
反轉`pandas` `DataFrame`的行列順序是一種非常實用的操作。在實際應用中,當我們需要對數據進行排列或者排序時,通常會使用到Pandas的行列反轉功能。這個過程可以幫助我們更好地理解數據集,發現其中的規律和趨勢。同時,行列反轉還可以幫助我們將數據可視化,使得圖表更加易於理解。 除了常規 ...
2 從內置功能中獲取最高性能
本章包括
- 剖析代碼以發現速度和記憶體瓶頸
- 更有效地利用現有的Python數據結構
- 瞭解Python分配典型數據結構的記憶體成本
- 使用懶編程技術處理大量數據
有很多工具和庫可以幫助我們編寫更高效的Python。但是,在我們深入研究提高性能的所有外部選項之前,讓我們先仔細看看如何編寫在計算和IO性能方面都更高效的純 Python代碼。事實上,許多Python性能問題(當然不是全部)都可以通過更加註意Python的限制和能力來解決。
為了展示Python自身用於提高性能的工具,讓我們將它們用於一個假設但現實的問題。假設您是一名數據工程師,負責準備對全球氣候數據進行分析。這些數據將基於美國國家海洋和大氣管理局(NOAA;http://mng.bz/ydge )的綜合地表資料庫。您的時間很緊,而且只能使用大部分標準Python。此外,由於預算限制,購買更強的處理能力也是不可能的。數據將在一個月後開始到達,您計劃利用數據到達前的時間來提高代碼性能。因此,您的任務就是找到需要優化的地方並提高其性能。
您要做的第一件事就是對現有的代碼進行剖析,以便攝取數據。你知道現有的代碼速度很慢,但在嘗試優化之前,你需要找到瓶頸的經驗證據。剖析之所以重要,是因為它能讓您以嚴謹、系統的方式搜索代碼中的瓶頸。最常見的替代方法--猜測,在這裡尤其無效,因為許多減速點可能很不直觀。
我們將瞭解純Python提供了哪些開箱即用的功能來幫助我們開發性能更高的代碼。首先,我們將使用幾種剖析工具對代碼進行剖析,以發現問題所在。然後,我們將重點關註Python的基本數據結構:列表、集合和字典。我們的目標是提高這些數據結構的效率,並以最佳方式為它們分配記憶體,以獲得最佳性能。最後,我們將瞭解現代Python懶編程技術如何幫助我們提高數據管道的性能。
本章將主要討論在沒有外部庫的情況下優化Python,但我們仍將使用一些外部工具來幫助我們優化性能和訪問數據。我們將使用Snakeviz來可視化Python剖析的輸出,並使用line_profiler來逐行剖析代碼。最後,我們將使用requests庫從互聯網下載數據。
2.1對具有IO和計算工作負載的應用程式進行剖析
我們的第一個目標是從氣象站下載數據,並獲取該氣象站某一年的最低溫度。NOAA 網站上的數據有 CSV 文件,每個年份一個,然後每個站點一個。例如,文https://www.ncei.noaa.gov/data/global-hourly/access/2021/01494099999.csv 包含01494099999氣象站2021年的所有條目。其中包括溫度和氣壓等條目,每天可能會記錄多次。
讓我們開發一個腳本,下載一組站點在某一年份間隔內的數據。下載相關數據後,我們將得到每個站點的最低氣溫。
2.1.1 下載數據並計算最低氣溫
我們的腳本將有一個簡單的命令行界面,通過該界面傳遞站點列表和感興趣的年份間隔。
執行:
# 獲取站點01044099999和02293099999 2021年的數據
$ python load.py 01044099999,02293099999 2021-2021
{'01044099999': -10.0, '02293099999': -27.6}
源碼
import collections
import csv
import sys
import requests
stations = sys.argv[1].split(",") #站點用逗號分割
years = [int(year) for year in sys.argv[2].split("-")] #年份用區間表示
start_year = years[0]
end_year = years[1]
TEMPLATE_URL = "https://www.ncei.noaa.gov/data/global-hourly/access/{year}/{station}.csv"
TEMPLATE_FILE = "station_{station}_{year}.csv"
def download_data(station, year):
my_url = TEMPLATE_URL.format(station=station, year=year)
req = requests.get(my_url)
if req.status_code != 200:
return # not found
w = open(TEMPLATE_FILE.format(station=station, year=year), "wt")
w.write(req.text)
w.close()
def download_all_data(stations, start_year, end_year):
for station in stations:
for year in range(start_year, end_year + 1):
download_data(station, year)
# 用pandas更佳
def get_file_temperatures(file_name):
with open(file_name, "rt") as f:
reader = csv.reader(f)
header = next(reader)
for row in reader:
station = row[header.index("STATION")]
tmp = row[header.index("TMP")]
temperature, status = tmp.split(",")
if status != "1":
continue
temperature = int(temperature) / 10
yield temperature
def get_all_temperatures(stations, start_year, end_year):
temperatures = collections.defaultdict(list)
for station in stations:
for year in range(start_year, end_year + 1):
for temperature in get_file_temperatures(TEMPLATE_FILE.format(station=station, year=year)):
temperatures[station].append(temperature)
return temperatures
def get_min_temperatures(all_temperatures):
return {station: min(temperatures) for station, temperatures in all_temperatures.items()}
download_all_data(stations, start_year, end_year)
all_temperatures = get_all_temperatures(stations, start_year, end_year)
min_temperatures = get_min_temperatures(all_temperatures)
print(min_temperatures)
現在,真正的樂趣開始了。我們的目標是在許多年裡不斷從許多站點下載大量數據。為了處理如此大量的數據,我們希望儘可能提高代碼的效率。提高代碼效率的第一步是有條理地全面剖析代碼,找出拖慢代碼運行的瓶頸。為此,我們將使用Python內置的剖析機制。
2.1.2 Python 內置剖析模塊
我們要確保代碼儘可能高效,首先要做的就是找到代碼中存在的瓶頸。我們首先要做的就是對代碼進行剖析,檢查每個函數的耗時。為此,我們通過cProfile模塊運行代碼。請確保不要使用profile模塊,因為它的速度要慢很多;只有當您自己開發剖析工具時,它才有用。
我們需要的是按累計時間排序的配置文件統計數據。使用該模塊的最簡單方法是在模塊調用中將我們的腳本傳遞給profiler,如下所示:
$ python -m cProfile -s cumulative load.py 01044099999,02293099999 2021-2021 > profile.txt
$ cat profile.txt
{'01044099999': -10.0, '02293099999': -27.6}
387321 function calls (381489 primitive calls) in 16.216 seconds
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
174/1 0.000 0.000 16.216 16.216 {built-in method builtins.exec}
1 0.000 0.000 16.216 16.216 load.py:1(<module>)
1 0.000 0.000 16.013 16.013 load.py:25(download_all_data)
2 0.001 0.000 16.013 8.006 load.py:15(download_data)
2 0.000 0.000 15.973 7.986 api.py:62(get)
2 0.000 0.000 15.973 7.986 api.py:14(request)
2 0.000 0.000 15.972 7.986 sessions.py:500(request)
[...]
1 0.000 0.000 0.000 0.000 socks.py:78(SOCKS5AuthError)
在許多情況下I/O有可能在所需時間方面占據主導地位。在我們的例子中,既有網路I/O(從NOAA獲取數據),也有磁碟I/O(將數據寫入磁碟)。由於網路成本取決於沿途的許多連接點,因此即使在不同的運行中,網路成本也會有很大差異。由於網路成本通常是最大的時間損失,因此我們要儘量減少網路成本。
2.1.3 使用本地緩存減少網路使用量
為了減少網路通信,讓我們在首次下載文件時保存一份副本,以備將來使用。我們將建立一個本地數據緩存。除了函數download_all_data外,我們將使用與前面相同的代碼:
def download_all_data(stations, start_year, end_year):
for station in stations:
for year in range(start_year, end_year + 1):
if not os.path.exists(TEMPLATE_FILE.format(station=station, year=year)):
download_data(station, year)
執行結果:
$ python -m cProfile -s cumulative load_cache.py 01044099999,02293099999 2021-2021 > profile_cache.txt
$ head profile_cache.txt
{'01044099999': -10.0, '02293099999': -27.6}
316570 function calls (310825 primitive calls) in 0.187 seconds
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
172/1 0.000 0.000 0.187 0.187 {built-in method builtins.exec}
1 0.000 0.000 0.187 0.187 load_cache.py:1(<module>)
16 0.000 0.000 0.169 0.011 __init__.py:1(<module>)
1 0.007 0.007 0.103 0.103 load_cache.py:51(get_all_temperatures)
雖然運行時間縮短了一個數量級,但IO仍然耗時最長。現在,不是網路問題,而是磁碟訪問問題。這主要是由於計算量過低造成的。
緩存管理也可能存在問題,而且是常見錯誤的根源。在我們的示例中,文件從未隨時間發生變化,但緩存的許多用例中,源文件可能會發生變化。在這種情況下,緩存管理代碼需要認識到這個問題。我們將在本書的其他部分再次討論緩存問題。
2.2 剖析代碼以檢測性能瓶頸
在這裡,我們將研究CPU耗時最長的代碼。我們將使用NOAA資料庫中的所有站點計算它們之間的距離,這是一個複雜度為n2的問題。
由於我們要比較所有站點之間的距離,因此複雜度為 n2。
前面的代碼需要很長時間才能運行。同時也會占用大量記憶體。如果您有記憶體問題,請限制要處理的站點數量。現在,讓我們使用 Python 的剖析基礎結構來看看大部分時間都花在哪裡了。
2.2.1 可視化剖析信息
我們再次查找延遲執行的代碼片段。但為了更好地檢查跟蹤,我們將使用外部可視化工具SnakeViz(https://jiffyclub.github.io/snakeviz/)。
# pip install snakeviz
$ python -m cProfile -o distance_cache.prof distance_cache.py
註意Python提供了pstats模塊來分析寫入磁碟的跟蹤信息。您可以執行 python -m pstats distance_cache.prof,這將啟動一個命令行界面來分析我們腳本的代價。有關該模塊的更多信息,請參閱 Python 文檔或第 5 章的剖析部分。
為了分析這些信息,我們將使用網路可視化工具SnakeViz。您只需執行snakeviz distance_cache.prof。這將啟動一個互動式瀏覽器視窗(圖 2.1 顯示了一個截圖)。
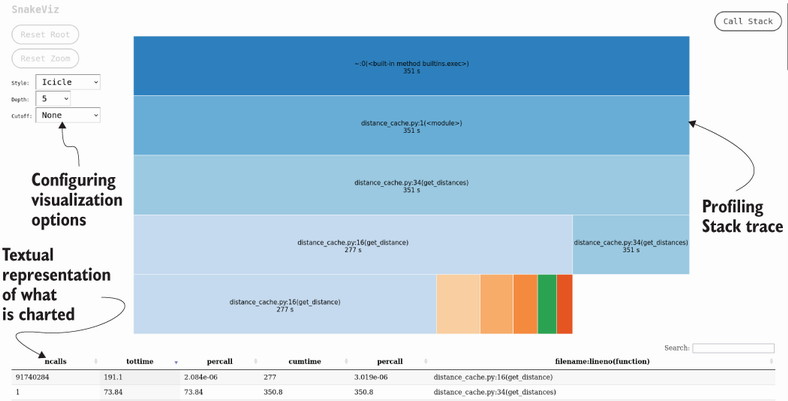
2.2 行剖析
我們將使用https://github.com/pyutils/line_profiler上。使用行剖析器非常簡單:只需在 get_distance 中添加註解即可:
@profile
def get_distance(p1, p2):
這是因為我們將使用line_profiler軟體包中的便捷腳本kernprof來:
kernprof -l lprofile_distance_cache.py
行剖析器所需的工具會大大降低代碼的運行速度,慢上幾個數量級。如果中斷運行,仍會有跟蹤記錄。剖析器運行結束後,可以使用以下命令查看結果:
$ python -m line_profiler lprofile_distance_cache.py.lprof
Timer unit: 1e-06 s
Total time: 19.194 s
File: lprofile_distance_cache.py
Function: get_distance at line 16
Line # Hits Time Per Hit % Time Line Contents
==============================================================
16 @profile
17 def get_distance(p1, p2):
18 6285284 1038835.3 0.2 5.4 lat1, lon1 = p1
19 6285284 942398.6 0.1 4.9 lat2, lon2 = p2
20
21 6285284 1425843.5 0.2 7.4 lat_dist = math.radians(lat2 - lat1)
22 6285284 1342482.5 0.2 7.0 lon_dist = math.radians(lon2 - lon1)
23 6285284 611137.0 0.1 3.2 a = (
24 6285284 2646991.4 0.4 13.8 math.sin(lat_dist / 2) * math.sin(lat_dist / 2) +
25 12570568 3500465.6 0.3 18.2 math.cos(math.radians(lat1)) * math.cos(math.radians(lat2)) *
26 12570568 2468080.8 0.2 12.9 math.sin(lon_dist / 2) * math.sin(lon_dist / 2)
27 )
28 6285284 2877574.5 0.5 15.0 c = 2 * math.atan2(math.sqrt(a), math.sqrt(1 - a))
29 6285284 725911.4 0.1 3.8 earth_radius = 6371
30 6285284 950183.7 0.2 5.0 dist = earth_radius * c
31
32 6285284 664096.4 0.1 3.5 return dist
參考資料
- 軟體測試精品書籍文檔下載持續更新 https://github.com/china-testing/python-testing-examples 請點贊,謝謝!
- 本文涉及的python測試開發庫 謝謝點贊! https://github.com/china-testing/python_cn_resouce
- python精品書籍下載 https://github.com/china-testing/python_cn_resouce/blob/main/python_good_books.md
- Linux精品書籍下載 https://www.cnblogs.com/testing-/p/17438558.html
2.2.3 Profiling小結
正如我們所看到的,作為第一種方法,內置剖析器總體上是一個很大的幫助;它也比行剖析快得多。但是行剖析的信息量要大得多,這主要是因為內置剖析不提供函數內部的細分。相反,Python的剖析只提供每個函數的累計值,並顯示花費在子調用上的時間。在特定情況下,可以知道一個子調用是否屬於另一個函數,但一般來說,這是不可能的。剖析的總體策略需要考慮到所有這些因素。
我們在這裡使用的策略是一種普遍合理的方法:首先,嘗試內置的cProfile,因為它速度快,而且能提供一些高級信息。如果這還不夠,可以使用行剖析,它的信息量更大,但速度也更慢。請記住,在這裡我們主要關註的是找到瓶頸;後面的章節將提供優化代碼的方法。有時,僅僅改變現有解決方案的部分內容是不夠的,還需要進行總體架構重構;我們也會在適當的時候討論這個問題。
timeit可能是新手最常用的代碼剖析方法,你可以在互聯網上找到大量使用 timeit 模塊的示例。使用timeit模塊最簡單的方法是使用IPython或Jupyter Notebook,因為這些系統能讓timeit非常精簡。例如,在IPython中,只需將%timeit魔法添加到你想要剖析的內容中即可:
In [1]: %timeit list(range(1000000))
18.5 ms ± 37.2 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
In [2]: %timeit range(1000000)
82.1 ns ± 0.721 ns per loop (mean ± std. dev. of 7 runs, 10,000,000 loops each)
這將為您提供正在剖析的函數的多次運行時間。這個魔法將決定運行多少次並報告基本統計信息。在前面的代碼段中,你可以看到range(1000000)和list(range(1000000))的區別。在這個具體案例中,timeit顯示,range的懶惰版本比急切版本快兩個數量級。
你可以在timeit模塊的文檔中找到更多細節,但在大多數情況下,使用IPython的%timeit功能就足夠了。我們鼓勵你使用IPython及其魔法,但在本書的其他大部分內容中,我們將使用標準解釋器。有關%timeit魔法的更多信息,請訪問:https://ipython.readthedocs.io/en/stable/interactive/magics.html。
釘釘或微信號: pythontesting 微信公眾號:pythontesting

