
配置Redis哨兵集群時日誌顯示+sdown slave的問題 一、配置及其環境描述(問題產生的原因是因為Redis複製中主節點對從節點的ip配置錯誤,從而導致哨兵無法識別從節點,進而無法進行故障轉移) 1.操作系統:Linux 虛擬機:VMware Workstation 16 Pro 、WSL ...
配置Redis哨兵集群時日誌顯示+sdown slave的問題
一、配置及其環境描述(問題產生的原因是因為Redis複製中主節點對從節點的ip配置錯誤,從而導致哨兵無法識別從節點,進而無法進行故障轉移)
1.操作系統:Linux
虛擬機:VMware Workstation 16 Pro 、WSL
Redis主從複製配置為在VM虛擬機上設置一臺master,WSL虛擬機上設置兩台slave。
Redis哨兵配置為在WSL上設置三台哨兵。
註:虛擬機一共只開啟了兩台,分別是VM和WSL。在WSL上我分別在兩個埠部署了redis-server,以達到兩個slave的目的。然後在WSL上我又在三個埠上部署了三個哨兵,用於在監視VM上部署的master。
2.配置的哨兵集群想達成如下效果:
當我使用shutdown命令關閉部署在VM上的master時,哨兵能夠即時檢測到master已經宕機,併進行投票選舉選出新的master。
3.master的內網ip及埠為:192.xxx.xxx.xxx:6379,兩個slave的內網ip及埠為:172.xxx.xxx.xxx:6380與172.xxx.xxx.xxx:6381
二、問題復現
啟動一主二從,並啟動三台哨兵。手動使master宕機,按照理想狀態得到的結果應該是哨兵從剩下的兩個slave中選取一個成為新的master,但是剩下的兩台slave只是在原地等待舊master的回歸,並未有新的master產生。
三、分析並解決問題
1.1)翻閱剛啟動哨兵時候的哨兵日誌,發現如下內容
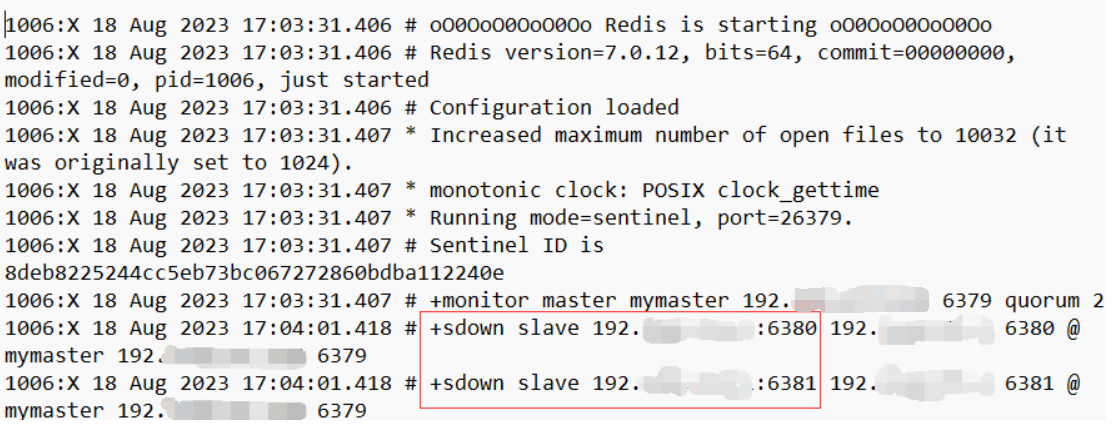
"+sdown slave",說明一件事,就是哨兵無法與我們的兩個從機取得聯繫(哨兵認為slave主觀下線)。那麼也很容易就明白了,在之後的投票選出新master的過程中,也無法在兩個slave中選出。同時,我們還註意到一件事,從節點的ip竟然是以192開頭的,這不對勁,因為從節點的ip應該以172開頭。
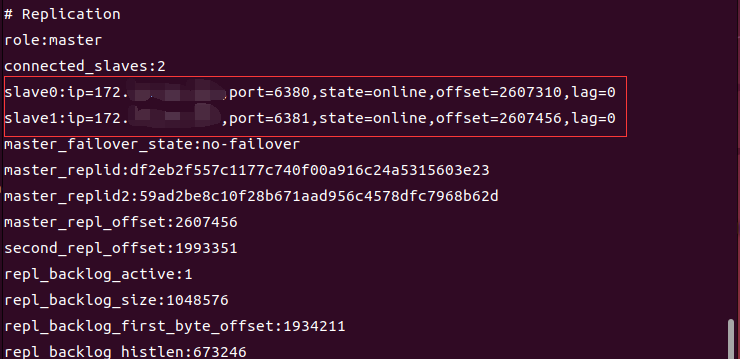
2)啟動Redis複製的一主二從,通過在master上設置鍵值對,並且在兩個從機上取得了對應的鍵值對可以驗證出,主從架構是搭建成功的。然後在master上使用命令"info replication"查詢主從機聯機狀態如下圖

從圖中看出,兩台slave是成功連到了master的。但是,slave的ip開頭竟然是192而不是172,說明,master識別從機的ip時,應該出現了問題。
3)那麼解決問題就應該從master正確識別slave的ip地址入手了。在Redis配置文件中可以配置配置項"slave-announce-ip 從機ip地址",slave-announce-ip 用於指定從節點在複製(Replication)過程中向主節點彙報的 IP 地址。通過在從節點的Redis配置文件中配置該配置項,我們可以使得master正確的反映出slave的ip地址。在經過上述配置後,我們再在master中使用"info replication"查詢主從機聯機狀態時,發現slave的ip地址顯示正確,此時再去哨兵的日誌文件中檢查,發現,哨兵成功的聯繫到了兩個slave。
註:哨兵成功聯繫到slave的哨兵日誌顯示應該是下麵的截圖所示的內容

這裡的"+slave slave"表示哨兵成功與slave的IP以172開頭,埠為6381的slave聯繫成功。
4)再次使master宕機,發現哨兵成功的選舉出了新的master,並變更了相應的Redis配置(使得舊的master成為新的master的slave,並使得原本效忠於舊master的slave重新效忠於新的master)
2.1)因為哨兵有在啟動的時候會將一些主從機以及自己的基本信息寫進哨兵配置文件的操作,所以,上述流程的分析中還可以加上分析哨兵配置文件的流程。
2)具體問題具體分析,但是分析流程可以相同


