
# 索引結構  ## InnoDB B 樹 
InnoDB B 樹
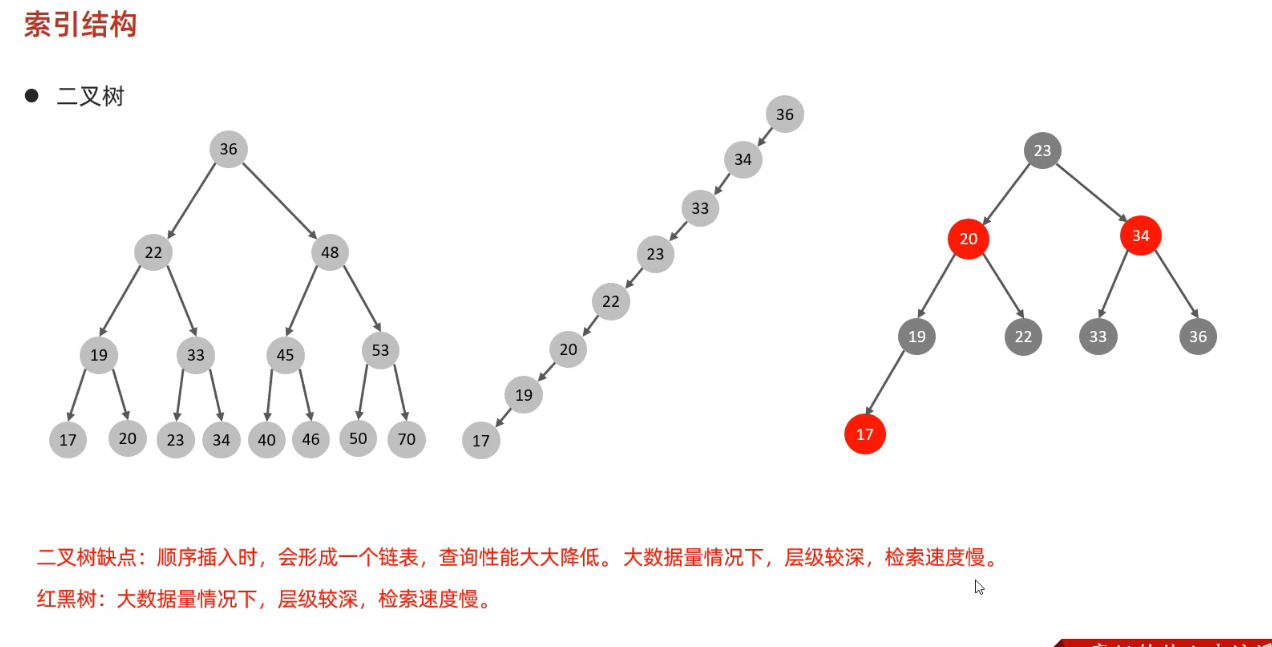
上面是二叉樹和紅黑樹的結構,其實紅黑樹是一個自平衡二叉查找樹,可以用於解決二叉樹順序插入時形成一個有序鏈表問題。
但是兩者都有一個明顯缺點,就是當數據量過大時,層級較深,檢索速度慢。
下麵分析一下 B樹(多路平衡查找樹)
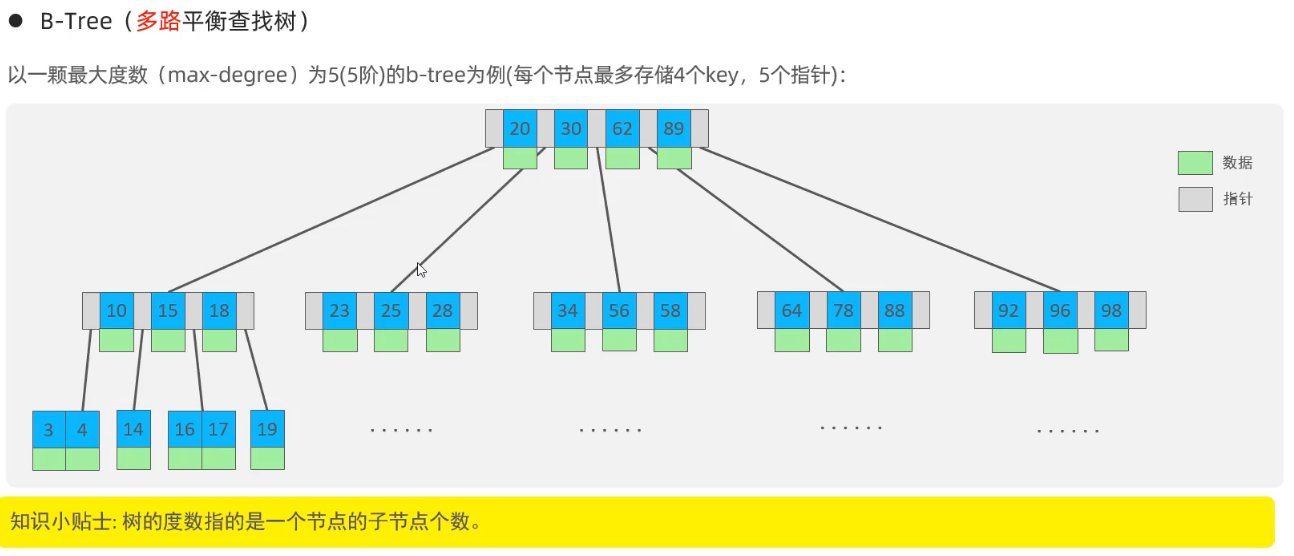
名詞解析:
- 度數:指的是一個節點的子節點個數。
上面這個 B 樹圖,度數為 5 也成為 5 階,最多可以存儲 4 個 key,5 個指針。
例如:小於 20 的會走第一個指針找到 【10,15,18】這個子節點,在 20 - 30 之間的會找到 【23,25,28】這個子節點依此推斷,如果一個節點 N 個 key,那麼就有 N+1 個指針。
這樣的數據結構優勢非常明顯,每一層能存儲的數據量增加了,並且有效的降低了樹的層級數。
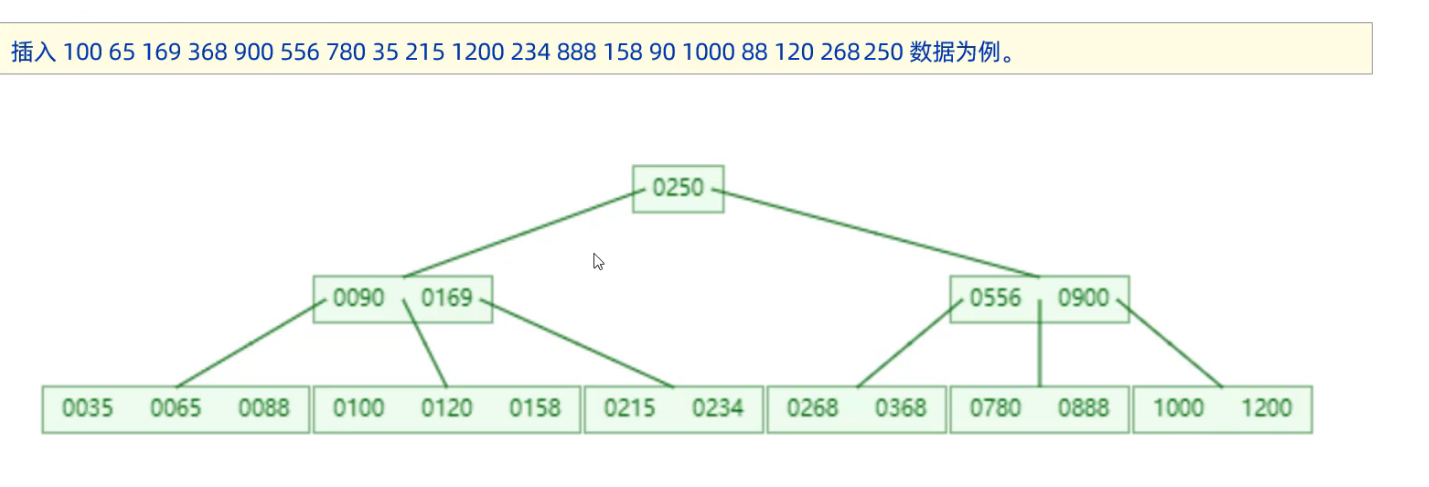
上圖是一個 B 數的插入分裂演變過程。
假設這個 B 數的最大度數是 5 階,那麼最多能存儲 4 key,5 個指針。
其核心在於插入順序和分裂過程:簡單來說就是按順序插入,當插入時發現這個節點以及滿足 4 個 key 了,那麼此時就需要進入到向上分裂過程,這個分裂是從當前節點的中間 key 向上分裂過程。
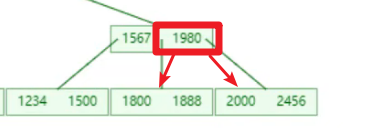
eg:待插入元素 【2456】,當前節點元素【1800,1888,1980,2000】
- 插入前發現當前節點存儲的 key 已經到達最大值,此時當前節點需要向上分裂。
- 插入後節點元素為【1800,1888,1980,2000,2456】,此時挑選中間元素向上分裂成為當前節點的父節點。
- 分裂結果:【1980】(父節點元素)、【1800,1888】|【2000,2456】
- 最終效果是:小於【1980】的指針指向【1800,1888】,大於【1980】的指針指向【2000,2456】
InnoDB B+ 數
首先看看經典的 B+ 樹結構:
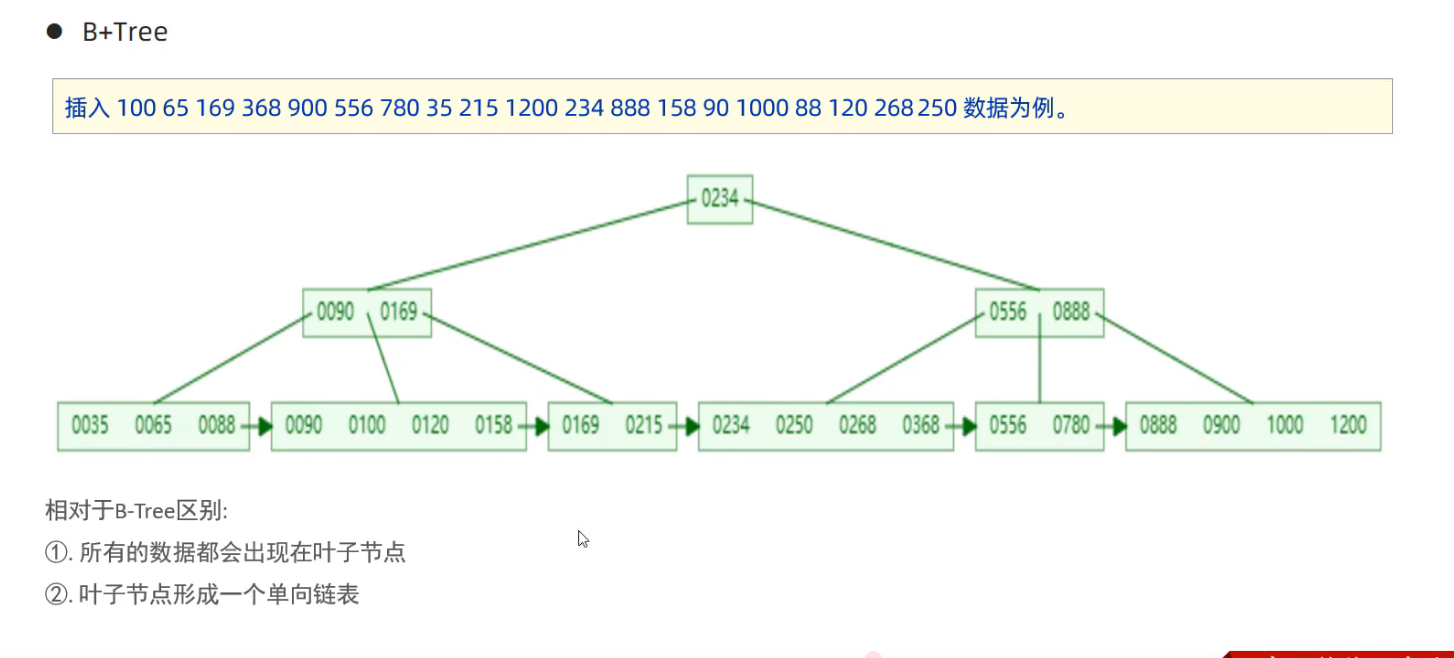
上面這個是經典 B+ 樹,其插入順序和分裂過程跟 B 樹類似,主要的區別點有 3 個:
- 分裂過程:在分裂過程中不單單是只將中間元素向上分裂,同時會將向上分裂的那個元素留在分裂後的子結點中。
- 所有的數據都在葉子節點。
- 葉子節點形成一個單線鏈表。
這分裂過程的特點主要結合所有數據都在葉子節點這個特點去理解。
因為可能我待插入數據他會導致節點出現向上分裂的過程,但是因為 B+ 樹所有數據都在葉子節點,所以需要將待插入的數據保存在葉子節點中。
在 InnoDB 中的 B+ 樹結構。
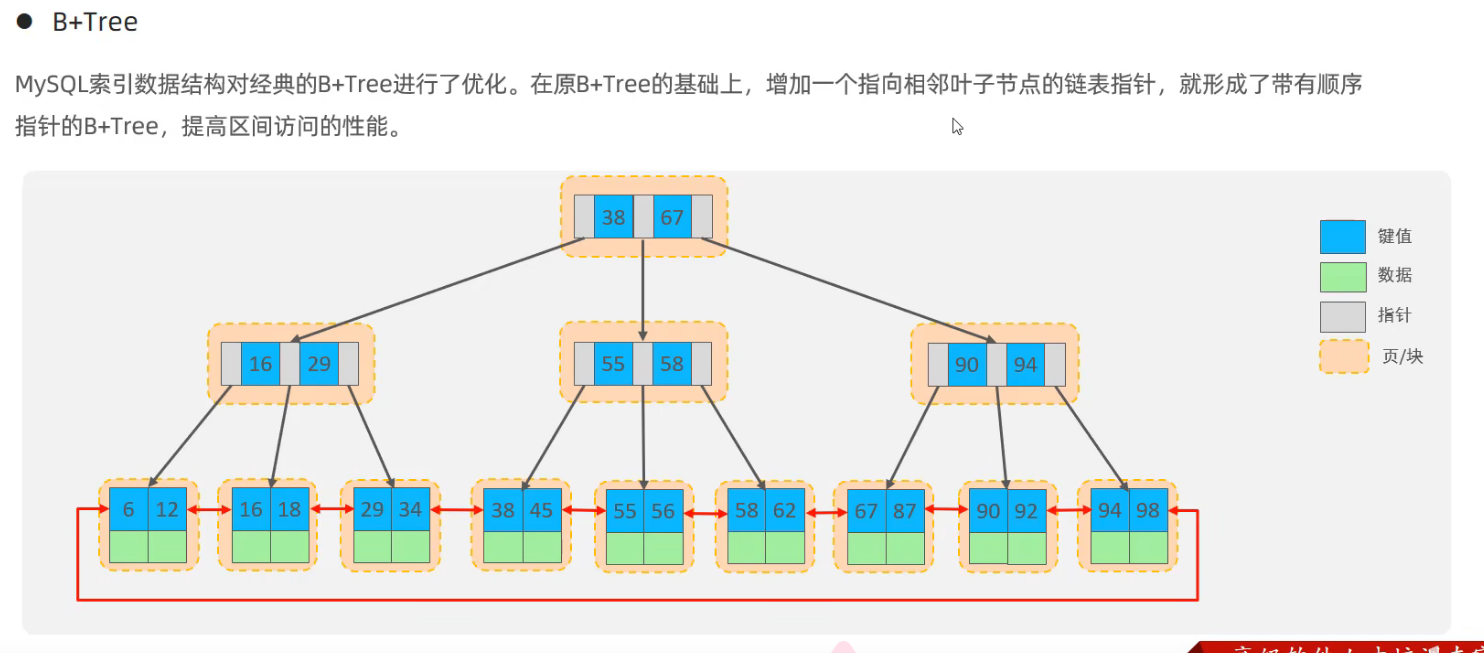
從上圖中可以看到 MySQL 針對經典 B+ 樹進行了優化(要根據物理存儲結構以及保證查詢效率)。
首先看看針對數據結構有什麼優化:
- 葉子節點之間變成了環形雙向鏈表(提高區間訪問效率)
- 每個節點都存在頁中(由 MySQL 中數據在磁碟I/O的基本單位)。
MySQL 表空間和數據區的概念:
表空間:從 InnoDB 邏輯存儲結構來看,所有的數據都被邏輯的存放在一個空間中,這個空間就叫做表空間(tablespace)。表空間由 段(segment)、區(extent)、頁(page)組成。創建一個表,磁碟中就有對應的
.ibd文件。在表空間里有很多組數據區,一組數據區(256MB)是256個數據區, 每個數據區(1MB)包含了64個數據頁,每個頁(16KB)
段(segment):分為索引段,數據段,回滾段等。其中索引段就是非葉子結點部分,而數據段就是葉子結點部分,回滾段用於數據的回滾和多版本控制。一個段包含256個區(256M大小)。
區(extent):區是頁的集合,一個區包含64個連續的頁,預設大小為 1MB (64*16K)。
頁(page):頁是 InnoDB 管理的最小單位,常見的有 FSP_HDR,INODE, INDEX 等類型。所有頁的結構都是一樣的,分為文件頭(前38位元組),頁數據和文件尾(後8位元組)。頁數據根據頁的類型不同而不一樣。
小結:
本次簡單的對 B 樹,B+ 樹,InnoDB B+ 樹,進行了簡單的一個分析。
為了更好的去理解 InnoDB B+ 樹,後續可能還需要去詳細理解 B+ 樹的具體實現、自平衡的原理(左旋右旋)。
後面準備詳細學習一下 MySQL 的調優,從建表規範、查詢語句優化、索引優化、分庫分表 各個方面進行學習。


