
來源:juejin.cn/post/7139202066362138654 昨天線上容器突然cpu飆升,也是第一次排查這種問題所以記錄一下~ ## 前言 首先問題是這樣的,周五正在寫文檔,突然收到了線上報警,發現cpu占用達到了90多,上平臺監控系統查看容器,在jvm監控中發現有一個pod在兩個小時 ...
來源:juejin.cn/post/7139202066362138654
昨天線上容器突然cpu飆升,也是第一次排查這種問題所以記錄一下~
前言
首先問題是這樣的,周五正在寫文檔,突然收到了線上報警,發現cpu占用達到了90多,上平臺監控系統查看容器,在jvm監控中發現有一個pod在兩個小時內產生了61次youngGc一次fullGc,這個問題特別嚴重且少見,由於我之前也沒有排查過此類問題,所以也是百度,但整個過程也有一些自己的思考,所以跟大家分享一下~
推薦一個開源免費的 Spring Boot 實戰項目:
當時場景
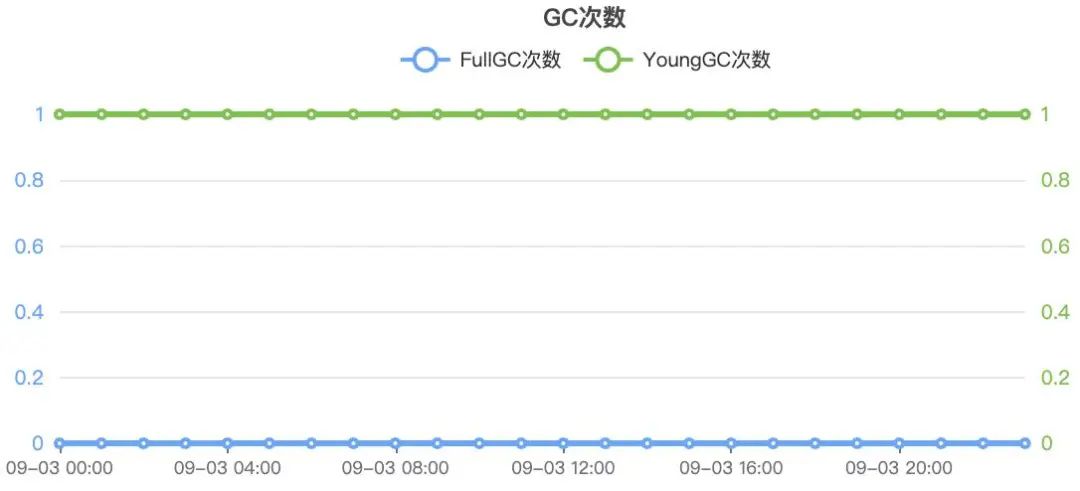
我先給大家看一下一副正常的gc曲線監控(為保密性,我自己按照平臺監控畫了出來):
正常的jvm監控曲線圖
產生問題的jvm監控曲線圖
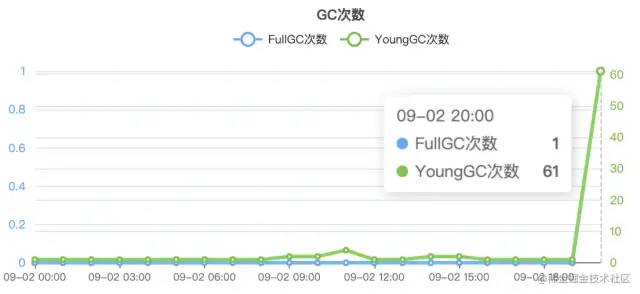
可以看的出來,正常情況下該系統很少gc(具體看業務系統使用情況、jvm記憶體分配),但是在圖二中出現了大量異常的gc情況甚至觸發了fullGc,所以我當時立馬進行了分析。
具體分析
首先異常gc的情況只出現在一個pod上(系統有多個pod),在監控系統找到對應的pod,進入pod內部查看問題原因,排查問題一定要冷靜
進入pod之後,輸入top查看各linux進程對系統資源的使用情況(因我這是事後補稿,資源使用不高,大家看步驟即可)

分析資源使用情況在當時的情況下
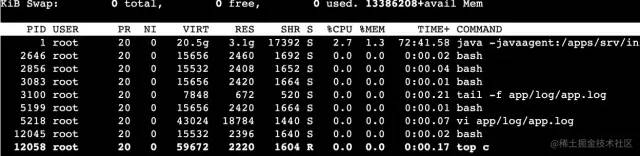
當時我的pid為1的進程cpu上到了130(多核)那我認定就是java應用出問題了,control+c退出繼續往下走
輸入top -H -p pid 通過此命令可以查看實際占用CPU最高的的線程的id,pid為剛纔資源使用高的pid號

出現具體線程的資源使用情況,表格裡的pid代表線程的id,我們稱他為tid

我記得當時的tip為746(上述圖片只是我給大家重覆步驟),使用命令printf "%x\n" 746,將線程tid轉換為16進位

因為我們線程id號在堆棧里是16進位的所以需要做一個進位轉換
輸入jstack pid | grep 2ea >gc.stack
jstack pid | grep 2ea >gc.stack

解釋一下,jstack是jdk給提供的監控調優小工具之一,jstack會生成JVM當前時刻的線程快照,然後我們可以通過它查看某個Java進程內的線程堆棧信息,之後我們把堆棧信息通過管道收集2ea線程的信息,然後將信息生成為gc.stack文件,我隨便起的,隨意
當時我先cat gc.stack 發現數據有點多在容器里看不方便,於是我下載到本地瀏覽,因為公司對各個機器的訪問做了限制,我只能用跳板機先找到一臺沒用的機器a,把文件下載到a然後我再把a里的文件下載到本地(本地訪問跳板機OK),先輸入python -m SimpleHTTPServer 8080,linux自帶python,這個是開啟一個簡單http服務供外界訪問

然後登錄跳板機,使用curl下載curl -o http://ip地址/gcInfo.stack
為方便演示,我在圖中把ip換了一個假的

之後用同樣的方法從本地下載跳板機就可以了,記得關閉python開啟的建議服務嗷
把文件下載到了本地,打開查看編輯器搜索2ea,找到nid為2ea的堆棧信息
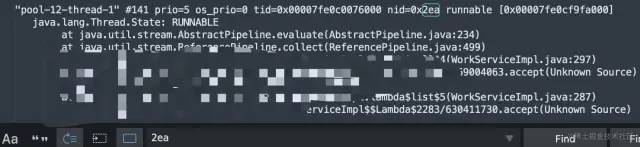
之後找到對應的impl根據行數分析程式
發現是在文件非同步導出excel的時候,導出介面使用了公共列表查詢介面,列表介面查詢數據最多為分頁200一批,而導出數據量每個人的許可權幾萬到十幾萬不等

並且該判斷方法使用了嵌套迴圈里判斷,且結合業務很容易 get 不到 value,Java 下的new ArrayList 就是返回一個 List 集合(好像不用說這麼細 (;一_一 ),在整個方法結束之前,產生的 lists生命周期還在所以發生多次gc觸發重啟之後還影響到了別的pod。然後對代碼進行了fix,緊急上線,問題解決~
結束語
遇到生產問題,大家不要害怕,遇到問題先保證服務是否可用,然後通過有限的信息層層解析,找出最終的問題。如果你會 arthas,排查起來會更輕鬆!
近期熱文推薦:
1.1,000+ 道 Java面試題及答案整理(2022最新版)
4.別再寫滿屏的爆爆爆炸類了,試試裝飾器模式,這才是優雅的方式!!
覺得不錯,別忘了隨手點贊+轉發哦!


