
我在上一章《形象談JVM-第一章-認識JVM》提到的“翻譯”,其實就是我們今天所說的“編譯”的概念。 上一章原文鏈接:https://www.cnblogs.com/xingxiangtan/p/17617654.html 原文: 【 虛擬機的職責是將位元組碼翻譯成對應系統能夠識別並執行的機器碼, 比 ...
我在上一章《形象談JVM-第一章-認識JVM》提到的“翻譯”,其實就是我們今天所說的“編譯”的概念。
上一章原文鏈接:https://www.cnblogs.com/xingxiangtan/p/17617654.html
原文:
【 虛擬機的職責是將位元組碼翻譯成對應系統能夠識別並執行的機器碼,
比如在linux系統,java文件被javac編譯器翻譯成位元組碼文件(class文件),jvm將位元組碼文件翻譯成linux能夠識別並執行的機器碼文件,這樣java程式便能夠被運行起來了。
java文件是咱人類能看懂的文件,位元組碼文件是虛擬機能看懂的文件,機器碼文件是CPU能看懂的文件。 】
本文將分為兩個部分來展開,前端編譯與優化和後端編譯與優化
講之前我們先來弄清楚這三個關鍵詞的意思,前端、後端和優化。
前後端:以文件進入JVM之前和之後為基準在區分前後的。
優化:一個高級的翻譯將英文作品翻譯成中文作品時,絕不會逐字死板的去翻譯,而是會在不影響原意的前提下加以文采的修飾,以達到讀者更好更快的理解,編譯器的優化類似,在編譯期,在不影響代碼邏輯的前提下,會將複雜優化成簡潔的,將緩慢的優化成快速的等等,為了程式更好更快(非絕對)的執行。
前端編譯器及優化:
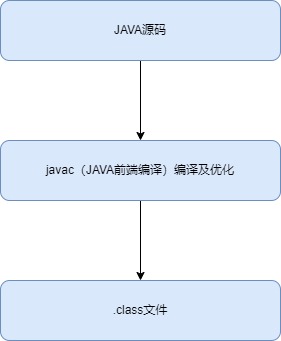
前端編譯器包括JDK的Javac、Eclipse JDT中的增量式編譯器(ECJ)等等, 咱們講javac,javac本身就是一個由Java語言編寫的程式。

執行javac命令,就是javac編譯器解析Java源代碼,並生成位元組碼文件的過程。javac編譯過程可以分為四個階段:
1、詞法、語法分析。
詞法分析是將源代碼的字元流轉變為標記集合的過程。
語法分析是根據標記序列構造抽象語法樹的過程,抽象語法樹(Abstract Syntax Tree,AST)是一種用來描述程式代碼語法結構的樹形表示方式。
舉個形象的例子,上中學,學英語科目,我們要弄懂一句話,首先得知道各個單詞的意思,這就對應著詞法分析了,然後英語的語法有很多種,首先要搞清楚主謂賓結構,還有從句,後置之類的語法,這個就對應了語法分析,這二者都沒問題了就能夠弄清楚這一句話的意思了。
2、填充符號表。
類之間是會互相引用的,但在編譯階段,無法確定其具體的地址,所以會使用一個符號來替代。等到被引用類載入時,javac 編譯器會將符號替換成具體的記憶體地址。
比如開學第一天,老師讓你去找一個班裡的一個名字叫“李小花”的同學,這個“名字”就相當於一個“符號”,你不知道李小花同學坐在哪裡,你就大喊李小花的名字,李小花同學聽到了,便答應,於是你就看到了李小花坐在三排二座,以後你就知道“三排二座”的同學就是李小花了,這個“三排二座”就相當於“地址值”。
3、註解處理。
JDK 5之後,Java語言提供了對註解的支持,註解在設計上原本是與普通的Java代碼一樣,都只會在程式運行期間發揮作用的,因此在這個階段會對註解進行分析,根據註解的作用將其還原成具體的指令集。
4、語義分析與位元組碼生成。
語義分析的主要任務是對結構上正確的源程式進行上下文相關性質的檢查,比如類型檢查、控制流檢查、數據流檢查,等等,再進行位元組碼的生成,最終輸出為class文件。
後端編譯器及優化:
後端編譯器包括JIT(Just In Time)即時編譯器和AOT(Ahead Of Time)提前編譯器。
而在解釋後端編譯器之前我們要先來解釋一下解釋器
解釋器:直接執行用編程語言編寫的指令的程式。
編譯器:把源代碼轉換成(翻譯)低級語言的程式。(這裡所指的低級是越接近於機器則越低級)

如上圖,編譯器如同“筆譯員”,對語言進行轉換,輸出一份可以被用於執行的文件,解釋器如同“口譯員”,直接將翻譯後的結果輸出,不保存任何中間文件。
從這二者的工作模式,可以很容易的聯想到它們的優點和缺點
解釋器:
優點:啟動速度快
缺點:執行速度慢,執行效率低
編譯器:
優點:執行效率高
缺點:編譯速度(啟動速度)慢
接下來咱們繼續講回後端編譯器。
JIT(Just In Time)即時編譯器
HotSpot虛擬機內置了兩個(或三個)即時編譯器,在執行的過程中,將熱點代碼(也就是執行次數比較多的代碼)轉化為本
地機器碼,並做優化,以加速執行效率。
客戶端編譯器(Client Compiler)和服務端編譯器(Server Compiler),簡稱為C1編譯器和C2編譯器,第三個是在JDK 10時才出現的、目標是代替C2的Graal編譯器。咱們本章節只講解C1、C2編譯器。
在 Java 7 以前,我們需要根據程式的特性選擇對應的即時編譯器。
對於執行時間較短的,或者對啟動性能有要求的程式,我們採用編譯效率較快的 C1,對應參數 -client。
對於執行時間較長的,或者對峰值性能有要求的程式,我們採用生成代碼執行效率較快的 C2,對應參數 -server。
在分層編譯(Tiered Compilation)的工作模式出現以前,HotSpot虛擬機通常是採用解釋器與其中一個編譯器直接搭配的方式工作,程式使用哪個編譯器,只取決於虛擬機運行的模式,HotSpot虛擬機會根據自身版本與宿主機器的硬體性能自動選擇運行模式,用戶也可以使用“-client”或“-server”參數去強制指定虛擬機運行在客戶端模式還是服務端模式。
無論採用的編譯器是客戶端編譯器還是服務端編譯器,解釋器與編譯器搭配使用的方式在虛擬機中被稱為“混合模式”(MixedMode),
用戶也可以使用參數“-Xint”強制虛擬機運行於“解釋模式”(Interpreted Mode),這時候編譯器完全不介入工作,全部代碼都使用解釋方式執行。另外,也可以使用參數“-Xcomp”強制虛擬機運行於“編譯模式”(Compiled Mode),這時候將優先採用編譯方式執行程式,但是解釋器仍然要在編譯無法進行的情況下介入執行過程。
可以通過虛擬機的“-version”命令的輸出結果顯示出這三種模式:

Java 7 引入了分層編譯(對應參數 -XX:+TieredCompilation)的概念,綜合了 C1 的啟動性能優勢和 C2 的峰值性能優勢。
分層編譯的五個層次
分層編譯將 Java 虛擬機的執行狀態分為了五個層次。
五個層級分別是:
1、程式解釋執行,不開啟Profiling(性能監控功能:解釋器替編譯器收集性能監控信息);
2、進行簡單可靠的穩定優化,執行不帶 profiling 的 C1 機器碼;
3、執行僅帶方法調用次數以及迴圈回邊執行次數 profiling 的 C1 機器碼;
4、執行帶所有 profiling(除第3層的統計信息外,還會收集如分支跳轉、虛方法調用版本等全部的統計信息) 的 C1 機器碼;
5、執行 C2 機器碼。對比C1,C2會啟用更多編譯耗時更長的優化,還會根據性能監控信息進行一些不可靠的激進優化;
通常情況下,C2 代碼的執行效率要比 C1 代碼的高出 30% 以上。
然而,對於 C1 代碼的三種狀態,按執行效率從高至低則是 1 層 > 2 層 > 3 層。
其中 1 層的性能比 2 層的稍微高一些,而 2 層的性能又比 3 層高出 30%。
這是因為 profiling 越多,其額外的性能開銷越大。
在 5 個層次的執行狀態中,1 層和 4 層為終止狀態。當一個方法被終止狀態編譯過後,如果編譯後的代碼並沒有失效,那麼 Java 虛擬機是不會再次發出該方法的編譯請求的。

如何來理解這個激進優化呢?
激進:有一定的性能提升,但不一定准確可靠
舉例:
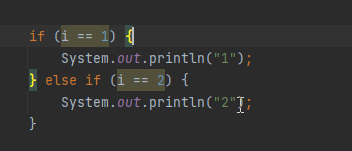
若在運行的過程中,性能監控到前一百次執行都只是走了1分支,那咱們編譯還需要去考慮編譯2分支嗎?不需要了。
但是如果不編譯2分支的代碼,之後程式真的走了2分支咋辦?直接找五層中的第一層的解釋器執行就好了。(在後面的章節中我們會講解更多的優化策略)
AOT(Ahead Of Time)提前編譯器
提前編譯器也可稱為靜態預編譯器,因為它不像即時編譯器,是在程式一邊解釋執行,一邊進行編譯的,而是先單獨把文件編譯完成。
JIT 優點:
1、啟動速度快
2、根據運行情況實時編譯生成最優機器指令
3、可以處理動態語言,因為可以在運行時確定類型。
JIT 缺點:
1、占用運行時的資源,可能會導致進程執行時候卡頓
2、識別熱點代碼需要時間,初始編譯不能達到最高性能。
AOT 優點:
1、在程式運行前編譯,可以避免在運行時的編譯性能消耗和記憶體消耗
2、程式運行初期就達到最高性能,顯著的提高執行效率。
AOT 缺點:
1、啟動速度慢
2、不能處理動態語言,因為需要在編譯時確定類型。
參考書籍:
深入理解虛擬機-第3版-周志明著
參考資料:
https://blog.csdn.net/Shockang/article/details/117392773
https://zhuanlan.zhihu.com/p/107382276
為什麼寫文章 ?(若有錯誤,希望得到你的指正,若有問題,都可評論,我將會積極回覆)
在作者剛入行時,會遇到很多無法理解的問題,便經常向前輩請教問題,或是於網路之中苦苦尋找答案,經常被一些晦澀難懂的表達折磨的死去活來,現作者是一名擁有多年經驗的IT從業者,希望能夠將自己的知識以一種形象的方式輸出,先從虛擬機開始分享,之後會寫更多的專欄,最新的分享將會先在公眾號發佈,謝謝讀者的關註


