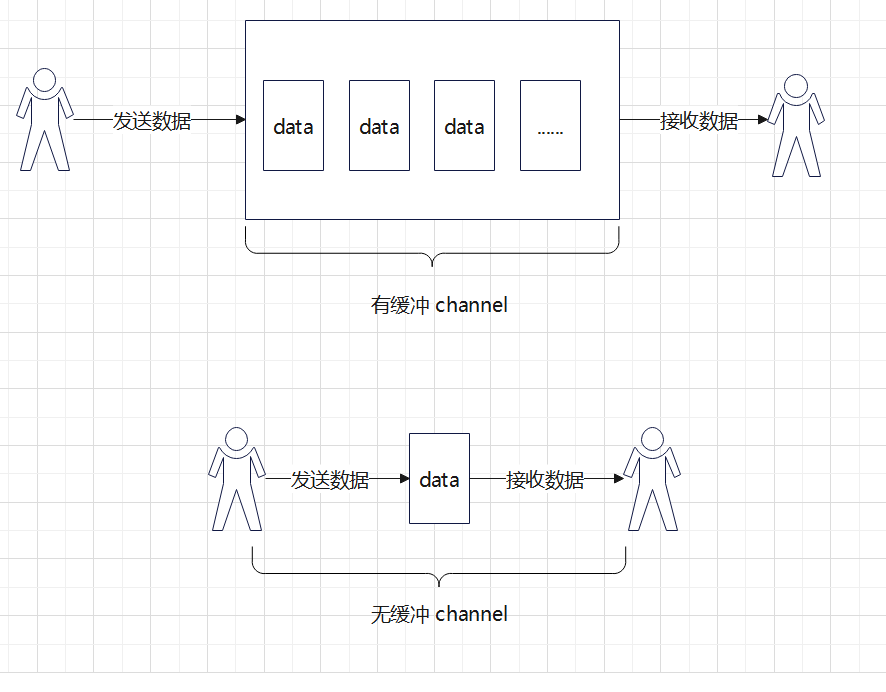
有緩衝 Channel
預設情況下,我們創建的 channel 是無緩衝的,意味著有接收數據,就一定要有對應的發送數據,否則就會永久阻塞程式。有緩衝的 channel 則可以避免這種限制。創建一個有緩衝的 channel:
ch := make(chan <type>, <num>) // num 代表有緩衝通道的大小有緩衝 channel 有點類似與隊列,它不限制發送數據和接收數據,實現了接發 channel 的解耦。每次向 channel 中發送數據不用管有沒有接收方,直接放入這個“隊列”中。當有接收方從隊列中取走數據時,就會從“隊列”中刪除這個值。當 channel 滿時,發送數據會被阻塞,直到 channel 有空;當 channel 為空時,接收數據會被阻塞,直到 channel 有數據過來。
func main() {
ch := make(chan int, 3)
fmt.Printf("當前通道長度:%d\n", len(ch))
send(ch, 1)
send(ch, 2)
send(ch, 3)
fmt.Println("所有數據已經已經放入通道")
fmt.Printf("當前通道長度:%d\n", len(ch))
for i := 0; i < 3; i++ {
fmt.Println(<-ch)
}
fmt.Println("主線程結束")
}
// 結果
當前通道長度:0
所有數據已經已經放入通道
當前通道長度:3
1
2
3
主線程結束這裡並沒有什麼不同的操作,程式也在正常運行,但我們把通道大小改成比 3 更小時,編譯就會出錯,提示 fatal error: all goroutines are asleep - deadlock!這是因為我們在主線程中連續的執行send,最終超出了通道的限制。
func main() {
ch := make(chan int, 2) // 把通道改小
...
}
// 結果
當前通道長度:0
fatal error: all goroutines are asleep - deadlock!
goroutine 1 [chan send]:
main.send(...)
E:/project/gotest/main.go:8
main.main()
E:/project/gotest/main.go:16 +0xfe嘗試使用協程來運行 send 函數:
func main() {
...
go send(ch, 1)
go send(ch, 2)
go send(ch, 3)
...
}
// 結果
當前通道長度:0
所有數據已經已經放入通道
當前通道長度:2
1
2
3
主線程結束channel 與 goroutine 有著千絲萬縷的關係,在使用 channel 時一定要使用 goroutine。
Channel 方向
channel 有一個很有意思的功能,當通道作為函數的參數時,可以限制該通道是發送數據還是接收數據。當程式變的複雜後,這可以有效的記住每個通道的意圖。一個簡單的例子:
func send(ch chan<- string, message string) {
fmt.Printf("發送: %#v\n", message)
ch <- message
}
func read(ch <-chan string) {
fmt.Printf("接收: %#v\n", <-ch)
}
func main() {
ch := make(chan string, 1)
send(ch, "Hello World!")
read(ch)
}
// 結果
發送: "Hello World!"
接收: "Hello World!"當錯誤使用通道時,編譯會不通過:
# command-line-arguments
.\main.go:11:32: invalid operation: cannot receive from send-only channel ch (variable of type chan<- string)多路復用
什麼是多路復用
在實際的業務場景中,有時候需要根據不同的數據來處理不同的結果。舉一個白話例子:
例如現在你有一個物流中心,這個物流中心具備一個這樣的功能:從青島、北海、舟山等城市接收海鮮,從朔州、大同等城市接受煤礦,從廣州、蘇州等城市接受製造業產出的生活用品。接收到這些物資後,根據物資種類發送到各個需要這些物資的地方,比如海鮮發往成渝做火鍋,煤礦發往長三角發電,生活用品發往陝甘供生活使用。
Golang 提供 select 關鍵詞來實現多路復用, select 就類似於這個物流中心,它用來接收多個 channel 中的數據,並做出不同的處理。select 的語法類似與 switch,都具備 case 和 default 但是 select 只適用於 channel。
func seafood(ch chan<- string) {
time.Sleep(2 * time.Second)
ch <- "海鮮已經送達"
}
func coal(ch chan<- string) {
time.Sleep(5 * time.Second)
ch <- "煤礦已經送達"
}
func goods(ch chan<- string) {
time.Sleep(8 * time.Second)
ch <- "生活用品已經送達"
}
func main() {
var (
text string
seafoodCh = make(chan string)
coalCh = make(chan string)
goodsCh = make(chan string)
tick = time.NewTicker(1 * time.Second)
)
go seafood(seafoodCh)
go coal(coalCh)
go goods(goodsCh)
for _ = range tick.C {
select {
case text = <-seafoodCh:
fmt.Println(text)
case text = <-coalCh:
fmt.Println(text)
case <-goodsCh:
fmt.Println("檢測到有生活用品,但是不做處理")
default:
fmt.Println("什麼都沒來")
}
}
}
// 結果
什麼都沒來
海鮮已經送達
什麼都沒來
什麼都沒來
煤礦已經送達
檢測到有生活用品,但是不做處理
什麼都沒來
什麼都沒來
什麼都沒來select 在運行時,如果所有 case 都不滿足,就會選擇 default 執行,如果沒有 default ,select 會一直阻塞等待,直到至少有一個 case 滿足被執行。如果同時有多個 case 被滿足,則 select 會隨機選擇一個執行。
使用多路復用來實現 channel 超時
Golang 沒有直接提供 channel 的超時機制,但是我們可以使用多路復用來實現:
func goods(ch chan<- string) {
time.Sleep(8 * time.Second)
ch <- "生活用品已經送達"
}
func main() {
var (
goodsCh = make(chan string)
)
go goods(goodsCh)
fmt.Println("開始等待")
select {
case <-goodsCh:
fmt.Println("生活用品送到了")
case t := <-time.After(3 * time.Second): // 三秒後 channel 發出當前時間
fmt.Println("沒有等到生活用品")
fmt.Println(t.Format("2006-01-02 15:04:05"))
break
}
fmt.Println("主線程運行結束")
}
// 結果
開始等待
沒有等到生活用品
2023-04-08 14:51:36
主線程運行結束本系列文章:


